AutoML 및 Python을 사용하여 회귀 모델 학습(SDK v1)
적용 대상: Python SDK azureml v1
Python SDK azureml v1
이 문서에서는 Azure Machine Learning 자동화된 ML을 사용하여 Azure Machine Learning Python SDK를 통해 회귀 모델을 학습하는 방법에 대해 알아봅니다. 이 회귀 모델은 NYC 택시 요금을 예측합니다.
이 프로세스는 학습 데이터 및 구성 설정을 적용하며 다양한 기능 정규화/표준화 메서드, 모델 및 하이퍼 매개 변수 설정의 결합을 자동으로 반복하여 최선의 모델에 도달합니다.
이 문서에서는 Python SDK를 사용하여 코드를 작성합니다. 다음 작업에 대해 알아봅니다.
- Azure Open Datasets를 사용하여 데이터 다운로드, 변환 및 지우기
- 자동화된 기계 학습 회귀 모델 학습
- 모델 정확도 계산
코드 없는 AutoML의 경우 다음 자습서를 사용해 보세요.
필수 조건
Azure 구독이 없는 경우 시작하기 전에 체험 계정을 만듭니다. 지금 Azure Machine Learning 평가판 또는 유료 버전을 사용해 보세요.
- Azure Machine Learning 작업 영역이나 컴퓨팅 인스턴스가 아직 없는 경우 빠른 시작: Azure Machine Learning 시작을 완료합니다.
- 빠른 시작을 완료한 후:
- 스튜디오에서 Notebooks를 선택합니다.
- 샘플 탭을 선택합니다.
- SDK v1/tutorials/regression-automl-nyc-taxi-data/regression-automated-ml.ipynb Notebook을 엽니다.
- 자습서의 각 셀을 실행하려면 이 Notebook 복제를 선택합니다.
이 문서는 GitHub에도 제공되기 때문에 자체 로컬 환경에서도 실행할 수 있습니다. 필요한 패키지를 가져오려면
- 전체
automl클라이언트를 설치합니다. pip install azureml-opendatasets azureml-widgets을 실행하여 필요한 패키지를 가져옵니다.
데이터 다운로드 및 준비
필요한 패키지를 가져옵니다. Open Datasets 패키지는 다운로드하기 전에 필터 날짜 매개 변수를 쉽게 필터링하기 위해 각 데이터 원본(예: NycTlcGreen)을 표시하는 클래스를 포함합니다.
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
먼저 택시 데이터를 저장할 데이터 프레임을 만듭니다. Spark 이외의 환경에서 작업하는 경우 Open Datasets는 큰 데이터 세트와 관련된 MemoryError를 방지하기 위해 특정 클래스를 사용하여 한 번에 1개월 분량의 데이터만 다운로드할 수 있습니다.
택시 데이터를 다운로드하려면 데이터 프레임의 급격한 증가를 방지하기 위해 한 번에 1개월 분량씩 반복해서 가져오고 green_taxi_df에 추가하기 전에 각 월 데이터에서 레코드 2000개를 임의로 샘플링합니다. 그런 다음, 데이터를 미리 봅니다.
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
| vendorID | lpepPickupDatetime | lpepDropoffDatetime | passengerCount | tripDistance | puLocationId | doLocationId | pickupLongitude | pickupLatitude | dropoffLongitude | ... | paymentType | fareAmount | extra | mtaTax | improvementSurcharge | tipAmount | tollsAmount | ehailFee | totalAmount | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 131969 | 2 | 2015-01-11 05:34:44 | 2015-01-11 05:45:03 | 3 | 4.84 | 없음 | 없음 | -73.88 | 40.84 | -73.94 | ... | 2 | 15.00 | 0.50 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 16.30 |
| 1129817 | 2 | 2015-01-20 16:26:29 | 2015-01-20 16:30:26 | 1 | 0.69 | 없음 | 없음 | -73.96 | 40.81 | -73.96 | ... | 2 | 4.50 | 1.00 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 6.30 |
| 1278620 | 2 | 2015-01-01 05:58:10 | 2015-01-01 06:00:55 | 1 | 0.45 | 없음 | 없음 | -73.92 | 40.76 | -73.91 | ... | 2 | 4.00 | 0.00 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 4.80 |
| 348430 | 2 | 2015-01-17 02:20:50 | 2015-01-17 02:41:38 | 1 | 0.00 | 없음 | 없음 | -73.81 | 40.70 | -73.82 | ... | 2 | 12.50 | 0.50 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 13.80 |
| 1269627 | 1 | 2015-01-01 05:04:10 | 2015-01-01 05:06:23 | 1 | 0.50 | 없음 | 없음 | -73.92 | 40.76 | -73.92 | ... | 2 | 4.00 | 0.50 | 0.50 | 0 | 0.00 | 0.00 | nan | 5.00 |
| 811755 | 1 | 2015-01-04 19:57:51 | 2015-01-04 20:05:45 | 2 | 1.10 | 없음 | 없음 | -73.96 | 40.72 | -73.95 | ... | 2 | 6.50 | 0.50 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 7.80 |
| 737281 | 1 | 2015-01-03 12:27:31 | 2015-01-03 12:33:52 | 1 | 0.90 | 없음 | 없음 | -73.88 | 40.76 | -73.87 | ... | 2 | 6.00 | 0.00 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 6.80 |
| 113951 | 1 | 2015-01-09 23:25:51 | 2015-01-09 23:39:52 | 1 | 3.30 | 없음 | 없음 | -73.96 | 40.72 | -73.91 | ... | 2 | 12.50 | 0.50 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 13.80 |
| 150436 | 2 | 2015-01-11 17:15:14 | 2015-01-11 17:22:57 | 1 | 1.19 | 없음 | 없음 | -73.94 | 40.71 | -73.95 | ... | 1 | 7.00 | 0.00 | 0.50 | 0.3 | 1.75 | 0.00 | nan | 9.55 |
| 432136 | 2 | 2015-01-22 23:16:33 2015-01-22 23:20:13 1 0.65 | 없음 | 없음 | -73.94 | 40.71 | -73.94 | ... | 2 | 5.00 | 0.50 | 0.50 | 0.3 | 0.00 | 0.00 | nan | 6.30 |
학습 또는 기타 기능 만들기에 필요하지 않은 열을 제거합니다. 기계 학습 자동화는 lpepPickupDatetime과 같은 시간 기반 기능을 자동으로 처리합니다.
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
데이터 정리
새 데이터 프레임에 대해 describe() 함수를 실행하고 각 필드에 대한 요약 통계를 확인합니다.
green_taxi_df.describe()
| vendorID | passengerCount | tripDistance | pickupLongitude | pickupLatitude | dropoffLongitude | dropoffLatitude | totalAmount | month_num day_of_month | day_of_week | hour_of_day |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 | 48000.00 |
| 평균 | 1.78 | 1.37 | 2.87 | -73.83 | 40.69 | -73.84 | 40.70 | 14.75 | 6.50 | 15.13 |
| std | 0.41 | 1.04 | 2.93 | 2.76 | 1.52 | 2.61 | 1.44 | 12.08 | 3.45 | 8.45 |
| min | 1.00 | 0.00 | 0.00 | -74.66 | 0.00 | -74.66 | 0.00 | -300.00 | 1.00 | 1.00 |
| 25% | 2.00 | 1.00 | 1.06 | -73.96 | 40.70 | -73.97 | 40.70 | 7.80 | 3.75 | 8.00 |
| 50% | 2.00 | 1.00 | 1.90 | -73.94 | 40.75 | -73.94 | 40.75 | 11.30 | 6.50 | 15.00 |
| 75% | 2.00 | 1.00 | 3.60 | -73.92 | 40.80 | -73.91 | 40.79 | 17.80 | 9.25 | 22.00 |
| 최대 | 2.00 | 9.00 | 97.57 | 0.00 | 41.93 | 0.00 | 41.94 | 450.00 | 12.00 | 30.00 |
요약 통계에서 이상값 또는 모델 정확도를 떨어뜨리는 값을 포함하는 여러 필드가 있음을 알 수 있습니다. 먼저 맨해튼 지역의 경계 내에 있도록 위도/경도 필드를 필터링합니다. 이렇게 하면 장거리 택시 여행이나 다른 특징과 관련된 이상치인 여행을 필터링합니다.
또한 tripDistance 필드가 0보다 크고 31마일(두 위도/경도 쌍 사이의 Haversine 거리) 미만이 되도록 필터링합니다. 이렇게 하면 운행 비용에 일관성이 없는 장거리 이상치 운행이 제외됩니다.
마지막으로 totalAmount 필드에 있는 음수 값의 택시 요금은 현재 모델에는 타당하지 않고, passengerCount 필드에는 최솟값이 0인 잘못된 데이터가 있습니다.
쿼리 함수를 사용하여 이러한 이상값을 필터링한 다음, 학습에 불필요한 마지막 몇 개의 열을 제거합니다.
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
데이터에 대해 describe()를 다시 호출하여 정리가 필요한 대로 작동했는지 확인합니다. 이제 기계 학습 모델 학습에 사용할 택시, 휴일 및 기상 데이터 세트를 준비하고 정리했습니다.
final_df.describe()
작업 영역 구성
기존 작업 영역에서 작업 영역 개체를 만듭니다. Workspace는 Azure 구독 및 리소스 정보를 허용하는 클래스입니다. 또한 클라우드 리소스를 만들어서 모델 실행을 모니터링하고 추적합니다. Workspace.from_config()는 config.json 파일을 읽어 ws라는 개체에 인증 세부 정보를 로드합니다. ws는 이 문서에서 나머지 코드에 사용됩니다.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
학습 및 테스트 세트로 데이터 분할
scikit-learn 라이브러리에서 train_test_split 함수를 사용하여 데이터를 학습 및 테스트 세트로 분할합니다. 이 함수는 데이터를 모델 학습용 x(기능) 데이터 세트 및 테스트용 y(예측 값) 데이터 세트로 분리합니다.
test_size 매개 변수는 테스트에 할당할 데이터 백분율을 정의합니다. random_state 매개 변수는 학습-테스트 분할이 결정적이 되도록 임의 생성기에 시드를 설정합니다.
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
이 단계의 목적은 데이터 요소에서 실제 정확도를 측정하기 위해 모델 학습에 사용되지 않은 완료된 모델을 테스트하는 것입니다.
즉, 잘 학습된 모델은 아직 확인되지 않은 데이터에서 정확한 예측을 수행할 수 있어야 합니다. 이제 기계 학습 모델을 자동 학습할 데이터가 준비되었습니다.
자동으로 모델 학습
자동으로 모델을 학습하려면 다음 단계를 수행합니다.
- 실험 실행을 위한 설정 정의 학습 데이터를 구성에 연결하고, 학습 프로세스를 제어하는 설정을 수정합니다.
- 모델 튜닝을 위한 실험 제출 실험을 제출한 후 프로세스는 다른 기계 학습 알고리즘 및 하이퍼 매개 변수 설정을 반복하여 정의된 제약 조건을 준수합니다. 정확도 메트릭을 최적화하여 가장 적합한 모델을 선택합니다.
학습 설정 정의
학습을 위해 실험 매개 변수 및 모델 설정을 정의합니다. 설정의 전체 목록을 확인합니다. 이러한 기본 설정을 사용하여 실험을 제출하는 데 약 5~20분이 걸리지만 짧은 실행 시간을 원하는 경우 experiment_timeout_hours 매개 변수를 줄입니다.
| 속성 | 이 문서의 값 | 설명 |
|---|---|---|
| iteration_timeout_minutes | 10 | 각 반복에 대한 분 단위 시간 제한 각 반복에 더 많은 시간이 필요한 대규모 데이터 세트의 경우 이 값을 늘립니다. |
| experiment_timeout_hours | 0.3 | 실험을 종료하기까지 모든 반복 조합에 소요되는 최대 시간(시간)입니다. |
| enable_early_stopping | True | 점수가 단기간에 개선되지 않는 경우 조기 종료를 활성화하는 플래그입니다. |
| primary_metric | spearman_correlation | 최적화하려는 메트릭입니다. 이 메트릭에 따라 최적화된 모델이 선택됩니다. |
| 기능화 | auto | auto를 사용하면 실험은 입력 데이터를 전처리할 수 있습니다(누락 데이터 처리, 텍스트를 숫자로 변환 등). |
| verbosity | logging.INFO | 로깅 수준을 제어합니다. |
| n_cross_validations | 5 | 유효성 검사 데이터가 지정되지 않은 경우 수행할 교차 유효성 검사 분할 수입니다. |
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
AutoMLConfig 개체에 대한 **kwargs 매개 변수로 정의된 학습 설정을 사용합니다. 또한 학습 데이터 및 모델의 유형을 지정합니다. 이 경우 regression입니다.
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
참고 항목
자동화된 기계 학습 사전 처리 단계(기능 정규화, 누락된 데이터 처리, 텍스트를 숫자로 변환 등)는 기본 모델의 일부가 됩니다. 예측에 모델을 사용하는 경우 학습 중에 적용되는 동일한 전처리 단계가 입력 데이터에 자동으로 적용됩니다.
자동 회귀 모델 학습
작업 영역에 실험 개체를 만듭니다. 실험은 개별 작업에 대한 컨테이너 역할을 합니다. 정의된 automl_config 개체를 실험에 전달하고 출력을 True로 설정하여 작업 중 진행률을 확인합니다.
실험을 시작한 후에 표시되는 출력은 실험이 실행됨에 따라 실시간으로 업데이트됩니다. 각 반복의 경우 모델 유형, 실행 지속 및 학습 정확도가 표시됩니다. 필드 BEST는 메트릭 유형에 따라 최적의 실행 학습 점수를 추적합니다.
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
결과 탐색
Jupyter 위젯을 통해 자동 학습 결과를 살펴봅니다. 위젯을 사용하면 모든 개별 작업 반복에 대한 그래프와 테이블을 학습 정확도 메트릭 및 메타데이터와 함께 볼 수 있습니다. 또한 드롭다운 선택기를 사용하면 기본 메트릭과 다른 정확도 메트릭을 필터링할 수 있습니다.
from azureml.widgets import RunDetails
RunDetails(local_run).show()
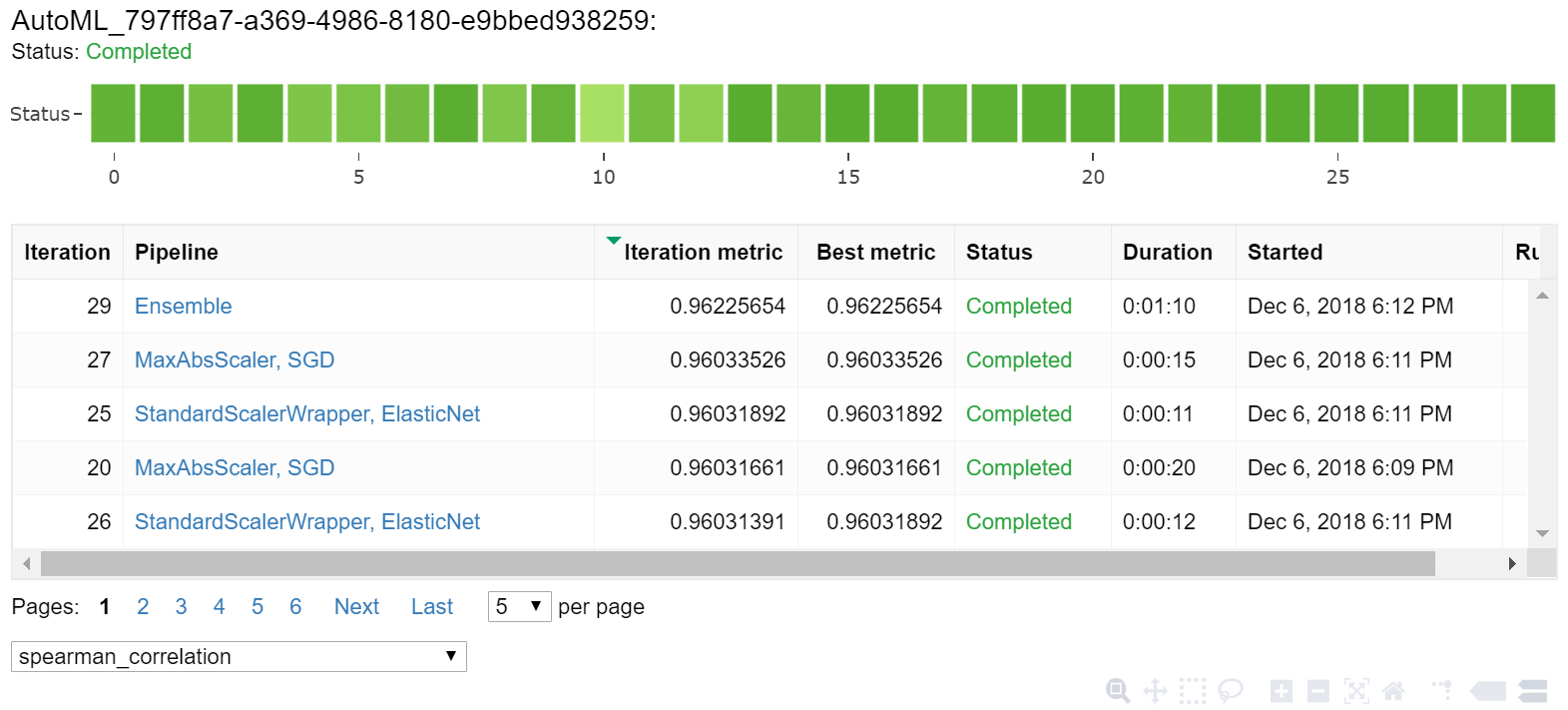
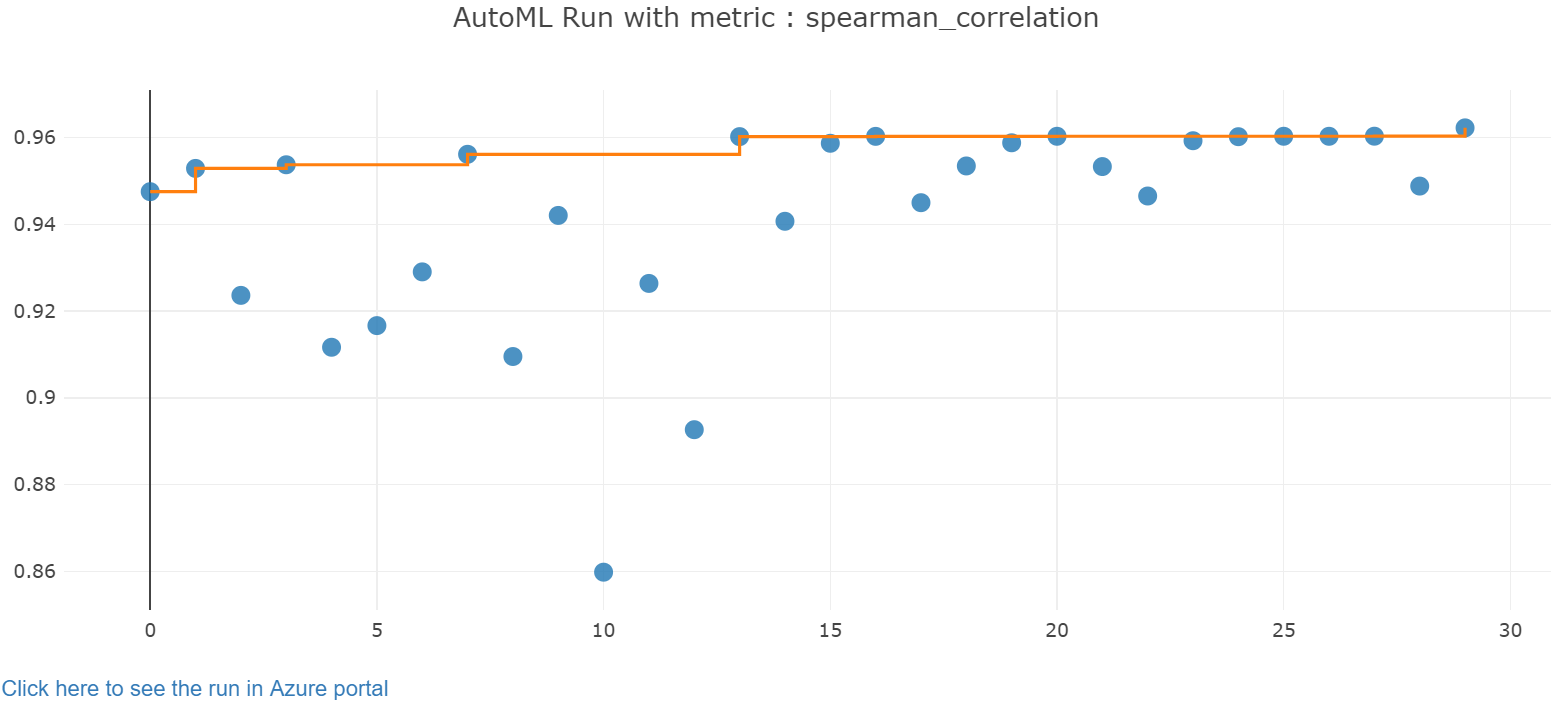
최적 모델 검색
반복에서 가장 적합한 모델을 선택합니다. get_output 함수는 마지막 맞춤 호출에 대한 최적의 실행 및 맞춤 모델을 반환합니다. get_output에 대한 오버로드를 사용하면 기록된 메트릭 또는 특정 반복에 대한 최적의 실행 및 맞춤 모델을 검색할 수 있습니다.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
최적 모델 정확도 테스트
최적 모델을 사용하여 테스트 데이터 세트에서 예측을 실행하여 택시 요금을 예측합니다. predict 함수는 최적 모델을 사용하고 x_test 데이터 세트에서 y(운행 비용) 값을 예측합니다. y_predict에서 첫 10개의 예측 비용 값을 인쇄합니다.
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
결과의 root mean squared error를 계산합니다. y_test 데이터 프레임을 목록으로 변환하여 예측 값과 비교합니다. mean_squared_error 함수는 두 개의 값 배열을 사용하고 두 배열 간의 평균 제곱 오차를 계산합니다. 결과의 제곱근을 구하면 y 변수(비용)와 동일한 단위에서 오류가 나타납니다. 택시 요금 예측이 실제 요금과 대략 어느 정도 차이가 있는지를 나타냅니다.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
전체 y_actual 및 y_predict 데이터 세트를 사용하여 MAPE(절대 평균 백분율 오차)를 계산하려면 다음 코드를 실행합니다. 이 메트릭은 각 예측 및 실제 값 사이 절대값 차이를 계산하며 모든 차이를 합산합니다. 그런 다음, 실제 값의 합계에 대한 백분율로 해당 합산을 표시합니다.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
두 개의 예측 정확도 메트릭을 통해, 모델이 데이터 세트의 특징으로부터 택시 요금을 예측하는 데 상당히 우수하다는 것을 알 수 있습니다(일반적으로 +- $4.00 이내, 오류율 약 15%).
기존의 Machine Learning 모델 개발 프로세스는 리소스가 상당히 많이 필요하며, 수십 가지 모델을 실행하고 결과를 비교하는 데 많은 도메인 지식과 시간이 필요합니다. 자동화된 기계 학습을 사용하는 것은 시나리오에 대한 다른 여러 모델을 신속하게 테스트하는 좋은 방법입니다.
리소스 정리
다른 Azure Machine Learning 자습서를 실행하려면 이 섹션을 완료하지 마세요.
컴퓨팅 인스턴스 중지
컴퓨팅 인스턴스를 사용한 경우 사용하지 않을 때는 해당 VM을 중지하여 비용을 절감합니다.
작업 영역에서 컴퓨팅을 선택합니다.
목록에서 컴퓨팅 인스턴스의 이름을 선택합니다.
중지를 선택합니다.
서버를 다시 사용할 준비가 되면 시작을 선택합니다.
모든 항목 삭제
자신이 만든 리소스를 사용하지 않으려는 경우 요금이 발생하지 않도록 삭제하세요.
- Azure Portal 맨 왼쪽에서 리소스 그룹을 선택합니다.
- 목록에서 만든 리소스 그룹을 선택합니다.
- 리소스 그룹 삭제를 선택합니다.
- 리소스 그룹 이름을 입력합니다. 그런 다음 삭제를 선택합니다.
또한 리소스 그룹을 유지하면서 단일 작업 영역을 삭제할 수도 있습니다. 작업 영역 속성을 표시하고 삭제를 선택합니다.
다음 단계
이 자동화된 Machine Learning 자습서에서 다음 작업을 수행했습니다.
- 작업 영역을 구성하고 실험을 위해 데이터를 준비했습니다.
- 사용자 지정 매개 변수를 통해 로컬로 자동화된 회귀 모델 사용을 학습했습니다.
- 학습 결과를 탐색하고 검토했습니다.