Azure Machine Learning 사용하면 배치 엔드포인트 및 배포 구현하여 기계 학습 모델 및 파이프라인을 사용하여 장기 실행 비동기 추론을 수행할 수 있습니다. 기계 학습 모델 또는 파이프라인을 학습할 때 다른 사용자가 새 입력 데이터와 함께 사용하여 예측을 생성할 수 있도록 배포해야 합니다. 모델 또는 파이프라인을 사용하여 예측을 생성하는 이 프로세스를 추론이라고 합니다.
Batch 엔드포인트는 데이터에 대한 포인터를 수신하고 비동기적으로 작업을 실행하여 컴퓨팅 클러스터에서 병렬로 데이터를 처리합니다. Batch 엔드포인트는 추가 분석을 위해 데이터 저장소에 출력을 저장합니다. 다음과 같은 경우 일괄 처리 엔드포인트를 사용합니다.
- 실행하는 데 시간이 더 오래 필요한 비용이 많이 드는 모델 또는 파이프라인이 있습니다.
- 기계 학습 파이프라인을 운영하여 구성 요소를 다시 사용하려고 합니다.
- 여러 파일에 분산된 대량의 데이터에 대해 유추를 수행해야 합니다.
- 낮은 대기 시간 요구 사항이 없습니다.
- 모델의 입력은 스토리지 계정 또는 Azure Machine Learning 데이터 자산에 저장됩니다.
- 병렬 처리를 활용할 수 있습니다.
일괄 처리 구성
배포는 엔드포인트에서 제공하는 기능을 구현하는 데 필요한 리소스 및 컴퓨팅 집합입니다. 엔드포인트는 각각 자체 구성을 사용하여 여러 배포를 호스트하여 배포 구현 세부 정보에서 엔드포인트 인터페이스를 분리할 수 있습니다. 일괄 처리 엔드포인트가 호출되면 클라이언트를 기본 배포로 자동으로 라우팅합니다. 이 기본 배포는 언제든지 구성하고 변경할 수 있습니다.

Azure Machine Learning 일괄 처리 엔드포인트에서 두 가지 유형의 배포가 가능합니다.
모델 배포
모델 배포를 사용하면 대규모로 모델 추론을 운영할 수 있으므로 대기 시간이 짧고 비동기적인 방식으로 대량의 데이터를 처리할 수 있습니다. Azure Machine Learning 컴퓨팅 클러스터의 여러 노드에서 추론 프로세스의 병렬화를 제공하여 확장성을 자동으로 계측합니다.
다음과 같은 경우 모델 배포 를 사용합니다.
- 유추를 실행하는 데 더 긴 시간이 필요한 비용이 많이 드는 모델이 있습니다.
- 여러 파일에 분산된 대량의 데이터에 대해 유추를 수행해야 합니다.
- 낮은 대기 시간 요구 사항이 없습니다.
- 병렬 처리를 활용할 수 있습니다.
모델 배포의 주요 이점은 온라인 엔드포인트에 대한 실시간 추론을 위해 배포된 동일한 자산을 사용할 수 있지만 이제는 대규모로 일괄 처리로 실행할 수 있다는 것입니다. 모델에 간단한 전처리 또는 후처리가 필요한 경우 필요한 데이터 변환 을 수행하는 채점 스크립트를 작성 할 수 있습니다.
일괄 처리 엔드포인트에서 모델 배포를 만들려면 다음 요소를 지정해야 합니다.
- 모델
- 컴퓨팅 클러스터
- 채점 스크립트(MLflow 모델의 경우 선택 사항)
- 환경(MLflow 모델의 경우 선택 사항)
파이프라인 구성 요소 배포
파이프라인 구성 요소 배포를 사용하면 전체 처리 그래프(또는 파이프라인)의 운영화가 짧은 대기 시간 및 비동기 방식으로 일괄 처리 유추를 수행할 수 있습니다.
다음과 같은 경우 파이프라인 구성 요소 배포 를 사용합니다.
- 여러 단계로 분해할 수 있는 전체 컴퓨팅 그래프를 운영해야 합니다.
- 기존 학습 파이프라인의 구성 요소를 추론 파이프라인에서 다시 사용해야 합니다.
- 낮은 대기 시간 요구 사항이 없습니다.
파이프라인 구성 요소 배포의 주요 이점은 플랫폼에 이미 존재하는 구성 요소의 재사용 가능성과 복잡한 유추 루틴을 운영할 수 있는 기능입니다.
일괄 처리 엔드포인트에서 파이프라인 구성 요소 배포를 만들려면 다음 요소를 지정해야 합니다.
- 파이프라인 구성 요소
- 컴퓨팅 클러스터 구성
일괄 처리 엔드포인트를 사용하면 기존 파이프라인 작업에서 파이프라인 구성 요소 배포를 만들 수도 있습니다. Azure Machine Learning이 작업을 수행할 때 자동으로 파이프라인 구성 요소를 만듭니다. 이렇게 하면 이러한 종류의 배포를 간단하게 사용할 수 있습니다. 그러나 항상 파이프라인 구성 요소를 명시적으로 만들어 MLOps 사례를 간소화하는 것이 좋습니다.
비용 관리
일괄 처리 엔드포인트를 호출하면 비동기 일괄 처리 유추 작업이 트리거됩니다. Azure Machine Learning 작업이 시작될 때 컴퓨팅 리소스를 자동으로 프로비전하고 작업이 완료되면 자동으로 할당을 취소합니다. 이렇게 하면 컴퓨팅을 사용할 때만 요금을 지불합니다.
팁
모델을 배포할 때 각 개별 일괄 처리 유추 작업에 대한 컴퓨팅 리소스 설정 (예: 인스턴스 수) 및 고급 설정(예: 미니 일괄 처리 크기, 오류 임계값 등)을 재정의할 수 있습니다. 이러한 특정 구성을 활용하여 실행 속도를 높이고 비용을 절감할 수 있습니다.
일괄 처리 엔드포인트는 우선 순위가 낮은 VM에서도 실행할 수 있습니다. Batch 엔드포인트는 할당 취소된 VM에서 자동으로 복구하고 유추를 위해 모델을 배포할 때 남아 있는 위치에서 작업을 다시 시작할 수 있습니다. 우선 순위가 낮은 VM을 사용하여 일괄 처리 유추 워크로드의 비용을 줄이는 방법에 대한 자세한 내용은 일괄 처리 엔드포인트에서 우선 순위가 낮은 VM 사용을 참조하세요.
마지막으로, Azure Machine Learning 일괄 처리 엔드포인트 또는 일괄 처리 배포 자체에 대한 요금을 청구하지 않으므로 시나리오에 가장 적합한 엔드포인트 및 배포를 구성할 수 있습니다. 엔드포인트 및 배포는 독립 클러스터 또는 공유 클러스터를 사용할 수 있으므로 작업에서 사용하는 컴퓨팅을 세밀하게 제어할 수 있습니다. 클러스터에서 0으로 확장 하여 유휴 상태일 때 리소스가 사용되지 않도록 합니다.
MLOps 연습 간소화
일괄 처리 엔드포인트는 동일한 엔드포인트에서 여러 배포를 처리할 수 있으므로 소비자가 호출하는 데 사용하는 URL을 변경하지 않고도 엔드포인트의 구현을 변경할 수 있습니다.
엔드포인트 자체에 영향을 주지 않고 배포를 추가, 제거 및 업데이트할 수 있습니다.
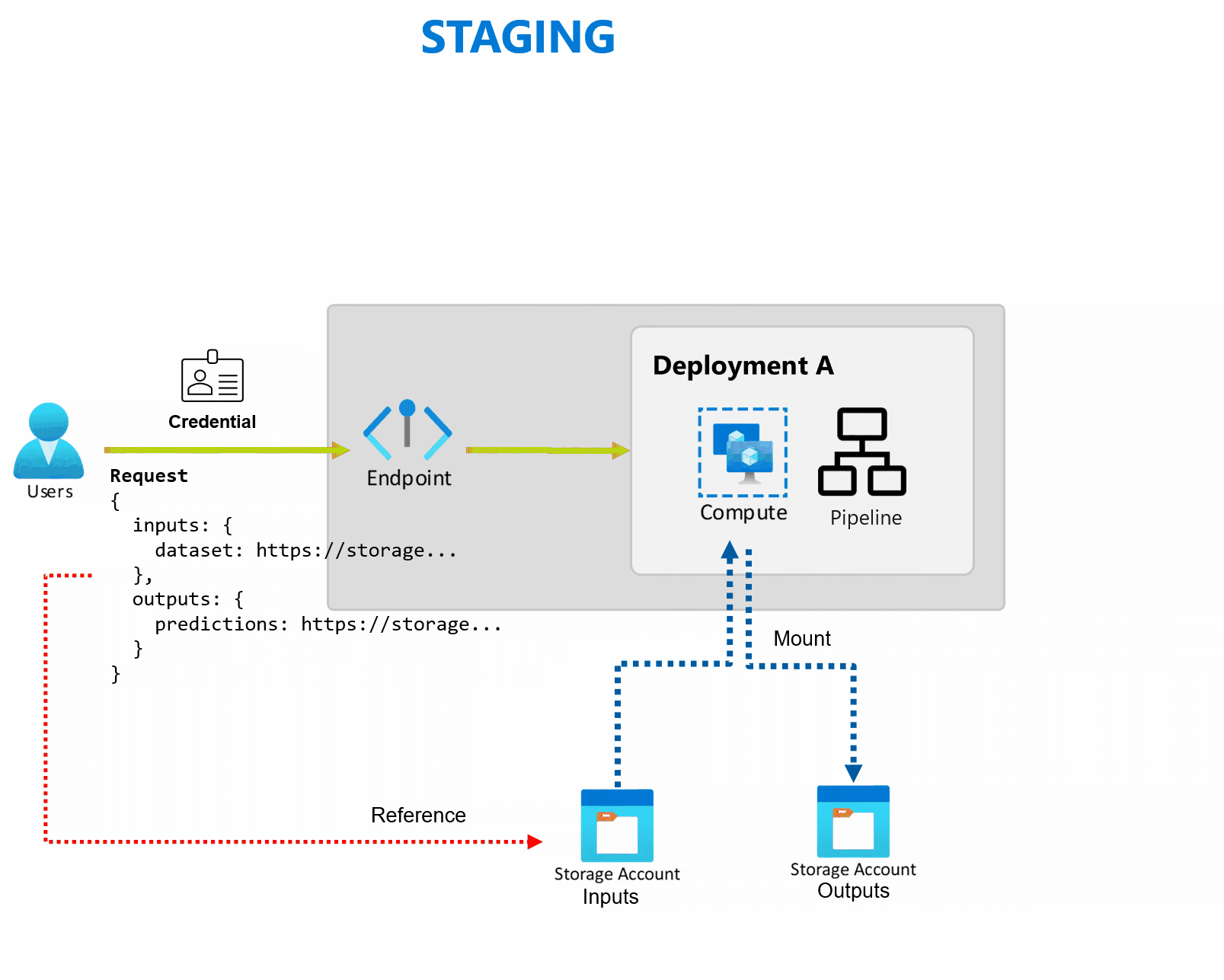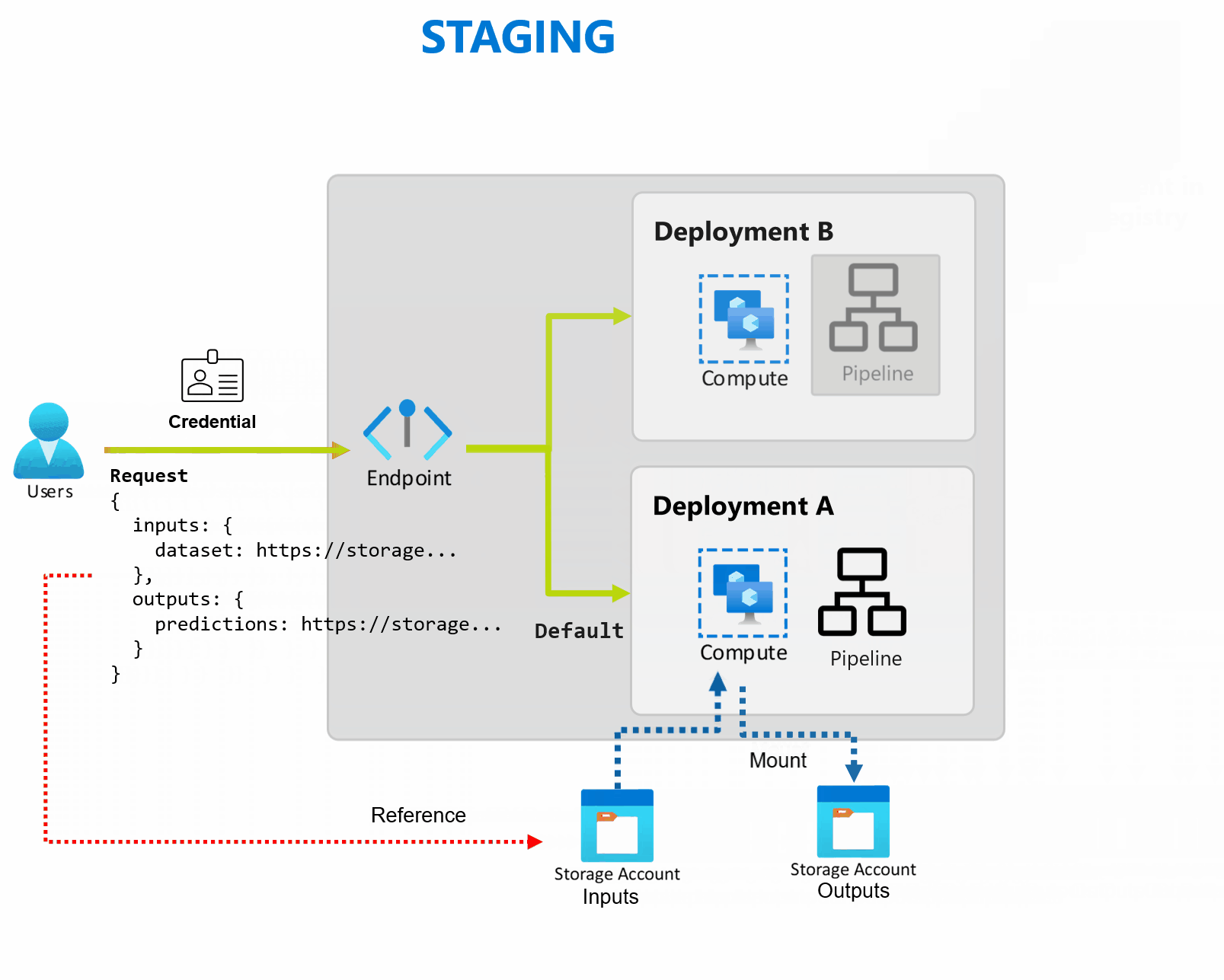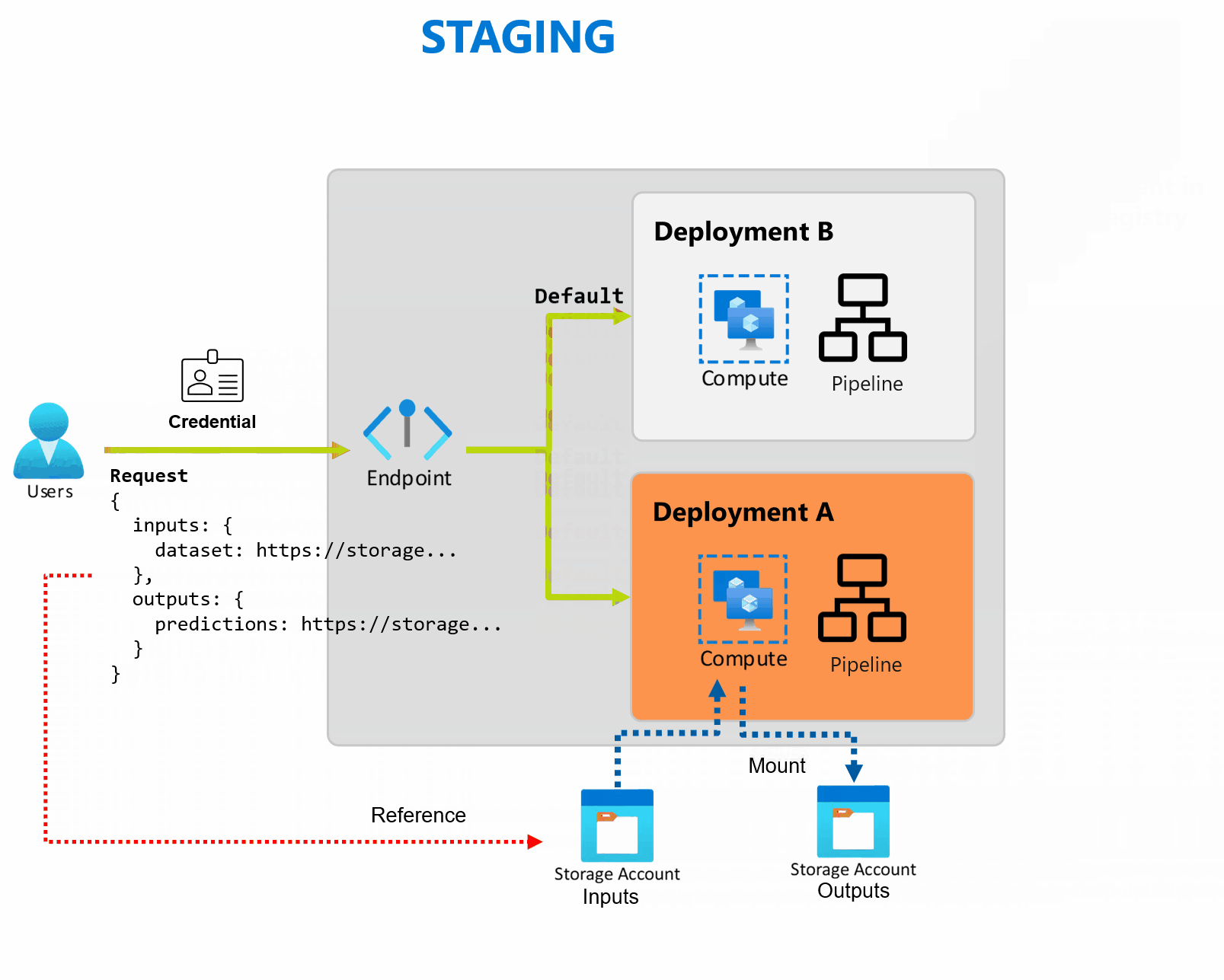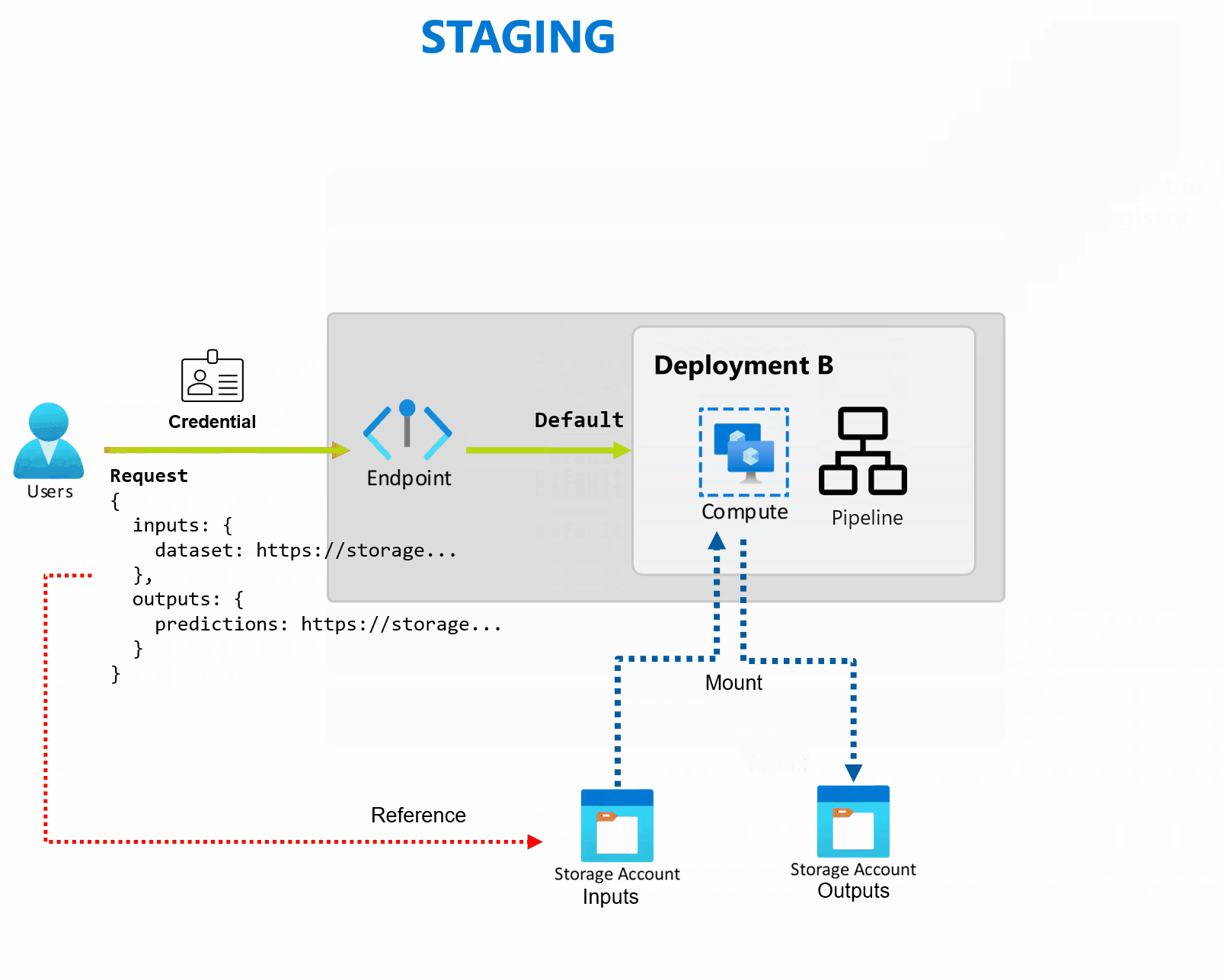
유연한 데이터 원본 및 스토리지
Batch 엔드포인트는 스토리지에서 직접 데이터를 읽고 씁니다. Azure Machine Learning 데이터 저장소, Azure Machine Learning 데이터 자산 또는 스토리지 계정을 입력으로 지정할 수 있습니다. 지원되는 입력 옵션 및 이를 지정하는 방법에 대한 자세한 내용은 일괄 처리 엔드포인트에 대한 작업 및 입력 데이터 만들기를 참조하세요.
보안
일괄 처리 엔드포인트는 엔터프라이즈 설정에서 프로덕션 수준 워크로드를 운영하는 데 필요한 모든 기능을 제공합니다. 보안 작업 공간 및 비공개 네트워킹과 Microsoft Entra 인증을 사용하여 사용자 주체(예: 사용자 계정) 또는 서비스 주체(예: 관리 ID 또는 비관리 ID)를 지원합니다. 일괄 처리 엔드포인트에서 생성된 작업은 호출자의 ID로 실행되므로 모든 시나리오를 유연하게 구현할 수 있습니다. 일괄 처리 엔드포인트를 사용하는 동안 권한 부여에 대한 자세한 내용은 일괄 처리 엔드포인트에서 인증하는 방법을 참조하세요.