적용 대상:  Python SDK azure-ai-ml v2(현재)
Python SDK azure-ai-ml v2(현재)
이 문서에서는 Azure Machine Learning Python SDK v2를 사용하여 대규모로 TensorFlow 학습 스크립트를 실행하는 방법에 대해 알아봅니다.
이 문서의 예제 코드는 DNN(심층 신경망)을 사용하여 필기 숫자를 분류하고, 모델을 등록하고, 온라인 엔드포인트에 배포하도록 TensorFlow 모델을 학습시킵니다.
TensorFlow 모델을 처음부터 학습시키든 아니면 기존 모델을 클라우드로 가져오든 관계없이, Azure Machine Learning에서 탄력적 클라우드 컴퓨팅 리소스를 사용하여 오픈 소스 학습 작업을 스케일 아웃할 수 있습니다. Azure Machine Learning을 사용하여 프로덕션 등급 모델을 빌드, 배포, 버전 관리 및 모니터링할 수 있습니다.
필수 조건
이 문서를 활용하려면 다음을 수행해야 합니다.
- Azure 구독에 액세스합니다. 아직 계정이 없으면 체험 계정을 만듭니다.
- Azure Machine Learning 컴퓨팅 인스턴스 또는 사용자 고유의 Jupyter Notebook에서 이 문서의 코드를 실행합니다.
- Azure Machine Learning 컴퓨팅 인스턴스 - 다운로드 또는 설치 필요 없음
- SDK 및 샘플 리포지토리가 사전 로드된 전용 Notebook 서버를 만들려면 시작 위한 리소스 만들기 자습서를 완료합니다.
- Notebook 서버의 딥 러닝 샘플 폴더에서 v2 > sdk > python > jobs > single-step > tensorflow > train-hyperparameter-tune-deploy-with-tensorflow로 이동하여 완성된 확장 Notebook을 찾습니다.
- Jupyter Notebook 서버
- Azure Machine Learning 컴퓨팅 인스턴스 - 다운로드 또는 설치 필요 없음
- 다음 파일을 다운로드합니다.
- 학습 스크립트 tf_mnist.py
- 채점 스크립트 score.py
- 샘플 요청 파일 sample-request.json
GitHub 샘플 페이지에서 이 가이드의 완료된 Jupyter Notebook 버전을 찾을 수도 있습니다.
이 문서의 코드를 실행하여 GPU 클러스터를 만들려면 먼저 작업 영역에 대한 할당량 증가를 요청해야 합니다.
작업 설정
이 섹션에서는 필요한 Python 패키지를 로드하고, 작업 영역에 연결하고, 명령 작업을 실행할 컴퓨팅 리소스를 만들고, 작업을 실행할 환경을 만들어 학습 작업을 설정합니다.
작업 영역에 연결
먼저, Azure Machine Learning 작업 영역에 연결해야 합니다. Azure Machine Learning 작업 영역은 서비스의 최상위 리소스입니다. 작업 영역은 Azure Machine Learning를 사용하는 경우 만드는 모든 아티팩트를 사용할 수 있는 중앙 집중식 위치를 제공합니다.
DefaultAzureCredential을 사용하여 작업 영역에 액세스합니다. 이 자격 증명은 대부분의 Azure SDK 인증 시나리오를 처리할 수 있어야 합니다.
DefaultAzureCredential이 적합하지 않은 경우 사용 가능한 추가 자격 증명은 azure-identity reference documentation 또는 Set up authentication을 참조하세요.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()브라우저를 사용하여 로그인하고 인증하려는 경우 다음 코드에서 주석 처리를 제거하고 대신 사용해야 합니다.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
다음으로, 구독 ID, 리소스 그룹 이름, 작업 영역 이름을 제공하여 작업 영역에 대한 핸들을 가져옵니다. 이 매개 변수를 찾으려면:
- Azure Machine Learning 스튜디오 도구 모음의 오른쪽 위에서 작업 영역 이름을 찾습니다.
- 작업 영역 이름을 선택하여 리소스 그룹 및 구독 ID를 표시합니다.
- 리소스 그룹 및 구독 ID의 값을 코드에 복사합니다.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)이 스크립트를 실행한 결과는 다른 리소스와 작업을 관리하는 데 사용할 작업 영역 핸들입니다.
참고 항목
-
MLClient를 만들면 클라이언트가 작업 영역에 연결되지 않습니다. 클라이언트 초기화는 지연되며 처음 호출해야 할 때까지 기다립니다. 이 문서에서는 컴퓨팅을 만드는 동안 이 문제가 발생합니다.
컴퓨팅 리소스 만들기
Azure Machine Learning에서는 작업을 실행할 컴퓨팅 리소스가 필요합니다. 이 리소스는 Linux 또는 Windows OS를 사용하는 단일 또는 다중 노드 머신 또는 Spark와 같은 특정 컴퓨팅 패브릭입니다.
다음 예제 스크립트에서는 Linux compute cluster를 프로비저닝합니다. VM 크기 및 가격의 전체 목록은 Azure Machine Learning pricing 페이지에서 확인할 수 있습니다. 이 예제에는 GPU 클러스터가 필요하므로 STANDARD_NC6 모델을 선택하고 Azure Machine Learning 컴퓨팅을 만들어 보겠습니다.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC4AS_T4_V3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)작업 환경 만들기
Azure Machine Learning 작업을 실행하려면 환경이 필요합니다. Azure Machine Learning 환경은 컴퓨팅 리소스에서 기계 학습의 학습 스크립트를 실행하는 데 필요한 종속성(예: 소프트웨어 런타임 및 라이브러리)을 캡슐화합니다. 이 환경은 로컬 머신의 Python 환경과 비슷합니다.
Azure Machine Learning에서는 일반적인 학습 및 추론 시나리오에 유용한 큐레이팅된(또는 즉시 사용 가능한) 환경을 사용할 수도 있고 Docker 이미지 또는 Conda 구성을 사용하여 사용자 지정 환경을 만들 수도 있습니다.
이 문서에서는 큐레이팅된 Azure Machine Learning 환경인 AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu를 다시 사용합니다.
@latest 지시문을 사용하여 이 환경의 최신 버전을 사용합니다.
curated_env_name = "AzureML-tensorflow-2.12-cuda11@latest"학습 작업 구성 및 제출
이 섹션에서는 학습을 위한 데이터를 소개하는 것부터 시작합니다. 그런 다음, 제공된 학습 스크립트를 사용하여 학습 작업을 실행하는 방법을 설명합니다. 학습 스크립트를 실행하기 위한 명령을 구성하여 학습 작업을 빌드합니다. 그런 다음 Azure Machine Learning에서 실행할 학습 작업을 제출합니다.
학습 데이터 가져오기
MNIST(Modified National Institute of Standards and Technology) 데이터베이스의 필기 숫자 데이터를 사용합니다. 이 데이터의 출처는 Yan LeCun의 웹 사이트이며 Azure 스토리지 계정에 저장됩니다.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"MNIST 데이터 세트에 대한 자세한 내용을 알아보려면 Yan LeCun의 웹 사이트를 방문하세요.
학습 스크립트 준비
이 문서에서는 tf_mnist.py 학습 스크립트를 제공했습니다. 실제로 사용자 지정 학습 스크립트를 있는 그대로 사용하여 코드를 수정하지 않고도 Azure Machine Learning에서 실행할 수 있어야 합니다.
제공된 학습 스크립트는 다음을 수행합니다.
- 데이터를 전처리하고, 데이터를 테스트 및 학습 데이터로 분할
- 모델 학습, 데이터 사용
- 출력 모델 반환
파이프라인을 실행하는 동안 MLFlow를 사용하여 매개 변수 및 메트릭을 기록합니다. MLFlow 추적을 사용하도록 설정하는 방법을 알아보려면 MLflow로 ML 실험 및 모델 추적을 참조하세요.
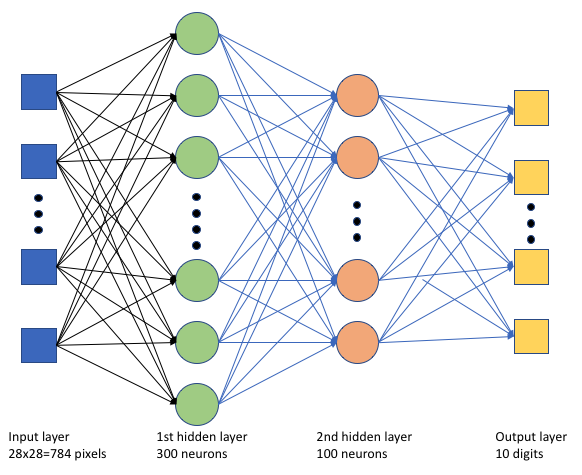
학습 스크립트 tf_mnist.py에서 간단한 DNN(심층 신경망)을 만듭니다. 이 DNN에는 다음 항목이 포함되어 있습니다.
- 28 * 28 = 784개의 뉴런이 있는 입력 레이어. 각 뉴런은 이미지 픽셀을 나타냅니다.
- 숨겨진 레이어 2개. 첫 번째 숨겨진 레이어에는 300개의 뉴런이 있고 두 번째 숨겨진 레이어에는 100개의 뉴런이 있습니다.
- 10개의 뉴런이 있는 출력 레이어. 각 뉴런은 0에서 9까지의 대상 레이블을 나타냅니다.
학습 작업 빌드
이제 작업을 실행하는 데 필요한 모든 자산이 있으므로 Azure Machine Learning Python SDK v2를 사용하여 작업을 빌드할 차례입니다. 이 예에서는 command를 만듭니다.
Azure Machine Learning command는 클라우드에서 학습 코드를 실행하는 데 필요한 모든 세부 정보를 지정하는 리소스입니다. 이 세부 정보에는 입력 및 출력, 사용할 하드웨어 유형, 설치할 소프트웨어, 코드 실행 방법이 포함됩니다.
command에는 단일 명령을 실행하기 위한 정보가 포함됩니다.
명령 구성
범용 command를 사용하여 학습 스크립트를 실행하고 원하는 작업을 수행합니다. 학습 작업의 구성 세부 정보를 지정하는 Command 개체를 만듭니다.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=64,
first_layer_neurons=256,
second_layer_neurons=128,
learning_rate=0.01,
),
compute=gpu_compute_target,
environment=curated_env_name,
code="./src/",
command="python tf_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="tf-dnn-image-classify",
display_name="tensorflow-classify-mnist-digit-images-with-dnn",
)이 명령의 입력에는 데이터 위치, 배치 크기, 첫 번째 및 두 번째 레이어의 뉴런 수, 학습 속도가 포함됩니다. 웹 경로를 입력으로 직접 전달했습니다.
매개 변수 값의 경우:
- 이 명령을 실행하기 위해 만든 컴퓨팅 클러스터
gpu_compute_target = "gpu-cluster"를 제공합니다. - 이전에 선언한
curated_env_name큐레이팅된 환경을 제공합니다. - 명령줄 작업 자체를 구성합니다. 이 경우 명령은
python tf_mnist.py입니다.${{ ... }}표기법을 통해 명령의 입력 및 출력에 액세스할 수 있습니다. - 표시 이름, 실험 이름 등의 메타데이터를 구성합니다. 여기서 실험은 특정 프로젝트에서 수행하는 모든 반복에 대한 컨테이너입니다. 동일한 실험 이름으로 제출된 모든 작업은 Azure Machine Learning 스튜디오에서 나란히 나열됩니다.
- 이 명령을 실행하기 위해 만든 컴퓨팅 클러스터
이 예제에서는
UserIdentity를 사용하여 명령을 실행합니다. 사용자 ID를 사용하면 명령이 ID를 사용하여 작업을 실행하고 Blob의 데이터에 액세스합니다.
작업 제출
이제 Azure Machine Learning에서 실행할 작업을 제출할 차례입니다. 이번에는 create_or_update에서 ml_client.jobs를 사용합니다.
ml_client.jobs.create_or_update(job)완료되면 작업은 학습의 결과로 작업 영역에 모델을 등록하고 Azure Machine Learning 스튜디오에서 작업을 보기 위한 링크를 출력합니다.
경고
Azure Machine Learning는 전체 원본 디렉터리를 복사하여 학습 스크립트를 실행합니다. 업로드를 원하지 않는 중요한 데이터가 있다면 .ignore 파일을 사용하거나 데이터를 원본 디렉터리에 포함하지 마세요.
작업을 실행하는 동안 수행되는 작업
작업이 실행되면 다음 단계를 거칩니다.
준비: 정의된 환경에 따라 Docker 이미지가 생성됩니다. 이미지는 작업 영역의 컨테이너 레지스트리에 업로드되고 나중에 실행될 수 있도록 캐시됩니다. 또한 로그는 작업 기록으로 스트리밍되며 진행 상황을 모니터링할 수 있도록 표시됩니다. 큐레이팅된 환경이 지정되면 해당 큐레이팅된 환경을 지원하는 캐시된 이미지가 사용됩니다.
스케일링: 실행하는 데 현재 사용 가능한 것보다 더 많은 노드가 필요한 경우 클러스터가 스케일 업을 시도합니다.
실행: 스크립트 폴더 src의 모든 스크립트가 컴퓨팅 대상으로 업로드되고, 데이터 저장소가 탑재되거나 복사되며, 스크립트가 실행됩니다. stdout 및 ./logs 폴더의 출력은 작업 기록으로 스트리밍되며 작업을 모니터링하는 데 사용될 수 있습니다.
모델 하이퍼 매개 변수 튜닝
SDK를 사용하여 TensorFlow 학습 실행을 수행하는 방법을 살펴보았으므로, 이번에는 모델의 정확도를 더 향상시킬 수 있는지 살펴보겠습니다. Azure Machine Learning의 sweep 기능을 사용하여 모델의 하이퍼 매개 변수를 튜닝하고 최적화할 수 있습니다.
모델의 하이퍼 매개 변수를 튜닝하려면 학습 중에 검색할 매개 변수 공간을 정의합니다. 이 작업을 수행하려면 패키지의 특수 입력을 사용하여 학습 작업에 전달된 일부 매개 변수(batch_size, first_layer_neurons, second_layer_neurons 및 learning_rate)를 azure.ml.sweep 패키지의 특수 입력으로 바꿉니다.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[32, 64, 128]),
first_layer_neurons=Choice(values=[16, 64, 128, 256, 512]),
second_layer_neurons=Choice(values=[16, 64, 256, 512]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)그런 다음, 감시할 기본 메트릭, 사용할 샘플링 알고리즘 등의 일부 스윕 관련 매개 변수를 사용하여 명령 작업에 대한 스윕을 구성합니다.
다음 코드에서는 임의 샘플링을 사용하여 기본 메트릭 validation_acc를 최대화하기 위해 하이퍼 매개 변수의 다양한 구성 세트를 시도합니다.
또한 조기 종료 정책인 BanditPolicy를 정의합니다. 이 정책은 두 번의 반복마다 작업을 확인하여 작동합니다. 기본 메트릭 validation_acc가 상위 10% 범위를 벗어나면 Azure Machine Learning이 작업을 종료합니다. 이렇게 하면 모델이 목표 메트릭에 도달하는 데 도움이 되지 않는 하이퍼 매개 변수를 계속 탐색하지 않아도 됩니다.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="validation_acc",
goal="Maximize",
max_total_trials=8,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)이제 이전과 같이 이 작업을 제출할 수 있습니다. 이번에는 학습 작업을 스윕하는 스윕 작업을 실행합니다.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)작업 실행 중에 표시되는 스튜디오 사용자 인터페이스 링크를 사용하여 작업을 모니터링할 수 있습니다.
최적 모델 찾기 및 등록
모든 실행이 완료되면 정확도가 가장 높은 모델을 생성한 실행을 찾을 수 있습니다.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "model"
path="azureml://jobs/{}/outputs/artifacts/paths/outputs/model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="custom_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)그런 다음, 이 모델을 등록할 수 있습니다.
registered_model = ml_client.models.create_or_update(model=model)모델을 온라인 엔드포인트로 배포
모델을 등록한 후 이를 온라인 엔드포인트, 즉 Azure 클라우드의 웹 서비스로 배포할 수 있습니다.
기계 학습 서비스를 배포하려면 일반적으로 다음이 필요합니다.
- 배포할 모델 자산. 이러한 자산에는 학습 작업에 이미 등록한 모델의 파일 및 메타데이터가 포함됩니다.
- 서비스로 실행할 일부 코드입니다. 이 코드는 지정된 입력 요청(항목 스크립트)에서 모델을 실행합니다. 항목 스크립트는 배포된 웹 서비스에 전송된 데이터를 받아서 모델에 전달합니다. 모델이 데이터를 처리한 후 스크립트는 모델의 응답을 클라이언트에 반환합니다. 이 스크립트는 모델마다 다르므로, 모델이 예상하고 반환하는 데이터를 이해해야 합니다. MLFlow 모델을 사용하면 Azure Machine Learning에서 자동으로 이 스크립트를 만듭니다.
배포에 대한 자세한 내용은 Python SDK v2를 사용하여 관리형 온라인 엔드포인트를 통해 기계 학습 모델 배포 및 점수 매기기를 참조하세요.
새 온라인 엔드포인트 만들기
모델을 배포하는 첫 번째 단계로 온라인 엔드포인트를 만들어야 합니다. 엔드포인트 이름은 전체 Azure 지역에서 고유해야 합니다. 이 문서에서는 UUID(범용 고유 식별자)를 사용하여 고유한 이름을 만듭니다.
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "tff-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using TensorFlow",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")엔드포인트를 만든 후 다음과 같이 검색할 수 있습니다.
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)엔드포인트에 모델 배포
엔드포인트를 만든 후에는 항목 스크립트를 사용하여 모델을 배포할 수 있습니다. 하나의 엔드포인트에 여러 배포가 있을 수 있습니다. 그러면 엔드포인트에서 규칙을 사용하여 트래픽을 이러한 배포로 보낼 수 있습니다.
다음 코드에서는 들어오는 트래픽을 100% 처리하는 단일 배포를 만듭니다. 배포에는 임의의 색 이름(tff-blue)을 사용합니다. 배포에 tff-green 또는 tff-red와 같은 다른 이름을 사용할 수도 있습니다. 엔드포인트에 모델을 배포하는 코드는 다음을 수행합니다.
- 이전에 등록한 모델에 가장 적합한 버전을 배포합니다.
-
score.py파일을 사용하여 모델의 점수를 지정하고 - 이전에 지정한 큐레이팅된 환경을 사용하여 추론을 수행합니다.
model = registered_model
from azure.ai.ml.entities import CodeConfiguration
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="tff-blue",
endpoint_name=online_endpoint_name,
model=model,
code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
environment=curated_env_name,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()참고 항목
이 배포를 완료하는 데 다소 시간이 걸립니다.
샘플 쿼리를 사용하여 배포 테스트
모델을 엔드포인트에 배포한 후 엔드포인트에서 invoke 메서드를 사용하여 배포된 모델의 출력을 예측할 수 있습니다. 추론을 실행하려면 sample-request.json 폴더의 샘플 요청 파일 을 사용합니다.
# # predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request/sample-request.json",
deployment_name="tff-blue",
)그러면 반환된 예측을 출력하고 입력 이미지와 함께 도표를 작성할 수 있습니다. 빨간색 글꼴과 반전된 이미지(검은색 바탕에 흰색)를 사용하여 잘못 분류된 샘플을 강조 표시합니다.
# compare actual value vs. the predicted values:
import matplotlib.pyplot as plt
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()참고 항목
모델 정확도가 높기 때문에 잘못 분류된 샘플을 보려면 셀을 여러 번 실행해야 할 수도 있습니다.
리소스 정리
엔드포인트를 사용하지 않는 경우 삭제하여 리소스 사용을 중지합니다. 엔드포인트를 삭제하기 전에 다른 배포에서 엔드포인트를 사용하고 있지 않은지 확인합니다.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)참고 항목
이 정리를 완료하는 데 약간의 시간이 걸릴 것입니다.
다음 단계
이 문서에서는 TensorFlow 모델을 학습시키고 등록했습니다. 또한 모델을 온라인 엔드포인트에 배포했습니다. Azure Machine Learning에 대한 자세한 내용은 다음 문서를 참조하세요.