이미지에는 종종 검색 시나리오와 관련된 유용한 정보가 포함됩니다. 이미지를 벡터화하여 검색 인덱스에서 시각적 콘텐츠를 나타낼 수 있습니다. 또는 AI 보강 및 기술 세트를 사용하여 다음을 포함하여 이미지에서 검색 가능한 텍스트를 만들고 추출할 수 있습니다.
OCR을 사용하면 중지 기호의 STOP 단어와 같은 사진이나 그림에서 텍스트를 추출할 수 있습니다. 이미지 분석을 통해 민들레 사진의 민들레 또는 노란색과 같은 이미지의 텍스트 표현을 생성할 수 있습니다. 또한 해당 크기와 같은 이미지에 대한 메타데이터를 추출할 수 있습니다.
이 문서에서는 기술 세트에서 이미지 작업의 기본 사항을 설명하고 포함된 이미지 작업, 사용자 지정 기술, 원본 이미지에 대한 시각화 오버레이와 같은 몇 가지 일반적인 시나리오에 대해서도 설명합니다.
기술 세트에서 이미지 콘텐츠를 작업하려면 다음이 필요합니다.
- 이미지를 포함하는 원본 파일
- 이미지 작업에 대해 구성된 검색 인덱서
- OCR 또는 이미지 분석을 호출하는 기본 제공 또는 사용자 지정 기술이 있는 기술 세트
- 분석된 텍스트 출력을 받을 필드가 있는 검색 인덱스와 연결을 설정하는 인덱서의 출력 필드 매핑
필요에 따라 데이터 마이닝 시나리오에 대한 지식 저장소에 이미지 분석 출력을 허용하는 프로젝션을 정의할 수 있습니다.
원본 파일 설정
이미지 처리는 인덱서 기반이므로 원시 입력은 지원되는 데이터 원본에 있어야 합니다.
- 이미지 분석은 JPEG, PNG, GIF 및 BMP를 지원합니다.
- OCR은 JPEG, PNG, BMP 및 TIF를 지원합니다.
이미지는 독립 실행형 이진 파일이거나 PDF, RTF 또는 Microsoft 애플리케이션 파일과 같은 문서에 포함되어 있습니다. 지정된 문서에서 최대 1,000개의 이미지를 추출할 수 있습니다. 문서에 1,000개 이상의 이미지가 있는 경우 처음 1,000개의 이미지가 추출된 다음 경고가 생성됩니다.
Azure Blob Storage는 Azure AI 검색에서 이미지 처리에 가장 자주 사용되는 스토리지입니다. Blob 컨테이너에서 이미지를 검색하는 데 관련된 세 가지 주요 작업이 있습니다.
컨테이너의 콘텐츠에 대한 액세스를 사용하도록 설정합니다. 키가 포함된 전체 액세스 연결 문자열을 사용하는 경우 키는 콘텐츠에 대한 권한을 부여합니다. 또는 Microsoft Entra ID를 사용하여 인증하거나 신뢰할 수 있는 서비스로 연결할 수 있습니다.
파일을 저장하는 Blob 컨테이너에 연결하는 azureblob 형식의 데이터 원본을 만듭니다.
서비스 계층 제한을 검토하여 원본 데이터가 인덱서 및 보강에 대한 최대 크기 및 수량 제한보다 미만인지 확인합니다.
이미지 처리를 위한 인덱서 구성
원본 파일을 설정된 후 인덱서 구성에서 imageAction 매개 변수를 설정하여 이미지 정규화를 사용하도록 설정합니다. 이미지 정규화는 다운스트림 처리를 위해 이미지를 더욱 균일하게 만드는 데 도움이 됩니다. 이미지 정규화에는 다음 작업이 포함됩니다.
- 큰 이미지는 균일하게 만들도록 최대 높이 및 너비로 크기가 조정됩니다.
- 방향을 지정하는 메타데이터가 있는 이미지의 경우 세로 로딩을 위해 이미지 회전이 조정됩니다.
매개 변수를 imageAction의 기본값이 아닌 다른 값으로 설정하면 none에 따라 이미지 추출에 추가 요금이 발생합니다.
메타데이터 조정은 각 이미지에 대해 만든 복합 형식으로 캡처됩니다. 이미지 정규화 요구 사항을 옵트아웃할 수 없습니다. OCR 및 이미지 분석과 같은 이미지를 반복하는 기술에는 정규화된 이미지를 사용하는 것이 좋습니다.
구성 속성을 설정하기 위해 인덱서 만들기 또는 업데이트:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }dataToExtract을contentAndMetadata로 설정합니다(필수).기본값(
parsingMode필수)으로 설정되어 있는지 확인 합니다.이 매개 변수는 인덱스에서 만든 검색 문서의 세분성을 결정합니다. 기본 모드는 하나의 Blob이 하나의 검색 문서를 생성하도록 일대일 대응을 설정합니다. 문서가 크거나 기술에 더 작은 텍스트 청크가 필요한 경우 처리를 위해 문서를 페이징으로 세분화하는 텍스트 분할 기술을 추가할 수 있습니다. 그러나 검색 시나리오의 경우 보강에 이미지 처리가 포함되어 있으면 문서당 하나의 Blob이 필요합니다.
보강 트리에서 노드를
imageAction사용하도록 설정normalized_images(필수):정규화된 이미지의 배열을 문서 크래킹의 일부로 생성하려면
generateNormalizedImages로 설정합니다.generateNormalizedImagePerPage(PDF에만 적용됨) PDF의 각 페이지가 한 개의 출력 이미지로 렌더링되는 경우 정규화된 이미지 배열을 생성합니다. PDF가 아닌 파일의 경우 이 매개 변수의 동작은 설정한generateNormalizedImages것과 비슷합니다. 그러나 여러 이미지를 생성해야 하므로 설정generateNormalizedImagePerPage으로 인해 인덱싱 작업이 디자인에 따라 성능이 낮아질 수 있습니다(특히 큰 문서의 경우).
필요에 따라 생성된 정규화된 이미지의 너비 또는 높이를 조정합니다.
normalizedImageMaxWidth픽셀 단위입니다. 기본값은 2,000입니다. 최대값은 10,000입니다.normalizedImageMaxHeight픽셀 단위입니다. 기본값은 2,000입니다. 최대값은 10,000입니다.
정규화된 이미지의 최대 너비와 높이에 대한 기본값은 OCR 기술 및 이미지 분석 기술에서 지원하는 최대 크기를 기반으로 합니다. OCR 기술은 영어가 아닌 언어의 경우 최대 너비 및 높이 4,200, 영어 10,000을 지원합니다. 최대 한도를 늘리면 기술 세트 정의 및 문서의 언어에 따라 큰 이미지 처리에 실패할 수 있습니다.
필요에 따라 워크로드가 특정 파일 형식을 대상으로 하는 경우 파일 형식 조건을 설정합니다. Blob 인덱서 구성에는 파일 포함 및 제외 설정이 포함됩니다. 원하지 않는 파일을 필터링할 수 있습니다.
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
정규화된 이미지 정보
없음imageAction값으로 설정되면 새 normalized_images 필드에 이미지 배열이 포함됩니다. 각 이미지는 다음 멤버가 포함된 복합 형식입니다.
| 이미지 멤버 | 설명 |
|---|---|
| 데이터 | JPEG 형식의 BASE64 인코딩된 정규화된 이미지 문자열입니다. |
| 너비 | 픽셀 단위로 정규화된 이미지의 너비입니다. |
| 높이 | 픽셀 단위로 정규화된 이미지의 높이입니다. |
| 원래 너비 | 정규화 이전에 이미지의 원래 너비입니다. |
| 원본 높이 | 정규화 이전에 이미지의 원래 높이입니다. |
| 원본에서의 회전 | 정규화된 이미지를 만들기 위해 발생한 시계 반대 방향 회전입니다. 0도에서 360도 사이의 값입니다. 이 단계에서는 카메라 또는 스캐너에서 생성하는 이미지의 메타데이터를 읽습니다. 일반적으로 90도의 배수입니다. |
| 콘텐츠 오프셋 (contentOffset) | 이미지가 추출된 콘텐츠 필드 내의 문자 오프셋입니다. 이 필드는 포함된 이미지가 있는 파일에만 적용됩니다.
contentOffset PDF 문서에서 추출된 이미지의 경우 항상 문서에서 추출된 페이지의 텍스트 끝에 있습니다. 즉, 이미지는 페이지의 이미지 원래 위치에 관계없이 해당 페이지의 모든 텍스트 뒤에 표시됩니다. |
| 페이지 번호 | 이미지를 추출하거나 PDF에서 렌더링하는 경우, 해당 필드에는 1부터 시작되는 추출 또는 렌더링된 PDF 페이지 번호가 포함됩니다. 이미지가 PDF 이미지가 아닌 경우, 해당 필드는 0입니다. |
| boundingPolygon | 이미지를 PDF에서 추출하거나 렌더링한 경우 이 필드에는 페이지에 이미지를 묶는 경계 다각형의 좌표가 포함됩니다. 다각형은 각 지점에 페이지의 크기로 정규화된 x 및 y 좌표가 있는 점의 중첩된 배열로 표시됩니다. 이는 .를 사용하여 imageAction: generateNormalizedImages추출된 이미지에만 적용됩니다. |
샘플 값:normalized_images
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2,
"boundingPolygon": "[[{\"x\":0.0,\"y\":0.0},{\"x\":500.0,\"y\":0.0},{\"x\":0.0,\"y\":300.0},{\"x\":500.0,\"y\":300.0}]]"
}
]
참고 항목
경계 다각형 데이터는 이중 중첩된 JSON 인코딩 배열로 되어 있는 다각형들을 포함하는 문자열로 나타납니다. 각 다각형은 점의 배열로, 각 지점에는 x 및 y 좌표가 있습니다. 좌표는 왼쪽 위 모서리에 원본(0, 0)이 있는 PDF 페이지를 기준으로 합니다.
현재 추출된 imageAction: generateNormalizedImages 이미지는 항상 단일 다각형을 생성하지만 이중 중첩 구조는 여러 다각형을 지원하는 문서 레이아웃 기술과 일관성을 유지하기 위해 유지 관리됩니다.
이미지 처리를 위한 기술 세트 정의
이 섹션에서는 이미지 처리와 관련된 기술 입력, 출력 및 패턴 작업에 대한 컨텍스트를 제공하여 기술 참조 문서를 보완합니다.
기술 세트를 만들거나 업데이트하여 기술을 추가합니다.
Azure Portal에서 OCR 및 이미지 분석에 대한 템플릿을 추가하거나 기술 참조 설명서에서 정의를 복사합니다. 기술 세트 정의의 기술 배열에 삽입합니다.
필요한 경우 기술 세트의 Azure AI 서비스 속성에 다중 서비스 키를 포함합니다. Azure AI 검색은 무료 제한을 초과하는 트랜잭션에 대한 OCR 및 이미지 분석을 위해 청구 가능한 Azure AI 서비스 리소스를 호출합니다(일간 인덱서당 20개). Azure AI 서비스는 검색 서비스와 동일한 지역에 있어야 합니다.
원본 이미지가 PDF 또는 응용 프로그램 파일(예: PPTX 또는 DOCX)에 포함된 경우 이미지 출력과 텍스트 출력을 함께 사용하려면 텍스트 병합 기술을 추가해야 합니다. 포함된 이미지 작업에 대해서는 이 문서에서 자세히 설명합니다.
기술 세트의 기본 프레임워크가 만들어지고 Azure AI 서비스가 구성되면 각 개별 이미지 기술에 중점을 두어 입력 및 원본 컨텍스트를 정의하고 출력을 인덱스 또는 지식 저장소의 필드에 매핑할 수 있습니다.
참고 항목
이미지 처리를 다운스트림 자연어 처리 와 결합하는 기술 세트의 예는 REST 자습서: REST 및 AI를 사용하여 Azure Blob에서 검색 가능한 콘텐츠를 생성합니다. 기술 이미징 출력을 엔터티 인식 및 핵심 구 추출에 공급하는 방법을 보여 줍니다.
이미지 처리를 위한 입력
설명한 대로 이미지는 문서 크래킹 중에 추출된 다음, 예비 단계로 정규화됩니다. 정규화된 이미지는 모든 이미지 처리 기술에 대한 입력이며 항상 보강된 문서 트리에 두 가지 방법 중 하나로 표시됩니다.
/document/normalized_images/*는 전체로 처리되는 문서용입니다./document/normalized_images/*/pages는 청크(페이지)로 처리되는 문서용입니다.
OCR 및 이미지 분석을 동일하게 사용할 경우 입력은 거의 동일한 구성을 갖습니다.
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
검색 필드에 출력 매핑
기술 세트에서 이미지 분석 및 OCR 기술 출력은 항상 텍스트입니다. 출력 텍스트는 내부 보강된 문서 트리의 노드로 표시되며, 각 노드는 앱에서 콘텐츠를 사용할 수 있도록 검색 인덱스의 필드 또는 지식 저장소의 프로젝션에 매핑되어야 합니다.
기술 세트에서 각 기술의
outputs섹션을 검토하여 보강된 문서에 존재하는 노드를 확인합니다.{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }검색 인덱스를 만들거나 업데이트하여 기술 출력을 수락할 필드를 추가합니다.
다음 필드 컬렉션 예제에서 콘텐츠 는 Blob 콘텐츠입니다. Metadata_storage_name 파일의 이름을 포함합니다(true
retrievable설정). Metadata_storage_path Blob의 고유한 경로이며 기본 문서 키입니다. Merged_content 텍스트 병합의 출력입니다(이미지가 포함된 경우 유용).Text 및 layoutText 는 OCR 기술 출력이며 전체 문서에 대해 모든 OCR 생성 출력을 캡처하려면 문자열 컬렉션이어야 합니다.
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],기술 세트 출력(보강 트리의 노드)을 인덱스 필드에 매핑하기 위해 인덱서를 업데이트합니다.
보강된 문서는 내부 문서입니다. 보강된 문서 트리에서 노드를 외부화하려면 노드 콘텐츠를 수신하는 인덱스 필드를 지정하는 출력 필드 매핑을 설정합니다. 인덱스 필드를 통해 앱에서 보강된 데이터에 액세스합니다. 다음 예제에서는 검색 인덱스의 텍스트 필드에 매핑된 보강된 문서의 텍스트 노드(OCR 출력)를 보여 줍니다.
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]인덱서를 실행하여 원본 문서 검색, 이미지 처리 및 인덱싱을 호출합니다.
결과 확인
인덱스에 대해 쿼리를 실행하여 이미지 처리 결과를 확인합니다. 검색 탐색기를 검색 클라이언트 또는 HTTP 요청을 보내는 도구로 사용합니다. 다음 쿼리는 이미지 처리의 출력을 포함하는 필드를 선택합니다.
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
OCR은 이미지 파일의 텍스트를 인식합니다. 즉, 원본 문서가 순수 텍스트이거나 순수 이미지인 경우 OCR 필드(텍스트 및 layoutText)가 비어 있습니다. 마찬가지로 원본 문서 입력이 엄격하게 텍스트인 경우 이미지 분석 필드(imageCaption 및 imageTags)는 비어 있습니다. 이미징 입력이 비어 있으면 인덱서 실행에서 경고를 내보냅니다. 보강된 문서에서 노드가 채워지지 않은 경우 이러한 경고가 예상됩니다. Blob 인덱싱을 사용하면 콘텐츠 형식을 격리된 상태로 작업하려는 경우 파일 형식을 포함하거나 제외할 수 있습니다. 이러한 설정을 사용하여 인덱서 실행 중 노이즈를 줄일 수 있습니다.
결과를 확인하기 위한 대체 쿼리에는 콘텐츠 및 merged_content 필드가 포함될 수 있습니다. 이러한 필드에는 모든 Blob 파일에 대한 콘텐츠가 포함되며, 심지어 이미지 처리가 수행되지 않은 필드도 포함됩니다.
기술 출력 정보
기술 출력에는 OCR(),(OCR), textlayoutText( merged_content 이미지 분석) (이미지 분석) captions 이 포함 tags 됩니다.
text은 OCR 생성 출력을 저장합니다. 이 노드는Collection(Edm.String)형식의 필드에 매핑되어야 합니다. 여러 이미지를 포함하는 문서에 대한 쉼표로 구분된 문자열로 구성된 검색 문서당 하나의text필드가 있습니다. 다음 그림에서는 세 개의 문서에 대한 OCR 출력을 보여 줍니다. 첫 번째는 이미지가 없는 파일이 포함된 문서입니다. 두 번째는 한 단어 인 Microsoft를 포함하는 문서(이미지 파일)입니다. 세 번째는 여러 이미지가 포함된 문서이며, 일부는 텍스트가 없는 문서입니다("",)."value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]layoutText에서는 정규화된 이미지의 경계 상자 및 좌표에 대해 설명된 페이지에 텍스트 위치에 대한 OCR 생성 정보를 저장합니다. 이 노드는Collection(Edm.String)형식의 필드에 매핑되어야 합니다. 쉼표로 구분된 문자열로 구성된 검색 문서당 하나의layoutText필드가 있습니다.merged_content는 텍스트 병합 기술의 출력을 저장하며, 이미지 대신 포함된Edm.String원본 문서의 원시 텍스트를 포함하는 하나의 큰 형식text필드여야 합니다. 파일이 텍스트 전용인 경우 OCR 및 이미지 분석은 아무 작업도 수행하지 않으며(Blob의 콘텐츠를 포함하는 Blob 속성)과merged_content동일합니다content.imageCaption는 이미지에 대한 설명을 개별 태그로 캡처하고 더 긴 텍스트 설명을 캡처합니다.imageTags는 이미지에 대한 태그를 원본 문서의 모든 이미지에 대한 하나의 컬렉션인 키워드 컬렉션으로 저장합니다.
다음 스크린샷은 텍스트 및 포함된 이미지를 포함하는 PDF의 그림입니다. 문서 크래킹이 갈매기 무리, 지도, 독수리의 세 가지 내장 된 이미지를 감지했습니다. 예제의 다른 텍스트(타이틀, 제목 및 본문 텍스트 포함)는 텍스트로 추출되어 이미지 처리에서 제외되었습니다.
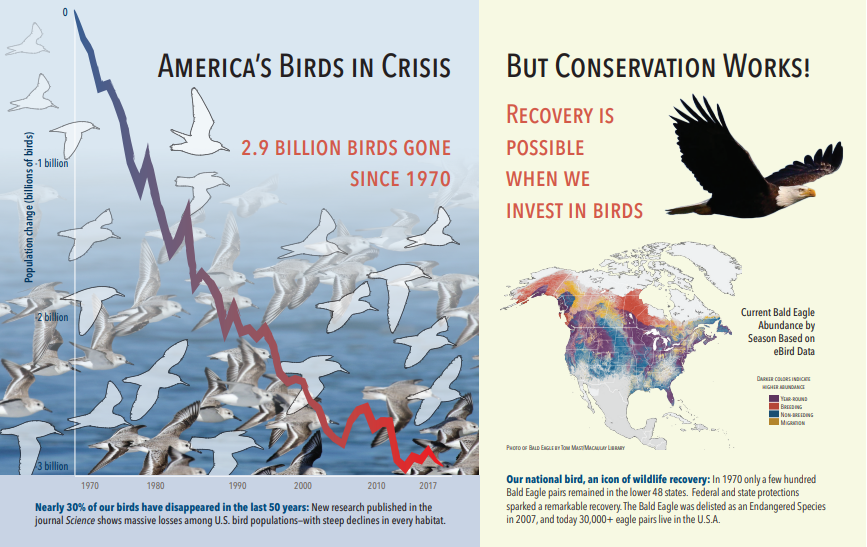
이미지 분석 출력은 다음 JSON(검색 결과)에 설명되어 있습니다. 기술 정의를 사용하면 관심 있는 시각적 개체 기능을 지정할 수 있습니다. 이 예제의 경우 태그와 설명이 생성되었지만 선택할 수 있는 출력이 더 많습니다.
imageCaption출력은 이미지당 하나씩 설명의 배열로,tags이미지를 설명하는 단일 단어와 더 긴 구로 구성됩니다. 갈매기 무리로 구성된 태그가 물 속에서 헤엄치거나 새를 클로즈업합니다.imageTags출력은 단일 태그의 배열로, 생성 순서대로 나열됩니다. 태그가 반복되는 것을 볼 수 있습니다. 집계 또는 그룹화는 없습니다.
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
시나리오: PDF의 포함된 이미지
처리하려는 이미지가 PDF 또는 DOCX와 같은 다른 파일에 포함되면 보강 파이프라인은 이미지만 추출한 다음 처리를 위해 OCR 또는 이미지 분석에 전달합니다. 이미지 추출은 문서 크래킹 단계 중에 발생하며, 이미지가 분리되면 처리된 출력을 원본 텍스트에 명시적으로 다시 병합하지 않는 한 분리된 상태로 유지됩니다.
텍스트 병합은 이미지 처리 출력을 문서에 다시 넣는 데 사용됩니다. 텍스트 병합은 어려운 요구 사항은 아니지만 이미지 출력(OCR text, OCR layoutText, image tags, image captions)을 문서에 다시 도입할 수 있도록 자주 호출됩니다. 기술에 따라 이미지 출력은 포함된 이진 이미지를 해당하는 현재 위치 텍스트로 바꿉니다. 이미지 분석 출력은 이미지 위치에서 병합할 수 있습니다. OCR 출력은 항상 각 페이지의 끝에 표시됩니다.
다음 워크플로에서는 이미지 추출, 분석, 병합 프로세스 및 파이프라인을 확장하여 이미지 처리 출력을 엔터티 인식 또는 텍스트 번역과 같은 다른 텍스트 기반 기술로 푸시하는 방법을 간략하게 설명합니다.
데이터 원본에 연결한 후 인덱서는 원본 문서를 로드 및 크랙킹하여 이미지와 텍스트를 추출하고, 처리를 위해 각 콘텐츠 형식을 큐에 대기시킵니다. 루트 노드(문서)로만 구성된 보강된 문서가 만들어집니다.
이미지 보강은
"/document/normalized_images"를 입력으로 사용하여 실행됩니다.이미지 출력은 각 출력을 별도의 노드로 하여 보강된 문서 트리로 전달됩니다. 출력은 기술(OCR의 경우 text 및 layoutText, 이미지 분석을 위한 태그 및 캡션)에 따라 다릅니다.
검색 문서에 텍스트 및 이미지 원본 텍스트를 모두 포함하고, 텍스트 병합을 실행하여 해당 이미지의 텍스트 표현을 파일에서 추출된 원시 텍스트와 결합하는 경우 선택 사항이지만 권장됩니다. 텍스트 청크는 단일 큰 문자열로 통합되고, 여기서 텍스트는 문자열에 먼저 삽입된 다음 OCR 텍스트 출력 또는 이미지 태그 및 캡션에 삽입됩니다.
텍스트 병합의 출력은 이제 텍스트 처리를 수행하는 다운스트림 기술에 대해 분석할 최종 텍스트입니다. 예를 들어 기술 세트에 OCR 및 엔터티 인식이 모두 포함된 경우 엔터티 인식에 대한 입력은
"document/merged_text"(텍스트 병합 기술 출력의 targetName)이어야 합니다.모든 기술이 실행되면 보강된 문서가 완료됩니다. 마지막 단계에서 인덱서는 출력 필드 매핑을 참조하여 검색 인덱스의 개별 필드에 보강된 콘텐츠를 보냅니다.
다음 예제 기술 세트는 포함된 이미지 대신 포함된 OCR 처리된 텍스트가 있는 문서의 원본 텍스트가 포함된 merged_text 필드를 만듭니다. 또한 입력으로 merged_text를 사용하는 엔터티 인식 기술도 포함됩니다.
요청 본문 구문
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
이제 필드가 있으므로 merged_text 인덱서 정의에서 검색 가능한 필드로 매핑할 수 있습니다. 이미지의 텍스트를 포함하여 파일의 모든 콘텐츠를 검색할 수 있습니다.
시나리오: 경계 상자 시각화
또 다른 일반적인 시나리오는 검색 결과 레이아웃 정보를 시각화하는 것입니다. 예를 들어 이미지에서 발견한 텍스트의 조각을 검색 결과의 일부로 강조 표시하는 것이 좋습니다.
OCR 단계는 정규화된 이미지에 수행되므로 레이아웃 좌표는 정규화된 이미지 공간에 있지만 원본 이미지를 표시해야 하는 경우 레이아웃의 좌표점을 원본 이미지 좌표계로 변환합니다.
다음 알고리즘은 패턴을 보여 줍니다.
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
시나리오: 사용자 지정 이미지 기술
이미지를 사용자 지정 기술로 전달하고 반환할 수도 있습니다. 기술 세트는 사용자 지정 기술에 전달되는 이미지를 base64로 인코딩합니다. 사용자 지정 기술 내에서 이미지를 사용하려면 "/document/normalized_images/*/data"를 사용자 지정 기술에 대한 입력으로 설정합니다. 사용자 지정 기술 코드 내에서, 문자열을 이미지로 변환하기 전에 base64로 디코딩합니다. 이미지를 기술 세트로 반환하려면 반환하기 전에 base64로 인코딩합니다.
이미지는 다음 속성을 가진 개체로서 반환됩니다.
{
"$type": "file",
"data": "base64String"
}
Azure Search Python 샘플 리포지토리에는 이미지를 보강하는 사용자 지정 기술의 Python에서 구현된 전체 샘플이 있습니다.
사용자 지정 기술에 이미지 전달
이미지 작업에 사용자 지정 기술이 필요한 시나리오의 경우, 사용자 지정 기술에 이미지를 전달하여 텍스트 또는 이미지를 반환할 수 있습니다. 다음 기술 세트는 샘플에서 가져온 것입니다.
다음 기술 세트는 정규화된 이미지(문서를 크래킹하는 동안 가져옴)를 사용하며 이미지 조각을 출력합니다.
샘플 기술 세트
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
사용자 지정 기술 예제
사용자 지정 기술 자체는 기술 세트 외부에 있습니다. 이 경우에는 Python 코드가 먼저 사용자 지정 기술 형식의 요청 레코드 일괄 처리를 반복한 다음 base64로 인코딩된 문자열을 이미지로 변환하게 됩니다.
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
이미지를 반환하는 것과 마찬가지로 파일$type이 있는 JSON 개체 내에서 base64로 인코딩된 문자열을 반환합니다.
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}