Azure에 기계 학습 모델 배포
적용 대상: Azure CLI ml 확장 v1Python SDK azureml v1
Azure CLI ml 확장 v1Python SDK azureml v1
Azure 클라우드의 웹 서비스로 기계 학습 또는 딥 러닝 모델을 배포하는 방법을 알아봅니다.
참고 항목
Azure Machine Learning 엔드포인트(v2)는 더 간단하고 향상된 배포 환경을 제공합니다. 엔드포인트는 실시간 및 일괄 처리 유추 시나리오를 둘 다 지원합니다. 엔드포인트는 컴퓨팅 유형 간에 모델 배포를 호출하고 관리할 수 있는 통합 인터페이스를 제공합니다. Azure Machine Learning 엔드포인트란?을 참조하세요.
모델 배포를 위한 워크플로
워크플로는 모델을 배포하는 위치와 관계없이 유사합니다.
- 모델을 등록합니다.
- 항목 스크립트를 준비합니다.
- 추론 구성을 준비합니다.
- 모델을 로컬로 배포하여 모든 것이 작동하는지 확인합니다.
- 컴퓨팅 대상을 선택합니다.
- 클라우드에 모델을 배포합니다.
- 결과 웹 서비스를 테스트합니다.
기계 학습 배포 워크플로와 관련한 개념에 대한 자세한 내용은 Azure Machine Learning을 사용한 모델 관리, 배포 및 모니터링을 참조하세요.
필수 조건
적용 대상: Azure CLI ml 확장 v1
Important
이 문서의 일부 Azure CLI 명령에서는 azure-cli-ml 또는 v1(Azure Machine Learning용 확장)을 사용합니다. v1 확장에 대한 지원은 2025년 9월 30일에 종료됩니다. v1 확장은 이 날짜까지 설치하고 사용할 수 있습니다.
2025년 9월 30일 이전에 ml 또는 v2 확장으로 전환하는 것이 좋습니다. v2 확장에 대한 자세한 내용은 Azure ML CLI 확장 및 Python SDK v2를 참조하세요.
- Azure Machine Learning 작업 영역 자세한 내용은 작업 영역 리소스 만들기를 참조하세요.
- 모델. 이 문서의 예제에서는 미리 학습된 모델을 사용합니다.
- 컴퓨팅 인스턴스와 같이 Docker를 실행할 수 있는 머신입니다.
작업 영역에 연결
적용 대상: Azure CLI ml 확장 v1
액세스 권한이 있는 작업 영역을 보려면 다음 명령을 사용합니다.
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
모델 등록
배포된 기계 학습 서비스의 일반적인 상황은 다음 구성 요소가 필요하다는 것입니다.
- 배포하려는 특정 모델을 나타내는 리소스(예: pytorch 모델 파일)
- 서비스에서 실행될 코드로, 지정된 입력에 대해 모델을 실행합니다.
Azure Machine Learning을 사용하면 배포를 두 개의 개별 구성 요소로 구분하여 동일한 코드를 유지하면서도 모델을 업데이트할 수 있습니다. 코드와 별도로 모델을 업로드하는 메커니즘을 "모델 등록"으로 정의합니다.
모델을 등록할 때 모델을 클라우드(작업 영역의 기본 스토리지 계정)에 업로드한 다음, 웹 서비스가 실행 중인 동일한 컴퓨팅에 탑재합니다.
다음 예제에서는 모델을 등록하는 방법을 보여줍니다.
Important
신뢰할 수 있는 원본에서 만들거나 가져온 모델만 사용해야 합니다. 보안 취약성이 널리 사용되는 여러 형식으로 검색되기 때문에 직렬화된 모델을 코드로 처리해야 합니다. 또한 모델은 의도적으로 또는 부정확한 결과를 제공하도록 악의적인 의도로 의도적으로 학습될 수 있습니다.
적용 대상: Azure CLI ml 확장 v1
다음 명령은 모델을 다운로드한 다음, Azure Machine Learning 작업 영역에 등록합니다.
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
-p를 등록하려는 폴더 또는 파일의 경로로 설정합니다.
az ml model register에 대한 자세한 내용은 참조 설명서를 참조하세요.
Azure Machine Learning 학습 작업에서 모델 등록
이전에 Azure Machine Learning 학습 작업을 통해 만든 모델을 등록해야 하는 경우 모델의 실험, 실행 및 경로를 지정할 수 있습니다.
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
--asset-path 매개 변수는 모델의 클라우드 위치를 의미합니다. 이 예제에서는 단일 파일의 경로를 사용합니다. 모델 등록에 여러 파일을 포함하려면 --asset-path를 파일이 담긴 폴더의 경로로 설정합니다.
az ml model register에 대한 자세한 내용은 참조 설명서를 참조하세요.
참고 항목
작업 영역 UI 포털을 통해 로컬 파일에서 모델을 등록할 수도 있습니다.
현재 UI에 로컬 모델 파일을 업로드하는 두 가지 옵션이 있습니다.
- v2 모델을 등록하는 로컬 파일에서
- v1 모델을 등록하는 로컬 파일에서(프레임워크 기반)
v1 모델이라고 하는 로컬 파일에서(프레임워크 기반) 입구를 통해 등록된 모델만 SDKv1/CLIv1을 사용하여 웹 서비스로 배포할 수 있습니다.
더미 항목 스크립트 정의
항목 스크립트는 배포된 웹 서비스에 전송된 데이터를 받아서 모델에 전달합니다. 그런 다음, 모델 응답을 클라이언트로 반환합니다. 스크립트는 모델에 따라 다릅니다. 항목 스크립트는 모델이 기대하고 반환하는 데이터를 해석해야 합니다.
항목 스크립트에서 수행해야 하는 두 가지 작업은 다음과 같습니다.
- 모델 로드(
init()라는 함수 사용) - 입력 데이터에서 모델 실행(
run()이라는 함수 사용)
초기 배포의 경우 수신한 데이터를 인쇄하는 더미 항목 스크립트를 사용합니다.
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
이 파일을 source_dir 디렉터리 내부에 echo_score.py로 저장합니다. 이 더미 스크립트는 전송한 데이터를 반환하므로 모델을 사용하지 않습니다. 하지만 점수 매기기 스크립트가 실행 중인지 테스트하는 데 유용합니다.
추론 구성 정의
유추 구성은 웹 서비스를 초기화할 때 사용할 Docker 컨테이너 및 파일을 설명합니다. 웹 서비스를 배포할 때 하위 디렉터리를 포함하여 원본 디렉터리 내의 모든 파일이 압축되어 클라우드에 업로드됩니다.
아래 유추 구성에서는 기계 학습 배포가 ./source_dir 디렉터리의 echo_score.py 파일을 사용하여 들어오는 요청을 처리하고, project_environment 환경에서 지정한 Python 패키지에 Docker 이미지를 사용합니다.
프로젝트 환경을 만들 때 Azure Machine Learning 추론 큐레이트 환경을 기본 Docker 이미지로 사용할 수 있습니다. 위에서 필요한 종속성을 설치하고 결과 Docker 이미지를 작업 영역과 연결된 리포지토리에 저장합니다.
참고 항목
Azure 기계 학습 추론 원본 디렉터리 업로드는 .gitignore 또는 .amlignore를 준수하지 않습니다.
적용 대상: Azure CLI ml 확장 v1
최소 유추 구성은 다음과 같이 작성할 수 있습니다.
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
이 파일을 dummyinferenceconfig.json이라는 이름으로 저장합니다.
유추 구성에 대한 자세한 내용은 이 문서를 참조하세요.
배포 구성 정의
배포 구성은 실행을 위해 웹 서비스에 필요한 메모리 및 코어의 양을 지정합니다. 또한 기본 웹 서비스 구성 세부 정보도 제공합니다. 예를 들어 배포 구성을 사용하여 서비스에 2기가바이트의 메모리, 2개의 CPU 코어, 1개의 GPU 코어가 필요하며 자동 크기 조정을 사용하도록 지정할 수 있습니다.
배포 구성에 사용할 수 있는 옵션은 선택한 컴퓨팅 대상에 따라 다릅니다. 로컬 배포에서는 웹 서비스가 제공되는 포트를 지정할 수 있습니다.
적용 대상: Azure CLI ml 확장 v1
deploymentconfig.json 문서의 항목은 LocalWebservice.deploy_configuration에 대한 매개 변수에 매핑됩니다. 다음 표에서는 JSON 문서의 엔터티 및 메서드에 대한 매개 변수 간의 매핑에 대해 설명합니다.
| JSON 엔터티 | 메서드 매개 변수 | 설명 |
|---|---|---|
computeType |
해당 없음 | 컴퓨팅 대상. 로컬 대상의 경우 값은 local이어야 합니다. |
port |
port |
서비스의 HTTP 엔드포인트를 노출할 로컬 포트입니다. |
이 JSON은 CLI에서 사용할 수 있는 배포 구성의 예제입니다.
{
"computeType": "local",
"port": 32267
}
이 JSON을 deploymentconfig.json 파일로 저장합니다.
자세한 내용은 배포 스키마를 참조하세요.
기계 학습 모델 배포
이제 모델을 배포할 준비가 되었습니다.
적용 대상: Azure CLI ml 확장 v1
bidaf_onnx:1을 모델 이름 및 해당 버전 번호로 바꿉니다.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
모델에 대한 호출
에코 모델이 성공적으로 배포되었는지 확인해 보겠습니다. 간단한 활동성 요청뿐만 아니라 채점 요청을 수행할 수 있어야 합니다.
적용 대상: Azure CLI ml 확장 v1
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
항목 스크립트 정의
이제 모델을 실제로 로드할 차례입니다. 먼저 항목 스크립트를 수정합니다.
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
이 파일을 source_dir 내부에 score.py로 저장합니다.
AZUREML_MODEL_DIR 환경 변수를 사용하여 등록된 모델을 찾습니다. 이제 일부 pip 패키지를 추가했습니다.
적용 대상: Azure CLI ml 확장 v1
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
이 파일을 inferenceconfig.json으로 저장합니다.
다시 배포하고 서비스를 호출합니다.
서비스를 다시 배포합니다.
적용 대상: Azure CLI ml 확장 v1
bidaf_onnx:1을 모델 이름 및 해당 버전 번호로 바꿉니다.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
그런 다음, 서비스에 게시 요청을 보낼 수 있는지 확인합니다.
적용 대상: Azure CLI ml 확장 v1
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
컴퓨팅 대상 선택
모델을 호스팅하는 데 사용하는 컴퓨팅 대상은 배포된 엔드포인트의 비용 및 가용성에 영향을 줍니다. 이 표를 사용하여 적절한 컴퓨팅 대상을 선택합니다.
| 컴퓨팅 대상 | 사용 대상 | GPU 지원 | 설명 |
|---|---|---|---|
| 로컬 웹 서비스 | 테스트/디버깅 | 제한된 테스트 및 문제 해결에 사용합니다. 하드웨어 가속은 로컬 시스템에서 라이브러리를 사용하는지에 따라 달라집니다. | |
| Azure Machine Learning Kubernetes | 실시간 유추 | 예 | 클라우드에서 유추 워크로드를 실행합니다. |
| Azure Container Instances | 실시간 유추 개발/테스트 목적으로만 권장됩니다. |
48GB 미만의 RAM이 필요한 소규모 CPU 기반 워크로드에 사용합니다. 클러스터를 관리하지 않아도 됩니다. 크기가 1GB 미만인 모델에만 적합합니다. 디자이너에서 지원됩니다. |
참고 항목
클러스터 SKU를 선택할 때는 먼저 스케일 업한 다음, 스케일 아웃합니다. 모델에 필요한 RAM이 150%인 머신에서 시작하여 결과를 프로파일링하고 필요한 성능을 갖춘 머신을 찾습니다. 이를 파악한 후에는 동시 추론 요구에 맞게 머신 수를 늘립니다.
참고 항목
Azure Machine Learning 엔드포인트(v2)는 더 간단하고 향상된 배포 환경을 제공합니다. 엔드포인트는 실시간 및 일괄 처리 유추 시나리오를 둘 다 지원합니다. 엔드포인트는 컴퓨팅 유형 간에 모델 배포를 호출하고 관리할 수 있는 통합 인터페이스를 제공합니다. Azure Machine Learning 엔드포인트란?을 참조하세요.
클라우드에 배포
서비스가 로컬로 작동하는지 확인하고 원격 컴퓨팅 대상을 선택하면 클라우드에 배포할 준비가 된 것입니다.
선택한 컴퓨팅 대상에 해당하도록 배포 구성을 변경합니다. 이 경우 Azure Container Instances입니다.
적용 대상: Azure CLI ml 확장 v1
배포 구성에 사용할 수 있는 옵션은 선택한 컴퓨팅 대상에 따라 다릅니다.
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
이 파일을 re-deploymentconfig.json으로 저장합니다.
자세한 내용은 이 참조에서 확인하세요.
서비스를 다시 배포합니다.
적용 대상: Azure CLI ml 확장 v1
bidaf_onnx:1을 모델 이름 및 해당 버전 번호로 바꿉니다.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
서비스 로그를 보려면 다음 명령을 사용합니다.
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
원격 웹 서비스 호출
원격으로 배포하는 경우 키 인증을 사용하도록 설정했을 수 있습니다. 아래 예제에서는 유추 요청을 만들기 위해 Python을 사용하여 서비스 키를 가져오는 방법을 보여줍니다.
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)print(service.get_logs())다른 언어로 된 더 많은 예제 클라이언트는 웹 서비스를 사용하는 클라이언트 애플리케이션에 대한 문서를 참조하세요.
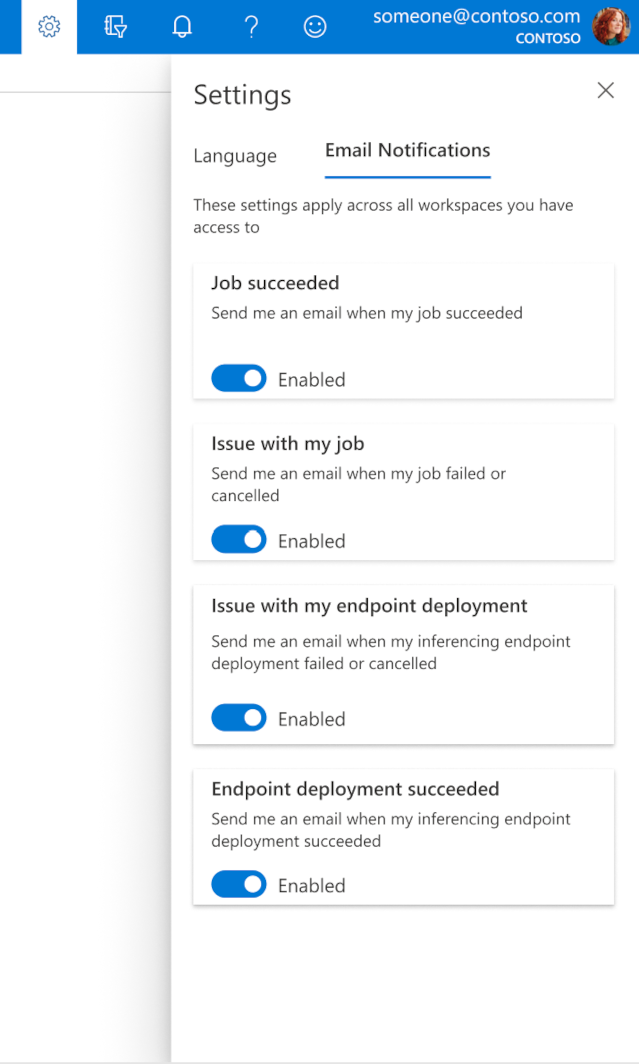
스튜디오에서 이메일을 구성하는 방법
작업, 온라인 엔드포인트 또는 일괄 처리 엔드포인트가 완료되거나 문제(실패, 취소)가 있는 경우 이메일 수신을 시작하려면 다음 단계를 사용합니다.
- Azure ML 스튜디오에서 기어 아이콘을 선택하여 설정으로 이동합니다.
- 이메일 알림 탭을 선택합니다.
- 특정 이벤트에 대한 이메일 알림을 사용하거나 사용하지 않도록 설정하려면 토글합니다.
서비스 상태 해석
모델이 배포되는 과정에서 완전히 배포되면 서비스 상태가 변하는 것을 확인할 수 있습니다.
다음 표에서는 이러한 여러 서비스 상태에 대해 설명합니다.
| 웹 서비스 상태 | 설명 | 최종 상태? |
|---|---|---|
| 전환 | 서비스가 배포 진행 중입니다. | 아니요 |
| 비정상 | 서비스가 배포되었지만 현재 연결할 수 없습니다. | 아니요 |
| 예약되지 않음 | 리소스가 부족하여 지금은 서비스를 배포할 수 없습니다. | 아니요 |
| 실패함 | 오류 또는 충돌 때문에 서비스를 배포하지 못했습니다. | 예 |
| 정상 | 서비스가 정상 상태이며 엔드포인트를 사용할 수 있습니다. | 예 |
팁
배포할 때는 컴퓨팅 대상에 대한 Docker 이미지를 ACR(Azure Container Registry)로부터 빌드하고 로드합니다. 기본적으로 Azure Machine Learning은 기본 서비스 계층을 사용하는 ACR을 만듭니다. 작업 영역에 대한 ACR을 표준 또는 프리미엄 계층으로 변경하면 이미지를 빌드하고 컴퓨팅 대상에 로드하는 시간을 줄일 수 있습니다. 자세한 내용은 Azure Container Registry 서비스 계층을 참조하세요.
참고 항목
AKS(Azure Kubernetes Service)에 모델을 배포하는 경우 해당 클러스터에 대해 Azure Monitor를 사용하도록 설정하는 것이 좋습니다. 이렇게 하면 전반적인 클러스터 상태와 리소스 사용을 해석할 수 있습니다. 다음 리소스도 유용할 수 있습니다.
비정상 또는 오버로드 상태인 클러스터에 모델 배포를 시도하면 문제가 발생하게 됩니다. AKS 클러스터 문제 해결에 도움이 필요한 경우 AKS 고객 지원팀에 문의하세요.
리소스 삭제
적용 대상: Azure CLI ml 확장 v1
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_IDaz ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
배포된 웹 서비스를 삭제하려면 az ml service delete <name of webservice>를 사용합니다.
작업 영역에서 등록된 모델을 삭제하려면 az ml model delete <model id>를 사용합니다.