Azure Machine Learning에서 Apache Spark를 사용한 대화형 데이터 랭글링
데이터 랭글링은 기계 학습 프로젝트에서 가장 중요한 단계 중 하나가 됩니다. Azure Machine Learning 통합은 Azure Synapse Analytics와 함께 Azure Machine Learning Notebooks를 사용하는 대화형 데이터 랭글링을 위해 Azure Synapse에서 지원하는 Apache Spark 풀에 대한 액세스를 제공합니다.
이 문서에서는 다음을 사용하여 데이터 랭글링을 수행하는 방법을 알아봅니다
- 서버리스 Spark 컴퓨팅
- 연결된 Synapse Spark 풀
필수 조건
- Azure 구독. Azure 구독이 아직 없는 경우 시작하기 전에 체험 계정을 만듭니다.
- Azure Machine Learning 작업 영역 작업 영역 리소스 만들기를 참조하세요.
- ADLS(Azure Data Lake Storage) Gen 2 스토리지 계정. ADLS(Azure Data Lake Storage) Gen 2 스토리지 계정 만들기를 참조하세요.
- (선택 사항): Azure Key Vault. Azure 키 자격 증명 모음 만들기를 참조하세요.
- (선택 사항): 서비스 주체. 서비스 주체 만들기를 참조하세요.
- (선택 사항): Azure Machine Learning 작업 영역의 연결된 Synapse Spark 풀.
데이터 랭글링 작업을 시작하기 전에 비밀을 저장하는 프로세스에 대해 알아봅니다.
- Azure Blob Storage 계정 액세스 키
- SAS(공유 액세스 서명) 토큰
- ADLS(Azure Data Lake Storage) Gen 2 서비스 주체 정보
를 저장하는 프로세스에 대해 잘 알고 있어야 합니다. Azure Storage 계정에서 역할 할당을 처리하는 방법도 알아야 합니다. 이후 섹션에서 이 개념을 검토합니다. 그런 다음, Azure Machine Learning Notebooks의 Spark 풀을 사용하여 대화형 데이터 랭글링의 세부 정보를 살펴봅니다.
팁
Azure Storage 계정 역할 할당 구성에 대해 알아보거나 사용자 ID 통과를 사용하여 스토리지 계정의 데이터에 액세스하는 경우 Azure Storage 계정에서 역할 할당 추가를 참조하세요.
Apache Spark를 사용한 대화형 데이터 랭글링
Azure Machine Learning은 Azure Machine Learning Notebooks에서 Apache Spark와의 대화형 데이터 처리를 위해 서버리스 Spark 컴퓨팅과 연결된 Synapse Spark 풀을 제공합니다. 서버리스 Spark 컴퓨팅에는 Azure Synapse 작업 영역에서 리소스를 만들 필요가 없습니다. 대신 완전 관리형 서버리스 Spark 컴퓨팅을 Azure Machine Learning Notebooks에서 직접 사용할 수 있습니다. 서버리스 Spark 컴퓨팅을 사용하는 것은 Azure Machine Learning에서 Spark 클러스터에 액세스하는 가장 쉬운 방법입니다.
Azure Machine Learning Notebooks의 서버리스 Spark 컴퓨팅
서버리스 Spark 컴퓨팅은 기본적으로 Azure Machine Learning Notebooks에서 사용할 수 있습니다. Notebook에서 액세스하려면 컴퓨팅 선택 메뉴의 Azure Machine Learning 서버리스 Spark에서 서버리스 Spark 컴퓨팅을 선택합니다.
Notebooks UI는 서버리스 Spark 컴퓨팅을 위한 Spark 세션 구성 옵션도 제공합니다. Spark 세션을 구성하려면:
- 화면 상단에서 세션 구성을 선택합니다.
- 드롭다운 메뉴에서 Apache Spark 버전을 선택합니다.
Important
Apache Spark용 Azure Synapse 런타임: 공지 사항
- Apache Spark 3.2용 Azure Synapse 런타임:
- EOLA 공지 사항 날짜: 2023년 7월 8일
- 지원 종료 날짜: 2024년 7월 8일. 이 날짜 이후에는 런타임이 사용하지 않도록 설정됩니다.
- 지속적인 지원과 최적의 성능을 위해서는 Apache Spark 3.3으로 마이그레이션하는 것이 좋습니다.
- Apache Spark 3.2용 Azure Synapse 런타임:
- 드롭다운 메뉴에서 인스턴스 유형을 선택합니다. 현재 지원되는 인스턴스 유형은 다음과 같습니다.
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
- Spark 세션 시간 제한 값을 분 단위로 입력합니다.
- 실행기를 동적으로 할당할지 여부를 선택합니다.
- Spark 세션의 실행기 수를 선택합니다.
- 드롭다운 메뉴에서 실행기 크기를 선택합니다.
- 드롭다운 메뉴에서 드라이버 크기를 선택합니다.
- Conda 파일을 사용하여 Spark 세션을 구성하려면 Conda 파일 업로드 확인란을 선택합니다. 그런 다음 찾아보기를 선택하고 원하는 Spark 세션 구성이 있는 Conda 파일을 선택합니다.
- 구성 설정 속성을 추가하고, 속성 및 값 텍스트 상자에 값을 입력하고, 추가를 선택합니다.
- 적용을 선택합니다.
- 새 세션을 구성하려고 하나요? 팝업에서 세션 중지를 선택합니다.
세션 구성 변경 내용은 유지되며 서버리스 Spark 컴퓨팅을 사용하여 시작된 다른 Notebook 세션에서 사용할 수 있게 됩니다.
팁
세션 수준 Conda 패키지를 사용하는 경우 구성 변수 spark.hadoop.aml.enable_cache를 true로 설정하면 Spark 세션 콜드 부팅 시간을 개선할 수 있습니다. 세션이 처음 시작될 때 세션 수준 Conda 패키지를 사용한 세션 콜드 부팅에는 일반적으로 10~15분이 걸립니다. 그러나 이 구성 변수가 true로 설정된 후 후속 세션 콜드 부팅에는 일반적으로 3~5분이 걸립니다.
ADLS(Azure Data Lake Storage) Gen 2에서 데이터 가져오기 및 랭글링
다음 두 가지 데이터 액세스 메커니즘 중 하나에 따라 abfss:// 데이터 URI를 사용하여 ADLS(Azure Data Lake Storage) Gen 2 스토리지 계정에 저장된 데이터에 액세스하고 데이터를 랭글링할 수 있습니다.
- 사용자 ID 통과
- 서비스 주체 기반 데이터 액세스
팁
서버리스 Spark 컴퓨팅을 사용한 데이터 랭글링 및 ADLS(Azure Data Lake Storage) Gen 2 스토리지 계정의 데이터에 액세스하기 위한 사용자 ID 통과에는 최소한의 구성 단계가 필요합니다.
사용자 ID 통과를 사용하는 대화형 데이터 랭글링을 시작하려면:
사용자 ID가 ADLS(Azure Data Lake Storage) Gen 2 스토리지 계정에서 기여자 및 Storage Blob 데이터 기여자역할 할당이 있는지 확인합니다.
서버리스 Spark 컴퓨팅을 사용하려면 컴퓨팅 선택 메뉴의 Azure Machine Learning 서버리스 Spark에서 서버리스 Spark 컴퓨팅을 선택합니다.
연결된 Synapse Spark 풀을 사용하려면 컴퓨팅 선택 메뉴에서 Synapse Spark 풀 아래 연결된 Synapse Spark 풀을 선택합니다.
이 Titanic 데이터 랭글링 코드 샘플은
pyspark.pandas및pyspark.ml.feature.Imputer를 사용하는abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>형식의 데이터 URI 사용을 보여 줍니다.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled", index_col="PassengerId", )참고 항목
이 Python 코드 샘플에서는
pyspark.pandas를 사용합니다. Spark 런타임 버전 3.2 이상에서만 이를 지원합니다.
서비스 주체를 통해 액세스하여 데이터를 랭글링하려면:
서비스 주체가 ADLS(Azure Data Lake Storage) Gen 2 스토리지 계정에서 기여자 및 Storage Blob 데이터 기여자역할 할당이 있는지 확인합니다.
서비스 주체 테넌트 ID, 클라이언트 ID 및 클라이언트 암호 값에 대한 Azure Key Vault 비밀을 만듭니다.
컴퓨팅 선택 메뉴의 Azure Machine Learning 서버리스 Spark에서 서버리스 Spark 컴퓨팅을 선택하거나 컴퓨팅 선택 메뉴의 Synapse Spark 풀에서 연결된 Synapse Spark 풀을 선택합니다.
구성에서 서비스 주체 테넌트 ID, 클라이언트 ID 및 클라이언트 암호를 설정하려면 다음 코드 샘플을 실행합니다.
코드의
get_secret()호출에서는 Azure Key Vault 이름과 서비스 주체 테넌트 ID, 클라이언트 ID 및 클라이언트 암호에 대해 생성된 Azure Key Vault 비밀의 이름을 사용합니다. 구성에서 다음과 같은 해당 속성 이름/값을 설정합니다.- 클라이언트 ID 속성:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - 클라이언트 암호 속성:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - 테넌트 ID 속성:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - 테넌트 ID 값:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary # Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>") # Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set( "fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_id, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_secret, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", )- 클라이언트 ID 속성:
Titanic 데이터를 사용하는 코드 샘플과 같이
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>형식의 데이터 URI를 사용하여 데이터를 가져오고 랭글링합니다.
Azure Blob Storage에서 데이터 가져오기 및 랭글링
스토리지 계정 액세스 키 또는 SAS(공유 액세스 서명) 토큰을 사용하여 Azure Blob Storage 데이터에 액세스할 수 있습니다. 이 자격 증명을 Azure Key Vault에서 비밀로 저장하고 세션 구성에서 속성으로 설정해야 합니다.
대화형 데이터 랭글링을 시작하려면:
Azure Machine Learning 스튜디오 왼쪽 패널에서 Notebooks를 선택합니다.
컴퓨팅 선택 메뉴의 Azure Machine Learning 서버리스 Spark에서 서버리스 Spark 컴퓨팅을 선택하거나 컴퓨팅 선택 메뉴의 Synapse Spark 풀에서 연결된 Synapse Spark 풀을 선택합니다.
Azure Machine Learning Notebooks에서 데이터 액세스에 대한 스토리지 계정 액세스 키 또는 SAS(공유 액세스 서명) 토큰을 구성하려면:
액세스 키의 경우 다음 코드 조각과 같이
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net속성을 설정합니다.from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key )SAS 토큰의 경우 다음 코드 조각과 같이
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net속성을 설정합니다.from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", sas_token, )참고 항목
위 코드 조각의
get_secret()호출에서는 Azure Key Vault 이름과 Azure Blob Storage 계정 액세스 키 또는 SAS 토큰에 대해 생성된 비밀 이름이 필요합니다.
동일한 Notebook에서 데이터 랭글링 코드를 실행합니다. 이 코드 조각에 표시된 것과 유사하게 데이터 URI의 형식을
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>로 지정합니다.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled", index_col="PassengerId", )참고 항목
이 Python 코드 샘플에서는
pyspark.pandas를 사용합니다. Spark 런타임 버전 3.2 이상에서만 이를 지원합니다.
Azure Machine Learning 데이터 저장소에서 데이터 가져오기 및 랭글링
Azure Machine Learning 데이터 저장소에서 데이터에 액세스하려면 URI 형식azureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA>으로 데이터 저장소의 데이터 경로를 정의합니다. Notebooks 세션에서 대화형으로 Azure Machine Learning 데이터 저장소의 데이터를 랭글링하려면:
컴퓨팅 선택 메뉴의 Azure Machine Learning 서버리스 Spark에서 서버리스 Spark 컴퓨팅을 선택하거나 컴퓨팅 선택 메뉴의 Synapse Spark 풀에서 연결된 Synapse Spark 풀을 선택합니다.
이 코드 샘플에서는
azureml://데이터 저장소 URIpyspark.pandas및pyspark.ml.feature.Imputer를 사용하여 Azure Machine Learning 데이터 저장소에서 Titanic 데이터를 읽고 랭글링하는 방법을 보여 줍니다.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "azureml://datastores/workspaceblobstore/paths/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "azureml://datastores/workspaceblobstore/paths/data/wrangled", index_col="PassengerId", )참고 항목
이 Python 코드 샘플에서는
pyspark.pandas를 사용합니다. Spark 런타임 버전 3.2 이상에서만 이를 지원합니다.
Azure Machine Learning 데이터 저장소는 Azure Storage 계정 자격 증명을 사용하여 데이터에 액세스하거나
- 선택키
- SAS 토큰
- 서비스 사용자(service principal)
자격 증명 없는 데이터 액세스를 제공할 수 있습니다. 데이터 저장소 유형 및 기본 Azure Storage 계정 유형에 따라 적절한 인증 메커니즘을 선택하여 데이터 액세스를 보장합니다. 이 표에는 Azure Machine Learning 데이터 저장소의 데이터에 액세스하기 위한 인증 메커니즘이 요약되어 있습니다.
| Storage 계정 유형 | 자격 증명 없는 데이터 액세스 | 데이터 액세스 메커니즘 | 역할 할당 |
|---|---|---|---|
| Azure Blob | 아니요 | 액세스 키 또는 SAS 토큰 | 역할 할당이 필요하지 않음 |
| Azure Blob | 예 | 사용자 ID 통과* | 사용자 ID는 Azure Blob Storage 계정에서 적절한 역할 할당이 있어야 함 |
| ADLS(Azure Data Lake Storage) Gen 2 | 아니요 | 서비스 사용자 | 서비스 주체는 ADLS(Azure Data Lake Storage) Gen 2 스토리지 계정에서 적절한 역할 할당이 있어야 함 |
| ADLS(Azure Data Lake Storage) Gen 2 | 예 | 사용자 ID 통과 | 사용자 ID는 ADLS(Azure Data Lake Storage) Gen 2 스토리지 계정에서 적절한 역할 할당이 있어야 함 |
* 사용자 ID 통과는 일시 삭제를 사용하도록 설정하지 않은 경우에만 Azure Blob Storage 계정을 가리키는 자격 증명 없는 데이터 저장소에서 작동합니다.
기본 파일 공유의 데이터 액세스
기본 파일 공유는 서버리스 Spark 컴퓨팅 및 연결된 Synapse Spark 풀 모두에 탑재됩니다.
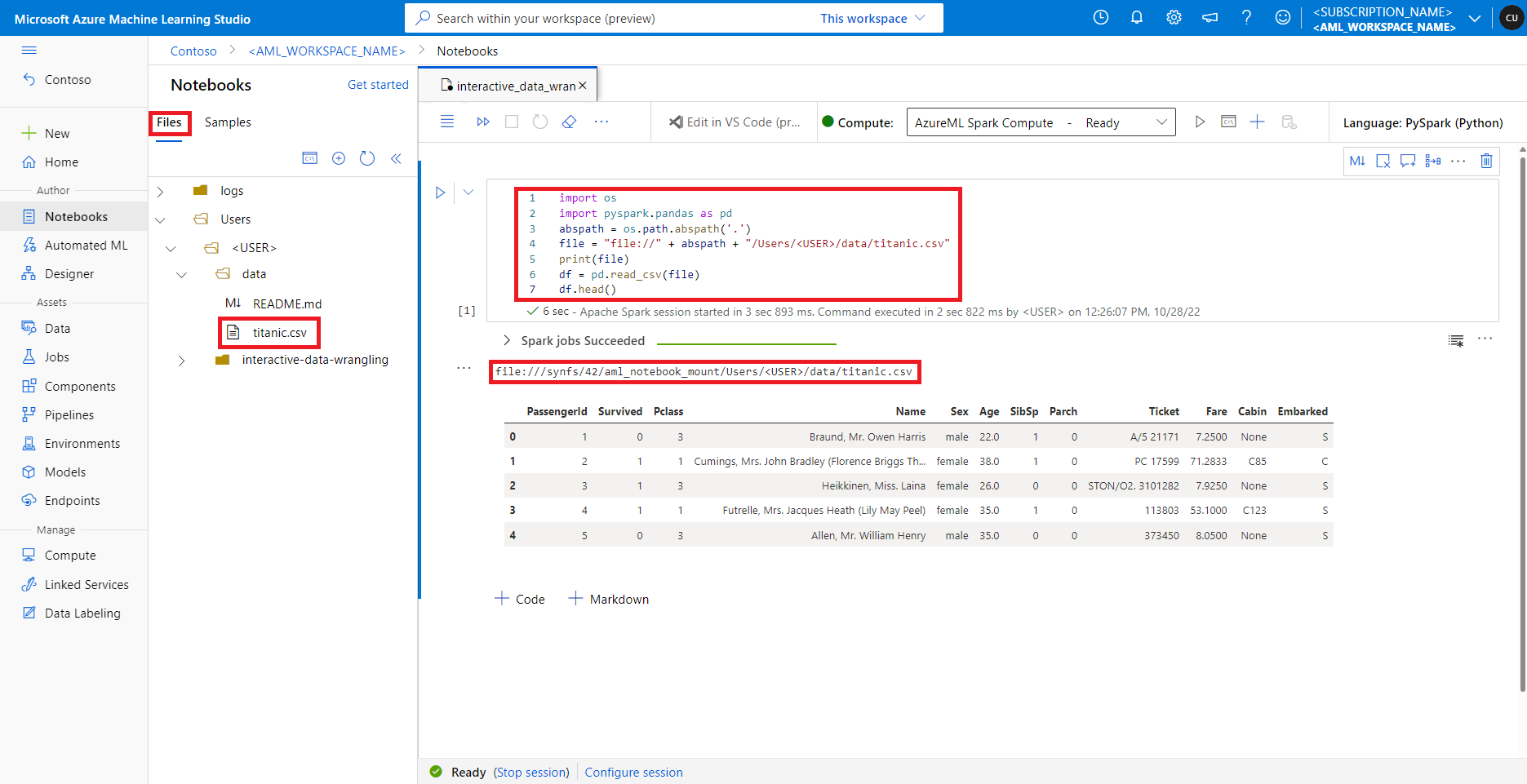
Azure Machine Learning 스튜디오에서 기본 파일 공유의 파일은 파일 탭 아래의 디렉터리 트리에 표시됩니다. Notebook 코드에서는 추가 구성 없이 file:// 프로토콜을 파일의 절대 경로와 함께 사용하여 이 파일 공유에 저장된 파일에 직접 액세스할 수 있습니다. 이 코드 조각은 기본 파일 공유에 저장된 파일에 액세스하는 방법을 보여 줍니다.
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
abspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(
inputCols=["Age"],
outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
참고 항목
이 Python 코드 샘플에서는 pyspark.pandas를 사용합니다. Spark 런타임 버전 3.2 이상에서만 이를 지원합니다.