프로덕션 유추를 위한 엔드포인트
적용 대상: Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
기계 학습 모델 또는 파이프라인을 학습했거나 모델 카탈로그에서 요구 사항에 맞는 모델을 찾은 경우 다른 사람들이 유추에 사용할 수 있도록 해당 모델을 프로덕션에 배포해야 합니다. 유추는 새로운 입력 데이터를 기계 학습 모델이나 파이프라인에 적용하여 출력을 생성하는 프로세스입니다. 이러한 출력을 일반적으로 "예측"이라고 부르지만 유추를 사용하여 분류 및 클러스터링과 같은 다른 기계 학습 작업에 대한 출력을 생성할 수 있습니다. Azure Machine Learning에서는 엔드포인트를 사용하여 유추를 수행합니다.
엔드포인트 및 배포
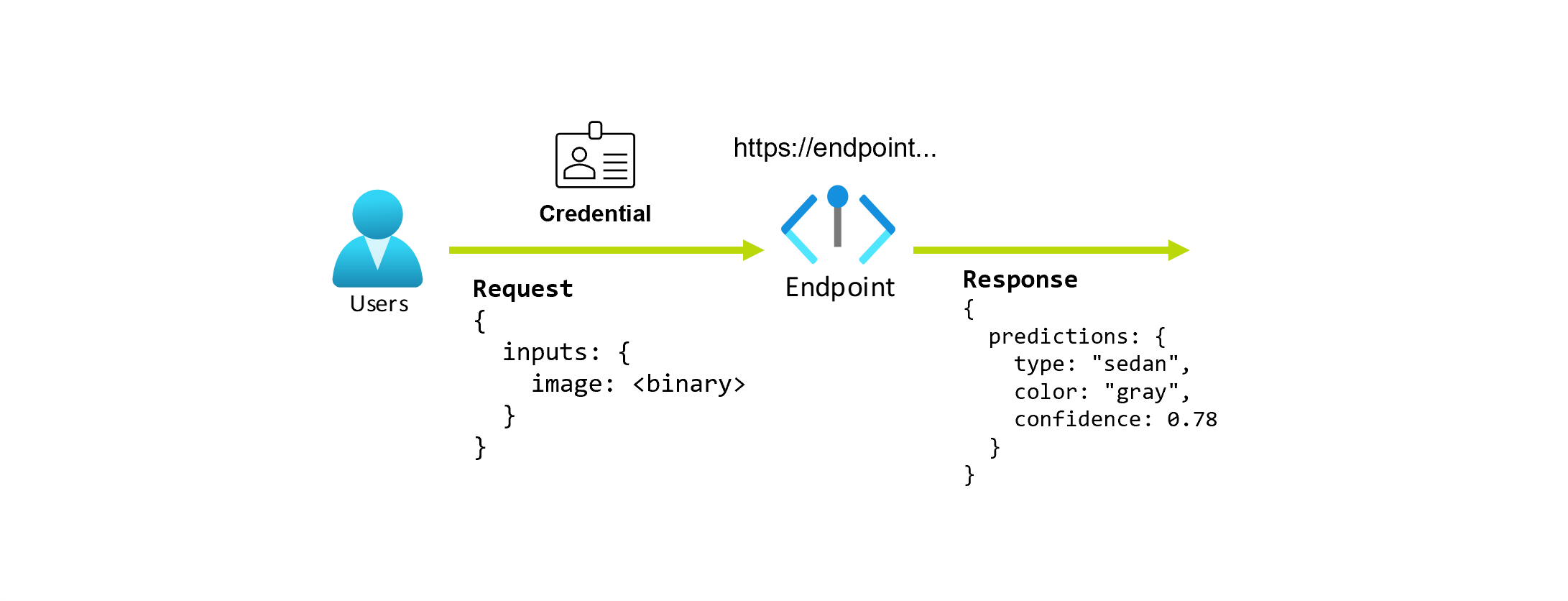
엔드포인트는 모델을 요청하거나 호출하는 데 사용할 수 있는 안정적이고 내구성 있는 URL입니다. 엔드포인트에 필요한 입력을 제공하고 출력을 다시 가져옵니다. Azure Machine Learning을 사용하면 서버리스 API 엔드포인트, 온라인 엔드포인트 및 일괄 처리 엔드포인트를 구현할 수 있습니다. 엔드포인트는 다음을 제공합니다.
- 안정적이고 내구성 있는 URL(예: endpoint-name.region.inference.ml.azure.com)
- 인증 메커니즘, 및
- 권한 부여 메커니즘.
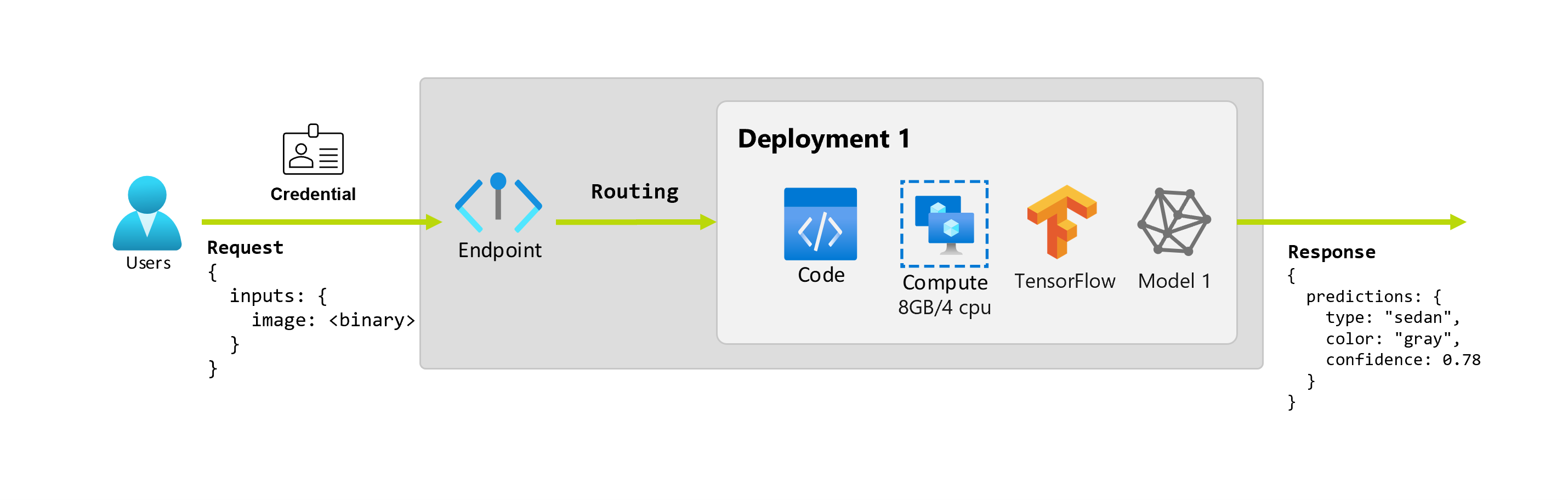
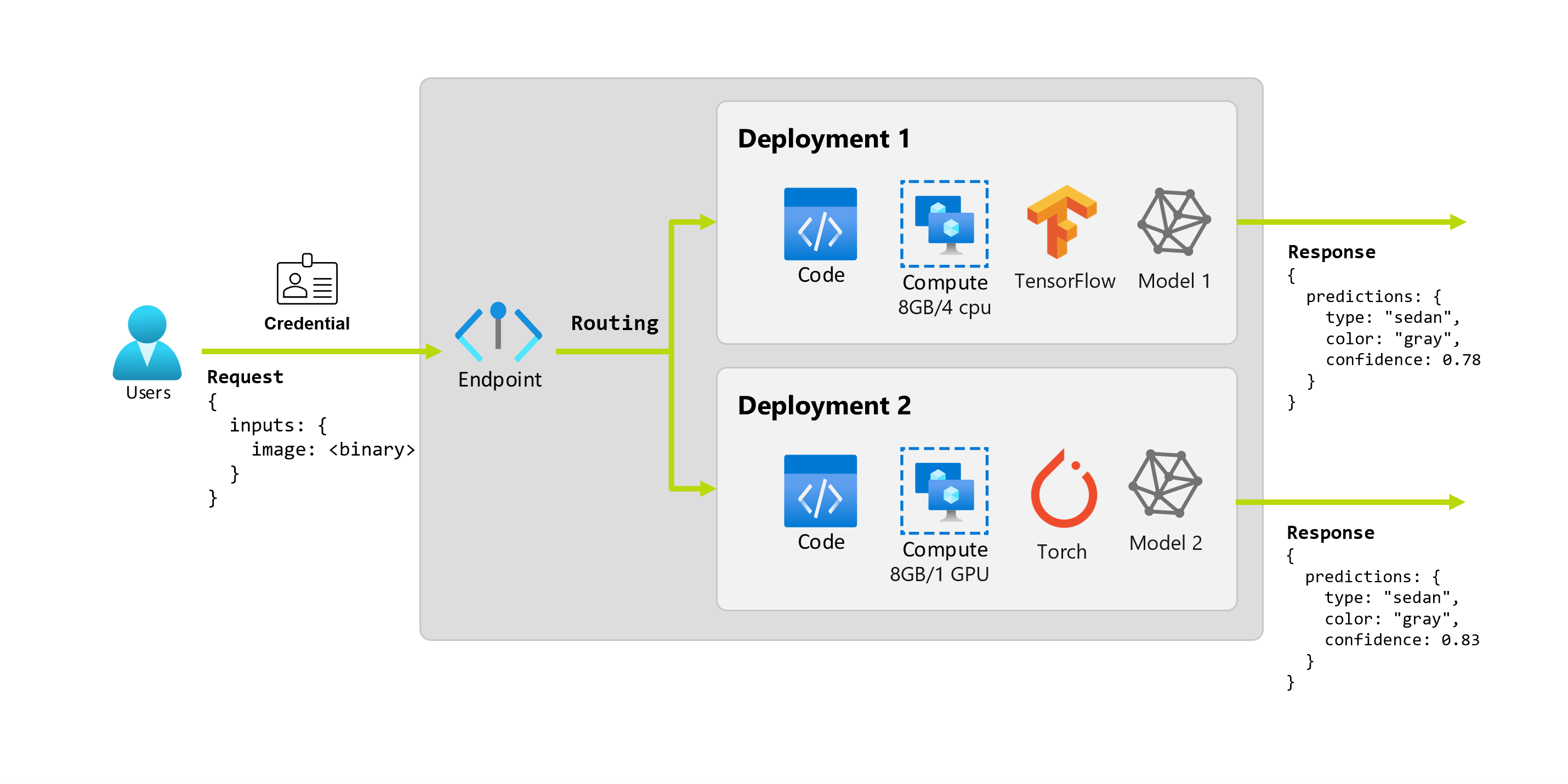
배포는 실제 유추를 수행하는 모델이나 구성 요소를 호스팅하는 데 필요한 리소스 및 컴퓨팅 집합입니다. 엔드포인트에는 배포가 포함되며, 온라인 및 일괄 처리 엔드포인트의 경우 하나의 엔드포인트에 여러 배포가 포함될 수 있습니다. 배포는 독립적인 자산을 호스팅하고 자산의 요구 사항에 따라 다양한 리소스를 소비할 수 있습니다. 또한 엔드포인트에는 요청을 해당 배포로 전달할 수 있는 라우팅 메커니즘이 있습니다.
한편, Azure Machine Learning의 일부 형식의 엔드포인트는 배포 시 전용 리소스를 사용합니다. 이러한 엔드포인트를 실행하려면 Azure 구독에 컴퓨팅 할당량이 있어야 합니다. 반면에 특정 모델은 서버리스 배포를 지원하므로 구독의 할당량을 사용하지 않습니다. 서버리스 배포의 경우 사용량을 기준으로 요금이 청구됩니다.
직관
사진을 바탕으로 자동차의 형식과 색을 예측하는 애플리케이션을 작업 중이라고 가정해 보겠습니다. 이 애플리케이션의 경우 특정 자격 증명을 가진 사용자는 URL에 대한 HTTP 요청을 만들고 요청의 일부로 자동차 사진을 제공합니다. 그 대가로 사용자는 자동차의 형식과 색이 문자열 값으로 포함된 응답을 가져옵니다. 이 시나리오에서는 URL이 엔드포인트 역할을 합니다.
또한 데이터 과학자인 Alice가 애플리케이션 구현 작업을 진행 중이라고 가정해 보겠습니다. Alice는 TensorFlow에 대해 많은 것을 알고 있으며 TensorFlow Hub의 RestNet 아키텍처와 함께 Keras 순차 분류자를 사용하여 모델을 구현하기로 결정했습니다. 모델을 테스트한 후 Alice는 결과에 만족하고 모델을 사용하여 자동차 예측 문제를 해결하기로 결정합니다. 이 모델은 크기가 크며 실행하려면 4개의 코어가 있는 8GB의 메모리가 필요합니다. 이 시나리오에서는 Alice의 모델과 모델을 실행하는 데 필요한 리소스(예: 코드, 컴퓨팅)가 엔드포인트 아래 배포를 구성합니다.
몇 달 후에 조직에서 이상적인 조명 조건이 아닌 이미지에서는 애플리케이션의 성능이 저하된다는 사실을 발견했다고 가정해 보겠습니다. 또 다른 데이터 과학자인 Bob은 모델이 해당 요소에 대한 견고성을 빌드하는 데 도움이 되는 데이터 증대 기술에 대해 많은 것을 알고 있습니다. 그러나 Bob은 Torch를 사용하여 모델을 구현하는 것이 더 편하다고 느끼고 Torch를 사용하여 새 모델을 학습합니다. Bob은 조직에서 이전 모델을 사용 중지할 준비가 될 때까지 프로덕션에서 이 모델을 점진적으로 시도하려고 합니다. 또한 새 모델은 GPU에 배포했을 때 더 나은 성능을 보여 주므로 배포에는 GPU가 포함되어야 합니다. 이 시나리오에서는 모델을 실행하는 데 필요한 Bob의 모델과 리소스(예: 코드, 컴퓨팅)가 동일한 엔드포인트 아래에 또 다른 배포를 구성합니다.
엔드포인트: 서버리스 API, 온라인 및 일괄 처리
Azure Machine Learning을 사용하면 서버리스 API 엔드포인트, 온라인 엔드포인트 및 일괄 처리 엔드포인트를 구현할 수 있습니다.
서버리스 API 엔드포인트 및 온라인 엔드포인트는 실시간 유추를 위해 설계되었습니다. 엔드포인트를 호출할 때마다 결과가 엔드포인트의 응답으로 반환됩니다. 서버리스 API 엔드포인트는 구독의 할당량을 사용하지 않습니다. 오히려 종량제 청구로 청구됩니다.
일괄 처리 엔드포인트는 장기 실행 Batch 유추를 위해 설계되었습니다. 일괄 처리 엔드포인트를 호출할 때마다 실제 작업을 수행하는 일괄 작업을 생성합니다.
서버리스 API, 온라인 및 일괄 처리 엔드포인트를 사용하는 경우
서버리스 API 엔드포인트:
서버리스 API 엔드포인트를 사용하면 상업용품 실시간 유추이나 이러한 모델의 미세 조정을 위해 대규모 기본 모델을 사용할 수 있습니다. 모든 모델을 서버리스 API 엔드포인트에 배포할 수 있는 것은 아닙니다. 다음과 같은 경우 이 배포 모드를 사용하는 것이 좋습니다.
- 사용자의 모델은 기본 모델이거나 서버리스 API 배포에 사용할 수 있는 기본 모델의 미세 조정된 버전입니다.
- 할당량이 없는 배포의 이점을 활용할 수 있습니다.
- 모델을 실행하는 데 사용되는 유추 스택을 사용자 지정할 필요가 없습니다.
온라인 엔드포인트:
온라인 엔드포인트를 사용하여 대기 시간이 짧은 동기식 요청에서 실시간 유추를 위한 모델을 운용합니다. 다음과 같은 경우에 사용하는 것이 좋습니다.
- 사용자의 모델은 기초 모델이거나 기초 모델의 미세 조정 버전이지만 서버리스 API 엔드포인트에서는 지원되지 않습니다.
- 짧은 대기 시간 요구 사항이 있습니다.
- 모델은 비교적 짧은 시간 내에 요청에 답변할 수 있습니다.
- 모델의 입력이 요청의 HTTP 페이로드에 맞습니다.
- 요청 수 측면에서 스케일 업해야 합니다.
일괄 처리 엔드포인트:
장기 실행 비동기 유추를 위해 일괄 처리 엔드포인트를 사용하여 모델 또는 파이프라인을 운용할 수 있습니다. 다음과 같은 경우에 사용하는 것이 좋습니다.
- 실행하는 데 더 오랜 시간이 필요한 비용이 많이 드는 모델이나 파이프라인이 있습니다.
- 기계 학습 파이프라인을 운용하고 구성 요소를 재사용하려고 합니다.
- 여러 파일에 분산되어 있는 대량의 데이터에 대해 유추를 수행해야 합니다.
- 낮은 대기 시간 요구 사항이 없습니다.
- 모델의 입력은 스토리지 계정 또는 Azure Machine Learning 데이터 자산에 저장됩니다.
- 병렬 처리를 활용할 수 있습니다.
서버리스 API, 온라인 및 일괄 처리 엔드포인트 비교
모든 서버리스 API, 온라인 및 일괄 처리 엔드포인트는 엔드포인트 개념을 기반으로 하므로 한 엔드포인트에서 다른 엔드포인트로 쉽게 전환할 수 있습니다. 온라인 및 일괄 처리 엔드포인트는 동일한 엔드포인트에 대한 여러 배포를 관리할 수도 있습니다.
끝점
다음 표에는 엔드포인트 수준에서 서버리스 API, 온라인 및 일괄 처리 엔드포인트에 사용할 수 있는 다양한 기능이 요약되어 있습니다.
| 기능 | 서버리스 API 엔드포인트 | 온라인 엔드포인트 | 일괄 처리 엔드포인트 |
|---|---|---|---|
| 안정적인 호출 URL | 예 | 예 | 예 |
| 다중 배포 지원 | 예 | 예 | 예 |
| 배포 라우팅 | None | 트래픽 분할 | 기본값으로 전환 |
| 안전한 출시를 위한 트래픽 미러링 | 예 | 네 | 아니요 |
| Swagger 지원 | 예 | 예 | 아니요 |
| 인증 | 키 | 키 및 Microsoft Entra ID(미리 보기) | Microsoft Entra ID |
| 개인 네트워크 지원(레거시) | 예 | 예 | 예 |
| 관리되는 네트워크 격리 | 예 | 예 | 예 (필요한 추가 구성 참조) |
| 고객 관리형 키 | 해당 없음 | 예 | 예 |
| 비용 기준 | 엔드포인트당, 분당1 | None | None |
1서버리스 API 엔드포인트에는 분당 약간의 요금이 부과됩니다. 토큰별로 청구되는 사용량 관련 요금은 배포 섹션을 참조하세요.
배포
다음 표에는 배포 수준에서 서버리스 API, 온라인 및 일괄 처리 엔드포인트에 사용할 수 있는 다양한 기능이 요약되어 있습니다. 이러한 개념은 엔드포인트 아래의 각 배포(온라인 및 일괄 처리 엔드포인트의 경우)에 적용되며 서버리스 API 엔드포인트(배포 개념이 엔드포인트에 기본 제공되어 있음)에 적용됩니다.
| 기능 | 서버리스 API 엔드포인트 | 온라인 엔드포인트 | 일괄 처리 엔드포인트 |
|---|---|---|---|
| 배포 형식 | 모델 | 모델 | 모델 및 파이프라인 구성 요소 |
| MLflow 모델 배포 | 아니요, 카탈로그의 특정 모델만 해당됩니다. | 예 | 예 |
| 사용자 지정 모델 배포 | 아니요, 카탈로그의 특정 모델만 해당됩니다. | 예, 채점 스크립트 포함 | 예, 채점 스크립트 포함 |
| 모델 패키지 배포 2 | 기본 제공 | 예(미리 보기) | 아니요 |
| 유추 서버 3 | Azure AI 모델 유추 API | - Azure Machine Learning 유추 서버 - Triton - 사용자 지정(BYOC 사용) |
Batch 유추 |
| 사용된 컴퓨팅 리소스 | 없음(서버리스) | 인스턴스 또는 세분화된 리소스 | 클러스터 인스턴스 |
| 컴퓨팅 형식 | 없음(서버리스) | 관리 컴퓨팅 및 Kubernetes | 관리 컴퓨팅 및 Kubernetes |
| 우선 순위가 낮은 컴퓨팅 | 해당 없음 | 예 | 예 |
| 컴퓨팅을 0으로 크기 조정 | 기본 제공 | 예 | 예 |
| 자동 크기 조정 컴퓨팅4 | 기본 제공 | 예, 리소스 사용 기준 | 예, 작업 수 기준 |
| 과잉 용량 관리 | 제한 | 제한 | 대기 중 |
| 비용 기준5 | 토큰당 | 배포별: 실행 중인 컴퓨팅 인스턴스 | 작업당: 작업에서 소비되는 컴퓨팅 인스턴스(클러스터의 최대 인스턴스 수로 제한됨) |
| 배포의 로컬 테스트 | 예 | 네 | 아니요 |
2 아웃바운드 인터넷 연결 또는 개인 네트워크 없이 엔드포인트에 MLflow 모델을 배포하려면 먼저 모델을 패키징해야 합니다.
3 유추 서버는 요청을 받아 처리하고 응답을 만드는 제공 기술을 의미합니다. 유추 서버는 입력 형식과 예상 출력 형식도 지정합니다.
4 자동 크기 조정은 로드에 따라 배포에 할당된 리소스를 동적으로 스케일 업하거나 스케일 다운하는 기능입니다. 온라인 및 일괄 처리 배포는 자동 크기 조정을 위해 서로 다른 전략을 사용합니다. 온라인 배포는 리소스 사용률(예: CPU, 메모리, 요청 등)에 따라 스케일 업 및 스케일 다운되는 반면, 일괄 처리 엔드포인트는 만들어진 작업 수에 따라 스케일 업 또는 스케일 다운됩니다.
5 온라인 배포와 일괄 처리 배포 모두 소비된 리소스에 따라 요금이 청구됩니다. 온라인 배포에서는 배포 시 리소스가 프로비전됩니다. 일괄 처리 배포에서는 배포 시 리소스가 소비되지 않고 작업이 실행될 때 리소스가 사용됩니다. 따라서 일괄 처리 배포 자체와 관련된 비용은 없습니다. 마찬가지로 대기 중인 작업도 리소스를 사용하지 않습니다.
개발자 인터페이스
엔드포인트는 조직이 Azure Machine Learning에서 프로덕션 수준 워크로드를 운용하는 데 도움을 주기 위해 설계되었습니다. 엔드포인트는 강력하고 확장성 있는 리소스이며 MLOps 워크플로를 구현하는 데 최고의 기능을 제공합니다.
여러 개발자 도구를 사용하여 일괄 처리 및 온라인 엔드포인트를 만들고 관리할 수 있습니다.
- Azure CLI 및 Python SDK
- Azure Resource Manager/REST API
- Azure Machine Learning 스튜디오 웹 포털
- Azure Portal(IT/관리자)
- Azure CLI 인터페이스 및 REST/ARM 인터페이스를 사용하여 CI/CD MLOps 파이프라인 지원