Microsoft Azure를 사용하면 Linux, UNIX, Windows(LUW)용 IBM DB2에서 실행 중인 기존 SAP 애플리케이션을 Azure 가상 머신으로 마이그레이션할 수 있습니다. LUW용 IBM DB2에서 SAP를 사용하면 관리자와 개발자가 온-프레미스와 동일한 개발 및 관리 도구를 사용할 수 있습니다. LUW용 IBM Db2에서 SAP Business Suite를 실행하는 방법에 대한 일반적인 정보는 Linux, UNIX 및 Windows용 IBM Db2 기반 SAP의 SCN(SAP Community Network)을 통해 제공됩니다.
Azure의 LUW용 DB2 SAP에 대한 추가 정보 및 업데이트는 SAP Note 2233094를 참조하세요.
Azure의 SAP 워크로드에 대한 다양한 문서가 있습니다. Azure VM의 SAP 시작으로 시작한 다음, 다른 관심 영역을 읽어보는 것이 좋습니다.
이 문서에서 다루는 영역에 대해 Azure의 SAP와 관련된 SAP Note는 다음과 같습니다.
| Note 번호 | 타이틀 |
|---|---|
| 1928533 | Azure의 SAP 애플리케이션: 지원 제품 및 Azure VM 유형 |
| 2015553 | Microsoft Azure의 SAP: 지원 필수 조건 |
| 1999351 | SAP용 고급 Azure 모니터링 문제 해결 |
| 2178632 | Microsoft Azure의 SAP용 주요 모니터링 메트릭 |
| 1409604 | Windows에서의 가상화: 향상된 모니터링 |
| 2191498 | Azure와 Linux의 SAP: 향상된 모니터링 |
| 2233094 | DB6: Linux, UNIX 및 Windows용 IBM DB2를 사용하는 SAP 애플리케이션 - 추가 정보 |
| 2243692 | Microsoft Azure(IaaS) VM의 Linux: SAP 라이선스 문제 |
| 1984787 | SUSE LINUX Enterprise Server 12: 설치 참고 |
| 2002167 | Red Hat Enterprise Linux 7.x: 설치 및 업그레이드 |
| 1597355 | Linux에 대한 스왑 공간 권장 사항 |
이 문서의 미리 읽기로 SAP 워크로드용 Azure Virtual Machines DBMS 배포 시 고려 사항을 검토하세요. Azure의 SAP 워크로드의 다른 가이드도 검토하세요.
Linux, UNIX 및 Windows용 IBM DB2 버전 지원
Microsoft Azure Virtual Machine 서비스에서 LUW용 IBM DB2의 SAP는 DB2 버전 10.5부터 지원됩니다. 지원되는 SAP 제품 및 Azure VM(Virtual Machines) 유형에 대한 자세한 내용은 SAP Note 1928533를 참조하세요.
Azure VM의 SAP 설치에 대한 Linux, UNIX 및 Windows용 IBM DB2 구성 지침
스토리지 구성
SAP 워크로드용 Azure 스토리지 유형에 대한 개요는 SAP 워크로드용 Azure 스토리지 유형 문서를 참조하세요. 모든 데이터베이스 파일은 Azure 블록 스토리지(Windows: NTFS, Linux: xfs, Db2 11.1부터 지원됨 또는 ext3)의 탑재된 디스크에 저장되어야 합니다.
나열된 시나리오의 Azure 서비스와 같은 원격 공유 볼륨은 Db2 데이터베이스 파일에 대해 지원 되지 않습니다 .
모든 게스트 OS용 Microsoft Azure File Service
Azure NetApp Files는 Windows 게스트 OS에서 실행되는 Db2용입니다.
나열된 시나리오에서 Azure 서비스와 같은 원격 공유 볼륨은 Db2 데이터베이스 파일에 대해 지원됩니다.
- Azure NetApp Files에서 호스트되는 NFS 공유에서 Linux 게스트 OS 기반 Db2 데이터 및 로그 파일을 호스팅합니다.
Azure Page Blob Storage 또는 관리 디스크를 기반으로 디스크를 사용하는 경우 SAP 워크로드에 대한 Azure Virtual Machines DBMS 배포에 대한 고려 사항 의 설명이 적용됩니다. 이러한 문은 Db2 DBMS(데이터베이스 관리 시스템)를 사용하는 배포와도 관련이 있습니다.
문서의 일반적인 부분에서 앞서 설명한 대로 Azure 디스크에 대한 IOPS(초당 I/O 작업) 처리량에 대한 할당량이 존재합니다. 정확한 할당량은 사용되는 VM 유형에 따라 달라집니다. VM 유형 및 해당 할당량의 목록은 여기(Linux) 및 여기(Windows)에 있습니다.
디스크당 현재 IOPS 할당량이 충분한 경우 탑재된 단일 디스크에 모든 데이터베이스 파일을 저장할 수 있습니다. 그러나 항상 데이터 파일 및 트랜잭션 로그 파일을 서로 다른 디스크/VHD로 분리해야 합니다.
성능 고려 사항은 SAP 설치 가이드의 "데이터베이스 디렉터리에 대한 데이터 안전 및 성능 고려 사항" 장을 참조하세요.
또는 SAP 워크로드에 대한 Azure Virtual Machines DBMS 배포에 대한 고려 사항에 설명된 대로 Windows Server 2012 이상에서 사용할 수 있는 Windows Storage 풀을 사용할 수 있습니다. Linux에서 LVM 또는 MDADM을 사용하여 여러 디스크에 하나의 큰 논리 디바이스를 만들 수 있습니다.
Azure M 시리즈 VM의 경우 Azure 쓰기 가속기를 사용하면 Azure Premium Storage 성능에 비해 트랜잭션 로그에 대한 쓰기 대기 시간을 요소별로 줄일 수 있습니다. 따라서 Db2 트랜잭션 로그의 볼륨을 구성하는 하나 이상의 VHD에 대해 Azure 쓰기 가속기를 배포해야 합니다. 자세한 내용은 Write Accelerator 문서에서 참조할 수 있습니다.
IBM Db2 LUW 11.5는 4KB 섹터 크기에 대한 지원을 릴리스했습니다. 설명된 대로 db2set DB2_4K_DEVICE_SUPPORT=ON 의 구성 설정에서 11.5로 4KB 섹터 크기를 사용하도록 설정해야 합니다.
이전 Db2 버전의 경우 512바이트 섹터 크기를 사용해야 합니다. 프리미엄 SSD는 4KB 네이티브이며 512바이트 에뮬레이션이 있습니다. Ultra Disk는 기본적으로 4KB 섹터 크기를 사용합니다. Ultra Disk를 만드는 동안 512 바이트 섹터 크기를 사용하도록 설정할 수 있습니다. 자세한 내용은 Azure Ultra Disks를 사용하여 사용할 수 있습니다. 이 512바이트 섹터 크기는 IBM Db2 LUW의 버전 11.5보다 낮은 버전에 필요한 전제 조건입니다.
Windows에서 Db2 스토리지 경로 및 log_dir 디렉터리에 대한 sapdatasaptmp 스토리지 풀을 사용하는 경우 실제 디스크 섹터 크기를 512바이트로 지정해야 합니다. Windows 스토리지 풀을 사용하는 경우 -LogicalSectorSizeDefault 매개 변수를 사용하여 명령줄 인터페이스를 통해 수동으로 스토리지 풀을 만들어야 합니다. 자세한 내용은 New-StoragePool을 참조하세요.
IBM Db2 배포를 위한 VM 및 디스크 구조에 대한 권장 사항
SAP NetWeaver 애플리케이션용 IBM Db2는 SAP 지원 정보 1928533에 나열된 모든 VM 유형에서 지원됩니다. IBM Db2 데이터베이스를 실행하는 데 권장되는 VM 제품군은 대형 다중 TB 데이터베이스에 Esd_v4/Eas_v4/Es_v3 및 M/M_v2 시리즈입니다. M 시리즈 쓰기 가속기를 사용하도록 설정하면 IBM Db2 트랜잭션 로그 디스크의 쓰기 성능이 향상될 수 있습니다.
다음 표는 매우 작은 것부터 매우 큰 것까지 다양한 크기와 용도로 SAP가 Db2에서 배포되는 경우의 기준 구성을 나타냅니다.
중요함
나열된 VM 유형은 각 범주의 vCPU 및 메모리 조건을 충족하는 예제입니다. 스토리지 구성은 Azure Premium Storage v1을 기반으로 합니다. 프리미엄 SSD v2 및 Azure Ultra Disk는 IBM Db2에서도 완벽하게 지원되며 배포에 사용할 수 있습니다. 용량, 버스트 처리량 및 버스트 IOPS 값을 사용하여 Ultra Disk 또는 Premium SSD v2 구성을 정의합니다. 5000 IOPS 정도에서 /db2/<SID>/log_dir에 대한 IOPS를 제한할 수 있습니다. 이러한 기준 권장 사항이 요구 사항을 충족하지 않는 경우 처리량 및 IOPS를 특정 워크로드로 조정합니다.
이 기준은 50GB - 200GB(예: 솔루션 관리자)의 데이터베이스 크기에 대한 것입니다.
| VM 크기/예제 | Db2 탑재 지점 | Azure 프리미엄 디스크 | 디스크 수 | IOPS | 처리량 [MB/s] | 크기[GB] | 버스트 IOPS | 버스트 처리량 [GB] | 스트라이프 크기 | 캐싱 |
|---|---|---|---|---|---|---|---|---|---|---|
| vCPU: 4 | /db2 | P6 | 1 | 240 | 50 | 64 | 3,500 | 170 | ||
| RAM: ~32GiB | /db2/<SID>/sapdata |
P10 | 2 | 1,000 | 200 | 256 | 7,000 | 340 | 256 KB |
ReadOnly |
| E4(d)s_v5 | /db2//<SID>saptmp |
P6 | 1 | 240 | 50 | 128 | 3,500 | 170 | ||
| E4(d)as_v5 | /db2/<SID>/log_dir |
P6 | 2 | 480 | 100 | 128 | 7,000 | 340 | 64 KB |
|
| ... | /db2/<SID>/offline_log_directory (오프라인 로그 디렉토리) |
P10 | 1 | 500 | 100 | 128 | 3,500 | 170 |
Azure NetApp Files 사용
ANF(Azure NetApp Files)를 기반으로 하는 NFS v4.1 볼륨의 사용은 SUSE 또는 Red Hat Linux 게스트 OS에서 호스트되는 IBM Db2에서 지원됩니다. 다음과 같이 나열된 최소 4개의 서로 다른 볼륨을 만들어야 합니다.
- saptmp1, sapmnt, usr_sap,
<sid>_home, db2<sid>_home, db2_software에 대한 공유 볼륨 - sapdata1에서 sapdatan까지 하나의 데이터 볼륨
- 다시 실행 로그 디렉터리를 위한 하나의 로그 볼륨
- 로그 보관 및 백업을 위한 하나의 볼륨
다섯 번째 잠재적 볼륨은 Azure Blob 저장소에서 스냅샷을 만들고 저장하는 데 사용하는 보다 장기적인 백업에 사용하는 ANF 볼륨일 수 있습니다.
구성은 다음처럼 보일 수 있습니다.
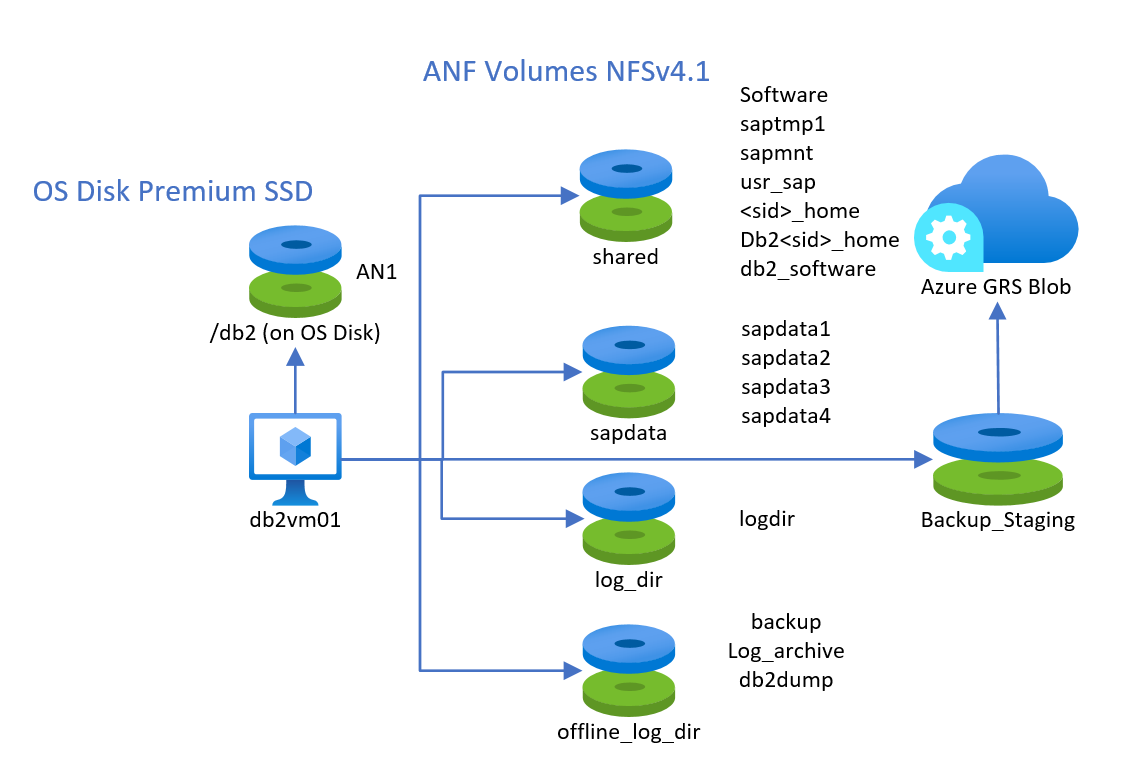
ANF 호스팅 볼륨의 성능 계층과 크기는 성능 요구 사항에 따라 선택해야 합니다. 그러나 데이터 및 로그 볼륨에 대해 Ultra 성능 수준을 사용하는 것이 좋습니다. 데이터 및 로그 볼륨에 대해 블록 스토리지와 공유 스토리지 유형을 혼합하는 것은 지원되지 않습니다.
탑재 옵션으로 이러한 볼륨 탑재는 다음과 같을 수 있습니다(SAP 시스템의 SID에 의해 <SID> 및 <sid> 교체).
vi /etc/idmapd.conf
# Example
[General]
Domain = defaultv4iddomain.com
[Mapping]
Nobody-User = nobody
Nobody-Group = nobody
mount -t nfs -o rw,hard,sync,rsize=262144,wsize=262144,sec=sys,vers=4.1,tcp 172.17.10.4:/db2shared /mnt
mkdir -p /db2/Software /db2/AN1/saptmp /usr/sap/<SID> /sapmnt/<SID> /home/<sid>adm /db2/db2<sid> /db2/<SID>/db2_software
mkdir -p /mnt/Software /mnt/saptmp /mnt/usr_sap /mnt/sapmnt /mnt/<sid>_home /mnt/db2_software /mnt/db2<sid>
umount /mnt
mount -t nfs -o rw,hard,sync,rsize=262144,wsize=262144,sec=sys,vers=4.1,tcp 172.17.10.4:/db2data /mnt
mkdir -p /db2/AN1/sapdata/sapdata1 /db2/AN1/sapdata/sapdata2 /db2/AN1/sapdata/sapdata3 /db2/AN1/sapdata/sapdata4
mkdir -p /mnt/sapdata1 /mnt/sapdata2 /mnt/sapdata3 /mnt/sapdata4
umount /mnt
mount -t nfs -o rw,hard,sync,rsize=262144,wsize=262144,sec=sys,vers=4.1,tcp 172.17.10.4:/db2log /mnt
mkdir /db2/AN1/log_dir
mkdir /mnt/log_dir
umount /mnt
mount -t nfs -o rw,hard,sync,rsize=262144,wsize=262144,sec=sys,vers=4.1,tcp 172.17.10.4:/db2backup /mnt
mkdir /db2/AN1/backup
mkdir /mnt/backup
mkdir /db2/AN1/offline_log_dir /db2/AN1/db2dump
mkdir /mnt/offline_log_dir /mnt/db2dump
umount /mnt
참고
탑재 매개 변수 hard 이며 sync필수입니다.
백업 및 복원
LUW용 IBM DB2의 백업/복원 기능은 표준 Windows Server 운영 체제 및 Hyper-V와 동일한 방법으로 지원됩니다. 유효한 데이터베이스 백업 전략이 있는지 확인합니다.
완전 배포에서처럼 백업/복원 성능은 병렬로 읽을 수 있는 볼륨 수와 이러한 볼륨의 처리량에 따라 달라집니다. 또한 백업 압축에서 사용하는 CPU 사용량은 최대 8개의 CPU 스레드가 있는 VM에서 중요한 역할을 수행할 수 있습니다. 따라서 다음을 가정할 수 있습니다.
- 데이터베이스 디바이스를 저장하는 데 사용하는 디스크 수가 적을수록 전반적인 읽기 처리량이 줄어듭니다.
- VM의 CPU 스레드 수가 적을수록 백업 압축에 대한 영향이 커집니다.
- 백업을 작성하는 대상(스트라이프 디렉터리, 디스크) 수가 적을수록 처리량이 줄어듭니다.
작성할 대상 수를 늘리려면 두 가지 옵션을 필요에 따라 사용/혼합할 수 있습니다.
- 여러 디스크에 백업 대상 볼륨을 스트라이프하여 해당 스트라이프 볼륨의 IOPS 처리량을 개선합니다.
- 둘 이상의 대상 디렉터리를 사용하여 백업을 작성합니다.
참고
Windows의 Db2는 Windows VSS 기술을 지원하지 않습니다. 따라서 Azure Backup Service의 애플리케이션 일치 VM 백업은 Db2 DBMS가 배포된 VM에 사용할 수 없습니다.
고가용성 및 재해 복구
Linux Pacemaker
중요함
Db2 버전 11.5.6 이상의 경우 IBM의 Pacemaker를 사용하는 통합 솔루션을 사용하는 것이 좋습니다.
Pacemaker를 사용하는 Db2 HADR(고가용성 재해 복구)이 지원됩니다. SLES 및 RHEL 운영 체제 모두 지원됩니다. 이 구성은 SAP용 IBM Db2의 고가용성을 보장합니다. 배포 가이드:
- SLES: Pacemaker를 사용하는 SUSE Linux Enterprise Server의 Azure VMs에 배포된 IBM Db2 LUW의 고가용성
- RHEL: Red Hat Enterprise Linux Server의 Azure VMs에서 IBM DB2 LUW의 고가용성
Windows 클러스터 서버
MSCS(Microsoft Cluster Server)라고도 하는 WSFC(Windows Server 장애 조치(failover) 클러스터)는 지원되지 않습니다.
DB2 HADR(고가용성 재해 복구)은 지원됩니다. HA 구성의 가상 머신에 이름 확인이 제대로 작동하는 경우 Azure에서의 설정은 온-프레미스에서의 설정과 아무런 차이가 없습니다. IP 해상도에만 의존하는 것은 권장되지 않습니다.
데이터베이스 디스크를 저장하는 스토리지 계정에는 지역 복제를 사용하지 마세요. 자세한 내용은 SAP 워크로드용 Azure Virtual Machines DBMS 배포 고려 사항 문서를 참조하세요.
가속화된 네트워킹
Windows의 Db2 배포에서는 Azure 가속화된 네트워킹 문서에 설명된 대로 가속화된 네트워킹의 Azure 기능을 사용하는 것이 좋습니다. 또한 SAP 워크로드용 Azure Virtual Machines DBMS 배포 시 고려 사항도 고려하세요.
Linux 배포에 대한 세부 정보
디스크당 현재 IOPS 할당량이 충분한 경우 단일 디스크에 모든 데이터베이스 파일을 저장할 수 있습니다. 그러나 항상 데이터 파일 및 트랜잭션 로그 파일을 서로 다른 디스크로 분리해야 합니다.
단일 Azure VHD의 IOPS 또는 I/O 처리량으로 충분하지 않은 경우 LVM(논리 볼륨 관리자) 또는 MDADM을 사용할 수 있습니다. 이러한 도구를 사용하면 SAP 워크로드에 대한 Azure Virtual Machines DBMS 배포에 대한 고려 사항에 설명된 대로 여러 디스크에 하나의 큰 논리 디바이스를 만들 수 있습니다.
사용자 sapdata 및 saptmp 디렉터리에 대한 Db2 스토리지 경로가 포함된 디스크의 경우 4KB의 실제 디스크 섹터 크기가 사용되는지 확인합니다. LVM 또는 MDADM을 사용하여 여러 디스크에 스트라이프 볼륨을 만드는 경우 큰 데이터베이스 워크로드에 대한 I/O 처리량을 최적화하도록 스트라이프 크기(또는 청크 크기)를 512KB로 구성합니다.
다음 단계
Azure 가용성 집합 또는 SAP 모니터링과 같은 다른 모든 일반 영역은 IBM Database를 사용하는 VM의 배포에도 적용됩니다. 이 일반 영역은 SAP 워크로드용 Azure Virtual Machines DBMS 배포 시 고려 사항에 설명되어 있습니다.