MLflow를 사용하여 ML 실험 및 모델 추적
이 문서에서는 MLflow를 사용하여 Azure Machine Learning 작업 영역에서 실험 및 실행을 추적하는 방법을 알아봅니다.
추적은 실행한 실험에 대한 관련 정보를 저장하는 프로세스입니다. 저장된 정보(메타데이터)는 프로젝트에 따라 다르며 다음이 포함될 수 있습니다.
- 코드
- 환경 세부 정보(예: OS 버전, Python 패키지)
- 입력 데이터
- 매개 변수 구성
- 모델
- 평가 메트릭
- 평가 시각화(예: 혼동 행렬, 중요도 플롯)
- 평가 결과(일부 평가 예측 포함)
Azure Machine Learning에서 작업을 수행할 때 Azure Machine Learning은 코드, 환경, 입력 및 출력 데이터 등 실험에 대한 일부 정보를 자동으로 추적합니다. 그러나 모델, 매개 변수, 메트릭과 같은 다른 항목의 경우 특정 시나리오에 맞게 추적을 구성해야 합니다.
참고 항목
Azure Databricks에서 실행 중인 실험을 추적하려면 MLflow 및 Azure Machine Learning을 사용하여 Azure Databricks ML 실험 추적을 참조하세요. Azure Synapse Analytics에서 실행 중인 실험 추적에 대해 알아보려면 MLflow 및 Azure Machine Learning을 사용하여 Azure Synapse Analytics ML 실험 추적을 참조하세요.
실험 추적의 이점
Azure Machine Learning에서 작업을 사용하여 학습하든 Notebooks에서 대화형으로 학습하든 상관없이 Machine Learning 전문가는 실험을 추적하는 것이 좋습니다. 실험 추적을 통해 다음을 수행할 수 있습니다.
- 모든 기계 학습 실험을 한 곳에서 정리합니다. 그런 다음 실험을 검색 및 필터링하고 드릴다운하여 이전에 실행한 실험에 대한 세부 정보를 확인할 수 있습니다.
- 약간의 추가 작업으로 실험을 비교하고, 결과를 분석하고, 모델 학습을 디버그합니다.
- 실험을 재현하거나 다시 실행하여 결과의 유효성을 검사합니다.
- 다른 팀원이 무엇을 하고 있는지 확인하고, 실험 결과를 공유하고, 실험 데이터에 프로그래밍 방식으로 액세스할 수 있으므로 협업이 개선됩니다.
실험 추적에 MLflow를 사용하는 이유는 무엇인가요?
Azure Machine Learning 작업 영역은 MLflow와 호환되므로 MLflow를 사용하여 Azure Machine Learning 작업 영역에서 실행, 메트릭, 매개 변수 및 아티팩트를 추적할 수 있습니다. 추적을 위해 MLflow를 사용하는 주요 이점은 Azure Machine Learning을 사용하거나 클라우드 관련 구문을 삽입하기 위해 학습 루틴을 변경할 필요가 없다는 것입니다.
지원되는 모든 MLflow 및 Azure Machine Learning 기능에 대한 자세한 내용은 MLflow 및 Azure Machine Learning을 참조하세요.
제한 사항
Azure Machine Learning에 연결된 경우 MLflow API에서 사용할 수 있는 일부 메서드를 사용하지 못할 수 있습니다. 지원되는 작업과 지원되지 않는 작업에 대한 자세한 내용은 실행 및 실험 쿼리 지원 매트릭스를 참조하세요.
필수 구성 요소
- Azure 구독 Azure 구독이 아직 없는 경우 시작하기 전에 체험 계정을 만듭니다. Azure Machine Learning 평가판 또는 유료 버전을 사용해 보세요.
MLflow SDK 패키지
mlflow및 MLflow용 Azure Machine Learning 플러그 인azureml-mlflow를 설치합니다.pip install mlflow azureml-mlflow팁
SQL 스토리지, 서버, UI 또는 데이터 과학 종속성이 없는 경량 MLflow 패키지인
mlflow-skinny패키지를 사용할 수 있습니다.mlflow-skinny는 배포를 포함한 전체 기능 도구 모음을 가져오지 않고 MLflow의 추적 및 로깅 기능이 주로 필요한 사용자에게 권장됩니다.Azure Machine Learning 작업 영역 기계 학습 리소스 만들기 자습서에 따라 리소스를 만들 수 있습니다.
원격 추적(즉, Azure Machine Learning 외부에서 실행되는 실험 추적)을 수행하는 경우 Azure Machine Learning 작업 영역의 추적 URI를 가리키도록 MLflow를 구성합니다. MLflow를 작업 영역에 연결하는 방법에 대한 자세한 내용은 Azure Machine Learning에 대한 MLflow 구성을 참조하세요.
실험을 구성합니다.
MLflow는 실험 및 실행을 통해 정보를 구성합니다(Azure Machine Learning에서는 실행을 작업이라고 함). 기본적으로 실행은 자동으로 만들어지는 Default라는 실험에 기록됩니다. 추적이 발생하는 실험을 구성할 수 있습니다.
Jupyter Notebook과 같은 대화형 학습의 경우 MLflow 명령 mlflow.set_experiment()를 사용합니다. 예를 들어, 다음 코드 조각은 실험을 구성합니다.
experiment_name = 'hello-world-example'
mlflow.set_experiment(experiment_name)
실행 구성
Azure Machine Learning은 MLflow가 실행이라고 부르는 모든 학습 작업을 추적합니다. 실행을 사용하여 작업이 수행하는 모든 처리를 캡처합니다.
대화형으로 작업할 때 MLflow는 활성 실행이 필요한 정보를 기록하려고 시도하는 즉시 학습 루틴을 추적하기 시작합니다. 예를 들어, MLflow 추적은 메트릭, 매개 변수를 기록하거나 학습 주기를 시작할 때 시작되고 Mlflow의 자동 로깅 기능이 사용하도록 설정됩니다. 그러나 일반적으로 실행을 명시적으로 시작하는 것이 도움이 되며, 특히 기간 필드에서 실험의 총 시간을 캡처하려는 경우 더욱 그렇습니다. 실행을 명시적으로 시작하려면 mlflow.start_run()을 사용합니다.
수동으로 실행을 시작하는지 여부에 관계없이 MLflow가 실험 실행이 완료되었음을 인식하고 실행 상태를 완료됨으로 표시할 수 있도록 결국 실행을 중지해야 합니다. 실행을 중지하려면 mlflow.end_run()을 사용합니다.
Notebooks에서 작업할 때 실행을 종료하는 것을 잊지 않도록 수동으로 실행을 시작하는 것이 좋습니다.
수동으로 실행을 시작하고 Notebook에서 작업을 마친 후 종료하려면 다음을 수행합니다.
mlflow.start_run() # Your code mlflow.end_run()일반적으로 실행 종료를 기억하는 데 도움이 되는 컨텍스트 관리자 패러다임을 사용하는 것이 도움이 됩니다.
with mlflow.start_run() as run: # Your codemlflow.start_run()을 사용하여 새 실행을 시작할 때run_name매개 변수를 지정하는 것이 유용할 수 있습니다. 이 매개 변수는 나중에 Azure Machine Learning 사용자 인터페이스에서 실행 이름으로 변환되고 실행을 더 빠르게 식별하는 데 도움이 됩니다.with mlflow.start_run(run_name="hello-world-example") as run: # Your code
MLflow 자동 로깅 사용
수동으로 MLflow로 메트릭, 매개 변수 및 파일을 로그할 수 있습니다. 그러나 MLflow 자동 로깅 기능을 사용할 수도 있습니다. MLflow에서 지원하는 각 기계 학습 프레임워크는 자동으로 추적할 항목을 결정합니다.
자동 로깅을 사용하도록 설정하려면 학습 코드 앞에 다음 코드를 삽입합니다.
mlflow.autolog()
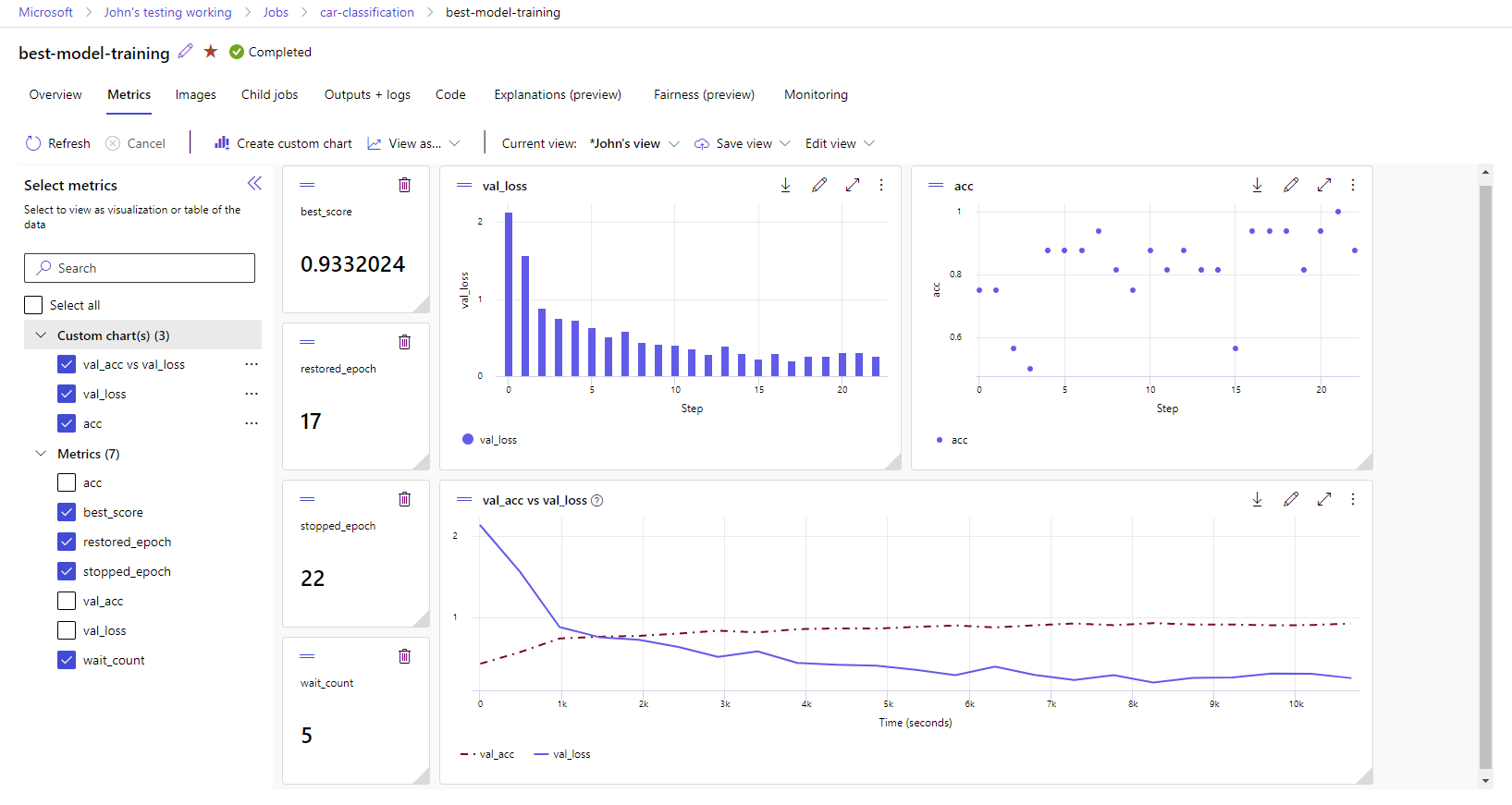
작업 영역에서 메트릭 및 아티팩트 보기
MLflow 로깅의 메트릭과 아티팩트는 작업 영역에 추적됩니다. 언제든지 스튜디오에서 보고 액세스하거나 MLflow SDK를 통해 프로그래밍 방식으로 액세스할 수 있습니다.
스튜디오에서 메트릭 및 아티팩트를 보려면 다음 안내를 따릅니다.
Azure Machine Learning 스튜디오로 이동합니다.
작업 영역으로 이동
작업 영역에서 이름으로 실험을 찾습니다.
로그된 메트릭을 선택하여 오른쪽에 차트를 렌더링합니다. 부드러운 색을 적용하거나, 색을 변경하거나, 단일 그래프에 여러 메트릭을 표시하여 차트를 사용자 지정할 수 있습니다. 레이아웃의 크기를 조정하고 원하는 대로 다시 정렬할 수도 있습니다.
원하는 보기를 만든 후에는 나중에 사용할 수 있도록 저장하고 직접 링크를 사용하여 팀원과 공유합니다.

MLflow SDK를 통해 프로그래밍 방식으로 메트릭, 매개 변수 및 아티팩트에 액세스하거나 쿼리하려면 mlflow.get_run()을 사용합니다.
import mlflow
run = mlflow.get_run("<RUN_ID>")
metrics = run.data.metrics
params = run.data.params
tags = run.data.tags
print(metrics, params, tags)
팁
메트릭의 경우 이전 예 코드에서는 지정된 메트릭의 마지막 값만 반환합니다. 특정 메트릭의 모든 값을 검색하려면 mlflow.get_metric_history 메서드를 사용합니다. 메트릭 값 검색에 대한 자세한 내용은 실행에서 매개 변수 및 메트릭 가져오기를 참조하세요.
파일, 모델 등 로깅한 아티팩트를 다운로드하려면 mlflow.artifacts.download_artifacts()를 사용합니다.
mlflow.artifacts.download_artifacts(run_id="<RUN_ID>", artifact_path="helloworld.txt")
MLflow를 사용하여 Azure Machine Learning의 실험 및 실행에서 정보를 쿼리 또는 비교하는 방법에 대한 자세한 내용은 MLflow를 사용하여 실험 및 실행 쿼리 및 비교를 참조하세요.