Azure Machine Learning SDK를 사용하여 기계 학습 파이프라인 만들기 및 실행
적용 대상: Python SDK azureml v1
Python SDK azureml v1
이 문서에서는 Azure Machine Learning SDK를 사용하여 기계 학습 파이프라인을 만들고 실행하는 방법을 알아봅니다. ML 파이프라인을 사용하여 다양한 ML 단계를 함께 연결하는 워크플로를 만듭니다. 그런 다음 나중에 액세스하거나 다른 사용자와 공유할 수 있도록 해당 파이프라인을 게시합니다. ML 파이프라인을 추적하여 모델이 실제 세계에서 어떻게 작동하는지 확인하고 데이터 드리프트를 탐지합니다. ML 파이프라인은 다양한 컴퓨팅을 사용하고 단계를 다시 실행하는 대신 재사용하고 다른 사용자와 ML 워크플로를 공유하는 일괄 처리 채점 시나리오에 적합합니다.
이 문서는 자습서가 아닙니다. 첫 번째 파이프라인을 만드는 방법에 관한 참고 자료는 자습서: 일괄 채점을 위한 Azure Machine Learning 파이프라인 빌드 또는 Python의 Azure Machine Learning 파이프라인에서 자동화된 ML 사용을 참조하세요.
ML 작업의 CI/CD 자동화를 위해 Azure 파이프라인이라는 다른 종류의 파이프라인을 사용할 수 있지만 해당 형식의 파이프라인은 작업 영역에 저장되지 않습니다. 다른 파이프라인을 비교합니다.
만든 ML 파이프라인은 Azure Machine Learning 작업 영역의 구성원에게 표시됩니다.
ML 파이프라인은 컴퓨팅 대상에서 실행됩니다(Azure Machine Learning에서 컴퓨팅 대상의 개념참조). 파이프라인은 지원되는 Azure Storage 위치에서 데이터를 읽고 쓸 수 있습니다.
Azure 구독이 없는 경우 시작하기 전에 체험 계정을 만듭니다. Azure Machine Learning 평가판 또는 유료 버전을 사용해 보세요.
필수 조건
Azure Machine Learning 작업 영역 작업 영역 리소스 만들기
Azure Machine Learning SDK를 설치하거나 SDK가 이미 설치된 Azure Machine Learning 컴퓨팅 인스턴스를 사용하도록 개발 환경을 구성합니다.
작업 영역을 연결하여 시작합니다.
import azureml.core
from azureml.core import Workspace, Datastore
ws = Workspace.from_config()
기계 학습 리소스 설정
ML 파이프라인을 실행하는 데 필요한 리소스를 만듭니다.
파이프라인 단계에서 필요한 데이터에 액세스하는 데 사용되는 데이터 저장소를 설정합니다.
데이터 저장소에 상주하거나 여기서 액세스할 수 있는 영구 데이터를 가리키도록
Dataset개체를 구성합니다. 파이프라인 단계 간에 전달되는 임시 데이터에 맞게OutputFileDatasetConfig개체를 구성합니다.파이프라인 단계가 실행될 컴퓨팅 대상을 설정합니다.
데이터 저장소 설정
데이터 저장소는 파이프라인에서 액세스할 데이터를 저장합니다. 각 작업 영역마다 기본 데이터 저장소가 있습니다. 추가 데이터 저장소를 등록할 수 있습니다.
작업 영역을 만들 때 Azure Files 및 Azure Blob Storage는 작업 영역에 연결됩니다. Azure Blob Storage에 연결하기 위해 기본 데이터 저장소가 등록됩니다. 자세한 내용은 Azure Files, Azure Blob 또는 Azure Disk를 사용할지 여부 결정을 참조하세요.
# Default datastore
def_data_store = ws.get_default_datastore()
# Get the blob storage associated with the workspace
def_blob_store = Datastore(ws, "workspaceblobstore")
# Get file storage associated with the workspace
def_file_store = Datastore(ws, "workspacefilestore")
일반적으로 단계는 데이터를 사용하고 출력 데이터를 생성합니다. 단계는 모델, 모델과 종속 파일이 있는 디렉터리 또는 임시 데이터와 같은 데이터를 만들 수 있습니다. 그런 다음, 파이프라인의 다른 후속 단계에서 이 데이터를 사용할 수 있습니다. 파이프라인을 데이터에 연결하는 방법에 관한 자세한 내용은 데이터 액세스 방법 및 데이터 세트 등록 방법 문서를 참조하세요.
Dataset 및 OutputFileDatasetConfig 개체를 사용하여 데이터 구성
파이프라인에 데이터를 제공하는 기본 방법은 Dataset 개체입니다. Dataset 개체는 데이터 저장소 또는 웹 URL에 상주하거나 여기서 액세스할 수 있는 데이터를 가리킵니다. Dataset 클래스는 추상이므로 데이터 열이 구분된 하나 이상의 파일에서 생성된 FileDataset(하나 이상의 파일 참조) 또는 TabularDataset의 인스턴스를 만듭니다.
from_files 또는 from_delimited_files와 같은 메서드를 사용하여 Dataset를 만듭니다.
from azureml.core import Dataset
my_dataset = Dataset.File.from_files([(def_blob_store, 'train-images/')])
중간 데이터(또는 단계의 출력)는 OutputFileDatasetConfig 개체로 표시됩니다. output_data1은 단계의 출력으로 생성됩니다. 선택적으로 이 데이터는 register_on_complete를 호출하여 데이터 세트로 등록할 수 있습니다. 한 단계에서 OutputFileDatasetConfig를 만들고 다른 단계에 대한 입력으로 사용하는 경우 단계 간의 데이터 종속성은 파이프라인에서 내재적 실행 순서를 만듭니다.
OutputFileDatasetConfig 개체는 디렉터리를 반환하며 기본적으로 작업 영역의 기본 데이터 저장소에 출력을 씁니다.
from azureml.data import OutputFileDatasetConfig
output_data1 = OutputFileDatasetConfig(destination = (datastore, 'outputdataset/{run-id}'))
output_data_dataset = output_data1.register_on_complete(name = 'prepared_output_data')
Important
OutputFileDatasetConfig를 사용하여 저장된 중간 데이터는 Azure에서 자동으로 삭제되지 않습니다.
파이프라인 실행이 끝날 때 프로그래밍 방식으로 중간 데이터를 삭제하거나, 짧은 데이터 보존 정책이 있는 데이터 저장소를 사용하거나, 정기적으로 수동 정리를 수행해야 합니다.
팁
현재 작업과 관련된 파일만 업로드합니다. 데이터 디렉터리 내에서 파일을 변경하면 다시 사용이 지정된 경우에도 다음에 파이프라인이 실행될 때 단계를 다시 실행하는 이유로 간주됩니다.
컴퓨팅 대상 설정
Azure Machine Learning에서 컴퓨팅(또는 컴퓨팅 대상) 용어는 기계 학습 파이프라인에서 계산 단계를 수행하는 머신 또는 클러스터를 가리킵니다. 컴퓨팅 대상의 전체 목록은 모델 학습을 위한 컴퓨팅 대상을 참조하고 컴퓨팅 대상을 만들어 작업 영역에 연결하는 방법은 컴퓨팅 대상 만들기를 참조하세요. 모델을 학습하든 파이프라인 단계를 실행하든 상관없이 컴퓨팅 대상을 만들고 연결하는 프로세스는 동일합니다. 컴퓨팅 대상을 만들고 연결한 후 파이프라인 단계에서 ComputeTarget 개체를 사용합니다.
Important
컴퓨팅 대상에 대한 관리 작업 수행은 원격 작업 내에서 지원되지 않습니다. 기계 학습 파이프라인은 원격 작업으로 제출되므로 파이프라인 내부에서 컴퓨팅 대상에 관리 작업을 사용하지 마십시오.
Azure Machine Learning 컴퓨팅
단계를 실행하기 위한 Azure Machine Learning 컴퓨팅을 만들 수 있습니다. 다른 컴퓨팅 대상의 코드는 유사하며 형식에 따라 매개 변수가 약간 다릅니다.
from azureml.core.compute import ComputeTarget, AmlCompute
compute_name = "aml-compute"
vm_size = "STANDARD_NC6"
if compute_name in ws.compute_targets:
compute_target = ws.compute_targets[compute_name]
if compute_target and type(compute_target) is AmlCompute:
print('Found compute target: ' + compute_name)
else:
print('Creating a new compute target...')
provisioning_config = AmlCompute.provisioning_configuration(vm_size=vm_size, # STANDARD_NC6 is GPU-enabled
min_nodes=0,
max_nodes=4)
# create the compute target
compute_target = ComputeTarget.create(
ws, compute_name, provisioning_config)
# Can poll for a minimum number of nodes and for a specific timeout.
# If no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(
show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current cluster status, use the 'status' property
print(compute_target.status.serialize())
학습 실행 환경 구성
다음 단계는 원격 학습 실행에 학습 단계에 필요한 모든 종속성이 있는지 확인하는 것입니다. RunConfiguration 개체를 만들고 구성하여 종속성과 런타임 컨텍스트를 설정합니다.
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core import Environment
aml_run_config = RunConfiguration()
# `compute_target` as defined in "Azure Machine Learning compute" section above
aml_run_config.target = compute_target
USE_CURATED_ENV = True
if USE_CURATED_ENV :
curated_environment = Environment.get(workspace=ws, name="AzureML-sklearn-0.24-ubuntu18.04-py37-cpu")
aml_run_config.environment = curated_environment
else:
aml_run_config.environment.python.user_managed_dependencies = False
# Add some packages relied on by data prep step
aml_run_config.environment.python.conda_dependencies = CondaDependencies.create(
conda_packages=['pandas','scikit-learn'],
pip_packages=['azureml-sdk', 'azureml-dataset-runtime[fuse,pandas]'],
pin_sdk_version=False)
위의 코드는 종속성을 처리하는 두 가지 옵션을 보여 줍니다. 표시된 대로 USE_CURATED_ENV = True에서 구성은 큐레이팅된 환경을 기반으로 합니다. 큐레이팅된 환경은 공통된 상호 종속적 라이브러리로 “사전 베이킹”되며 더 빨리 온라인 상태로 전환할 수 있습니다. 큐레이팅된 환경은 Microsoft Container Registry에 미리 빌드된 Docker 이미지를 포함합니다. 자세한 내용은 Azure Machine Learning 큐레이팅된 환경을 참조하세요.
USE_CURATED_ENV를 False로 변경한 경우 사용되는 경로는 종속성을 명시적으로 설정하기 위한 패턴을 보여 줍니다. 이 시나리오에서 새로운 사용자 지정 Docker 이미지가 생성되고 리소스 그룹 내의 Azure Container Registry에 등록됩니다(Azure의 프라이빗 Docker 컨테이너 레지스트리 소개 참조). 이 이미지를 빌드하고 등록하려면 몇 분 정도 걸릴 수 있습니다.
파이프라인 단계 구성
컴퓨팅 리소스와 환경을 만들었으면 파이프라인의 단계를 정의할 준비가 된 것입니다. azureml.pipeline.steps 패키지에 대한 참조 문서에서 볼 수 있듯이 Azure Machine Learning SDK를 통해 사용할 수 있는 기본 제공 단계가 많이 있습니다. 가장 유연한 클래스는 Python 스크립트를 실행하는 PythonScriptStep입니다.
from azureml.pipeline.steps import PythonScriptStep
dataprep_source_dir = "./dataprep_src"
entry_point = "prepare.py"
# `my_dataset` as defined above
ds_input = my_dataset.as_named_input('input1')
# `output_data1`, `compute_target`, `aml_run_config` as defined above
data_prep_step = PythonScriptStep(
script_name=entry_point,
source_directory=dataprep_source_dir,
arguments=["--input", ds_input.as_download(), "--output", output_data1],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
위의 코드는 일반적인 초기 파이프라인 단계를 보여 줍니다. 데이터 준비 코드는 하위 디렉터리(이 예에서는 "./dataprep.src" 디렉터리의 "prepare.py")에 있습니다. 파이프라인 만들기 프로세스의 일부로 이 디렉터리는 압축되어 compute_target에 업로드되며 단계는 script_name의 값으로 지정된 스크립트를 실행합니다.
arguments 값은 단계의 입력과 출력을 지정합니다. 위의 예제에서 기준 데이터는 my_dataset 데이터 세트입니다. 코드에서 as_download()로 지정하므로 해당 데이터가 컴퓨팅 리소스로 다운로드됩니다. prepare.py 스크립트는 현재 작업에 적합한 데이터 변환 작업을 수행하고 OutputFileDatasetConfig 형식의 output_data1에 데이터를 출력합니다. 자세한 내용은 ML 파이프라인 단계로/단계 간에 데이터 이동(Python)을 참조하세요.
단계는 aml_run_config 구성을 사용하여 compute_target을 통해 정의된 머신에서 실행됩니다.
불필요하게 재실행할 필요가 없어지면 민첩성이 제공되므로 협업 환경에서 파이프라인을 사용할 때 이전 결과(allow_reuse)를 재사용하는 것이 중요합니다. 재사용은 script_name, 입력 및 단계의 매개 변수가 동일하게 유지될 때의 기본 동작입니다. 재사용이 허용되는 경우 이전 실행의 결과가 다음 단계로 즉시 전송됩니다. allow_reuse가 False로 설정된 경우 파이프라인 실행 중에 이 단계에 대해 항상 새로운 실행이 생성됩니다.
단일 단계로 파이프라인을 만들 수 있지만 거의 항상 전체 프로세스를 여러 단계로 분할하도록 선택합니다. 예를 들어 데이터 준비, 학습, 모델 비교 및 배포 단계가 있을 수 있습니다. 예를 들어 위에 지정된 data_prep_step 이후 다음 단계는 학습이라고 가정할 수 있습니다.
train_source_dir = "./train_src"
train_entry_point = "train.py"
training_results = OutputFileDatasetConfig(name = "training_results",
destination = def_blob_store)
train_step = PythonScriptStep(
script_name=train_entry_point,
source_directory=train_source_dir,
arguments=["--prepped_data", output_data1.as_input(), "--training_results", training_results],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
위의 코드는 데이터 준비 단계의 코드와 비슷합니다. 학습 코드는 데이터 준비 코드와는 별개의 디렉터리에 있습니다. 데이터 준비 단계의 OutputFileDatasetConfig 출력인 output_data1은 학습 단계에 대한 입력으로 사용됩니다. 후속 비교 또는 배포 단계의 결과를 보유하기 위해 새로운 OutputFileDatasetConfig 개체인 training_results가 생성됩니다.
다른 코드 예제는 2단계 ML 파이프라인 빌드 방법과 실행 완료 시 데이터 저장소에 데이터를 다시 쓰는 방법을 참조하세요.
단계를 정의한 후 일부 또는 모든 단계를 사용하여 파이프라인을 빌드합니다.
참고 항목
단계를 정의하거나 파이프라인을 빌드할 때는 Azure Machine Learning에 파일 또는 데이터가 업로드되지 않습니다. Experiment.submit()를 호출할 때 파일이 업로드됩니다.
# list of steps to run (`compare_step` definition not shown)
compare_models = [data_prep_step, train_step, compare_step]
from azureml.pipeline.core import Pipeline
# Build the pipeline
pipeline1 = Pipeline(workspace=ws, steps=[compare_models])
데이터 세트 사용
Azure Blob Storage, Azure Files, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure SQL Database 및 Azure Database for PostgreSQL에서 만든 데이터 세트는 파이프라인 단계의 입력으로 사용할 수 있습니다. DataTransferStep, DatabricksStep에 출력을 쓸 수 있습니다. 또는 특정 데이터 저장소에 데이터를 쓰려는 경우 OutputFileDatasetConfig를 사용합니다.
Important
Azure Blob, Azure File 공유, ADLS Gen 1 및 Gen 2 데이터 저장소의 경우 OutputFileDatasetConfig를 사용하여 데이터 저장소에 출력 데이터를 쓰는 것만 지원됩니다.
dataset_consuming_step = PythonScriptStep(
script_name="iris_train.py",
inputs=[iris_tabular_dataset.as_named_input("iris_data")],
compute_target=compute_target,
source_directory=project_folder
)
그런 다음 Run.input_datasets 사전을 사용하여 파이프라인에서 데이터 세트를 검색합니다.
# iris_train.py
from azureml.core import Run, Dataset
run_context = Run.get_context()
iris_dataset = run_context.input_datasets['iris_data']
dataframe = iris_dataset.to_pandas_dataframe()
Run.get_context() 줄은 강조할 가치가 있습니다. 이 함수는 현재 실험 실행을 나타내는 Run을 검색합니다. 위의 샘플에서는 이 암수를 사용하여 등록된 데이터 세트를 검색합니다. Run 개체의 또 다른 일반적인 용도는 실험 자체와 실험이 있는 작업 영역을 모두 검색하는 것입니다.
# Within a PythonScriptStep
ws = Run.get_context().experiment.workspace
데이터를 전달하고 액세스하는 다른 방법을 포함한 자세한 내용은 ML 파이프라인 단계로/단계 간에 데이터 이동(Python)을 참조하세요.
캐싱 및 재사용
파이프라인의 동작을 최적화하고 사용자 지정하려면 캐싱 및 재사용과 관련된 몇 가지 작업을 수행할 수 있습니다. 예를 들어 다음을 선택할 수 있습니다.
- 단계 정의 중에
allow_reuse=False를 설정하여 단계 실행 출력의 기본 재사용을 해제합니다. 불필요하게 실행할 필요가 없어지면 민첩성이 제공되므로 협업 환경에서 파이프라인을 사용할 때 재사용하는 것이 중요합니다. 그러나 재사용을 옵트아웃할 수 있습니다. pipeline_run = exp.submit(pipeline, regenerate_outputs=True)를 사용하여 실행의 모든 단계에 대한 출력 강제 재생성
기본적으로 단계에 대해 allow_reuse가 사용 가능하고 단계 정의에 지정된 source_directory가 해시됩니다. 따라서 지정된 단계에 대한 스크립트가 동일하게 유지되고(script_name, 입력 및 매개 변수) source_directory의 다른 항목이 변경되지 않으면 이전 단계 실행의 출력이 재사용되고 컴퓨팅에 작업이 제출되지 않으며, 이전 실행의 결과를 다음 단계에서 즉시 사용할 수 있습니다.
step = PythonScriptStep(name="Hello World",
script_name="hello_world.py",
compute_target=aml_compute,
source_directory=source_directory,
allow_reuse=False,
hash_paths=['hello_world.ipynb'])
참고 항목
데이터 입력의 이름이 변경되면 기본 데이터가 변경되지 않는 경우에도 단계가 다시 실행됩니다. 입력 데이터의 name 필드를 명시적으로 설정해야 합니다(data.as_input(name=...)). 이 값을 명시적으로 설정하지 않으면 name 필드가 임의 guid로 설정되고 단계의 결과가 다시 사용되지 않습니다.
파이프라인 제출
파이프라인을 제출하면 Azure Machine Learning은 각 단계에 대한 종속성을 확인하고 지정된 소스 디렉터리의 스냅샷을 업로드합니다. 소스 디렉터리를 지정하지 않으면 현재 로컬 디렉터리가 업로드됩니다. 스냅샷도 작업 영역에 실험의 일부로 저장됩니다.
Important
불필요한 파일이 스냅샷에 포함되지 않도록 하려면 디렉터리에 ignore 파일(.gitignore 또는 .amlignore)을 만듭니다. 이 파일에 제외할 파일 및 디렉터리를 추가합니다. 이 파일 내에서 사용하는 구문에 대한 자세한 내용은 .gitignore의 구문 및 패턴을 참조하세요. .amlignore 파일은 동일한 구문을 사용합니다. 두 파일이 모두 있는 경우 .amlignore 파일이 사용되고 .gitignore 파일은 사용되지 않습니다.
자세한 내용은 스냅샷을 참조하세요.
from azureml.core import Experiment
# Submit the pipeline to be run
pipeline_run1 = Experiment(ws, 'Compare_Models_Exp').submit(pipeline1)
pipeline_run1.wait_for_completion()
파이프라인을 처음 실행하는 경우 Azure Machine Learning은 다음을 수행합니다.
작업 영역과 연결된 Blob Storage에서 컴퓨팅 대상으로 프로젝트 스냅샷을 다운로드합니다.
파이프라인의 각 단계에 해당하는 Docker 이미지를 빌드합니다.
컨테이너 레지스트리에서 컴퓨팅 대상으로 각 단계의 Docker 이미지를 다운로드합니다.
Dataset및OutputFileDatasetConfig개체에 대한 액세스를 구성합니다.as_mount()액세스 모드의 경우 FUSE를 사용하여 가상 액세스를 제공합니다. 탑재가 지원되지 않거나 사용자가 액세스를as_upload()로 지정한 경우 데이터가 대신 컴퓨팅 대상에 복사됩니다.단계 정의에 지정된 컴퓨팅 대상에서 단계를 실행합니다.
단계에서 지정한 로그, stdout, stderr, 메트릭, 출력 등의 아티팩트를 만듭니다. 그런 다음, 해당 아티팩트가 업로드되어 사용자의 기본 데이터 저장소에 보관됩니다.
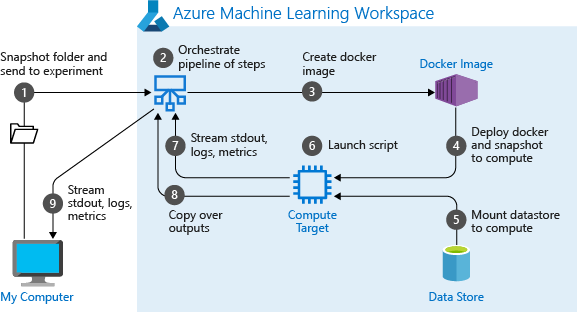
자세한 내용은 실험 클래스 참조를 확인하세요.
추론 시간에 변경되는 인수에 파이프라인 매개 변수 사용
경우에 따라 파이프라인 내의 개별 단계에 대한 인수가 개발 및 학습 기간과 관련이 있습니다. 예를 들어, 학습 속도와 모멘텀, 데이터 또는 구성 파일 경로 등이 있습니다. 그러나 모델이 배포되면 추론하는 인수(즉, 응답하도록 모델을 빌드한 쿼리)를 동적으로 전달하는 것이 좋습니다. 해당 형식의 인수 파이프라인 매개 변수를 만들어야 합니다. Python에서 이 작업을 수행하려면 다음 코드 조각에 표시된 대로 azureml.pipeline.core.PipelineParameter 클래스를 사용합니다.
from azureml.pipeline.core import PipelineParameter
pipeline_param = PipelineParameter(name="pipeline_arg", default_value="default_val")
train_step = PythonScriptStep(script_name="train.py",
arguments=["--param1", pipeline_param],
target=compute_target,
source_directory=project_folder)
Python 환경이 파이프라인 매개 변수와 작동하는 방식
이전에 학습 실행 환경 구성에서 설명한 대로 환경 상태 및 Python 라이브러리 종속성은 Environment 개체를 사용하여 지정됩니다. 일반적으로 이름 및 선택적으로 버전을 참조하여 기존 Environment를 지정할 수 있습니다.
aml_run_config = RunConfiguration()
aml_run_config.environment.name = 'MyEnvironment'
aml_run_config.environment.version = '1.0'
그러나 PipelineParameter 개체를 사용하여 런타임 시 파이프라인 단계의 변수를 동적으로 설정하도록 선택한 경우 기존 Environment를 참조하는 이 기술을 사용할 수 없습니다. 대신 PipelineParameter 개체를 사용하려면 RunConfiguration의 environment 필드를 Environment 개체로 설정해야 합니다. 해당 Environment에 외부 Python 패키지에 대한 종속성이 올바르게 설정되었는지 확인하는 것은 사용자의 책임입니다.
파이프라인의 결과 보기
스튜디오에서 모든 파이프라인 및 해당 실행 세부 정보 목록을 참조하세요.
Azure Machine Learning Studio에 로그인합니다.
작업 영역을 확인합니다.
왼쪽에서 파이프라인을 선택하여 모든 파이프라인의 실행을 확인합니다.
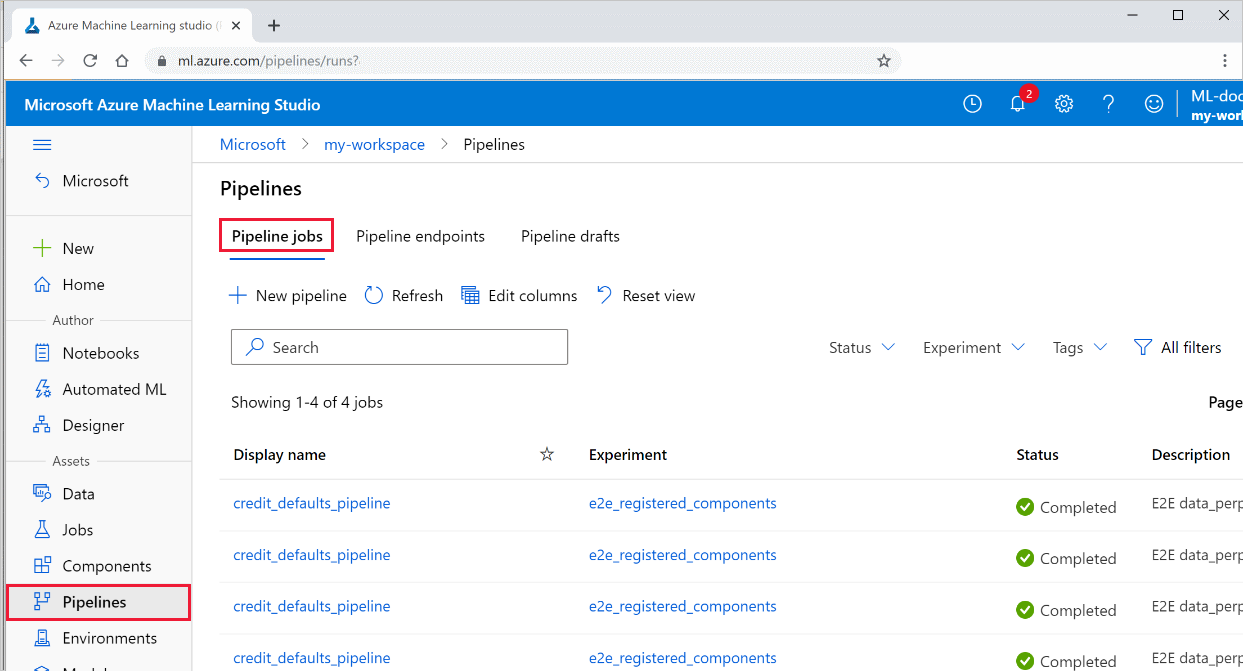
특정 파이프라인을 선택하여 실행 결과를 확인합니다.
Git 추적 및 통합
원본 디렉터리가 로컬 Git 리포지토리인 학습 실행을 시작하면 리포지토리에 대한 정보가 실행 기록에 저장됩니다. 자세한 내용은 Azure Machine Learning에 대한 Git 통합을 참조하세요.
다음 단계
- 동료 또는 고객과 파이프라인을 공유하려면 기계 학습 파이프라인 게시를 참조하세요.
- GitHub의 Jupyter Notebook을 사용하여 기계 학습 파이프라인을 추가로 살펴보기
- azureml-pipelines-core 패키지 및 azureml-pipelines-steps 패키지에 대한 SDK 참조 도움말을 확인하세요.
- 파이프라인 디버깅 및 문제 해결에 대한 팁은 방법을 참조하세요.
- Jupyter 노트북을 사용하여 이 서비스 검색 문서를 따라 노트북을 실행하는 방법을 알아봅니다.