점수 매기기 프로필은 조건에 따라 일치하는 문서의 순위를 높이는 데 사용됩니다. 이 문서에서는 제공하는 매개 변수에 따라 검색 점수를 높이는 점수 매기기 프로필을 지정하고 할당하는 방법을 알아봅니다. 다음을 기반으로 점수 매기기 프로필을 만들 수 있습니다.
가중치가 지정된 필드입니다. 여기서 부스팅은 특정 문자열 필드에 있는 일치 항목을 기반으로 합니다. 예를 들어 "제목" 필드에 있는 일치 항목이 "설명" 필드에 있는 것과 동일한 일치 항목보다 관련성이 더 높아야 하는 경우입니다.
숫자 데이터에 대한 함수 - 날짜, 범위 및 지리적 좌표를 포함합니다. 임의의 문자열 컬렉션을 제공하는 필드에서 작동하는 Tags 함수도 있습니다. 태그 필드에 일치하는 항목이 있는지 여부에 따라 점수를 높이려는 경우 가중치 필드보다 이 방법을 선택할 수 있습니다.
Azure 포털에서 JSON 정의를 편집하거나 Azure SDK에서 제공하는 Create or Update Index REST 또는 이에 상응하는 API를 통해 프로그래밍 방식으로 인덱스에 스코어링 프로필을 추가할 수 있습니다.
필수 조건
키워드 검색의 점수 매기기 프로필에 API 버전 또는 SDK 패키지를 사용할 수 있습니다. 벡터 및 하이브리드 검색의 경우 기능 패리티를 제공하는 2024-05-01-preview 및 2024-07-01 REST API 또는 Azure SDK 패키지를 사용합니다. 점수 프로필과 시맨틱 랭커 간의 통합을 위해 2025-05-01-preview 버전 및 이후를 사용합니다.
점수 매기기 프로필 규칙
텍스트 또는 숫자 필드가 있는 새 검색 인덱스 또는 기존 검색 인덱스가 있어야 합니다.
키워드 검색, 벡터 검색 및 하이브리드 검색에서 점수 매기기 프로필을 사용할 수 있습니다. 그러나 점수 매기기 프로필은 비벡터 필드에만 적용되므로 인덱스에 증가하거나 가중치를 적용할 수 있는 텍스트 또는 숫자 필드가 있는지 확인합니다.
인덱스 하나에 최대 100개의 점수 매기기 프로필을 포함할 수는 있지만(서비스 한도 참조) 프로필은 지정된 쿼리에 한 번에 하나만 지정할 수 있습니다.
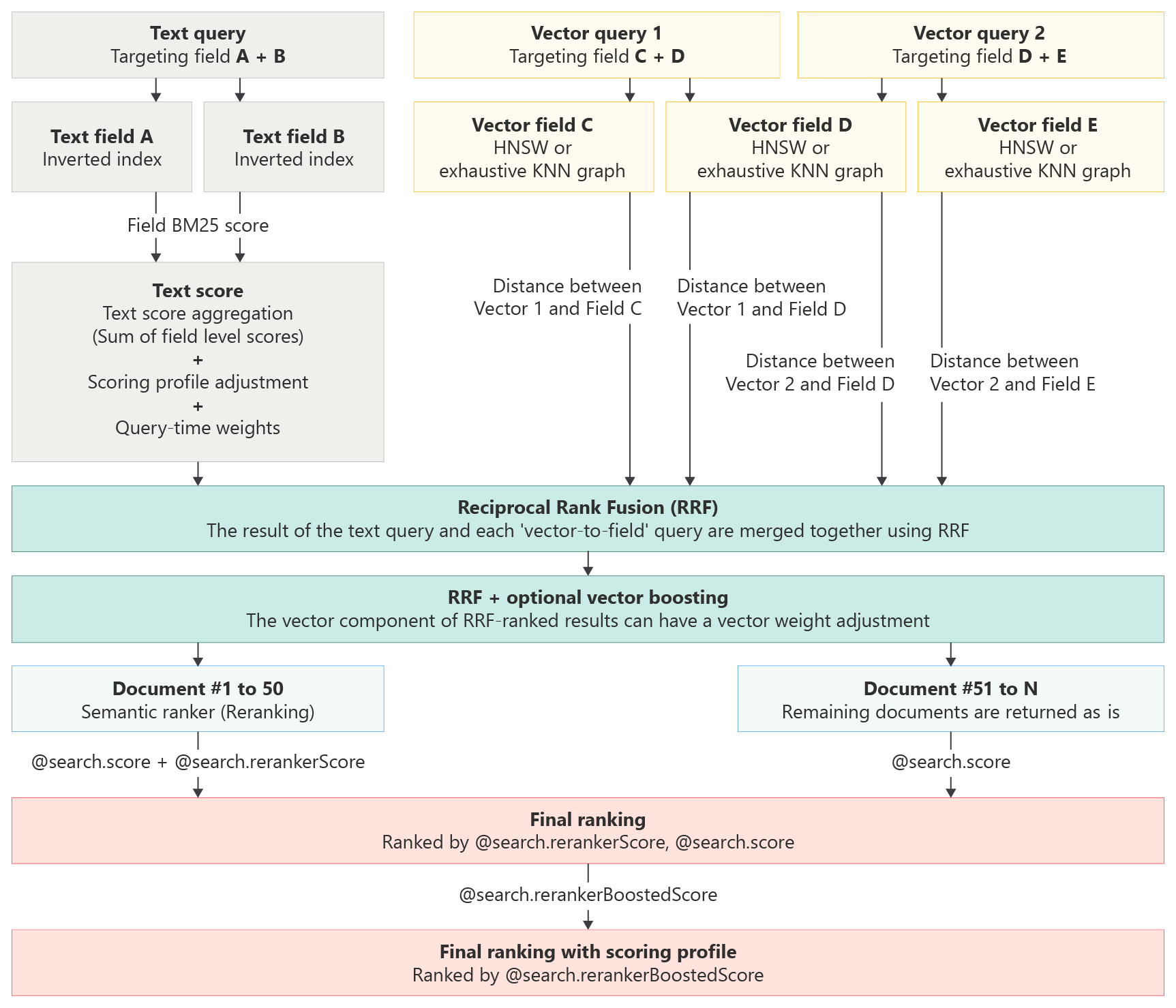
점수 매기기 프로필에 의미 체계 순위 매기기를 사용할 수 있습니다. 여러 순위 또는 관련성 기능이 실행 중인 경우 의미 체계 순위가 마지막 단계입니다. 검색 점수 매기기 작동 방식은 그림을 제공합니다.
참고 항목
관련성 개념에 익숙하지 않으신가요? 배경 정보를 보려면 Azure AI 검색의 관련성 및 채점을 방문하세요. 또한 이 YouTube의 비디오 세그먼트에서 BM25 순위 결과를 통한 점수 매기기 프로필에 대해 살펴볼 수도 있습니다.
점수 매기기 프로필 정의
점수 매기기 프로필은 인덱스 스키마에 정의된 개체로 명명됩니다. 점수 매기기 프로필은 가중 필드, 함수 및 매개 변수로 구성되어 있습니다.
다음 정의는 "geo"라는 간단한 프로필을 보여 줍니다. 이 예제는 hotelName 필드에 검색 용어가 포함된 결과를 부스트합니다. 또한 distance 함수를 사용하여 현재 위치에서 10km 이내에 있는 결과의 점수를 높입니다. ‘inn’이라는 용어를 검색하는 경우 ‘inn’이 호텔 이름의 일부분이라면 현재 위치의 10KM 반경 내에서 이름에 ‘inn’이 포함된 호텔을 포함하는 문서가 검색 결과에서 더 높은 순위로 표시됩니다.
"scoringProfiles": [
{
"name":"geo",
"text": {
"weights": {
"hotelName": 5
}
},
"functions": [
{
"type": "distance",
"boost": 5,
"fieldName": "location",
"interpolation": "logarithmic",
"distance": {
"referencePointParameter": "currentLocation",
"boostingDistance": 10
}
}
]
}
]
이 점수 매기기 프로필을 사용하려면 쿼리를 작성하여 요청에 매개 변수를 지정 scoringProfile 합니다. REST API를 사용하는 경우 쿼리는 GET 및 POST 요청을 통해 지정됩니다. 다음 예제에서 "currentLocation"에는 단일 대시(-) 구분 기호가 있습니다. 그 다음에는 경도와 위도 좌표가 옵니다. 여기서 경도는 음수 값입니다.
POST /indexes/hotels/docs&api-version=2024-07-01
{
"search": "inn",
"scoringProfile": "geo",
"scoringParameters": ["currentLocation--122.123,44.77233"]
}
이 쿼리는 용어 "inn"을 검색하고 현재 위치를 전달합니다. 이 쿼리에는 scoringParameter 같은 다른 매개 변수도 포함되어 있습니다. "scoringParameter"를 포함한 쿼리 매개 변수는 문서 검색(REST API)에 설명되어 있습니다.
더 많은 시나리오를 보려면 벡터 및 하이브리드 검색용으로 확장된 예제 및 키워드 검색용으로 확장된 예제를 참조하세요.
Azure AI 검색에서 검색 점수 매기기가 작동하는 방식
점수 매기기 프로필은 프로필의 조건을 충족하는 일치 항목의 점수를 높여 기본 점수 매기기 알고리즘을 보완합니다. 점수 매기기 함수는 다음 사항에 적용됩니다.
- 텍스트(키워드) 검색
- 순수 벡터 쿼리
- 텍스트 및 벡터 하위 쿼리가 있는 하이브리드 쿼리는 병렬로 실행됩니다.
독립 실행형 텍스트 쿼리의 경우 점수 매기기 프로필은 BM25 순위 검색에서 최대 1,000개의 일치 항목을 식별하고 상위 50개 항목이 결과에 반환됩니다.
순수 벡터의 경우 쿼리는 벡터 전용이지만 k 일치 문서에 사람이 읽을 수 있는 콘텐츠가 있는 비벡터 필드가 포함된 경우 점수 매기기 프로필을 적용할 수 있습니다. 점수 매기기 프로필은 프로필의 기준과 일치하는 문서를 승격하여 결과 집합을 수정합니다.
하이브리드 쿼리의 텍스트 쿼리의 경우 점수 매기기 프로필은 BM25 순위 검색에서 최대 1,000개의 일치 항목을 식별합니다. 그러나 이러한 1,000개의 결과가 식별되면 원래 BM25 순서로 복원되므로 벡터와 함께 다시 점수 매기기할 수 있도록 최종 RRF(상호 순위 함수) 순서가 지정됩니다. 여기서 점수 매기기 프로필(그림에서 "최종 문서 승격 조정"으로 식별됨)은 마지막 단계로 벡터 가중치 및 의미 체계 순위와 함께 병합된 결과에 적용됩니다.
검색 인덱스에 점수 매기기 프로필 추가
인덱스 정의부터 시작합니다. 인덱스를 다시 작성하지 않고 기존 인덱스에서 점수 매기기 프로필을 추가하고 업데이트할 수 있습니다. 인덱스 만들기 또는 업데이트 요청을 사용하여 수정 버전을 게시합니다.
이 문서에 제공된 템플릿에 붙여넣습니다.
Azure AI Search 명명 규칙을 준수하는 이름을 제공합니다.
특정 프로필의 효율성을 증명하거나 반증하는 데 도움이 되는 데이터 세트를 사용하여 반복적으로 작업해야 합니다.
점수 매기기 프로필은 다음 스크린샷과 같이 Azure Portal에서 정의할 수도 있고, REST API 또는 Azure SDK(예: .NET용 Azure SDK의 ScoringProfile 클래스)를 통해 프로그래밍 방식으로 정의할 수도 있습니다.

텍스트 가중 필드 사용
필드 컨텍스트가 중요하고 쿼리에 searchable 문자열 필드가 포함되어 있는 경우 텍스트 가중 필드를 사용합니다. 예를 들어 쿼리에 "airport"라는 용어가 포함된 경우 HotelName 필드보다 설명 필드의 "airport"에 더 많은 가중치를 부여하려 할 것입니다.
가중 필드는 searchable 필드와 승수로 사용되는 양수로 구성된 이름-값 쌍입니다. HotelName의 원래 필드 점수가 3이면 이 필드의 상승된 점수는 6이 되어 부모 문서 자체의 전체적인 점수가 높아집니다.
"scoringProfiles": [
{
"name": "boostSearchTerms",
"text": {
"weights": {
"HotelName": 2,
"Description": 5
}
}
}
]
함수 사용
숫자 데이터로 계산되는 거리 및 최신 여부의 사례처럼 단순 상대 가중치로는 충분하지 않거나 단순 상대 가중치가 적용되지 않는 경우에는 함수를 사용합니다. 점수 매기기 프로필마다 여러 함수를 지정할 수 있습니다. Azure AI 검색에 사용되는 EDM 데이터 형식에 대한 자세한 내용은 지원되는 데이터 형식을 참조하세요.
| 함수 | 설명 | 사용 사례 |
|---|---|---|
| 거리 | 근접도 또는 지리적 위치를 기준으로 점수를 높입니다. 이 함수는 Edm.GeographyPoint 필드에만 사용할 수 있습니다. |
"내 근처 찾기" 시나리오에 사용합니다. |
| 신선도 | 날짜/시간 필드(Edm.DateTimeOffset)의 값만큼 점수를 높입니다.
boostingDuration을 설정하여 점수 상승이 발생하는 기간을 나타내는 값을 지정합니다. |
최신 또는 이전 날짜를 기준으로 점수를 높이려는 경우에 사용합니다. 현재 날짜에 더 가까운 항목이 더 먼 미래의 항목보다 높은 순위가 지정되도록 미래 날짜의 일정 이벤트 같은 항목에 순위를 지정합니다. 범위의 한쪽 끝이 현재 시간으로 고정됩니다. 과거의 시간 범위에 더 높은 점수를 주려면 양수 boostingDuration을 사용합니다. 미래의 시간 범위에 더 높은 점수를 주려면 음수 boostingDuration을 사용합니다. |
| 규모 | 숫자 필드의 값 범위를 기준으로 순위 지정을 변경합니다. 이 값은 정수이거나 부동 소수점 숫자여야 합니다. 별 등급 1~4에서 시작 값은 1이고 50%를 초과하는 이익의 경우에는 시작 값이 50입니다. 이 함수는 Edm.Double 및 Edm.Int 필드에만 사용할 수 있습니다. magnitude 함수의 경우 반전 패턴을 사용하려면(예: 비싼 품목보다 저렴한 품목의 점수를 높이기 위해) 범위를 높은 값에서 낮은 값 순서로 반전할 수 있습니다. 가격 범위가 $100에서 $1 사이인 경우 100에서 boostingRangeStart을(를) 설정하고 1에서 boostingRangeEnd을(를) 설정하여 낮은 가격의 항목을 상승시킬 수 있습니다. |
이익률, 등급, 클릭 수, 최고 가격, 최저 가격 또는 다운로드 수로 점수를 높이려는 경우에 사용합니다. 관련 항목이 두 개이면 등급이 높은 항목이 먼저 표시됩니다. |
| 태그 | 검색 문서와 쿼리 문자열에 공통적으로 적용된 태그를 기준으로 점수를 높입니다. 태그는 tagsParameter에 제공됩니다. 이 함수는 Edm.String 및 Collection(Edm.String) 형식의 검색 필드에만 사용할 수 있습니다. |
태그 필드가 있는 경우에 사용합니다. 목록 내의 지정된 태그 자체가 쉼표로 구분된 목록인 경우 필드의 텍스트 정규화기를 사용하여 쿼리 시 쉼표를 제거할 수 있습니다(공백에 쉼표 문자 매핑). 이 방식은 모든 용어가 쉼표로 구분된 긴 단일 용어 문자열이 되도록 목록을 "평면화"합니다. |
함수 사용 규칙
- 함수는
filterable로 특성이 지정된 필드에만 적용할 수 있습니다. - 함수 형식("freshness", "magnitude", "distance", "tag")은 소문자여야 합니다.
- 함수는 null 또는 빈 값을 포함할 수 없습니다.
- 함수에는 함수 정의당 필드가 하나만 있을 수 있습니다. 같은 프로필에서 magnitude를 두 번 사용하려면 각 필드에 하나씩 두 개의 magnitude 정의를 제공합니다.
템플릿
이 섹션에서는 점수 매기기 프로필의 구문과 템플릿에 대해 설명합니다. 속성에 대한 설명은 REST API 참조를 참조하세요.
"scoringProfiles": [
{
"name": "name of scoring profile",
"text": (optional, only applies to searchable fields) {
"weights": {
"searchable_field_name": relative_weight_value (positive #'s),
...
}
},
"functions": (optional) [
{
"type": "magnitude | freshness | distance | tag",
"boost": # (positive number used as multiplier for raw score != 1),
"fieldName": "(...)",
"interpolation": "constant | linear (default) | quadratic | logarithmic",
"magnitude": {
"boostingRangeStart": #,
"boostingRangeEnd": #,
"constantBoostBeyondRange": true | false (default)
}
// ( - or -)
"freshness": {
"boostingDuration": "..." (value representing timespan over which boosting occurs)
}
// ( - or -)
"distance": {
"referencePointParameter": "...", (parameter to be passed in queries to use as reference location)
"boostingDistance": # (the distance in kilometers from the reference location where the boosting range ends)
}
// ( - or -)
"tag": {
"tagsParameter": "..."(parameter to be passed in queries to specify a list of tags to compare against target field)
}
}
],
"functionAggregation": (optional, applies only when functions are specified) "sum (default) | average | minimum | maximum | firstMatching"
}
],
"defaultScoringProfile": (optional) "...",
보간 설정
보간을 사용하면 점수 매기기에 사용되는 기울기의 모양을 설정할 수 있습니다. 채점은 높음에서 낮음으로 진행되기 때문에 기울기가 항상 감소하지만, 보간을 통해 하향 기울기의 곡선이 결정됩니다. 다음과 같은 보간을 사용할 수 있습니다.
| 보간 | 설명 |
|---|---|
linear |
최댓값 및 최솟값 범위 내 항목의 경우 점수 상승은 지속적으로 감소하는 양으로 적용됩니다. Linear는 점수 매기기 프로필의 기본 보간입니다. |
constant |
시작 및 끝 범위 내 항목의 경우 일정한 점수 상승이 순위 결과에 적용됩니다. |
quadratic |
점수 상승 값이 일정하게 감소하는 선형 보간과는 달리 2차 보간에서는 처음에 값이 조금씩 감소했다가 끝 범위가 가까워지면 값이 훨씬 큰 간격으로 감소합니다. 이 보간 옵션은 tag 점수 매기기 함수에서 허용되지 않습니다. |
logarithmic |
점수 상승 값이 일정하게 감소하는 선형 보간과는 달리 로그 보간에서는 처음에 값이 크게 감소했다가 끝 범위가 가까워질수록 값이 훨씬 작은 간격으로 감소합니다. 이 보간 옵션은 tag 점수 매기기 함수에서 허용되지 않습니다. |

freshness 함수에 대한 boostingDuration 설정
boostingDuration은 freshness 함수의 특성입니다. 이 특성을 사용하여 특정 문서에 대해 상승이 중지되는 만료 기간을 설정합니다. 예를 들어 프로모션 기간 10일 동안 특정 제품 라인이나 브랜드를 상승시키려는 경우 해당 문서에 대해 10일의 기간을 "P10D"로 지정합니다.
boostingDuration 의 형식은 XSD "dayTimeDuration" 값(ISO 8601 기간 값의 제한된 하위 집합)으로 지정해야 합니다. 이 형식의 패턴은 "P[nD][T[nH][nM][nS]]"입니다.
다음 테이블에 여러 예제가 나와 있습니다.
| 기간 | 부스팅 지속시간 |
|---|---|
| 하루 | "P1D" |
| 2일 12시간 | "P2DT12H" |
| 15분 | "PT15M" |
| 30일, 5시간, 10분, 6.334초 | "P30DT5H10M6.334S" |
더 많은 예제를 보려면 XML 스키마: Datatypes(W3.org 웹 사이트)를 참조하세요.
벡터 및 하이브리드 검색용으로 확장된 예제
벡터 및 생성형 AI 시나리오에서 점수 매기기 프로필 및 문서 부스팅을 사용하는 데모는 이 블로그 게시물 및 Notebook을 참조하세요.
키워드 검색용으로 확장된 예제
아래 예제에서는 2개의 점수 매기기 프로필 boostGenre 및 newAndHighlyRated가 있는 인덱스의 스키마를 보여줍니다. 쿼리 매개 변수로 두 프로필 중 하나를 포함하는 쿼리를 이 인덱스에 대해 실행하는 경우 해당 프로필을 사용하여 결과 집합의 점수를 계산합니다.
boostGenre 프로필은 가중치 텍스트 필드를 사용하여 albumTitle, genre 및 artistName 필드에서 검색된 일치 항목의 점수를 높입니다. 이러한 필드의 점수는 각각 1.5, 5, 2가 높아집니다. genre가 다른 필드보다 훨씬 크게 상승하는 이유는, musicstoreindex에서 '장르'의 경우와 같이 다소 동질적인 데이터에 대해 검색을 수행하는 경우 상대적 가중치에 더 큰 분산이 필요할 수 있습니다. 예를 들어 musicstoreindex에서 ‘rock’은 장르로도 표시되고 같은 구를 사용하는 장르 설명에도 표시됩니다. 이 경우 장르 설명보다 장르에 더 높은 가중치를 적용하려면 genre 필드에 훨씬 높은 상대 가중치를 적용해야 합니다.
{
"name": "musicstoreindex",
"fields": [
{ "name": "key", "type": "Edm.String", "key": true },
{ "name": "albumTitle", "type": "Edm.String" },
{ "name": "albumUrl", "type": "Edm.String", "filterable": false },
{ "name": "genre", "type": "Edm.String" },
{ "name": "genreDescription", "type": "Edm.String", "filterable": false },
{ "name": "artistName", "type": "Edm.String" },
{ "name": "orderableOnline", "type": "Edm.Boolean" },
{ "name": "rating", "type": "Edm.Int32" },
{ "name": "tags", "type": "Collection(Edm.String)" },
{ "name": "price", "type": "Edm.Double", "filterable": false },
{ "name": "margin", "type": "Edm.Int32", "retrievable": false },
{ "name": "inventory", "type": "Edm.Int32" },
{ "name": "lastUpdated", "type": "Edm.DateTimeOffset" }
],
"scoringProfiles": [
{
"name": "boostGenre",
"text": {
"weights": {
"albumTitle": 1.5,
"genre": 5,
"artistName": 2
}
}
},
{
"name": "newAndHighlyRated",
"functions": [
{
"type": "freshness",
"fieldName": "lastUpdated",
"boost": 10,
"interpolation": "quadratic",
"freshness": {
"boostingDuration": "P365D"
}
},
{
"type": "magnitude",
"fieldName": "rating",
"boost": 10,
"interpolation": "linear",
"magnitude": {
"boostingRangeStart": 1,
"boostingRangeEnd": 5,
"constantBoostBeyondRange": false
}
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [ "albumTitle", "artistName" ]
}
]
}