이 문서에서는 RHEL(Red Hat Enterprise Server)에서 기본 Pacemaker 클러스터를 구성하는 방법을 설명합니다. 지침에는 RHEL 7, RHEL 8 및 RHEL 9가 포함됩니다.
필수 구성 요소
다음 SAP Note 및 문서를 먼저 읽어 보세요.
RHEL HA(고가용성) 설명서
Azure 관련 RHEL 설명서
SAP 제품에 대한 RHEL 설명서
개요
중요합니다
여러 VNet(가상 네트워크)/서브넷에 걸쳐 있는 Pacemaker 클러스터는 표준 지원 정책에서 다루지 않습니다.
RHEL용 pacemaker 클러스터에서 펜싱을 구성하기 위해 Azure 사용할 수 있는 두 가지 옵션이 있습니다. Azure 펜스 에이전트는 Azure API를 통해 실패한 노드를 다시 시작하거나 SBD 디바이스를 사용할 수 있습니다.
중요합니다
Azure에서 스토리지 기반 펜싱(fence_sbd)을 사용하는 RHEL 고가용성 클러스터는 소프트웨어로 에뮬레이트된 워치독을 사용합니다. 펜싱 메커니즘으로 SBD를 선택할 때 Software-Emulated Watchdog의 알려진 제한 사항 및 sbd와 fence_sbd를 포함한 RHEL 고가용성 클러스터에 대한 지원 정책을 검토하는 것이 중요합니다.
SBD 디바이스 사용
참고
SBD를 사용한 펜싱 메커니즘은 RHEL 8.8 이상 및 RHEL 9.0 이상에서 지원됩니다.
다음 두 옵션 중 하나를 사용하여 SBD 디바이스를 구성할 수 있습니다.
iSCSI 대상 서버가 있는 SBD
SBD 디바이스에는 iSCSI(Internet Small Compute System Interface) 대상 서버 역할을 하고 SBD 디바이스를 제공하는 추가 VM(가상 머신)이 하나 이상 필요합니다. 단, 이러한 iSCSI 대상 서버를 다른 pacemaker 클러스터와 공유할 수 있습니다. SBD 디바이스를 사용할 때의 장점은 이미 온-프레미스에서 SBD 디바이스를 사용하고 있는 경우 pacemaker 클러스터를 작동하는 방법을 변경할 필요가 없다는 것입니다.
예를 들어, iSCSI 대상 서버의 OS 패치 동안 pacemaker 클러스터에서 SBD 디바이스를 사용할 수 없게 하도록 하려면 최대 3개의 SBD 디바이스를 사용할 수 있습니다. pacemaker당 2개 이상의 SBD 디바이스를 사용하려는 경우 여러 iSCSI 대상 서버를 배포하고 각 iSCSI 대상 서버에서 하나의 SBD를 연결해야 합니다. SBD 디바이스를 1개 또는 3개 사용하는 것이 좋습니다. 두 개의 SBD 디바이스만 구성되어 있고 그중 하나를 사용할 수 없는 경우 Pacemaker는 클러스터 노드를 자동으로 차단할 수 없습니다. 하나의 iSCSI 대상 서버가 다운되었을 때 방어하려면 3개의 SBD 디바이스, 즉 3개의 iSCSI 대상 서버를 사용해야 합니다. SBD를 사용할 때 가장 탄력적인 구성입니다.
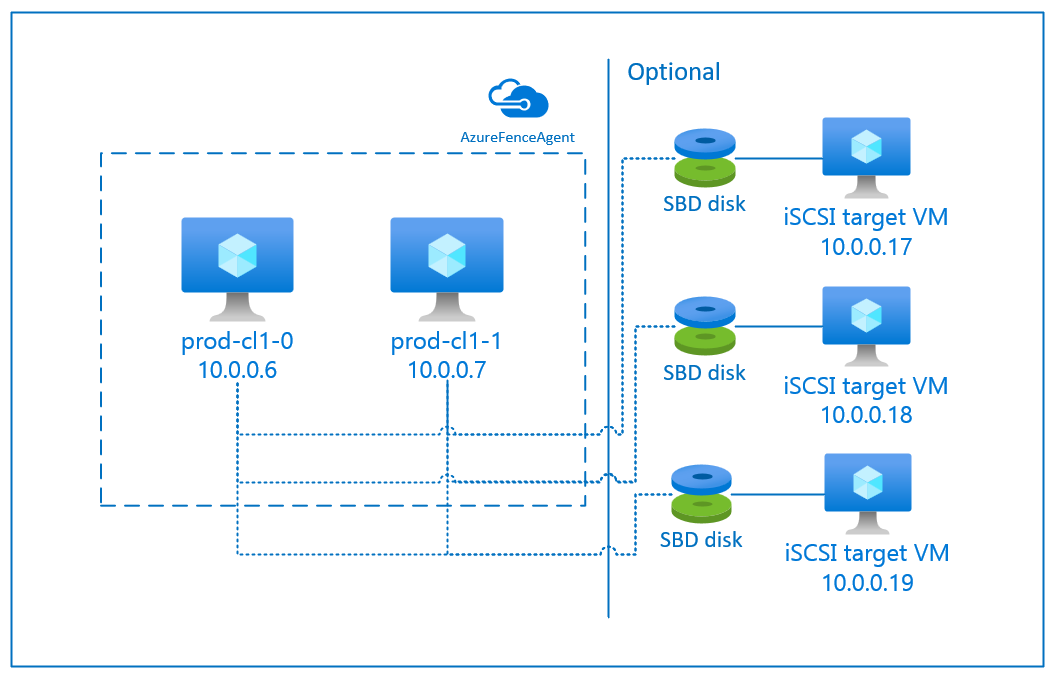
중요합니다
Linux Pacemaker 클러스터 노드 및 SBD 디바이스를 배포하고 구성하려는 경우 가상 머신과 SBD 디바이스를 호스팅하는 VM 간의 라우팅이 NVA(네트워크 가상 어플라이언스)와 같은 다른 디바이스를 통과하도록 허용하지 않습니다.
유지 관리 이벤트 및 NVA와 관련된 기타 문제는 전체 클러스터 구성의 안정성 및 안정성에 부정적인 영향을 미칠 수 있습니다. 자세한 내용은 사용자 정의 라우팅 규칙을 참조하세요.
Azure 공유 디스크가 있는 SBD
SBD 디바이스를 구성하려면 pacemaker 클러스터의 일부인 모든 가상 머신에 하나 이상의 Azure 공유 디스크를 연결해야 합니다. Azure 공유 디스크를 사용하는 SBD 디바이스의 장점은 추가 가상 머신을 배포하고 구성할 필요가 없다는 것입니다.
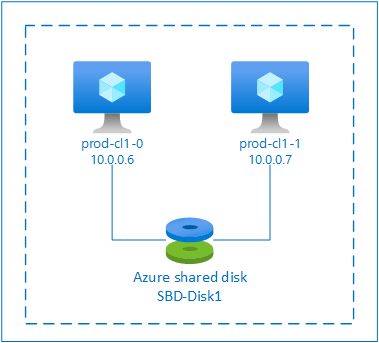
다음은 Azure 공유 디스크를 사용하여 구성할 때 SBD 디바이스에 대한 몇 가지 중요한 고려 사항입니다.
- 프리미엄 SSD를 사용하는 Azure 공유 디스크는 SBD 디바이스로 지원됩니다.
- Azure 공유 디스크를 사용하는 SBD 디바이스는 RHEL 8.8 이상에서 지원됩니다.
- Azure 프리미엄 공유 디스크를 사용하는 SBD 디바이스는 LRS(로컬 중복 스토리지) 및 존 중복 스토리지(ZRS) 지원됩니다.
- 배포의 유형에 따라 Azure 공유 디스크에 대한 적절한 중복 스토리지를 SBD 디바이스로 선택합니다.
- Azure 프리미엄 공유 디스크(skuName - Premium_LRS)에 LRS를 사용하는 SBD 장치는 지역 배포, 예를 들어 가용성 설정에서만 지원됩니다.
- Azure 프리미엄 공유 디스크(skuName - Premium_ZRS)에서 ZRS를 활용하는 SBD 디바이스를 운영할 때는 동일 가용성 영역 내 배포하거나, FD=1로 설정된 확장 집합을 사용하는 것이 권장됩니다.
- 관리 디스크용 ZRS는 현재 지역 가용성 문서에 나열된 지역에서 사용할 수 있습니다.
- SBD 디바이스에 사용하는 Azure 공유 디스크는 클 필요가 없습니다. maxShares 값은 공유 디스크를 사용할 수 있는 클러스터 노드 수를 결정합니다. 예를 들어 SAP ASCS/ERS 또는 SAP HANA 확장과 같은 2노드 클러스터에서 SBD 디바이스에 P1 또는 P2 디스크 크기를 사용할 수 있습니다.
- HANA HSR(시스템 복제) 및 pacemaker를 사용한 HANA 스케일 아웃의 경우 현재 제한인 maxShares 때문에 복제 사이트당 최대 5개의 노드가 있는 클러스터의 SBD 디바이스에 Azure 공유 디스크를 사용할 수 있습니다.
- pacemaker 클러스터에서 Azure 공유 디스크 SBD 디바이스를 연결하지 않는 것이 좋습니다.
- 여러 Azure 공유 디스크 SBD 디바이스를 사용하는 경우 VM에 연결할 수 있는 최대 데이터 디스크 수에 대한 제한을 확인합니다.
- Azure 공유 디스크의 제한 사항에 대한 자세한 내용은 Azure 공유 디스크 설명서 "제한 사항" 섹션을 주의 깊게 검토하세요.
Azure 펜스 에이전트 사용
Azure 펜스 에이전트를 사용하여 펜싱을 설정할 수 있습니다. Azure 펜스 에이전트에는 클러스터 VM에 대한 관리 ID 또는 Azure API를 통해 실패한 노드를 다시 시작하도록 관리하는 서비스 주체 또는 MSI(관리 시스템 ID)가 필요합니다. Azure 펜스 에이전트는 추가 가상 머신을 배포할 필요가 없습니다.
iSCSI 대상 서버가 있는 SBD
보호용 iSCSI 대상 서버를 사용하는 SBD 디바이스를 사용하려면 다음 섹션의 지침을 따릅니다.
iSCSI 대상 서버 설정
먼저 iSCSI 대상 가상 머신을 만들어야 합니다. 여러 Pacemaker 클러스터와 iSCSI 대상 서버를 공유할 수 있습니다.
지원되는 RHEL OS 버전에서 실행되는 가상 머신을 배포하고 SSH를 통해 연결합니다. VM의 크기가 클 필요는 없습니다. Standard_E2s_v3 또는 Standard_D2s_v3 등의 VM 크기면 충분합니다. 반드시 OS 디스크용 프리미엄 스토리지를 사용합니다.
HA 및 Update Services가 포함된 RHEL for SAP 또는 iSCSI 대상 서버에 대한 RHEL for SAP 앱 OS 이미지를 사용할 필요는 없습니다. 대신 표준 RHEL OS 이미지를 사용할 수 있습니다. 그러나 지원 수명 주기는 OS 제품 릴리스마다 다릅니다.
모든 iSCSI 대상 가상 머신에 대해 다음 명령을 실행합니다.
RHEL을 업데이트합니다.
sudo yum -y update참고
OS를 업그레이드 또는 업데이트한 후 노드를 다시 부팅해야 할 수도 있습니다.
iSCSI 대상 패키지를 설치합니다.
sudo yum install targetcli부팅 시 시작하도록 대상을 시작하고 구성합니다.
sudo systemctl start target sudo systemctl enable target방화벽에서 포트
3260열기sudo firewall-cmd --add-port=3260/tcp --permanent sudo firewall-cmd --add-port=3260/tcp
iSCSI 대상 서버에 iSCSI 디바이스 만들기
SAP 시스템 클러스터에 대해 iSCSI 디스크를 만들려면 모든 iSCSI 대상 가상 머신에 대해 다음 명령을 실행합니다. 이 예제에서는 여러 클러스터에 대해 SBD 디바이스를 만들고 여러 클러스터에 대해 단일 iSCSI 대상 서버를 사용하는 방법을 보여 줍니다. SBD 디바이스는 OS 디스크에 구성되므로 충분한 공간이 있는지 확인합니다.
- ascsnw1: NW1의 ASCS/ERS 클러스터를 나타냅니다.
- dbhn1: HN1의 데이터베이스 클러스터를 나타냅니다.
- sap-cl1 및 sap-cl2: NW1 ASCS/ERS 클러스터 노드의 호스트 이름입니다.
- hn1-db-0 and hn1-db-1: 데이터베이스 클러스터 노드의 호스트 이름입니다.
다음 지침에서 필요에 따라 특정 호스트 이름 및 SID를 사용하여 명령을 수정합니다.
모든 SBD 디바이스에 대한 루트 폴더를 만듭니다.
sudo mkdir /sbd시스템 NW1의 ASCS/ERS 서버용 SBD 디바이스를 만듭니다.
sudo targetcli backstores/fileio create sbdascsnw1 /sbd/sbdascsnw1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.ascsnw1.local:ascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/luns/ create /backstores/fileio/sbdascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl1.local:sap-cl1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl2.local:sap-cl2시스템 NW1의 데이터베이스 클러스터용 SBD 디바이스를 만듭니다.
sudo targetcli backstores/fileio create sbddbhn1 /sbd/sbddbhn1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.dbhn1.local:dbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/luns/ create /backstores/fileio/sbddbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-0.local:hn1-db-0 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-1.local:hn1-db-1targetcli 구성을 저장합니다.
sudo targetcli saveconfig모든 것이 올바르게 설정되었는지 확인합니다.
sudo targetcli ls o- / ......................................................................................................................... [...] o- backstores .............................................................................................................. [...] | o- block .................................................................................................. [Storage Objects: 0] | o- fileio ................................................................................................. [Storage Objects: 2] | | o- sbdascsnw1 ............................................................... [/sbd/sbdascsnw1 (50.0MiB) write-thru activated] | | | o- alua ................................................................................................... [ALUA Groups: 1] | | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | | o- sbddbhn1 ................................................................... [/sbd/sbddbhn1 (50.0MiB) write-thru activated] | | o- alua ................................................................................................... [ALUA Groups: 1] | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | o- pscsi .................................................................................................. [Storage Objects: 0] | o- ramdisk ................................................................................................ [Storage Objects: 0] o- iscsi ............................................................................................................ [Targets: 2] | o- iqn.2006-04.dbhn1.local:dbhn1 ..................................................................................... [TPGs: 1] | | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | | o- acls .......................................................................................................... [ACLs: 2] | | | o- iqn.2006-04.hn1-db-0.local:hn1-db-0 .................................................................. [Mapped LUNs: 1] | | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | | o- iqn.2006-04.hn1-db-1.local:hn1-db-1 .................................................................. [Mapped LUNs: 1] | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | o- luns .......................................................................................................... [LUNs: 1] | | | o- lun0 ............................................................. [fileio/sbddbhn1 (/sbd/sbddbhn1) (default_tg_pt_gp)] | | o- portals .................................................................................................... [Portals: 1] | | o- 0.0.0.0:3260 ..................................................................................................... [OK] | o- iqn.2006-04.ascsnw1.local:ascsnw1 ................................................................................. [TPGs: 1] | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | o- acls .......................................................................................................... [ACLs: 2] | | o- iqn.2006-04.sap-cl1.local:sap-cl1 .................................................................... [Mapped LUNs: 1] | | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | | o- iqn.2006-04.sap-cl2.local:sap-cl2 .................................................................... [Mapped LUNs: 1] | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | o- luns .......................................................................................................... [LUNs: 1] | | o- lun0 ......................................................... [fileio/sbdascsnw1 (/sbd/sbdascsnw1) (default_tg_pt_gp)] | o- portals .................................................................................................... [Portals: 1] | o- 0.0.0.0:3260 ..................................................................................................... [OK] o- loopback ......................................................................................................... [Targets: 0]
iSCSI 대상 서버 SBD 디바이스 설정
[A]: 모든 노드에 적용됩니다. [1]: 노드 1에만 적용됩니다. [2]: 노드 2에만 적용됩니다.
클러스터 노드에서 이전 섹션에서 만든 iSCSI 디바이스를 연결하고 검색합니다. 만들려는 새 클러스터의 노드에서 다음 명령을 실행합니다.
[A] 모든 클러스터 노드에서 iSCSI 초기자 유틸리티를 설치하거나 업데이트합니다.
sudo yum install -y iscsi-initiator-utils[A] 모든 클러스터 노드에 클러스터 및 SBD 패키지를 설치합니다.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] iSCSI 서비스를 사용하도록 설정합니다.
sudo systemctl enable iscsid iscsi[1] 클러스터의 첫 번째 노드에서 초기자 이름을 변경합니다.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl1.local:sap-cl1[2] 클러스터의 두 번째 노드에서 초기자 이름을 변경합니다.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl2.local:sap-cl2[A] 이제 iSCSI 서비스를 다시 시작하여 변경 내용을 적용합니다.
sudo systemctl restart iscsid sudo systemctl restart iscsi[A] iSCSI 디바이스를 연결합니다. 다음 예에서 10.0.0.17은 iSCSI 대상 서버의 IP 주소이고 3260은 기본 포트입니다. 첫 번째 명령
iqn.2006-04.ascsnw1.local:ascsnw1를 실행할 때 대상 이름iscsiadm -m discovery이 나열됩니다.sudo iscsiadm -m discovery --type=st --portal=10.0.0.17:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.17:3260 sudo iscsiadm -m node -p 10.0.0.17:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] 여러 SBD 디바이스를 사용하려면 두 번째 iSCSI 대상 서버에도 연결합니다.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.18:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.18:3260 sudo iscsiadm -m node -p 10.0.0.18:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] 여러 SBD 디바이스를 사용하려면 세 번째 iSCSI 대상 서버에도 연결합니다.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.19:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.19:3260 sudo iscsiadm -m node -p 10.0.0.19:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] iSCSI 디바이스를 사용할 수 있는지 확인하고 디바이스 이름을 기록해 둡니다. 다음 예제에서는 3개의 iSCSI 대상 서버에 노드를 연결하여 3개의 iSCSI 디바이스가 검색됩니다.
lsscsi [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sde [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdb [1:0:0:2] disk Msft Virtual Disk 1.0 /dev/sdc [1:0:0:3] disk Msft Virtual Disk 1.0 /dev/sdd [2:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdf [3:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdh [4:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdg[A] iSCSI 디바이스의 ID를 검색합니다.
ls -l /dev/disk/by-id/scsi-* | grep -i sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf ls -l /dev/disk/by-id/scsi-* | grep -i sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh ls -l /dev/disk/by-id/scsi-* | grep -i sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdg이 명령은 모든 SBD 디바이스에 대해 세 개의 디바이스 ID를 나열합니다. scsi-3으로 시작하는 ID를 사용하는 것이 좋습니다. 앞의 예에서 ID는 다음과 같습니다.
- /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2
- /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d
- /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65
[1] SBD 디바이스 만들기
iSCSI 디바이스의 디바이스 ID를 사용하여 첫 번째 클러스터 노드에 새 SBD 디바이스를 만듭니다.
sudo sbd -d /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -1 60 -4 120 create또한 두 개 이상을 사용하려면 두 번째 및 세 번째 SBD 디바이스를 만듭니다.
sudo sbd -d /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -1 60 -4 120 create sudo sbd -d /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -1 60 -4 120 create
[A] SBD 구성을 조정합니다.
SBD 구성 파일을 엽니다.
sudo vi /etc/sysconfig/sbdSBD 디바이스의 속성을 변경하고, Pacemaker 통합을 활성화하고, SBD의 시작 모드를 변경합니다.
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2;/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d;/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] # # In some cases, a longer delay than the default "msgwait" seconds is needed. So, set a specific delay value, in seconds. See, `man sbd` for more information. SBD_DELAY_START=186 [...]
[A] 다음 명령을 실행하여
softdog모듈을 로드합니다.modprobe softdog[A] 다음 명령을 실행하여 노드를 다시 부팅한 후
softdog이 자동으로 로드되도록 합니다.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A]
SBD_DELAY_START값으로 설정되면 부팅 시 SBD 서비스의 시작이 지연됩니다. SBD 서비스의 systemdTimeoutSec가 기본값(90초)으로 유지되는 경우 서비스를 시작하기 전에 시간이 초과될 수 있으므로TimeoutSec을(를)SBD_DELAY_START보다 큰 값으로 늘려야 합니다.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=223" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=3min 43s # TimeoutStopUSec=3min 43s # TimeoutAbortUSec=3min 43s
Azure 공유 디스크를 사용하는 SBD
이 섹션은 Azure 공유 디스크에서 SBD 디바이스를 사용하려는 경우에만 적용됩니다.
PowerShell을 사용하여 Azure 공유 디스크 구성
PowerShell을 사용하여 Azure 공유 디스크를 만들고 연결하려면 다음 명령을 실행합니다. Azure CLI 또는 Azure 포털을 사용하여 리소스를 배포하려는 경우 ZRS 디스크 배포 참조할 수도 있습니다.
$ResourceGroup = "MyResourceGroup"
$Location = "MyAzureRegion"
$DiskSizeInGB = 4
$DiskName = "SBD-disk1"
$ShareNodes = 2
$LRSSkuName = "Premium_LRS"
$ZRSSkuName = "Premium_ZRS"
$vmNames = @("prod-cl1-0", "prod-cl1-1") # VMs to attach the disk
# ZRS Azure shared disk: Configure an Azure shared disk with ZRS for a premium shared disk
$zrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $ZRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$zrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $zrsDiskConfig
# Attach ZRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $zrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
# LRS Azure shared disk: Configure an Azure shared disk with LRS for a premium shared disk
$lrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $LRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$lrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $lrsDiskConfig
# Attach LRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $lrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
Azure 공유 디스크 SBD 디바이스 설정
[A] 모든 클러스터 노드에 클러스터 및 SBD 패키지를 설치합니다.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] 연결된 디스크를 사용할 수 있는지 확인합니다.
lsblk # NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT # sda 8:0 0 4G 0 disk # sdb 8:16 0 64G 0 disk # ├─sdb1 8:17 0 500M 0 part /boot # ├─sdb2 8:18 0 63G 0 part # │ ├─rootvg-tmplv 253:0 0 2G 0 lvm /tmp # │ ├─rootvg-usrlv 253:1 0 10G 0 lvm /usr # │ ├─rootvg-homelv 253:2 0 1G 0 lvm /home # │ ├─rootvg-varlv 253:3 0 8G 0 lvm /var # │ └─rootvg-rootlv 253:4 0 2G 0 lvm / # ├─sdb14 8:30 0 4M 0 part # └─sdb15 8:31 0 495M 0 part /boot/efi # sr0 11:0 1 1024M 0 rom lsscsi # [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sdb # [0:0:0:2] cd/dvd Msft Virtual DVD-ROM 1.0 /dev/sr0 # [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda # [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdc[A] 연결된 공유 디스크의 디바이스 ID를 검색합니다.
ls -l /dev/disk/by-id/scsi-* | grep -i sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-14d534654202020200792c2f5cc7ef14b8a7355cb3cef0107 -> ../../sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -> ../../sda연결된 공유 디스크의 명령 목록 디바이스 ID입니다. scsi-3으로 시작하는 ID를 사용하는 것이 좋습니다. 이 예제에서 ID는 /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107입니다.
[1] SBD 디바이스 만들기
# Use the device ID from step 3 to create the new SBD device on the first cluster node sudo sbd -d /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -1 60 -4 120 create[A] SBD 구성을 조정합니다.
SBD 구성 파일을 엽니다.
sudo vi /etc/sysconfig/sbdSBD 디바이스의 속성을 변경하고, Pacemaker 통합을 사용하도록 설정하고, SBD의 시작 모드를 변경하고, SBD_DELAY_START 값을 조정합니다.
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] # In some cases, a longer delay than the default "msgwait" seconds is needed. So, set a specific delay value, in seconds. See, `man sbd` for more information. SBD_DELAY_START=186 [...]
[A] 다음 명령을 실행하여
softdog모듈을 로드합니다.modprobe softdog[A] 다음 명령을 실행하여 노드를 다시 부팅한 후
softdog이 자동으로 로드되도록 합니다.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A]
SBD_DELAY_START값으로 설정되면 부팅 시 SBD 서비스의 시작이 지연됩니다. SBD 서비스의 systemdTimeoutSec가 기본값(90초)으로 유지되는 경우 서비스를 시작하기 전에 시간이 초과될 수 있으므로TimeoutSec을(를)SBD_DELAY_START보다 큰 값으로 늘려야 합니다.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=223" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=3min 43s # TimeoutStopUSec=3min 43s # TimeoutAbortUSec=3min 43s
Azure 펜싱 에이전트 구성
펜싱 디바이스는 관리 ID를 통해 Azure 리소스 또는 서비스 주체에 대한 Azure 권한을 부여합니다. ID 관리 방법에 따라 적절한 절차를 따릅니다.
ID 관리 구성
관리 ID 또는 서비스 주체를 사용합니다.
관리 ID(MSI)를 만들려면 클러스터의 각 VM에 대해 시스템 할당 관리 ID를 만듭니다. 시스템 할당 관리 ID가 이미 있는 경우 해당 ID가 사용됩니다. 지금은 Pacemaker에서 사용자 할당 관리 ID를 사용하지 마세요. 관리 ID를 기반으로 하는 펜스 디바이스는 RHEL 7.9 및 RHEL 8.x/RHEL 9.x/RHEL 10.x에서 지원됩니다.
펜스 에이전트에 대한 사용자 지정 역할 만들기
관리 ID와 서비스 주체 모두 기본적으로 Azure 리소스에 액세스할 수 있는 권한이 없습니다. 클러스터의 모든 VM을 시작하고 중지(전원 끄기)하려면 관리 ID 또는 서비스 주체 권한을 부여해야 합니다. 사용자 지정 역할을 아직 만들지 않은 경우 PowerShell 또는 Azure CLI 사용하여 만들 수 있습니다.
입력 파일에 다음 콘텐츠를 사용합니다. 콘텐츠를 구독에 맞게 조정해야 합니다. 즉,
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx및yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy를 구독 ID로 바꿔야 합니다. 구독이 하나만 있는 경우AssignableScopes에서 두 번째 항목을 제거합니다.{ "Name": "Linux Fence Agent Role", "description": "Allows to power-off and start virtual machines", "assignableScopes": [ "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "/subscriptions/yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy" ], "actions": [ "Microsoft.Compute/*/read", "Microsoft.Compute/virtualMachines/powerOff/action", "Microsoft.Compute/virtualMachines/start/action" ], "notActions": [], "dataActions": [], "notDataActions": [] }사용자 지정 역할 할당
관리 ID 또는 서비스 주체를 사용합니다.
마지막 섹션에서 만들어진 사용자 지정 역할
Linux Fence Agent Role을 클러스터 VM의 각 관리 ID에 할당합니다. 각 VM 시스템 할당 관리 ID에는 모든 클러스터 VM의 리소스에 할당된 역할이 필요합니다. 자세한 내용은 Azure 포털을 사용하여 리소스에 대한 관리 ID 액세스 할당 참조하세요. 각 VM의 관리 ID 역할 할당에 모든 클러스터 VM이 포함되어 있는지 확인합니다.중요합니다
관리 ID를 사용한 승인의 할당 및 제거는 유효할 때까지 지연될 수 있습니다.
클러스터 설치
RHEL 7과 RHEL 8/RHEL 9 사이의 명령 또는 구성의 차이점이 문서에 나와 있습니다.
[A] RHEL HA 추가 기능을 설치합니다.
sudo yum install -y pcs pacemaker nmap-ncat[A] RHEL 9.x에서 클라우드 배포용 리소스 에이전트를 설치합니다.
sudo yum install -y resource-agents-cloud[A] Azure 펜스 에이전트를 기반으로 펜싱 디바이스를 사용하는 경우 펜스 에이전트 패키지를 설치합니다.
sudo yum install -y fence-agents-azure-arm중요합니다
펜스 에이전트의 서비스 주체 이름 대신 Azure 리소스에 관리 ID를 사용하려는 고객에게는 다음 버전의 Azure 펜스 에이전트(이상)를 사용하는 것이 좋습니다.
- RHEL 8.4: fence-agents-4.2.1-54.el8.
- RHEL 8.2: fence-agents-4.2.1-41.el8_2.4
- RHEL 8.1: fence-agents-4.2.1-30.el8_1.4
- RHEL 7.9: fence-agents-4.2.1-41.el7_9.4.
중요합니다
RHEL 9에서는 Azure 펜스 에이전트와 관련된 문제를 방지하려면 다음 패키지 버전(이상)을 사용하는 것이 좋습니다.
- fence-agents-4.10.0-20.el9_0.7
- fence-agents-common-4.10.0-20.el9_0.6
- ha-cloud-support-4.10.0-20.el9_0.6.x86_64.rpm
Azure 펜스 에이전트의 버전을 확인합니다. 필요한 경우 최소 필수 버전 이상으로 업데이트합니다.
# Check the version of the Azure Fence Agent sudo yum info fence-agents-azure-arm중요합니다
Azure 펜스 에이전트를 업데이트해야 하는 경우 사용자 지정 역할을 사용하는 경우 powerOff 작업을 포함하도록 사용자 지정 역할을 업데이트해야 합니다. 자세한 내용은 펜스 에이전트에 대한 사용자 지정 역할 만들기를 참조하세요.
[A] 호스트명 해상도를 설정합니다.
DNS 서버를 사용하거나 모든 노드의
/etc/hosts파일을 수정할 수 있습니다. 다음 예제에서는/etc/hosts파일을 사용하는 방법을 보여 줍니다. 다음 명령에서 IP 주소와 호스트 이름을 바꿉니다.중요합니다
클러스터 구성에서 호스트 이름을 사용하는 경우 신뢰할 수 있는 호스트 이름 확인이 중요합니다. 이름을 사용할 수 없으면 클러스터 통신이 실패하여 클러스터 장애 조치(failover)가 지연될 수 있습니다.
/etc/hosts를 사용하면 클러스터가 DNS로부터 독립되며 이는 단일 실패 지점이 될 수도 있다는 이점이 있습니다.sudo vi /etc/hosts/etc/hosts에 다음 줄을 삽입합니다. 사용자 환경에 맞게 IP 주소와 호스트 이름을 변경합니다.# IP address of the first cluster node 10.0.0.6 prod-cl1-0 # IP address of the second cluster node 10.0.0.7 prod-cl1-1[A]
hacluster암호를 동일한 암호로 변경합니다.sudo passwd hacluster[A] Pacemaker의 방화벽 규칙을 추가합니다.
클러스터 노드 간의 모든 클러스터 통신에 다음 방화벽 규칙을 추가합니다.
sudo firewall-cmd --add-service=high-availability --permanent sudo firewall-cmd --add-service=high-availability[A] 기본 클러스터 서비스를 사용하도록 설정합니다.
다음 명령을 실행하여 Pacemaker 서비스를 사용하도록 설정하고 시작합니다.
sudo systemctl start pcsd.service sudo systemctl enable pcsd.service[1] Pacemaker 클러스터를 만듭니다.
다음 명령을 실행하여 노드를 인증하고 클러스터를 만듭니다. 메모리 보존 유지 관리를 허용하도록 토큰을 30000으로 설정합니다. 자세한 내용은 Linux에 대한 관련 문서를 참조하세요.
RHEL 7.x에 클러스터를 빌드하는 경우 다음 명령을 사용합니다.
sudo pcs cluster auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup --name nw1-azr prod-cl1-0 prod-cl1-1 --token 30000 sudo pcs cluster start --allRHEL 8.x/RHEL 9.x/RHEL 10.x에서 클러스터를 빌드하는 경우 다음 명령을 사용합니다.
sudo pcs host auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup nw1-azr prod-cl1-0 prod-cl1-1 totem token=30000 sudo pcs cluster start --all다음 명령을 실행하여 클러스터 상태를 확인합니다.
# Run the following command until the status of both nodes is online sudo pcs status # Cluster name: nw1-azr # WARNING: no stonith devices and stonith-enabled is not false # Stack: corosync # Current DC: prod-cl1-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum # Last updated: Fri Aug 17 09:18:24 2018 # Last change: Fri Aug 17 09:17:46 2018 by hacluster via crmd on prod-cl1-1 # # 2 nodes configured # 0 resources configured # # Online: [ prod-cl1-0 prod-cl1-1 ] # # No resources # # Daemon Status: # corosync: active/disabled # pacemaker: active/disabled # pcsd: active/enabled[A] 예상 투표를 설정합니다.
# Check the quorum votes pcs quorum status # If the quorum votes are not set to 2, execute the next command sudo pcs quorum expected-votes 2팁
다중 노드 클러스터, 즉 3개 이상의 노드가 있는 클러스터를 빌드하는 경우 응답을 2로 설정하지 마세요.
[1] 동시 Fence 작업을 허용합니다.
sudo pcs property set concurrent-fencing=true
Pacemaker 클러스터에 펜싱 디바이스 만들기
팁
- 2노드 Pacemaker 클러스터 내에서 펜스 경합을 방지하려면
priority-fencing-delay클러스터 속성을 구성하면 됩니다. 이 속성은 분할 브레인 시나리오가 발생할 때 총 리소스 우선 순위가 더 높은 노드를 펜싱하는 데 더 많은 지연을 발생합니다. 자세한 내용은 Pacemaker가 실행 중인 리소스가 가장 적은 클러스터 노드를 펜스할 수 있나요? -
priority-fencing-delay속성은 Pacemaker 버전 2.0.4-6.el8 이상 및 2노드 클러스터에 적용 가능합니다.priority-fencing-delay클러스터 속성을 구성하는 경우pcmk_delay_max속성을 설정할 필요가 없습니다. 하지만 Pacemaker 버전이 2.0.4-6.el8 미만인 경우에는pcmk_delay_max속성을 설정해야 합니다. -
priority-fencing-delay클러스터 속성을 설정하는 방법에 대한 지침은 각 SAP ASCS/ERS 및 SAP HANA 강화 HA 문서를 참조하세요.
선택한 펜싱 메커니즘에 따라, 관련 지침에 대해 SBD를 펜싱 디바이스로 사용하는 섹션 또는 Azure 펜스 에이전트를 펜싱 디바이스로 사용하는 섹션 중 하나만 따르십시오.
SBD를 펜싱 디바이스로 사용
[A] SBD 서비스를 사용하도록 설정합니다.
sudo systemctl enable sbd[1] iSCSI 대상 서버 또는 Azure 공유 디스크를 사용하여 구성된 SBD 디바이스의 경우 다음 명령을 실행합니다.
sudo pcs property set stonith-timeout=210 sudo pcs property set stonith-enabled=true # Replace the device IDs with your device ID. pcs stonith create sbd fence_sbd \ devices=/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2,/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d,/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 \ op monitor interval=600 timeout=15[1] 클러스터를 다시 시작합니다.
sudo pcs cluster stop --all # It would take time to start the cluster as "SBD_DELAY_START" is set to "yes" sudo pcs cluster start --all참고
Pacemaker 클러스터를 시작하는 동안 다음 오류가 발생하면 메시지를 무시할 수 있습니다. 또는
pcs cluster start --all --request-timeout 140명령을 사용하여 클러스터를 시작할 수 있습니다.오류: 모든 노드 node1/node2를 시작할 수 없음: node1/node2에 연결할 수 없습니다. pcsd가 실행 중인지 확인하거나,
--request-timeout옵션을 사용하여 더 높은 시간 제한을 설정해 보세요(60000밀리초 동안 0바이트가 수신된 후에 작업 시간이 초과됨).
펜싱 디바이스로 펜스 에이전트 Azure
[1] 두 클러스터 노드에 역할을 할당한 후 클러스터에서 펜싱 디바이스를 구성할 수 있습니다.
sudo pcs property set stonith-timeout=900 sudo pcs property set stonith-enabled=true[1] Azure 펜스 에이전트에 대한 관리 ID 또는 서비스 주체를 사용하는지 여부에 따라 적절한 명령을 실행합니다.
참고
Azure 정부 클라우드를 사용하는 경우 펜스 에이전트를 구성할 때
cloud=옵션을 지정해야 합니다. 예를 들어 Azure 미국 정부 클라우드에 대한cloud=usgov. Azure 정부 클라우드의 RedHat 지원에 대한 자세한 내용은 RHEL 고가용성 클러스터에 대한 정책 지원 - 클러스터 멤버로 Microsoft Azure Virtual Machines 참조하세요.팁
pcmk_host_map옵션은 RHEL 호스트 이름과 Azure VM 이름이 동일하지 않은 경우에만 명령에 필요합니다. hostname:vm-name 형식으로 매핑을 지정합니다. 자세한 내용은 pcmk_host_map 펜싱 디바이스에 대한 노드 매핑을 지정하는 데 사용해야 하는 형식을 참조하세요.RHEL 7.x의 경우, 다음 명령을 사용하여 Fence 디바이스를 구성합니다.
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ meta failure-timeout=120s \ op monitor interval=3600RHEL 8.x/9.x/10.x의 경우 다음 명령을 사용하여 펜스 디바이스를 구성합니다.
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version greater than 2.0.4-6.el8) OR (HANA scale out) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 \ meta failure-timeout=120s \ op monitor interval=3600 # Run following command if you are setting up fence agent on (two-node cluster and pacemaker version less than 2.0.4-6.el8) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ meta failure-timeout=120s \ op monitor interval=3600
서비스 주체 구성에 따라 펜싱 디바이스를 사용하는 경우, Azure 펜싱을 사용하여 SPN에서 MSI로 전환하는 방법에 대한 Pacemaker 클러스터에서 SPN에서 MSI로 변경을 읽은 후 관리 ID 구성으로 전환하는 방법을 배우십시오.
모니터링 및 펜싱 작업이 역직렬화됩니다. 결과적으로 더 오래 실행되는 모니터링 작업과 동시 펜싱 이벤트가 있는 경우 모니터링 작업이 이미 실행 중이므로 클러스터 장애 조치(failover)에 지연이 없습니다.
팁
Azure 펜스 에이전트는 퍼블릭 엔드포인트에 대한 아웃바운드 연결이 필요합니다. 가능한 솔루션에 대한 자세한 내용은 표준 ILB를 사용하는 VM의 공용 엔드포인트 연결을 참조하세요.
Azure의 예약 이벤트에 대해 Pacemaker 구성 방법
Azure 예약된 이벤트 제공합니다. 예약된 이벤트는 메타데이터 서비스를 통해 제공되며 애플리케이션이 해당 이벤트를 준비할 시간을 허용합니다.
리소스 에이전트 azure-events-az 예약된 Azure 이벤트를 모니터링합니다. 이벤트가 검색되고 리소스 에이전트가 다른 클러스터 노드를 사용할 수 있다고 판단하는 경우 노드 수준 상태 특성을 #health-azure-1000000설정합니다.
이 특수 클러스터 상태 특성이 노드에 대해 설정된 경우 노드는 클러스터에서 비정상으로 간주되며 모든 리소스는 영향을 받는 노드에서 멀리 마이그레이션됩니다. 위치 제약 조건은 에이전트가 이 비정상 상태에서 실행되어야 하므로 이름이 'health-'로 시작하는 리소스가 제외되도록 합니다. 영향을 받는 클러스터 노드가 클러스터 리소스를 실행하지 않으면 예약된 이벤트는 리소스를 실행할 위험 없이 다시 시작과 같은 작업을 실행할 수 있습니다.
모든 이벤트가 처리되면, Pacemaker 시작 시 #heath-azure 속성이 다시 0으로 설정되어 노드를 다시 정상 상태로 표시합니다.
[A]
azure-events-az에이전트용 패키지가 이미 설치되어 있고 최신 상태인지 확인합니다.RHEL 8.x: sudo dnf info resource-agents RHEL 9.x: sudo dnf info resource-agents-cloud필요한 최소 버전:
- RHEL 8.4:
resource-agents-4.1.1-90.13 - RHEL 8.6:
resource-agents-4.9.0-16.9 - RHEL 8.8:
resource-agents-4.9.0-40.1 - RHEL 9.0:
resource-agents-cloud-4.10.0-9.6 - RHEL 9.2 이상:
resource-agents-cloud-4.10.0-34.1
- RHEL 8.4:
[1] Pacemaker에서 리소스를 구성합니다.
#Place the cluster in maintenance mode sudo pcs property set maintenance-mode=true[1] Pacemaker 클러스터 상태 노드 전략 및 제약 조건을 설정합니다.
sudo pcs property set node-health-strategy=custom # For RHEL 8.x/9.x sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ defined '#uname' # For RHEL 10.x sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ "defined #uname"중요합니다
다음 단계에 설명된 리소스 외에
health-로 시작하는 클러스터의 다른 리소스를 정의하지 마세요.[1] 클러스터 특성의 초기 값을 설정합니다. 각 클러스터 노드에 대해 실행하고 주요 제조업체 VM을 포함한 스케일 아웃 환경에 대해 실행합니다.
sudo crm_attribute --node prod-cl1-0 --name '#health-azure' --update 0 sudo crm_attribute --node prod-cl1-1 --name '#health-azure' --update 0[1] Pacemaker에서 리소스를 구성합니다. 리소스가
health-azure로 시작하는지 확인합니다.sudo pcs resource create health-azure-events \ ocf:heartbeat:azure-events-az \ meta failure-timeout=120s \ op monitor interval=10s timeout=240s \ op start timeout=10s start-delay=90s # For RHEL 8.x/9.x sudo pcs resource clone health-azure-events allow-unhealthy-nodes=true # For RHEL 10.x sudo pcs resource clone health-azure-events meta allow-unhealthy-nodes=truePacemaker 클러스터의 유지 관리 모드를 해제합니다.
sudo pcs property set maintenance-mode=false사용하도록 설정 중에 오류를 지우고 모든 클러스터 노드에서
health-azure-events리소스가 성공적으로 시작되었는지 확인합니다.sudo pcs resource cleanup예약된 이벤트에 대한 최초 쿼리 실행은 최대 2분 정도 걸릴 수 있습니다. 예약된 이벤트를 사용한 Pacemaker 테스트는 클러스터 VM에 대해 다시 부팅 또는 다시 배포 작업을 사용할 수 있습니다. 자세한 정보는 예약된 이벤트를 참조하세요.
선택적 펜싱 구성
팁
이 섹션은 특수 펜싱 디바이스 fence_kdump를 구성하려는 경우에만 적용 가능합니다.
VM 내에서 진단 정보를 수집해야 하는 경우, 펜스 에이전트 fence_kdump를 기반으로 다른 펜싱 디바이스를 구성하는 것이 유용할 수 있습니다.
fence_kdump 에이전트는 노드가 kdump 크래시 복구에 들어갔다는 것을 감지하고 다른 펜싱 메서드가 호출되기 전에 크래시 복구 서비스가 완료되도록 허용할 수 있습니다. Azure VM을 사용하는 경우 fence_kdump SBD 또는 Azure 펜스 에이전트와 같은 기존 펜스 메커니즘을 대체하는 것은 아닙니다.
중요합니다
fence_kdump가 첫 번째 수준 펜싱 디바이스로 구성된 경우 펜싱 작업이 지연되고 애플리케이션 리소스 장애 조치(failover)가 각각 지연됩니다.
크래시 덤프가 성공적으로 검색되면 크래시 복구 서비스가 완료될 때까지 펜싱이 지연됩니다. 실패한 노드에 연결할 수 없거나 응답하지 않는 경우 펜싱은 결정된 시간, 구성된 반복 횟수 및 fence_kdump 시간 제한에 따라 지연됩니다. 자세한 내용은 Red Hat Pacemaker 클러스터에서 fence_kdump 구성하는 방법을 참조하세요.
제안된 fence_kdump 시간 제한을 특정 환경에 맞게 조정해야 할 수도 있습니다.
VM 내에서 진단을 수집해야 하는 경우에만 fence_kdump 펜싱을 구성하고 항상 SBD 또는 Azure 펜스 에이전트와 같은 기존 펜스 메서드와 함께 구성하는 것이 좋습니다.
다음 Red Hat 기술 자료 문서에는 fence_kdump 펜싱 구성에 대한 중요한 정보가 포함되어 있습니다.
- Red Hat Pacemaker 클러스터에서 fence_kdump 구성하려면 어떻게 해야 하나요?
- Pacemaker를 사용하여 RHEL 클러스터에서 펜싱 수준을 구성/관리하는 방법을 참조하세요.
- 2.0.14보다 오래된 kexec-tools를 사용하는 RHEL 6 또는 7 HA 클러스터에서 "X초 후 시간 제한"로 인해 fence_kdump가 실패함을 참조하세요.
- 기본 시간 제한을 변경하는 방법에 대한 자세한 내용은 RHEL 6, 7, 8 HA 추가 기능과 함께 사용하도록 kdump를 구성하는 방법을 참조하세요.
-
fence_kdump를 사용할 때 장애 조치(Failover) 지연을 줄이는 방법에 대한 더 자세한 내용은 fence_kdump 구성을 추가할 때 예상되는 장애 조치(Failover) 지연을 줄일 수 있나요?를 참조하세요.
다음 선택적 단계를 실행하여 Azure 펜스 에이전트 구성 외에도 fence_kdump 첫 번째 수준 펜싱 구성으로 추가합니다.
[A]
kdump가 활성 상태이고 구성되어 있는지 확인합니다.systemctl is-active kdump # Expected result # active[A]
fence_kdump펜스 에이전트를 설치합니다.yum install fence-agents-kdump[1] 클러스터에
fence_kdump펜싱 디바이스를 만듭니다.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" timeout=30[1]
fence_kdump펜싱 메커니즘이 먼저 사용되도록 펜싱 수준을 구성합니다.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" pcs stonith level add 1 prod-cl1-0 rsc_st_kdump pcs stonith level add 1 prod-cl1-1 rsc_st_kdump # Replace <stonith-resource-name> to the resource name of the STONITH resource configured in your pacemaker cluster (example based on above configuration - sbd or rsc_st_azure) pcs stonith level add 2 prod-cl1-0 <stonith-resource-name> pcs stonith level add 2 prod-cl1-1 <stonith-resource-name> # Check the fencing level configuration pcs stonith level # Example output # Target: prod-cl1-0 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name> # Target: prod-cl1-1 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name>[A] 방화벽을 통해
fence_kdump에 필요한 포트를 허용합니다.firewall-cmd --add-port=7410/udp firewall-cmd --add-port=7410/udp --permanent[A]
fence_kdump_nodes에서/etc/kdump.conf구성을 수행하여 일부fence_kdump버전에 대한 시간 제한에 따른kexec-tools실패를 방지합니다. 자세한 내용은 fence_kdump_nodes가 kexec-tools 버전 2.0.15 이상으로 지정되지 않은 경우 fence_kdump 시간 초과 및 2.0.14 이전의 kexec-tools 버전이 있는 RHEL 6 또는 7 고가용성 클러스터에서 "X초 후 시간 제한"으로 fence_kdump 실패를 참조하세요. 두 노드 클러스터에 대한 구성 예가 여기에 나와 있습니다./etc/kdump.conf를 변경한 후에는 kdump 이미지를 다시 생성해야 합니다. 다시 생성하려면kdump서비스를 다시 시작합니다.vi /etc/kdump.conf # On node prod-cl1-0 make sure the following line is added fence_kdump_nodes prod-cl1-1 # On node prod-cl1-1 make sure the following line is added fence_kdump_nodes prod-cl1-0 # Restart the service on each node systemctl restart kdump[A]
initramfs이미지 파일에fence_kdump및hosts파일이 포함되어 있는지 확인합니다. 자세한 내용은 Red Hat Pacemaker 클러스터에서 fence_kdump 구성하는 방법을 참조하세요.lsinitrd /boot/initramfs-$(uname -r)kdump.img | egrep "fence|hosts" # Example output # -rw-r--r-- 1 root root 208 Jun 7 21:42 etc/hosts # -rwxr-xr-x 1 root root 15560 Jun 17 14:59 usr/libexec/fence_kdump_send노드를 충돌시켜 구성을 테스트합니다. 자세한 내용은 Red Hat Pacemaker 클러스터에서 fence_kdump 구성하는 방법을 참조하세요.
중요합니다
클러스터가 이미 생산적으로 사용되고 있는 경우 노드 크래시가 애플리케이션에 영향을 미치므로 이에 따라 테스트를 계획합니다.
echo c > /proc/sysrq-trigger
다음 단계
- SAP에 대한 Azure Virtual Machines 계획 및 구현을 참조하세요.
- SAP에 대한 Azure Virtual Machines 배포를 참조하세요.
- SAP 대한
Azure Virtual Machines DBMS 배포를 참조하세요. - HA를 설정하고 Azure VM에서 SAP HANA 재해 복구를 계획하는 방법을 알아보려면
Azure Virtual Machines 참조하세요.