이 문서에서는 Azure IaaS에서 SAP 워크로드용 SQL Server를 배포할 때 고려해야 할 몇 가지 다른 영역에 대해 설명합니다. 이 설명서를 읽기 전에 SAP 워크로드를 위한 Azure Virtual Machines DBMS 배포 고려 사항 설명서와 Azure의 SAP 워크로드 설명서의 다른 가이드를 참조하세요.
중요합니다
이 문서의 범위는 SQL Server의 Windows 버전입니다. SAP는 어떤 SAP 소프트웨어에서도 Linux 버전의 SQL Server를 지원하지 않습니다. 이 문서에서는 Microsoft Azure 플랫폼의 PaaS(Platform as a Service) 제품인 Microsoft Azure SQL Database에 대해 설명하지 않습니다. 이 문서에서는 Azure의 IaaS(서비스 제공 인프라)를 활용하여 Azure Virtual Machines에서 온-프레미스 배포에 대해 알려진 SQL Server 제품을 실행하는 방법에 대해 설명합니다. 이러한 두 환경에서의 데이터베이스 기능은 다르므로 서로 혼합하지 않아야 합니다. 자세한 내용은 Azure SQL Database를 참조하세요.
일반적으로 최신 SQL Server 릴리스를 사용하여 Azure IaaS에서 SAP 작업을 실행하는 것이 좋습니다. 최신 SQL Server 릴리스는 Azure 서비스 및 기능 중 일부와 더 효율적으로 통합됩니다. 또는 Azure IaaS 인프라에서 작업을 최적화하도록 변경되었습니다.
Azure VM(Virtual Machines)에서 실행되는 SQL Server에 대한 일반 설명서는 다음 설명서에서 찾을 수 있습니다.
- Azure Virtual Machines의 SQL Server(Windows)
- Windows SQL Server IaaS 에이전트 확장으로 관리 자동화
- Azure VM에서 SQL Server에 대한 Azure Key Vault 통합 구성(Resource Manager)
- 검사 목록: Azure VM의 SQL Server에 대한 모범 사례
- 스토리지: Azure VM의 SQL Server에 대한 성능 모범 사례
- HADR 구성 모범 사례(Azure VM의 SQL Server)
Azure VM 설명서의 일반 SQL Server에 나와 있는 내용과 설명 중에는 SAP 워크로드에 적용되지 않는 부분도 있습니다. 그러나 해당 설명서를 읽어 보면 원칙에 대해 잘 이해할 수 있습니다. SAP 워크로드에서 지원되지 않는 기능의 예로는 FCI 클러스터링 사용을 들 수 있습니다.
계속하기 전에 다음과 같은 IaaS의 SQL Server 관련 정보를 참조하세요.
- SQL 버전 지원: SAP Note #1928533에 지원되는 최소 SQL Server 릴리스가 SQL Server 2008 R2라고 명시되어 있지만 Azure에서 지원되는 SQL Server 버전 창은 SQL Server의 수명 주기에 따라 결정됩니다. SQL Server 2012의 연장 유지 관리는 2022년 중순 종료되었습니다. 따라서 새로 배포된 시스템의 현재 최소 릴리스는 SQL Server 2014입니다. 최근일수록 더 좋습니다. 최신 SQL Server 릴리스는 Azure 서비스 및 기능 중 일부와 더 효율적으로 통합됩니다. 또는 Azure IaaS 인프라에서 작업을 최적화하도록 변경되었습니다.
- Azure Marketplace에서 이미지 사용: 새 Microsoft Azure VM을 배포하는 가장 빠른 방법은 Azure Marketplace의 이미지를 사용하는 것입니다. Azure Marketplace에는 최신 SQL Server 릴리스가 포함된 이미지가 있습니다. SQL Server가 이미 설치된 이미지는 SAP NetWeaver 애플리케이션에 즉시 사용할 수 없습니다. 그 이유는 기본 SQL Server 정렬이 해당 이미지에 설치되고 SAP NetWeaver 시스템에 필요한 정렬은 설치되지 않기 때문입니다. 이러한 이미지를 사용하려면 Microsoft Azure Marketplace에서 SQL Server 이미지 사용 챕터에서 설명하는 단계를 확인하세요.
- 단일 Azure VM 내에서 SQL Server 다중 인스턴스 지원: 이 배포 방법이 지원됩니다. 그러나 특히 사용 중인 VM 유형의 네트워크 및 스토리지 대역폭과 관련된 리소스 제한을 알고 있어야 합니다. 자세한 내용은 Azure의 가상 머신 크기 문서에서 확인할 수 있습니다. 이러한 할당량 제한으로 인해 온-프레미스에서 구현할 수 있는 것과 동일한 다중 인스턴스 아키텍처를 구현하지 못할 수 있습니다. 단일 VM 내에서 사용 가능한 리소스를 공유하는 구성 및 간섭의 경우 온-프레미스와 동일한 고려 사항이 필요합니다.
- 단일 VM의 단일 SQL Server 인스턴스에 있는 여러 SAP 데이터베이스: 이러한 구성이 지원됩니다. 단일 SQL Server 인스턴스의 공유 리소스를 공유하는 여러 SAP 데이터베이스에 대한 고려 사항은 온-프레미스 배포의 경우와 동일합니다. 특정 VM 유형에 연결할 수 있는 디스크 수와 같은 다른 제한을 염두에 두세요. 또는 세부적인 Azure의 가상 머신 크기와 같은 특정 VM 유형의 네트워크 및 스토리지 할당량 제한을 염두합니다.
새로운 M 시리즈 VM 및 SQL Server
Azure는 Mv3 제품군에 속하는 몇 가지 새로운 M 시리즈 SKU 제품군을 릴리스했습니다. Windows Server 게스트 OS에서 SMT(하이퍼스레딩)를 사용하지 않도록 설정하지 않고 SQL Server 2022를 포함하여 이 제품군의 일부 VM 유형을 SQL Server에 사용하면 안 됩니다. 그 이유는 Windows Server 게스트 운영 체제에 표시되는 NUMA 노드 수가 64개 이상의 vCPU를 포함하기 때문에 SQL Server가 이를 수용하기에는 너무 크기 때문입니다. Windows Server 게스트 운영 체제에서 SMT를 사용하지 않도록 설정하면 vCPU 수가 줄어듭니다. 따라서 각 NUMA 노드의 vCPU 수는 64개 미만입니다. SMT를 사용하지 않도록 설정하는 방법은 여기에 설명되어 있습니다. 구체적인 VM 형식은 다음과 같습니다.
- M176(d)s_3_v3 - SMT를 사용하지 않도록 설정하거나 M176bds_4_v3 또는 M176bds_4_v3을 대안으로 사용합니다.
- M176(d)s_4_v3 - SMT를 사용하지 않도록 설정하거나 M176bds_4_v3을 대안으로 사용
- M624(d)s_12_v3 - SMT 사용하지 않도록 설정하거나 M416ms_v2를 대안으로 사용
- M832(d)s_12_v3 - SMT 사용하지 않도록 설정하거나 M416ms_v2를 대안으로 사용
- M832i(d)s_16_v3 - SMT를 사용하지 않도록 설정하거나 M416ms_v2를 대안으로 사용
참고
일부 새로운 M(b)v3 VM 형식에서 읽기 캐시된 프리미엄 SSD v1 스토리지를 사용하면 읽기 및 쓰기 IOPS 속도와 처리량이 읽기 캐시를 사용하지 않는 경우보다 낮아질 수 있습니다.
SAP 관련 SQL Server 배포용 VM/VHD 구조에 대한 권장 사항
일반적인 설명, 운영 체제, SQL Server 실행 파일에 따라 SAP 실행 파일은 개별 Azure 디스크에 배치 또는 설치해야 합니다. 일반적으로 대부분의 SQL Server 시스템 데이터베이스는 SAP NetWeaver 워크로드에서 높은 수준으로 활용되지 않습니다. 그렇다고 하더라도 SQL Server의 시스템 데이터베이스는 별도의 Azure 디스크에 다른 SQL Server 디렉터리와 함께 사용해야 합니다. SQL Server tempdb는 비지속성 D:\ drive 또는 별도의 디스크에 있어야 합니다.
- 모든 SAP 인증 VM 형식(SAP Note #1928533 참조)의 경우 tempdb 데이터 및 로그 파일을 비지속형 D:\ 드라이브에 배치할 수 있습니다.
- SQL Server 릴리스의 경우 SQL Server가 tempdb를 하나의 데이터 파일로만 설치하므로 여러 tempdb 데이터 파일을 사용하는 것이 좋습니다. D:\ 드라이브 볼륨은 VM 유형에 따라 크기 및 기능이 다릅니다. 여러 VM의 D:\ 드라이브에 대한 정확한 크기는 Azure에서 Windows 가상 머신에 대한 크기 문서를 확인하세요.
이러한 구성을 사용하면 tempdb가 추가적인 공간을 활용할 수 있게 되어 시스템 드라이브에서 제공할 수 있는 것보다 더 중요한 IOPS(초당 I/O 작업) 및 스토리지 대역폭을 활용할 수 있습니다. 또한 비영구 D:\ 드라이브는 더 뛰어난 I/O 대기 시간 및 처리량을 제공합니다. 적절한 tempdb 크기를 결정하기 위해 기존 시스템에서 tempdb 크기를 확인할 수 있습니다.
참고
tempdb 데이터 파일과 로그 파일을 만든 D:\ 드라이브의 폴더에 저장하는 경우 VM을 다시 부팅한 후에 해당 폴더가 있는지 확인해야 합니다. VM이 다시 부팅되면 D:\ 드라이브가 새로 초기화될 수 있으므로, 모든 파일과 디렉터리의 구조가 초기화될 수 있습니다. SQL Server 서비스가 시작되기 전에 D:\ 드라이브에 최종 디렉터리 구조를 다시 만들 수 있는지에 대해서는 이 문서에서 설명합니다.
SQL Server와 SAP 데이터베이스를 실행하고 tempdb 데이터 및 tempdb 로그 파일이 D:\ 드라이브 및 Azure Premium Storage v1 또는 v2에 배치된 VM 구성은 다음과 같습니다.
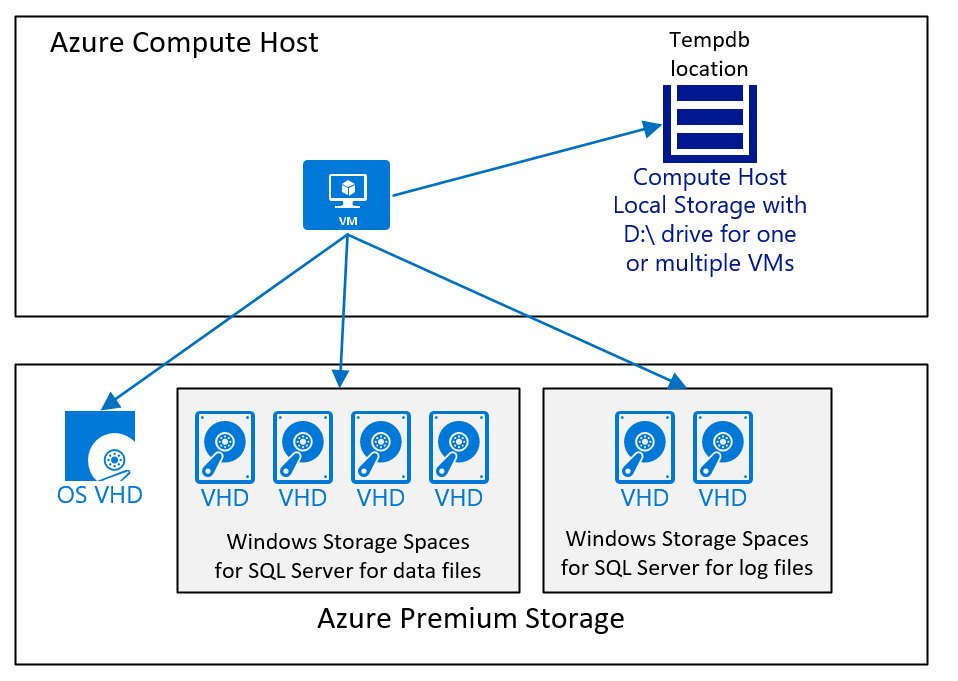
위 다이어그램은 간단한 경우를 보여 줍니다. SAP 워크로드용 Azure Virtual Machines DBMS 배포 시 고려 사항 문서에서 쉽게 이해되지 않았던 것처럼 디스크의 Azure 스토리지 유형, 수와 크기는 다양한 요소에 따라 다릅니다. 그러나 일반적으로 다음과 같이 권장됩니다.
- 더 작은 범위 및 중간 범위 배포의 경우 SQL Server 데이터 파일이 포함된 하나의 큰 볼륨을 사용합니다. 이렇게 구성하는 이유는 SQL Server 데이터 파일의 사용 가능한 공간이 동일하지 않은 경우 다른 I/O 워크로드를 더 쉽게 처리할 수 있기 때문입니다. 대규모 배포, 특히 고객이 다른 유형의 데이터베이스 마이그레이션을 사용하여 Azure의 SQL Server로 이동한 배포에서는 별도의 디스크를 사용한 다음 해당 디스크에 데이터 파일을 배포했습니다. 이러한 아키텍처는 각 디스크의 데이터 파일의 수가 동일하고, 모든 데이터 파일의 크기가 동일하고, 사용 가능한 공간도 거의 같은 경우에만 성공적으로 작동합니다.
- 성능이 충분하면 tempdb에 D:\ 드라이브를 사용합니다. D:\ 드라이브에 있는 tempdb의 성능으로 인해 전체 워크로드가 제한되는 경우 이 문서에서 권장하는 대로 tempdb를 Azure Premium Storage v1 또는 v2나 Ultra Disk로 이동해야 합니다.
SQL Server 비례 채우기 메커니즘은 모든 SQL Server 데이터 파일이 크기가 같고 사용 가능한 공간이 같으면 모든 데이터 파일에 읽기 및 쓰기를 균등하게 분산합니다. SQL Server의 SAP는 읽기와 쓰기가 사용 가능한 모든 데이터 파일에 균등하게 분산될 때 최상의 성능을 제공합니다. 데이터베이스에 데이터 파일이 너무 적거나 기존 데이터 파일이 매우 불균형한 경우 이를 수정하는 가장 좋은 방법은 R3load 내보내기 및 가져오기입니다. R3load 내보내기 및 가져오기에는 가동 중지 시간이 포함되며 해결해야 하는 명백한 성능 문제가 있는 경우에만 수행해야 합니다. 데이터 파일의 크기가 크게 다르지 않다면 모든 데이터 파일을 같은 크기로 늘리면 SQL Server가 시간이 지남에 따라 데이터를 리밸런싱합니다. 추적 플래그 1117이 설정되어 있거나 추적 플래그 없이 SQL Server 2016 이상을 사용하는 경우 SQL Server는 자동으로 데이터 파일을 균등하게 늘립니다.
M 시리즈 VM에 대한 특별 고려 사항
Azure M 시리즈 VM의 경우 Azure 쓰기 가속기를 사용하면 Azure Premium Storage 성능 v1에 비해 트랜잭션 로그의 대기 시간 기록을 줄일 수 있습니다. Premium Storage v1이 제공하는 대기 시간이 SAP 워크로드의 확장성을 제한하는 경우, SQL Server 트랜잭션 로그 파일을 저장하는 디스크를 쓰기 가속기에 사용하도록 설정할 수 있습니다. 자세한 내용은 Write Accelerator 문서에서 참조할 수 있습니다. Azure 쓰기 가속기는 Azure Premium Storage v2 및 Ultra Disk와 호환되지 않습니다. 두 경우 모두 대기 시간이 Azure Premium Storage v1이 제공하는 대기 시간보다 향상됩니다. 쓰기 가속기는 Premium SSD v2를 지원하지 않습니다.
참고
일부 새로운 M(b)v3 VM 형식에서 읽기 캐시된 프리미엄 SSD v1 스토리지를 사용하면 읽기 및 쓰기 IOPS 속도와 처리량이 읽기 캐시를 사용하지 않는 경우보다 낮아질 수 있습니다.
디스크 형식 설정
SQL Server의 경우 SQL Server 서버 데이터 및 로그 파일이 포함된 디스크의 NTFS 블록 크기는 64KB여야 합니다. D:\ 드라이브의 형식을 설정할 필요가 없습니다. 이 드라이브는 미리 포맷되어 있습니다.
파일의 내용을 제거하여 데이터베이스를 복원하거나 만들더라도 데이터 파일이 초기화되지 않도록 하려면 SQL Server 서비스가 실행되고 있는 사용자 컨텍스트에 사용자 권한 볼륨 유지 관리 작업 수행이 있는지 확인해야 합니다. 자세한 내용은 데이터베이스 인스턴스 파일 초기화를 참조하세요.
SQL Server 2014 및 최신 SQL Server 버전 - Azure Blob Storage에 데이터베이스 파일을 직접 저장
SQL Server 2014 이상 릴리스에서는 VHD의 '래퍼' 없이 Azure Blob Storage에 직접 데이터베이스 파일을 저장할 수 있습니다. 이 기능은 몇 년 전 Azure 블록 저장소의 단점을 해결하기 위한 것이었습니다. 요즘에는 이 배포 방법을 사용하지 말고, 대신 Azure Premium Storage v1, Premium Storage v2 또는 Ultra Disk를 선택하는 것이 좋습니다. 이는 요구 사항에 따라 다릅니다.
SQL Server에 대한 Backup/복구 고려 사항
Azure에 SQL Server를 배포하려면 백업 아키텍처를 검토해야 합니다. 시스템이 프로덕션 시스템이 아니더라도 SQL Server SAP 데이터베이스는 주기적으로 백업해야 합니다. Azure Storage에는 이제 세 개의 이미지가 있으므로 스토리지 작동 중단을 보완하는 측면에서 백업의 중요성이 줄어들었습니다. 적절한 백업 및 복구 계획을 유지하는 것이 중요한 이유는 논리적/수동 오류를 보상하기 위해 특정 시점 복구 기능을 제공하기 때문입니다. 목표는 백업을 사용하여 데이터베이스를 다시 특정 시점으로 복원하거나 또는 Azure의 백업을 사용하여 기존 데이터베이스 백업을 복사하여 다른 시스템에 시드를 적용할 수 있습니다.
Azure에서 SQL Server 데이터베이스를 백업하고 복원하는 방법에는 여러 가지가 있습니다. 최상의 개요와 세부 정보를 확인하려면 Azure VM에서 SQL Server 백업 및 복원 문서를 참조하세요. 이 문서에서는 여러 가지 가능성을 다루고 있습니다.
Microsoft Azure Marketplace에서 SQL Server 이미지 사용
Microsoft는 이미 SQL Server 버전이 포함되어 있는 Azure Marketplace에서 VM을 제공합니다. SQL Server 및 Windows에 대한 라이선스가 필요한 SAP 고객의 경우, 이러한 이미지를 사용하면 이미 SQL Server가 설치된 VM의 회전율을 높여 라이선스에 대한 요구 사항을 충족시킬 수 있습니다. SAP에 대한 이러한 이미지를 사용하려면 다음 사항을 고려해야 합니다.
- 평가판이 아닌 SQL Server 버전은 Azure Marketplace에서 배포한 'Windows 전용' VM보다 비용이 더 높습니다. 가격을 비교하려면 Windows Virtual Machines 가격 책정 및 SQL Server Enterprise Virtual Machines 가격 책정을 참조하세요.
- SAP 소프트웨어에서 지원하는 SQL Server 릴리스만 사용할 수 있습니다.
- Azure Marketplace에서 제공되는 VM에 설치되는 SQL Server 인스턴스의 데이터 정렬은 SAP NetWeaver에서 SQL Server 인스턴스를 실행하는 데 필요한 데이터 정렬이 아닙니다. 다음 섹션의 지침을 사용하여 데이터 정렬을 변경할 수 있습니다.
Microsoft Windows/SQL Server VM의 SQL Server 데이터 정렬 변경
Azure Marketplace의 SQL Server 이미지는 SAP NetWeaver 애플리케이션에 필요한 데이터 정렬을 사용하도록 설정되지 않았으므로 배포 직후에 데이터 정렬을 변경해야 합니다. SQL Server의 경우 이 정렬 변경은 VM을 배포하고 관리자가 배포된 VM에 로그인할 수 있게 되는 즉시 다음 단계를 통해 수행할 수 있습니다.
- 관리자 권한으로 Windows 명령 창을 엽니다.
- 디렉터리를 C:\Program Files\Microsoft SQL Server\110\Setup Bootstrap\SQLServer2012로 변경합니다.
- Setup.exe /QUIET /ACTION=REBUILDDATABASE /INSTANCENAME=MSSQLSERVER /SQLSYSADMINACCOUNTS=
<local_admin_account_name> /SQLCOLLATION=SQL_Latin1_General_Cp850_BIN2 명령을 실행합니다.<local_admin_account_name>은 갤러리를 통해 처음으로 VM을 배포할 때 관리자 계정으로 정의된 계정입니다.
이 프로세스는 몇 분밖에 안 걸립니다. 단계가 올바르게 수행되었는지 확인하려면 다음 단계를 수행하세요.
- SQL Server Management Studio를 엽니다.
- 쿼리 창을 엽니다.
- SQL Server master 데이터베이스에서 sp_helpsort 명령을 실행합니다.
다음과 같은 결과가 나와야 합니다.
Latin1-General, binary code point comparison sort for Unicode Data, SQL Server Sort Order 40 on Code Page 850 for non-Unicode Data
결과가 다른 경우 모든 SAP 배포를 중지하고 설치 명령이 예상대로 작동하지 않는 이유를 조사합니다. 언급한 것과 다른 SQL Server 코드 페이지를 사용하여 SAP NetWeaver 애플리케이션을 SQL Server 인스턴스에 배포하는 것은 NetWeaver 배포에서 지원되지 않습니다.
Azure의 SAP용 SQL Server 고가용성
SAP용 Azure IaaS 배포에서 SQL Server를 사용하면 데이터베이스 계층을 고가용성으로 배포하기 위해 추가할 수 있는 여러 가지 다른 가능성이 있습니다. Azure는 다른 Azure 블록 저장소, Azure 가용성 집합에 배포된 VM 쌍 또는 여러 Azure 가용성 영역에 걸쳐 배포된 VM 쌍을 사용하여 단일 VM에 대해 서로 다른 작동 시간 SLA를 제공합니다. 프로덕션 시스템의 경우 유연한 오케스트레이션을 통해 두 개의 가용성 영역에 걸쳐 가상 머신 확장 집합 내에 두 개의 VM을 배포해야 합니다. 자세한 내용은 SAP 워크로드에 대한 다양한 배포 유형 비교를 참조하세요. 하나의 VM이 활성 SQL Server 인스턴스를 실행합니다. 다른 VM은 수동 인스턴스를 실행합니다.
Windows 스케일 아웃 파일 서버나 Azure 공유 디스크를 사용하는 SQL Server 클러스터링
Microsoft는 Windows Server 2016에서 스토리지 공간 직접 배포를 도입했습니다. 스토리지 공간 다이렉트 배포에 따라 일반적으로 SQL Server FCI 클러스터링이 지원됩니다. 또한, Azure에서는 Windows 클러스터링에 사용할 수 있는 Azure 공유 디스크를 제공합니다. SAP 워크로드의 경우, 이러한 HA 옵션을 지원하지 않습니다.
SQL Server 로그 전달
고가용성 기능 중 하나로는 SQL Server 로그 전달이 있습니다. HA 구성에 참여하는 VM에 이름 확인 작업이 있으면 문제가 없습니다. Azure의 설정은 로그 전달 설정 및 로그 전달과 관련된 원칙과 관련하여 온-프레미스에서 수행되는 설정과 다르지 않습니다. SQL Server 로그 전달에 대한 자세한 내용은 로그 전달 정보(SQL Server) 문서에서 확인할 수 있습니다.
SQL Server 로그 전달 기능은 Azure에서 거의 사용되지 않아 하나의 Azure 지역 내에서 고가용성을 달성할 수 없었습니다. 그러나 다음 시나리오에서 SAP 고객은 Azure에서 성공적으로 로그 전달을 사용하고 있었습니다.
- Azure 지역 간 재해 복구 시나리오
- 온-프레미스에서 Azure 지역으로의 재해 복구 구성
- 온-프레미스에서 Azure로 전환하는 시나리오. 이러한 경우 로그 전달은 Azure의 새 데이터베이스 배포를 온-프레미스의 진행 중인 프로덕션 시스템과 동기화하는 데 사용됩니다. 전환 시점에는 프로덕션이 중단되고 마지막 최신 트랜잭션 로그 백업이 Azure 데이터베이스 배포로 전송되었는지 확인합니다. 그런 다음 Azure 데이터베이스 배포가 프로덕션에 공개됩니다.
SQL Server Always On (항상 켜짐)
Always On은 SAP 온-프레미스에 대해 지원되므로(SAP Note 1772688참조) Azure에서 SAP와 함께 지원됩니다. SQL Server 가용성 그룹 수신기(Azure 가용성 집합과는 다름)를 배포하는 것과 관련된 몇 가지 특별 고려 사항이 있습니다. 따라서 다른 설치 단계 몇 가지를 수행해야 합니다.
가용성 그룹 수신기를 사용하는 경우 몇 가지 고려 사항이 있습니다.
- 가용성 그룹 수신기는 Windows Server 2012 이상을 VM의 게스트 OS로 사용할 때만 사용할 수 있습니다. Windows Server 2012 경우 Windows Server 2008 R2 및 Windows Server 2012 기반 Microsoft Azure 가상 머신에서 SQL Server 가용성 그룹 수신기를 사용하도록 설정하는 업데이트가 적용되었는지 확인합니다.
- Windows Server 2008 R2의 경우 이 패치가 존재하지 않습니다. 이 경우 Always On은 데이터베이스 미러링과 동일한 방식으로 사용해야 합니다. 연결 문자열에 장애 조치(failover) 파트너를 지정(SAP default.pfl 매개 변수 dbs/mss/server를 통해 수행됨 - SAP Note #965908 참조)하면 됩니다.
- 가용성 그룹 수신기를 사용하여 데이터베이스 VM을 전용 Load Balancer에 연결해야 합니다. Always On 구성에서 해당 VM의 네트워크 인터페이스에 고정 IP 주소를 할당해야 합니다(고정 IP 주소 정의는 이 문서 에서 확인). DHCP와 비교하여 고정 IP 주소는 두 VM이 모두 중지될 수 있는 경우 새 IP 주소가 할당되는 것을 방지합니다.
- 현재 기능의 Azure는 클러스터가 만들어진 노드와 동일한 IP 주소를 클러스터 이름에 할당하므로 클러스터에 특정 IP 주소를 할당해야 하는 WSFC 클러스터를 구성할 때는 특별한 단계가 필요합니다. 이러한 동작은 클러스터에 다른 IP 주소를 할당하기 위해서는 수동 단계를 수행해야 함을 의미합니다.
- 가용성 그룹 수신기는 가용성 그룹의 기본 및 보조 복제본을 실행 중인 VM에 할당된 TCP/IP 엔드포인트를 사용하여 Azure에서 만들어집니다.
- 이러한 엔드포인트는 ACL로 보호해야 할 수 있습니다.
Azure VM에 SQL Server와 함께 Always On을 배포하는 방법에 대한 자세한 설명서는 다음과 같습니다.
- Azure Virtual Machines의 SQL Server Always On 가용성 그룹 소개
- 다른 하위 지역의 Azure Virtual Machines에서 Always On 가용성 그룹 구성
- Azure에서 Always On 가용성 그룹에 대한 부하 분산 장치 구성
- HADR 구성 모범 사례(Azure VM의 SQL Server)
참고
Azure Virtual Machines의 SQL Server Always On 가용성 그룹 소개에서 SQL Server의 DNN(직접 네트워크 이름) 수신기에 대해 읽어 보세요. 이 새로운 기능은 SQL Server 2019 CU8에 도입되었습니다. 이 새로운 기능으로 인해 가용성 그룹 수신기의 가상 IP 주소를 처리하는 Azure 부하 분산 장치의 사용이 더 이상 사용되지 않습니다.
SQL Server Always On은 SAP 워크로드용 Azure 배포에 가장 일반적으로 사용되는 고가용성 및 재해 복구 기능입니다. 대부분의 고객은 단일 Azure 지역 내의 고가용성을 위해 Always On을 사용합니다. 배포가 두 개의 노드로만 제한되는 경우 두 가지 연결 옵션이 있습니다.
- 가용성 그룹 수신기 사용. 가용성 그룹 수신기를 사용하여 Azure 부하 분산 장치를 배포해야 합니다.
- Windows Server 2016 이상에서 SQL Server 2016 SP3, SQL Server 2017 CU 25 또는 SQL Server 2019 CU8 이상의 최신 SQL Server 릴리스를 사용하는 경우 Azure Load Balancer 대신 DNN(직접 네트워크 이름) 수신기를 사용할 수 있습니다. DNN은 Azure 부하 분산 장치에 대한 요구 사항을 제거합니다.
SQL Server 데이터베이스 미러링의 연결 매개 변수를 사용하는 것은 다른 두 방법에 문제가 생겼을 경우 이를 조사하는 상황에만 고려해야 합니다. 이 경우 두 노드의 이름이 지정된 방식으로 SAP 애플리케이션의 연결을 구성해야 합니다. 이러한 SAP 쪽 구성에 대한 정확한 세부 정보는 SAP Note #965908에서 설명하고 있습니다. 이 옵션을 사용하면 가용성 그룹 수신기를 구성할 필요가 없습니다. 또한 Azure Load Balancer가 없고, 이 방법으로 해당 구성 요소의 문제를 조사할 수 있는 상황이어야 합니다. 그러나 이 옵션은 가용성 그룹이 두 인스턴스에 걸쳐 있도록 제한하는 경우에만 작동합니다.
대부분의 고객은 Azure 지역 간 재해를 복구하기 위해 SQL Server Always On 기능을 사용합니다. 일부 고객은 보조 복제본에서 백업을 수행하는 기능도 사용합니다.
SQL Server 투명한 데이터 암호화
Azure에 SAP SQL Server 데이터베이스를 배포할 때 SQL Server TDE(투명한 데이터 암호화)를 사용하는 고객이 많이 있습니다. SQL Server TDE 기능은 SAP에서 완벽하게 지원됩니다(SAP Note #1380493 참조).
SQL Server TDE 적용
온-프레미스에서 실행되는 다른 데이터베이스에서 Azure에서 실행되는 Windows/SQL Server로 이기종 마이그레이션을 수행하는 경우 미리 SQL Server에 빈 대상 데이터베이스를 만들어야 합니다. 다음 단계에서는 이러한 빈 데이터베이스에 SQL Server TDE 기능을 적용하게 됩니다. 이 순서로 수행하려는 이유는 빈 데이터베이스를 암호화하는 프로세스에 시간이 상당히 오래 걸릴 수 있다는 것입니다. 그러면 SAP 가져오기 프로세스에서 가동 중지 시간 단계 동안 데이터를 암호화된 데이터베이스로 가져옵니다. 암호화된 데이터베이스로 가져오는 오버헤드는 가동 중지 시간 단계에서 내보내기 단계 이후에 데이터베이스를 암호화하는 것보다 시간으로 인한 영향이 훨씬 적습니다. 데이터베이스 상에서 SAP 워크로드를 실행하면서 TDE를 적용하려고 시도했을 때 부정적인 환경이 있었습니다. 따라서 TDE 배포는 특정 데이터베이스에서 SAP 워크로드 없이, 또는 적은 양의 SAP 워크로드로 수행해야 하는 작업으로 취급하는 것이 좋습니다. SQL Server 2016부터는 초기 암호화를 수행하는 TDE 검사를 중지 및 다시 시작할 수 있습니다. TDE(투명한 데이터 암호화) 문서에서 명령 및 세부 정보를 확인할 수 있습니다.
SAP SQL Server 데이터베이스를 온-프레미스에서 Azure로 이동하는 경우 암호화를 가장 빠르게 적용할 수 있는 인프라에서 테스트하는 것이 좋습니다. 이 경우에는 다음 사실에 유념하세요.
- 데이터베이스에 데이터 암호화를 적용하는 데 사용되는 스레드 수는 정의할 수 없습니다. 스레드 수는 주로 SQL Server 데이터 및 로그 파일이 분산되는 디스크 볼륨의 수에 따라 달라집니다. 즉, 고유 볼륨(드라이브 문자)이 많을수록 암호화를 수행하기 위해 병렬로 사용되는 스레드가 많아집니다. 이러한 구성은 Azure VM에서 SQL Server 데이터베이스 파일용 스토리지 공간을 하나 또는 여러 개를 구축하는 경우의 이전 디스크 구성 제안과 약간 충돌합니다. 볼륨 수가 적은 구성에서는 암호화를 실행하는 스레드 수가 적습니다. 단일 스레드 암호화는 64KB 익스텐트를 읽고, 암호화한 다음, 익스텐트가 암호화되었음을 알리는 레코드를 트랜잭션 로그 파일에 기록합니다. 결과적으로 트랜잭션 로그의 부하는 중간 수준입니다.
- 이전의 SQL Server 릴리스에서는 SQL Server 데이터베이스를 암호화할 때 백업 압축이 더 이상 효율적이지 못했습니다. SQL Server 데이터베이스를 온-프레미스에서 암호화한 다음, 백업을 Azure에 복사하여 Azure에서 데이터베이스를 복원하려고 했을 때 이 동작은 문제로 발전할 수 있었습니다. SQL Server 백업 압축은 요인 4의 압축 비율을 달성할 수 있습니다.
- SQL Server 2016에서 SQL Server는 암호화된 데이터베이스의 백업도 효율적인 방식으로 압축할 수 있는 새로운 기능을 도입했습니다. 자세한 내용은 이 블로그를 참조하세요.
Azure Key Vault 사용
Azure는 암호화 키를 저장하기 위해 Key Vault 서비스를 제공합니다. 다른 쪽의 SQL Server는 Azure Key Vault를 TDE 인증서 저장소로 사용할 수 있는 커넥터를 제공합니다.
SQL Server TDE에 Azure Key Vault를 사용하는 방법에 대한 자세한 내용은 다음 문서에 나와 있습니다.
- Azure VM에서 SQL Server에 대한 Azure Key Vault 통합 구성(Resource Manager)
- SQL Server 투명한 데이터 암호화에 대한 고객의 자세한 질문 - TDE + Azure Key Vault
중요합니다
특히 Azure Key Vault에서 SQL Server TDE를 사용하는 경우 SQL Server 2014, SQL Server 2016 및 SQL Server 2017의 최신 패치를 사용하는 것이 좋습니다. 이는 고객의 피드백에 따라 최적화 및 수정이 코드에 적용되었기 때문입니다. 예를 들어 KBA #4058175를 확인하세요.
최소 배포 구성
이 섹션에서는 SAP 워크로드에서의 다양한 데이터베이스 크기에 대한 일련의 최소 구성을 제안합니다. 어떤 크기가 특정 워크로드에 적합한지 평가하는 것은 매우 어렵습니다. 때때로 데이터베이스 크기에 비해 메모리가 넉넉한 경우가 있습니다. 어떤 경우에는 디스크 크기가 일부 워크로드에 비해 너무 작을 수도 있습니다. 따라서 이러한 구성은 있는 그대로 취급되어야 합니다. 이러한 구성을 통해 시작 지점을 알 수 있어야 합니다. 이후 특정 워크로드 및 비용 효율성 요구 사항에 맞게 이러한 구성을 미세 조정하는 것입니다.
데이터베이스 크기가 50~250GB인 소규모 SQL Server 인스턴스에 대한 구성의 예는 다음과 같습니다.
| 구성 | 데이터베이스 VM | 주석 |
|---|---|---|
| VM 유형 | E4s_v3/v4/v5(4 vCPU/32GiB RAM) | |
| 가속 네트워킹 | 사용 | |
| SQL Server 버전 | SQL Server 2019 이상 | |
| 데이터 파일 수 | 4 | |
| 로그 파일 수 | 1 | |
| 임시 데이터 파일 수 | 4 또는 SQL Server 2016 이후 기본값 | |
| 운영 체제 | Windows Server 2019 이상 | |
| 디스크 집계 | 원하는 경우 저장소 공간 | |
| 파일 시스템 | NTFS | |
| 포맷 블록 크기 | 64KB | |
| 데이터 디스크 수 및 유형 | Premium Storage v1: 2개 x P10(RAID0) Premium Storage v2: 2 x 150GiB(RAID0) - 기본 IOPS 및 처리량 또는 동급 Premium SSD v2 |
캐시 = Premium Storage v1의 경우 읽기 전용 |
| 로그 디스크 수 및 유형 | Premium Storage v1: 1개 x P20 Premium Storage v2: 1 x 128GiB - 기본 IOPS 및 처리량 또는 동급 Premium SSD v2 |
캐시 = 없음 |
| SQL Server 최대 메모리 매개 변수 | 실제 RAM의 90% | 단일 인스턴스 가정 |
소규모 SAP Business Suite 시스템과 같이 데이터베이스 크기가 250~750GB인 소규모 SQL Server 인스턴스에 대한 구성의 예는 다음과 같습니다.
| 구성 | 데이터베이스 VM | 주석 |
|---|---|---|
| VM 유형 | E16s_v3/v4/v5(16 vCPU/128GiB RAM) | |
| 가속 네트워킹 | 사용 | |
| SQL Server 버전 | SQL Server 2019 이상 | |
| 데이터 파일 수 | 8 (여덟) | |
| 로그 파일 수 | 1 | |
| 임시 데이터 파일 수 | 8 또는 SQL Server 2016 이후 기본값 | |
| 운영 체제 | Windows Server 2019 이상 | |
| 디스크 집계 | 원하는 경우 저장소 공간 | |
| 파일 시스템 | NTFS | |
| 포맷 블록 크기 | 64KB | |
| 데이터 디스크 수 및 유형 | Premium Storage v1: 4개 x P20(RAID0) Premium Storage v2: 4 x 100GiB - 200GiB(RAID0) - 기본 IOPS 및 디스크당 25MB/초 추가 처리량 또는 동급 Premium SSD v2 |
캐시 = Premium Storage v1의 경우 읽기 전용 |
| 로그 디스크 수 및 유형 | Premium Storage v1: 1개 x P20 Premium Storage v2: 1 x 200GiB - 기본 IOPS 및 처리량 또는 동급 Premium SSD v2 |
캐시 = 없음 |
| SQL Server 최대 메모리 매개 변수 | 실제 RAM의 90% | 단일 인스턴스 가정 |
소규모 SAP Business Suite 시스템과 같이 데이터베이스 크기가 750~2,000GB인 중간 규모 SQL Server 인스턴스에 대한 구성의 예는 다음과 같습니다.
| 구성 | 데이터베이스 VM | 주석 |
|---|---|---|
| VM 유형 | E64s_v3/v4/v5(64 vCPU/432GiB RAM) | |
| 가속 네트워킹 | 사용 | |
| SQL Server 버전 | SQL Server 2019 이상 | |
| 데이터 디바이스 수 | 16 | |
| 로그 디바이스 수 | 1 | |
| 임시 데이터 파일 수 | 8 또는 SQL Server 2016 이후 기본값 | |
| 운영 체제 | Windows Server 2019 이상 | |
| 디스크 집계 | 원하는 경우 저장소 공간 | |
| 파일 시스템 | NTFS | |
| 포맷 블록 크기 | 64KB | |
| 데이터 디스크 수 및 유형 | Premium Storage v1: 4개 x P30(RAID0) Premium Storage v2: 4 x 250GiB - 500GiB - 디스크당 2,000 IOPS 및 75MB/초 처리량 또는 동급 Premium SSD v2 |
캐시 = Premium Storage v1의 경우 읽기 전용 |
| 로그 디스크 수 및 유형 | Premium Storage v1: 1개 x P20 Premium Storage v2: 1 x 400GiB - 기본 IOPS 및 75MB/초 추가 처리량 또는 동급 Premium SSD v2 |
캐시 = 없음 |
| SQL Server 최대 메모리 매개 변수 | 실제 RAM의 90% | 단일 인스턴스 가정 |
대규모 SAP Business Suite 시스템과 같이 데이터베이스 크기가 2,000~4,000GB인 대규모 SQL Server 인스턴스에 대한 구성의 예는 다음과 같습니다.
| 구성 | 데이터베이스 VM | 주석 |
|---|---|---|
| VM 유형 | E96(d)s_v5(96개 vCPU/672GiB RAM) | |
| 가속 네트워킹 | 사용 | |
| SQL Server 버전 | SQL Server 2019 이상 | |
| 데이터 디바이스 수 | 24 | |
| 로그 디바이스 수 | 1 | |
| 임시 데이터 파일 수 | 8 또는 SQL Server 2016 이후 기본값 | |
| 운영 체제 | Windows Server 2019 이상 | |
| 디스크 집계 | 원하는 경우 저장소 공간 | |
| 파일 시스템 | NTFS | |
| 포맷 블록 크기 | 64KB | |
| 데이터 디스크 수 및 유형 | Premium Storage v1: 4개 x P30(RAID0) Premium Storage v2: 4 x 500GiB - 800GiB - 디스크당 2500 IOPS 및 100MB/초 처리량 추가 또는 동급 Premium SSD v2 |
캐시 = Premium Storage v1의 경우 읽기 전용 |
| 로그 디스크 수 및 유형 | Premium Storage v1: 1개 x P20 Premium Storage v2: 1 x 400GiB - 1,000 IOPS 및 75MB/초 추가 처리량 또는 동급 Premium SSD v2 |
캐시 = 없음 |
| SQL Server 최대 메모리 매개 변수 | 실제 RAM의 90% | 단일 인스턴스 가정 |
전역적으로 사용되는 대규모 SAP Business Suite 시스템과 같이 데이터베이스 크기가 4TB 이상인 대규모 SQL Server 인스턴스에 대한 구성의 예는 다음과 같습니다.
| 구성 | 데이터베이스 VM | 주석 |
|---|---|---|
| VM 유형 | M 시리즈(1.0 ~4.0TB RAM) | |
| 가속 네트워킹 | 사용 | |
| SQL Server 버전 | SQL Server 2019 이상 | |
| 데이터 디바이스 수 | 32 | |
| 로그 디바이스 수 | 1 | |
| 임시 데이터 파일 수 | 8 또는 SQL Server 2016 이후 기본값 | |
| 운영 체제 | Windows Server 2019 이상 | |
| 디스크 집계 | 원하는 경우 저장소 공간 | |
| 파일 시스템 | NTFS | |
| 포맷 블록 크기 | 64KB | |
| 데이터 디스크 수 및 유형 | Premium Storage v1: 4+ x P40(RAID0) Premium Storage v2: 4+ x 1,000GiB - 4,000GiB - 디스크당 4,500 IOPS 및 125MB/초 처리량 또는 동급 Premium SSD v2 |
캐시 = Premium Storage v1의 경우 읽기 전용 |
| 로그 디스크 수 및 유형 | Premium Storage v1: 1개 x P30 Premium Storage v2: 1 x 500GiB - 2,000 IOPS 및 125MB/초 처리량 또는 동급 Premium SSD v2 |
캐시 = 없음 |
| SQL Server 최대 메모리 매개 변수 | 실제 RAM의 95% | 단일 인스턴스 가정 |
예를 들어, 이 구성은 SQL Server에서 SAP Business Suite의 데이터베이스 VM 구성입니다. 이 VM은 연간 $200B 이상의 매출을 올리며 상근 직원을 200K명 이상 보유한 글로벌 회사의 단일 전역 SAP Business Suite 인스턴스의 30TB 규모 데이터베이스를 호스팅합니다. 이 시스템은 모든 재무 처리, 판매 및 유통 처리는 물론 북아메리카 지역의 급료 지불을 비롯한 다양한 영역 등 매우 다양한 비즈니스 프로세스를 실행합니다. 이 시스템은 2018년 초부터 Azure M 시리즈 VM을 데이터베이스 VM으로 사용하여 Azure에서 실행되고 있습니다. 고가용성을 위해 시스템은 동일한 Azure 지역의 다른 가용성 영역에 동기 복제본 하나를 두고 Always On을 사용합니다. 그리고 또 다른 Azure 지역에 비동기 복제본이 있습니다. NetWeaver 애플리케이션 계층은 최신 D(a)/E(a) VM 제품군에 배포됩니다.
| 구성 | 데이터베이스 VM | 주석 |
|---|---|---|
| VM 유형 | M192dms_v2(192 vCPU/4,196GiB RAM) | |
| 가속 네트워킹 | 활성화됨 | |
| SQL Server 버전 | SQL Server 2019 | |
| 데이터 파일 수 | 32 | |
| 로그 파일 수 | 1 | |
| 임시 데이터 파일 수 | 8 (여덟) | |
| 운영 체제 | Windows Server 2019 | |
| 디스크 집계 | 스토리지 공간 | |
| 파일 시스템 | NTFS | |
| 포맷 블록 크기 | 64KB | |
| 데이터 디스크 수 및 유형 | Premium Storage v1: 16 x P40 또는 동급 Premium SSD v2 | 캐시 = 읽기 전용 |
| 로그 디스크 수 및 유형 | Premium Storage v1: 1 x P60 또는 동급 Premium SSD v2 | 쓰기 가속기 사용 |
| tempdb 디스크 수 및 유형 | Premium Storage v1: 1 x P30 또는 동급 Premium SSD v2 | 캐싱 없음 |
| SQL Server 최대 메모리 매개 변수 | 실제 RAM의 95% |
Azure의 SAP용 SQL Server에 대한 일반적 요약
이 가이드에는 많은 권장 사항이 있으며 Azure 배포를 계획하기 전에 두 번 이상 읽는 것이 좋습니다. 일반적으로 Azure의 SQL Server에 대한 주요 권장 사항을 따릅니다.
- Azure에서 가장 많은 이점을 제공하는 SQL Server 2022와 같은 최신 SQLServer 릴리스를 사용합니다.
- 데이터 파일 레이아웃과 Azure 제한 사항 균형을 조정하도록 Azure에서 SAP 시스템 배경을 신중하게 계획합니다.
- 디스크가 너무 많으면 안 되지만 필요한 IOPS에 도달할 수 있을 만큼 충분해야 합니다.
- 더 높은 처리량이 필요한 경우에만 디스크를 스트라이프합니다.
- 디스크가 너무 많으면 안 되지만 필요한 IOPS에 도달할 수 있을 만큼 충분해야 합니다.
- D:\ 드라이브는 영구적이지 않으므로 이 드라이브에 소프트웨어를 설치하거나 영구 보존이 필요한 파일을 두지 마세요. 이 드라이브에 있는 모든 내용은 Windows 다시 부팅이나 VM 다시 시작 시 손실될 수 있습니다.
- SQL Server Always On 솔루션을 사용하여 데이터베이스 데이터를 복제합니다.
- 항상 이름 확인을 사용하고 IP 주소를 사용하지 마세요.
- SQL Server TDE를 사용하여 최신 SQL Server 패치를 적용합니다.
- Azure Marketplace의 SQL Server 이미지를 사용할 때는 주의하세요. SQL Server 이미지를 사용하는 경우 SAP NetWeaver 시스템을 설치하기 전에 인스턴스 데이터 정렬을 변경해야 합니다.
- 배포 가이드에서 설명한 대로 Azure용 SAP 호스트 모니터링을 설치 및 구성합니다.
다음 단계
문서 읽기