SUSE Enterprise Linux에서 Azure NetApp Files를 사용한 SAP HANA 스케일 업의 고가용성
이 문서에서는 Azure NetApp Files를 사용하여 HANA 파일 시스템이 NFS를 통해 탑재된 경우 스케일 업 배포에서 SAP HANA 시스템 복제를 구성하는 방법을 설명합니다. 구성 및 설치 명령 예에서 인스턴스 번호 03 및 HANA 시스템 ID HN1이 사용됩니다. SAP HANA 복제는 하나의 기본 노드와 하나 이상의 보조 노드로 구성됩니다.
이 문서의 단계에 다음 접두사가 표시되면 이는 다음을 의미합니다.
- [A]: 단계가 모든 노드에 적용됩니다.
- [1]: 단계가 노드 1에만 적용됩니다.
- [2]: 단계가 노드 2에만 적용됩니다.
다음 SAP Note 및 문서를 먼저 읽어 보세요.
- SAP Note 1928533에는 다음이 포함됩니다.
- SAP 소프트웨어 배포에 지원되는 Azure VM 크기 목록.
- Azure VM(가상 머신) 크기에 대한 중요한 용량 정보.
- 지원되는 SAP 소프트웨어 및 OS(운영 체제)와 데이터베이스 조합.
- Azure의 Windows 및 Linux에 필요한 SAP 커널 버전.
- SAP Note 2015553는 Azure에서 SAP을 지원하는 SAP 소프트웨어 배포에 대한 필수 구성 요소를 나열합니다.
- SAP Note 405827에는 HANA 환경에 권장되는 파일 시스템이 나열되어 있습니다.
- SAP Note 2684254에는 SAP 애플리케이션 15용 SLES(SUSE Linux Enterprise Server) 15/SLES에 권장되는 OS 설정이 나와 있습니다.
- SAP Note 1944799에는 SLES OS 설치에 대한 SAP HANA 지침이 있습니다.
- SAP Note 2178632는 Azure에서 SAP에 대해 보고된 모든 모니터링 메트릭에 대한 자세한 정보를 포함하고 있습니다.
- SAP Note 2191498는 Azure에서 Linux에 필요한 SAP Host Agent 버전을 포함하고 있습니다.
- SAP Note 2243692는 Azure에서 Linux의 SAP 라이선스에 대한 정보를 포함하고 있습니다.
- SAP Note 1999351에는 SAP용 Azure 고급 모니터링 확장에 대한 추가 문제 해결 정보가 있습니다.
- SAP Note 1900823: SAP HANA 스토리지 요구 사항에 대한 정보가 있습니다.
- SUSE SAP HA(고가용성) 우수 사례 가이드에는 NetWeaver HA 및 SAP HANA 시스템 복제 온-프레미스를 설정하는 데 필요한 모든 정보가 포함되어 있습니다(일반 기준으로 사용). 여기서 훨씬 더 자세한 정보를 제공합니다.
- SAP Community Wiki에는 Linux에 필요한 모든 SAP Note가 포함되어 있습니다.
- Linux에서 SAP용 Azure Virtual Machines 계획 및 구현
- Linux에서 SAP용 Azure Virtual Machines 배포
- Linux에서 SAP용 Azure Virtual Machines DBMS 배포
- 일반 SLES 설명서:
- Azure 관련 SLES 설명서:
- Azure NetApp Files를 사용하는 Microsoft Azure의 NetApp SAP 애플리케이션
- SAP HANA용 Azure NetApp Files 기반 NFS v4.1 볼륨
- Linux에서 SAP용 Azure Virtual Machines 계획 및 구현
참고 항목
이 문서에는 Microsoft에서 더 이상 사용하지 않는 용어에 대한 참조가 포함되어 있습니다. 소프트웨어에서 용어가 제거되면 이 문서에서 해당 용어가 제거됩니다.
개요
일반적으로 스케일 업 환경에서는 SAP HANA의 모든 파일 시스템이 로컬 스토리지에서 탑재됩니다. SUSE Enterprise Linux에서 SAP HANA 시스템 복제의 HA 설정은 SLES에서 SAP HANA 시스템 복제 설정에 게시되어 있습니다.
Azure NetApp Files NFS 공유에서 스케일 업 시스템의 SAP HANA HA를 달성하려면 클러스터에 추가 리소스 구성이 필요합니다. 한 노드가 Azure NetApp Files의 NFS 공유에 대한 액세스를 잃을 때 HANA 리소스를 복구할 수 있도록 이 구성이 필요합니다.
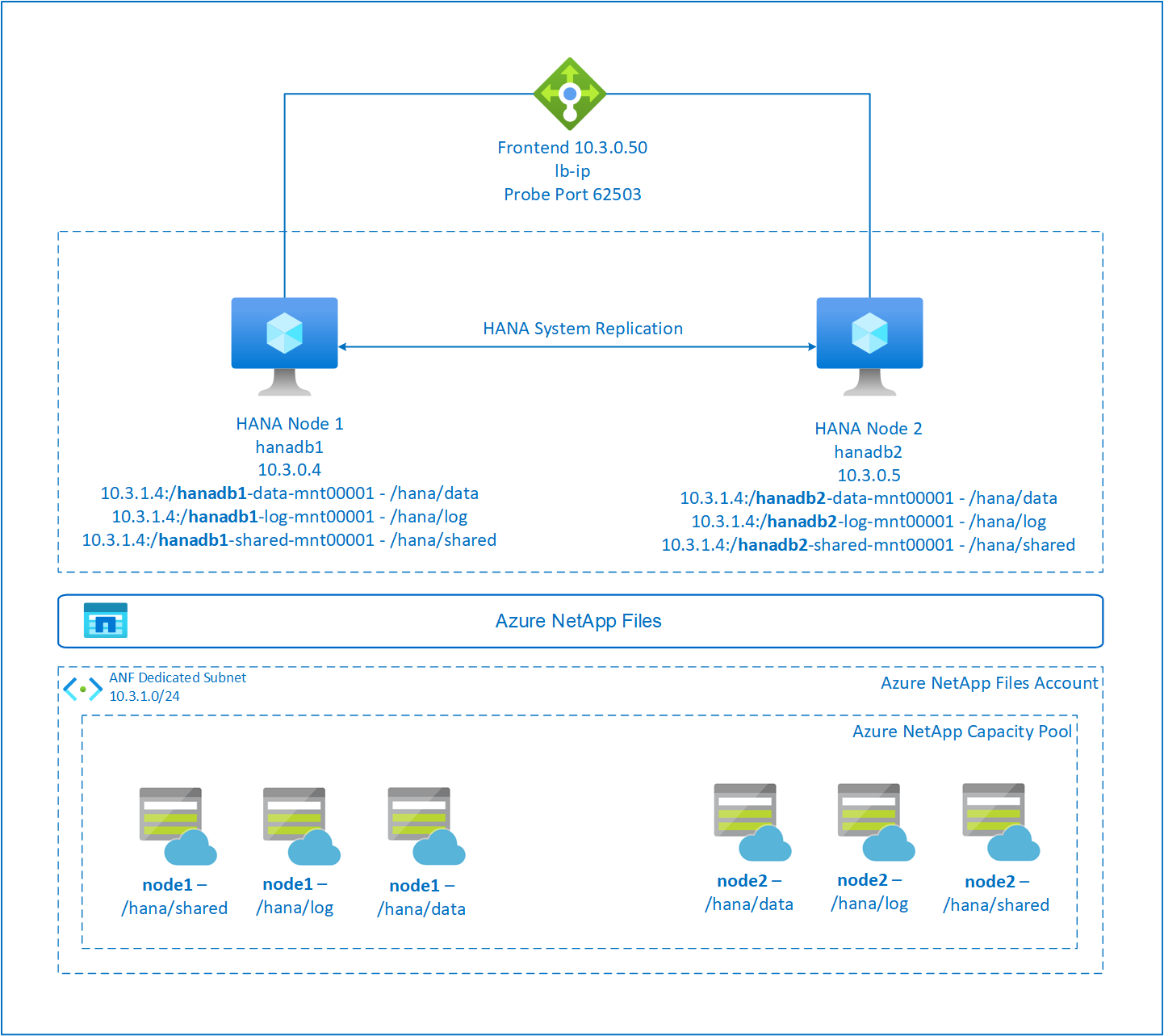
SAP HANA 파일 시스템은 각 노드에서 Azure NetApp Files를 사용하여 NFS 공유에 탑재됩니다. 파일 시스템 /hana/data, /hana/log 및 /hana/shared는 각 노드에 고유합니다.
Node1에 탑재됨(hanadb1):
- /hana/data에는 10.3.1.4:/hanadb1-data-mnt00001
- /hana/log에는 10.3.1.4:/hanadb1-log-mnt00001
- /hana/shared에는 10.3.1.4:/hanadb1-shared-mnt00001
Node2에 탑재됨(hanadb2):
- /hana/data에는 10.3.1.4:/hanadb2-data-mnt00001
- /hana/log에는 10.3.1.4:/hanadb2-log-mnt00001
- /hana/shared에는 10.3.1.4:/hanadb2-shared-mnt0001
참고 항목
파일 시스템 /hana/shared, /hana/data 및 /hana/log는 두 노드 간에 공유되지 않습니다. 각 클러스터 노드에는 별도의 파일 시스템이 있습니다.
SAP HA HANA 시스템 복제 구성은 전용 가상 호스트 이름과 가상 IP 주소를 사용합니다. Azure에서는 가상 IP 주소를 사용하려면 부하 분산 장치가 필요합니다. 제시된 구성은 다음이 포함된 부하 분산 장치를 보여 줍니다.
- 프런트 엔드 구성 IP 주소: hn1-db용 10.3.0.50
- 프로브 포트: 62503
Azure NetApp Files 인프라 설정
Azure NetApp Files 인프라 설정을 계속하려면 먼저 Azure NetApp Files 설명서를 잘 알고 있어야 합니다.
Azure NetApp Files는 여러 Azure 지역에서 사용할 수 있습니다. 선택한 Azure 지역에서 Azure NetApp Files를 제공하는지 확인하세요.
Azure 지역별 Azure NetApp Files 가용성에 대한 자세한 내용은 Azure 지역별 Azure NetApp Files 가용성을 참조하세요.
중요 사항
SAP HANA용 Azure NetApp Files 스케일업 시스템을 생성할 때 SAP HANA용 Azure NetApp Files 기반 NFS v4.1 볼륨에 설명된 중요한 고려 사항에 유의하세요.
Azure NetApp Files에서 HANA 데이터베이스 크기 조정
Azure NetApp Files 볼륨의 처리량은 Azure NetApp Files에 대한 서비스 수준에 설명된 대로 볼륨 크기와 서비스 수준의 함수입니다.
Azure NetApp Files를 사용하여 Azure의 SAP HANA에 대한 인프라를 설계할 때에는 SAP HANA용 Azure NetApp Files의 NFS v4.1 볼륨에 대한 권장 사항을 알고 있어야 합니다.
이 문서의 구성에는 간단한 Azure NetApp Files 볼륨이 제공됩니다.
Important
성능이 핵심인 프로덕션 시스템의 경우 SAP HANA용 Azure NetApp Files 애플리케이션 볼륨 그룹을 평가하고 사용하는 것이 좋습니다.
이 문서에서 /hana/shared를 탑재하는 모든 명령은 NFSv4.1 /hana/shared 볼륨에 대해 제공됩니다. /hana/shared 볼륨을 NFSv3 볼륨으로 배포한 경우 NFSv3에 대한 /hana/shared의 탑재 명령을 조정하는 것을 잊지 마세요.
Azure NetApp Files 리소스 배포
다음 지침에서는 Azure 가상 네트워크를 이미 배포했다고 가정합니다. Azure NetApp Files 리소스가 탑재될 Azure NetApp Files 리소스와 VM을 동일한 Azure 가상 네트워크 또는 피어링된 Azure 가상 네트워크에 배포해야 합니다.
NetApp 계정 만들기의 지침에 따라 선택한 Azure 지역에서 NetApp 계정을 만듭니다.
Azure NetApp Files 용량 풀 설정의 지침에 따라 Azure NetApp Files 용량 풀을 설정합니다.
이 문서에 제시된 HANA 아키텍처는 Ultra 서비스 수준에서 단일 Azure NetApp Files 용량 풀을 사용합니다. Azure의 HANA 워크로드의 경우 Azure NetApp Files Ultra 또는 Premium 서비스 수준을 사용하는 것이 좋습니다.
Azure NetApp Files에 서브넷 위임의 지침에 따라 Azure NetApp Files에 서브넷을 위임합니다.
Azure NetApp Files에 대한 NFS 볼륨 만들기의 지침에 따라 Azure NetApp Files 볼륨을 배포합니다.
볼륨을 배포할 때 NFSv4.1 버전을 선택해야 합니다. 지정된 Azure NetApp Files 서브넷에 볼륨을 배포합니다. Azure NetApp Files 볼륨의 IP 주소는 자동으로 할당됩니다.
Azure NetApp Files 리소스와 Azure VM은 동일하거나 피어링된 Azure 가상 네트워크에 있어야 합니다. 예를 들어 hanadb1-data-mnt00001, hanadb1-log-mnt00001 등은 볼륨 이름이고 nfs://10.3.1.4/hanadb1-data-mnt00001, nfs://10.3.1.4/hanadb1-log-mnt00001 등은 Azure NetApp Files 볼륨의 파일 경로입니다.
hanadb1에서
- hanadb1-data-mnt00001 볼륨(nfs://10.3.1.4:/hanadb1-data-mnt00001)
- hanadb1-log-mnt00001 볼륨(nfs://10.3.1.4:/hanadb1-log-mnt00001)
- hanadb1-shared-mnt00001 볼륨(nfs://10.3.1.4:/hanadb1-shared-mnt00001)
hanadb2에서
- hanadb2-data-mnt00001 볼륨(nfs://10.3.1.4:/hanadb2-data-mnt00001)
- hanadb2-log-mnt00001 볼륨(nfs://10.3.1.4:/hanadb2-log-mnt00001)
- hanadb2-shared-mnt00001 볼륨(nfs://10.3.1.4:/hanadb2-shared-mnt00001)
인프라 준비
SAP HANA의 리소스 에이전트는 SAP 애플리케이션의 SUSE Linux Enterprise Server에 포함되어 있습니다. SAP 애플리케이션 12 또는 15용 SUSE Linux Enterprise Server에 대한 이미지는 Azure Marketplace에서 사용할 수 있습니다. 이미지를 사용하여 새 VM을 배포할 수 있습니다.
Azure Portal을 통해 수동으로 Linux VM 배포
이 문서에서는 리소스 그룹, Azure Virtual Network 및 서브넷을 이미 배포했다고 가정합니다.
SAP HANA용 VM을 배포합니다. HANA 시스템에 지원되는 적합한 SLES 이미지를 선택합니다. 가상 머신 확장 집합, 가용성 영역 또는 가용성 집합 같은 옵션 중 하나에서 VM을 배포할 수 있습니다.
Important
선택한 운영 체제가 배포에 사용하려는 특정 VM 유형에서 SAP HANA용으로 인증된 SAP인지 확인해야 합니다. SAP HANA 인증 IaaS 플랫폼에서 SAP HANA 인증 VM 유형 및 해당 OS 릴리스 를 조회할 수 있습니다. 특정 VM 형식에 대한 SAP HANA 지원 OS 릴리스의 전체 목록을 보려면 VM 유형의 세부 정보를 확인하세요.
Azure Load Balancer 구성
VM 구성 중에 네트워킹 섹션에서 기존 부하 분산 장치를 만들거나 선택할 수 있는 옵션이 있습니다. HANA 데이터베이스의 HA 설정을 위한 표준 Load Balancer를 설정하려면 다음 단계를 따릅니다.
Azure Portal을 사용하여 고가용성 SAP 시스템용 표준 Load Balancer를 설정하려면 부하 분산 장치 만들기의 단계를 따릅니다. 부하 분산 장치를 설정하는 동안 다음 사항을 고려합니다.
- 프런트 엔드 IP 구성: 프런트 엔드 IP를 만듭니다. 데이터베이스 가상 머신과 동일한 가상 네트워크 및 서브넷 이름을 선택합니다.
- 백 엔드 풀: 백 엔드 풀을 만들고 데이터베이스 VM을 추가합니다.
- 인바운드 규칙: 부하 분산 규칙을 만듭니다. 두 부하 분산 규칙 모두에 대해 동일한 단계를 수행합니다.
- 프런트 엔드 IP 주소: 프런트 엔드 IP를 선택합니다.
- 백 엔드 풀: 백 엔드 풀을 선택합니다.
- 고가용성 포트: 이 옵션을 선택합니다.
- 프로토콜: TCP를 선택합니다.
- 상태 프로브: 다음 세부 정보를 사용하여 상태 프로브를 만듭니다.
- 프로토콜: TCP를 선택합니다.
- 포트: 예, 625<instance-no.>.
- 간격: 5를 입력합니다.
- 프로브 임계값: 2를 입력합니다.
- 유휴 시간 제한(분): 30을 입력합니다.
- 부동 IP 사용: 이 옵션을 선택합니다.
참고 항목
포털에서 비정상 임계값이라고도 알려진 상태 프로브 구성 속성 numberOfProbes는 준수되지 않습니다. 성공하거나 실패한 연속 프로브 수를 제어하려면 probeThreshold 속성을 2로 설정합니다. 현재 Azure Portal을 사용하여 이 속성을 설정할 수 없으므로 Azure CLI 또는 PowerShell 명령을 사용합니다.
SAP HANA에 필요한 포트에 대한 자세한 내용은 SAP HANA 테넌트 데이터베이스 가이드의 테넌트 데이터베이스에 연결 챕터 또는 SAP Note 2388694를 참조하세요.
공용 IP 주소가 없는 VM이 내부(공용 IP 주소 없음) 표준 Azure Load Balancer의 백 엔드 풀에 배치되면 공용 엔드포인트로의 라우팅을 허용하도록 추가 구성이 수행되지 않는 한 아웃바운드 인터넷 연결이 이루어지지 않습니다. 아웃바운드 연결을 달성하는 방법에 대한 자세한 내용은 SAP 고가용성 시나리오에서 Azure 표준 Load Balancer를 사용하는 VM에 대한 공용 엔드포인트 연결을 참조하세요.
Important
- Load Balancer 뒤에 배치되는 Azure VM에서 TCP 타임스탬프를 사용하도록 설정하면 안 됩니다. TCP 타임스탬프를 사용하도록 설정하면 상태 프로브에 오류가 발생합니다.
net.ipv4.tcp_timestamps매개 변수를0으로 설정합니다. 자세한 내용은 부하 분산 장치 상태 프로브 및 AP Note 2382421을 참조하세요. - saptune이 수동으로 설정된
net.ipv4.tcp_timestamps값을0에서 다시1로 변경하지 못하게 하려면 saptune 버전을 3.1.1 이상으로 업데이트합니다. 자세한 내용은 saptune 3.1.1 – 업데이트가 필요하나요?를 참조하세요.
Azure NetApp Files 볼륨 탑재
[A] HANA 데이터베이스 볼륨에 대한 탑재 지점을 만듭니다.
sudo mkdir -p /hana/data/HN1/mnt00001 sudo mkdir -p /hana/log/HN1/mnt00001 sudo mkdir -p /hana/shared/HN1[A] NFS 도메인 설정을 확인합니다. 도메인이 기본 Azure NetApp Files 도메인(예: defaultv4iddomain.com)으로 구성되어 있고 매핑이 nobody로 설정되어 있는지 확인합니다.
sudo cat /etc/idmapd.conf예제 출력:
[General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobodyImportant
VM의 /etc/idmapd.conf에서 NFS 도메인을 Azure NetApp Files의 기본 도메인 구성(defaultv4iddomain.com)과 일치하도록 설정합니다. NFS 클라이언트(즉, VM)의 도메인 구성과 NFS 서버(즉, Azure NetApp Files 구성)가 일치하지 않는 경우 VM에 탑재된 Azure NetApp Files 볼륨의 파일에 대한 사용 권한이 nobody로 표시됩니다.
[A] 두 노드에서
/etc/fstab를 편집하여 각 노드와 관련된 볼륨을 영구적으로 탑재합니다. 다음 예에서는 볼륨을 영구적으로 탑재하는 방법을 보여 줍니다.sudo vi /etc/fstab두 노드의
/etc/fstab에 다음 항목을 추가합니다.hanadb1의 예:
10.3.1.4:/hanadb1-data-mnt00001 /hana/data/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb1-log-mnt00001 /hana/log/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb1-shared-mnt00001 /hana/shared/HN1 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0hanadb2의 예:
10.3.1.4:/hanadb2-data-mnt00001 /hana/data/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb2-log-mnt00001 /hana/log/HN1/mnt00001 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0 10.3.1.4:/hanadb2-shared-mnt00001 /hana/shared/HN1 nfs rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 0 0모든 볼륨을 탑재합니다.
sudo mount -a더 높은 처리량이 필요한 워크로드의 경우 SAP HANA용 Azure NetApp Files의 NFS v4.1 볼륨에 설명된 대로
nconnect탑재 옵션을 사용하는 것이 좋습니다.nconnect를 Linux 릴리스에서 Azure NetApp Files가 지원하는지 확인합니다.[A] 모든 HANA 볼륨이 NFS 프로토콜 버전 NFSv4로 탑재되었는지 확인합니다.
sudo nfsstat -m플래그
vers가 4.1로 설정되어 있는지 확인합니다.hanadb1의 예:
/hana/log/HN1/mnt00001 from 10.3.1.4:/hanadb1-log-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.3.0.4,local_lock=none,addr=10.3.1.4 /hana/data/HN1/mnt00001 from 10.3.1.4:/hanadb1-data-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.3.0.4,local_lock=none,addr=10.3.1.4 /hana/shared/HN1 from 10.3.1.4:/hanadb1-shared-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.3.0.4,local_lock=none,addr=10.3.1.4[A] nfs4_disable_idmapping을 확인합니다. Y로 설정되어야 합니다. nfs4_disable_idmapping이 있는 디렉터리 구조를 만들려면 mount 명령을 실행합니다. 커널/드라이버에 대한 액세스가 예약되어 있으므로
/sys/modules아래에 디렉터리를 수동으로 만들 수 없습니다.#Check nfs4_disable_idmapping sudo cat /sys/module/nfs/parameters/nfs4_disable_idmapping #If you need to set nfs4_disable_idmapping to Y sudo echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping #Make the configuration permanent sudo echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.conf
SAP HANA 설치
[A] 모든 호스트의 호스트 이름 확인을 설정합니다.
DNS 서버를 사용하거나 모든 노드의
/etc/hosts파일을 수정할 수 있습니다. 다음 예제에서는/etc/hosts파일을 사용하는 방법을 보여 줍니다. 다음 명령에서 IP 주소와 호스트 이름을 바꿉니다.sudo vi /etc/hosts다음 줄을
/etc/hosts파일에 삽입합니다. 사용자 환경에 맞게 IP 주소와 호스트 이름을 변경합니다.10.3.0.4 hanadb1 10.3.0.5 hanadb2[A] SAP Note 3024346 - NetApp NFS용 Linux 커널 설정에 설명된 대로 NFS를 사용하여 Azure NetApp에서 SAP HANA를 실행하기 위한 OS를 준비합니다. NetApp 구성 설정에 대한 구성 파일
/etc/sysctl.d/91-NetApp-HANA.conf를 만듭니다.sudo vi /etc/sysctl.d/91-NetApp-HANA.conf구성 파일에 다음 항목을 추가합니다.
net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[A] 더 많은 최적화 설정을 사용하여 구성 파일
/etc/sysctl.d/ms-az.conf를 만듭니다.sudo vi /etc/sysctl.d/ms-az.conf구성 파일에 다음 항목을 추가합니다.
net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10팁
SAP 호스트 에이전트가 포트 범위를 관리할 수 있도록 sysctl 구성 파일에서
net.ipv4.ip_local_port_range및net.ipv4.ip_local_reserved_ports를 명시적으로 설정하지 마세요. 자세한 내용은 SAP Note 2382421을 참조하세요.[A] SAP Note 3024346 - NetApp NFS용 Linux 커널 설정에 권장된 대로
sunrpc설정을 조정합니다.sudo vi /etc/modprobe.d/sunrpc.conf다음 줄을 삽입합니다.
options sunrpc tcp_max_slot_table_entries=128[A] HANA용 SLES를 구성합니다.
SLES 버전에 따라 다음 SAP Note에 설명된 대로 SLES를 구성합니다.
[A] SAP HANA를 설치합니다.
HANA 2.0 SPS 01부터는 MDC(Multitenant Database Containers)가 기본 옵션입니다. HANA 시스템을 설치하는 경우 SYSTEMDB와 동일한 SID를 가진 테넌트를 함께 만듭니다. 경우에 따라 기본 테넌트가 필요하지 않습니다. 설치와 함께 초기 테넌트를 만들지 않으려면 SAP Note 2629711의 지침을 따릅니다.
HANA 설치 소프트웨어 디렉터리에서
hdblcm프로그램을 시작합니다../hdblcm프롬프트에서 다음 값을 입력합니다.
- 설치 선택: 1을 입력합니다(설치의 경우).
- 설치할 추가 구성 요소 선택: 1을 입력합니다.
- 설치 경로 입력[/hana/shared]: Enter 키를 눌러 기본값을 적용합니다.
- 로컬 호스트 이름 입력[..]: Enter 키를 눌러 기본값을 적용합니다.
- 시스템에 호스트를 더 추가하려고 하나요?(y/n) [n]: n을 선택합니다.
- SAP HANA 시스템 ID 입력: HN1을 입력합니다.
- 인스턴스 번호 입력[00]: 03을 입력합니다.
- 데이터베이스 모드 선택/인덱스 입력[1]: Enter 키를 눌러 기본값을 적용합니다.
- 시스템 사용량 선택/인덱스 입력 [4]: 4 입력합니다(사용자 지정).
- 데이터 볼륨 위치 입력[/hana/data]: Enter 키를 눌러 기본값을 적용합니다.
- 로그 볼륨 위치 입력[/hana/log]: Enter 키를 눌러 기본값을 적용합니다.
- 최대 메모리 할당을 제한하려고 하나요? [n]: Enter 키를 눌러 기본값을 적용합니다.
- 호스트 '...'에 대한 인증서 호스트 이름 입력[...]: Enter 키를 눌러 기본값을 적용합니다.
- SAP 호스트 에이전트 사용자(sapadm) 암호 입력: 호스트 에이전트 사용자 암호를 입력합니다.
- SAP 호스트 에이전트 사용자(sapadm) 암호 확인: 호스트 에이전트 사용자 암호를 다시 입력하여 확인합니다.
- 시스템 관리자(hn1adm) 암호 입력: 시스템 관리자 암호를 입력합니다.
- 시스템 관리자(hn1adm) 암호 확인: 시스템 관리자 암호를 다시 입력하여 확인합니다.
- 시스템 관리자 홈 디렉터리 입력[/usr/sap/HN1/home]: Enter 키를 눌러 기본값을 적용합니다.
- 시스템 관리자 로그인 셸 입력[/bin/sh]: Enter 키를 눌러 기본값을 적용합니다.
- 시스템 관리자 사용자 ID 입력[1001]: Enter 키를 눌러 기본값을 적용합니다.
- 사용자 그룹의 ID 입력(sapsys)[79]: Enter 키를 눌러 기본값 적용
- 데이터베이스 사용자(SYSTEM) 암호 입력: 데이터베이스 사용자 암호를 입력합니다.
- 데이터베이스 사용자(SYSTEM) 암호 확인: 데이터베이스 사용자 암호를 다시 입력하여 확인합니다.
- 컴퓨터 다시 부팅 후 시스템을 다시 시작하려고 하나요? [n]: Enter 키를 눌러 기본값을 적용합니다.
- 계속하려고 하나요?(y/n): 요약의 유효성을 검사합니다. 계속하려면 y를 입력합니다.
[A] SAP 호스트 에이전트를 업그레이드합니다.
SAP Software Center에서 최신 SAP 호스트 에이전트 아카이브를 다운로드하고 다음 명령을 실행하여 에이전트를 업그레이드합니다. 다운로드한 파일을 가리키도록 아카이브의 경로를 바꿉니다.
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP Host Agent SAR>
SAP HANA 시스템 복제 구성
SAP HANA 시스템 복제의 단계에 따라 SAP HANA 시스템 복제를 구성합니다.
클러스터 구성
이 섹션에서는 Azure NetApp Files를 사용하여 SAP HANA를 NFS 공유에 설치할 때 클러스터가 원활하게 작동하는 데 필요한 단계를 설명합니다.
Pacemaker 클러스터 만들기
Azure의 SUSE Enterprise Linux에서 Pacemaker 설정의 단계에 따라 이 HANA 서버에 대한 본 Pacemaker 클러스터를 만듭니다.
HANA 후크 SAPHanaSR 및 susChkSrv 구현
이 중요한 단계에서는 클러스터와의 통합을 최적화하고 클러스터 장애 조치(failover)가 필요할 때 검색 기능을 향상합니다. SAPHanaSR 및 susChkSrv Python 후크를 모두 구성하는 것이 좋습니다. PYTHON 시스템 복제 후크 SAPHanaSR/SAPHanaSR-angi 및 susChkSrv 구현의 단계를 따릅니다.
SAP HANA 클러스터 리소스 구성
이 섹션에서는 SAP HANA 클러스터 리소스를 구성하는 데 필요한 단계를 설명합니다.
SAP HANA 클러스터 리소스 만들기
SAP HANA 클러스터 리소스 만들기의 단계에 따라 HANA 서버에 대한 클러스터 리소스를 만듭니다. 리소스가 만들어진 후 다음 명령을 사용하여 클러스터의 상태를 확인해야 합니다.
sudo crm_mon -r
예제 출력:
# Online: [ hn1-db-0 hn1-db-1 ]
# Full list of resources:
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
파일 시스템 리소스 만들기
파일 시스템 /hana/shared/SID는 HANA 작업과 HANA의 상태를 결정하는 Pacemaker 모니터링 작업에도 필요합니다. 리소스 에이전트를 구현하여 오류 발생 시 모니터링하고 작동합니다. 섹션에는 두 가지 옵션이 포함되어 있습니다. 하나는 for SAPHanaSR 및 다른 옵션에 대한 것입니다 SAPHanaSR-angi.
더미 파일 시스템 클러스터 리소스를 만듭니다. NFS 탑재 파일 시스템 /hana/shared에 액세스하는 데 문제가 있는 경우 오류를 모니터링하고 보고합니다. 이를 통해 /hana/shared에 액세스하는 데 문제가 있는 경우 클러스터가 장애 조치(failover)를 트리거할 수 있습니다. 자세한 내용은 HANA 시스템 복제용 SUSE HA 클러스터에서 실패한 NFS 공유 처리를 참조하세요.
[A] 두 노드에 디렉터리 구조를 만듭니다.
sudo mkdir -p /hana/shared/HN1/check sudo mkdir -p /hana/shared/check[1] 모니터링할 디렉터리 구조를 추가하도록 클러스터를 구성합니다.
sudo crm configure primitive rsc_fs_check_HN1_HDB03 Filesystem params \ device="/hana/shared/HN1/check/" \ directory="/hana/shared/check/" fstype=nfs \ options="bind,defaults,rw,hard,rsize=262144,wsize=262144,proto=tcp,noatime,_netdev,nfsvers=4.1,lock,sec=sys" \ op monitor interval=120 timeout=120 on-fail=fence \ op_params OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 \ op stop interval=0 timeout=120[1] 클러스터에서 새로 구성된 볼륨을 복제하고 확인합니다.
sudo crm configure clone cln_fs_check_HN1_HDB03 rsc_fs_check_HN1_HDB03 meta clone-node-max=1 interleave=true예제 출력:
sudo crm status # Cluster Summary: # Stack: corosync # Current DC: hanadb1 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Tue Nov 2 17:57:39 2021 # Last change: Tue Nov 2 17:57:38 2021 by root via crm_attribute on hanadb1 # 2 nodes configured # 11 resource instances configured # Node List: # Online: [ hanadb1 hanadb2 ] # Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # rsc_SAPHanaTopology_HN1_HDB03 (ocf::suse:SAPHanaTopology): Started hanadb1 (Monitoring) # rsc_SAPHanaTopology_HN1_HDB03 (ocf::suse:SAPHanaTopology): Started hanadb2 (Monitoring) # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # rsc_SAPHana_HN1_HDB03 (ocf::suse:SAPHana): Master hanadb1 (Monitoring) # Slaves: [ hanadb2 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb1 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb1 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]OCF_CHECK_LEVEL=20특성이 모니터 작업에 추가되어 모니터 작업에서 파일 시스템의 읽기/쓰기 테스트를 수행합니다. 이 특성이 없으면 모니터 작업은 파일 시스템이 탑재되어 있는지만 확인합니다. 이는 연결이 끊어질 때 파일 시스템에 액세스할 수 없는 경우에도 탑재된 상태를 유지할 수 있기 때문에 문제가 될 수 있습니다.on-fail=fence특성도 모니터 작업에 추가됩니다. 이 옵션을 사용하면 노드에서 모니터 작업이 실패하는 경우 해당 노드가 즉시 펜싱됩니다.
Important
불필요한 펜스 작업을 피하기 위해 이전 구성의 시간 제한을 특정 HANA 설정에 맞게 조정해야 할 수도 있습니다. 시간 제한 값을 너무 낮게 설정하지 마세요. 파일 시스템 모니터는 HANA 시스템 복제와 관련이 없다는 점에 유의해야 합니다. 자세한 내용은 SUSE 설명서를 참조하세요.
클러스터 설정 테스트
이 섹션에서는 설정을 테스트하는 방법을 설명합니다.
테스트를 시작하기 전에 Pacemaker에 실패한 작업(crm 상태를 통해)이 없고 예기치 못한 위치 제약 조건(예: 마이그레이션 테스트의 남은 부분)이 없는지 확인합니다. 또한 HANA 시스템 복제가 동기화 상태인지 확인합니다(예:
systemReplicationStatus).sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"다음 명령을 사용하여 HANA 리소스의 상태를 확인합니다.
SAPHanaSR-showAttr # You should see something like below # hanadb1:~ SAPHanaSR-showAttr # Global cib-time maintenance # -------------------------------------------- # global Mon Nov 8 22:50:30 2021 false # Sites srHook # ------------- # SITE1 PRIM # SITE2 SOK # Site2 SOK # Hosts clone_state lpa_hn1_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost # -------------------------------------------------------------------------------------------------------------------------------------------------------------- # hanadb1 PROMOTED 1636411810 online logreplay hanadb2 4:P:master1:master:worker:master 150 SITE1 sync PRIM 2.00.058.00.1634122452 hanadb1 # hanadb2 DEMOTED 30 online logreplay hanadb1 4:S:master1:master:worker:master 100 SITE2 sync SOK 2.00.058.00.1634122452 hanadb2노드가 종료될 때 발생하는 오류 시나리오에 대한 클러스터 구성을 확인합니다. 다음 예에서는 노드 1 종료를 보여 줍니다.
sudo crm status sudo crm resource move msl_SAPHana_HN1_HDB03 hanadb2 force sudo crm resource cleanup예제 출력:
sudo crm status #Cluster Summary: # Stack: corosync # Current DC: hanadb2 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Mon Nov 8 23:25:36 2021 # Last change: Mon Nov 8 23:25:19 2021 by root via crm_attribute on hanadb2 # 2 nodes configured # 11 resource instances configured # Node List: # Online: [ hanadb1 hanadb2 ] # Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ] # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # Masters: [ hanadb2 ] # Stopped: [ hanadb1 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb2 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb2 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]Node1에서 HANA 중지:
sudo su - hn1adm sapcontrol -nr 03 -function StopWait 600 10노드 1을 보조 노드로 등록하고 상태 확인:
hdbnsutil -sr_register --remoteHost=hanadb2 --remoteInstance=03 --replicationMode=sync --name=SITE1 --operationMode=logreplay예제 출력:
#adding site ... #nameserver hanadb1:30301 not responding. #collecting information ... #updating local ini files ... #done.sudo crm statussudo SAPHanaSR-showAttr노드가 NFS 공유(/hana/shared)에 대한 액세스 권한을 잃을 때 장애 시나리오에 대한 클러스터 구성을 확인합니다.
SAP HANA 리소스 에이전트는 /hana/shared에 저장된 이진 파일을 사용하여 장애 조치(failover) 중 작업을 수행합니다. 제시된 시나리오에서는 파일 시스템 /hana/shared가 NFS를 통해 탑재됩니다.
서버 중 하나가 NFS 공유에 대한 액세스 권한을 상실하는 오류를 시뮬레이션하는 것은 어렵습니다. 테스트로 파일 시스템을 읽기 전용으로 다시 탑재할 수 있습니다. 이 방식은 활성 노드에서 /hana/shared에 대한 액세스가 손실된 경우 클러스터가 장애 조치(failover)될 수 있는지 유효성을 검사합니다.
예상 결과: /hana/shared를 읽기 전용 파일 시스템으로 만들 때 파일 시스템에서 읽기/쓰기 작업을 수행하는 리소스
hana_shared1의OCF_CHECK_LEVEL특성이 실패합니다. 파일 시스템에 아무것도 쓸 수 없고 HANA 리소스 장애 조치(failover)를 수행하기 때문에 실패합니다. HANA 노드가 NFS 공유에 액세스할 수 없는 경우에도 동일한 결과가 예상됩니다.테스트 시작 전 리소스 상태:
sudo crm status #Cluster Summary: # Stack: corosync # Current DC: hanadb2 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Mon Nov 8 23:01:27 2021 # Last change: Mon Nov 8 23:00:46 2021 by root via crm_attribute on hanadb1 # 2 nodes configured # 11 resource instances configured #Node List: # Online: [ hanadb1 hanadb2 ] #Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ] # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # Masters: [ hanadb1 ] # Slaves: [ hanadb2 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb1 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb1 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]다음 명령을 사용하여 활성 클러스터 노드에서 /hana/shared를 읽기 전용 모드로 설정할 수 있습니다.
sudo mount -o ro 10.3.1.4:/hanadb1-shared-mnt00001 /hana/sharedb서버
hanadb1은 작업 집합에 따라 다시 부팅되거나 전원이 꺼집니다. 서버(hanadb1)가 다운되면 HANA 리소스가hanadb2로 이동합니다.hanadb2에서 클러스터의 상태를 확인할 수 있습니다.sudo crm status #Cluster Summary: # Stack: corosync # Current DC: hanadb2 (version 2.0.5+20201202.ba59be712-4.9.1-2.0.5+20201202.ba59be712) - partition with quorum # Last updated: Wed Nov 10 22:00:27 2021 # Last change: Wed Nov 10 21:59:47 2021 by root via crm_attribute on hanadb2 # 2 nodes configured # 11 resource instances configured #Node List: # Online: [ hanadb1 hanadb2 ] #Full List of Resources: # Clone Set: cln_azure-events [rsc_azure-events]: # Started: [ hanadb1 hanadb2 ] # Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ] # Clone Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] (promotable): # Masters: [ hanadb2 ] # Stopped: [ hanadb1 ] # Resource Group: g_ip_HN1_HDB03: # rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hanadb2 # rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hanadb2 # rsc_st_azure (stonith:fence_azure_arm): Started hanadb2 # Clone Set: cln_fs_check_HN1_HDB03 [rsc_fs_check_HN1_HDB03]: # Started: [ hanadb1 hanadb2 ]SAP HANA 시스템 복제에서 설명하는 테스트도 수행하여 SAP HANA 클러스터 구성을 철저히 테스트하는 것이 좋습니다.