검색 문서에 문자열 필드가 있고 검색 문서의 벡터 쿼리에 텍스트 표현이 있는 경우 텍스트 쿼리, 하이브리드 쿼리, 벡터 쿼리에 의미 체계 순위 지정을 적용할 수 있습니다.
이 문서에서는 쿼리에서 의미 순위매기기기를 호출하는 방법을 설명합니다. 가장 최근의 안정 또는 미리 보기 API를 사용 중이라고 가정합니다. 이전 버전에 대한 도움말은 의미 체계 순위 코드 마이그레이션을 참조 하세요.
필수 조건
의미 순위매기기가 사용하도록 설정된 기본 계층 이상의 검색 서비스입니다.
의미 체계 구성 및 서식 있는 텍스트 콘텐츠가 있는 기존 검색 인덱스.
기능에 대한 소개가 필요한 경우 의미 체계 순위를 검토합니다.
참고
캡션과 답변은 검색 문서의 텍스트에서 그대로 추출됩니다. 의미 체계 하위 시스템은 컴퓨터 읽기 이해력을 사용하여 캡션 또는 답변의 특징이 있는 콘텐츠를 인식하지만 쿼리 다시 쓰기의 경우를 제외하고는 새 문장이나 구를 작성하지 않습니다. 이러한 이유로 설명이나 정의가 포함된 내용은 의미 체계 순위에 가장 잘 맞습니다. 생성된 응답과 채팅 스타일 상호 작용을 하려면 RAG(검색 증강 세대)를 참조하세요.
클라이언트 선택
다음 도구 및 SDK 중 하나를 사용하여 의미 체계 순위 지정을 사용하는 쿼리를 작성할 수 있습니다.
- Azure Portal: 인덱스 디자이너를 사용하여 의미 체계 구성을 추가합니다.
- Visual Studio Code와 REST 클라이언트
- .NET용 Azure SDK
- Python용 Azure SDK
- Java용 Azure SDK
- JavaScript용 Azure SDK
관련성 점수를 우회하는 기능 방지
일부 쿼리 기능은 관련성 평가를 바이패스하므로 의미 체계 순위 지정과 호환되지 않습니다. 쿼리 논리에 다음 기능이 포함된 경우 결과 순위를 의미상으로 지정할 수 없습니다.
search=*가 포함된 쿼리나 비어 있는 쿼리 문자열(예: 순수 필터 전용 쿼리)은 의미 체계적 관련성을 측정할 기준이 없으므로 작동하지 않으며, 따라서 검색 점수가 0이 됩니다. 쿼리는 처리 중에 평가할 수 있고 관련성에 대한 점수가 매겨진 검색 문서를 생성하는 용어 또는 구를 제공해야 합니다. 점수가 매겨진 결과는 의미 체계 순위에 대한 입력입니다.특정 필드에 대한 정렬(orderBy 절)은 검색 점수 및 의미 체계 점수를 재정의합니다. 의미 점수가 순위를 제공한다고 가정하에 orderby 절을 추가하면, 순서가 지정된 결과에서 의미 순위를 적용할 경우 HTTP 400 오류가 발생합니다.
쿼리 설정
기본적으로 쿼리는 의미 체계 순위를 사용하지 않습니다. 의미 체계 순위를 사용하려면 두 개의 서로 다른 매개 변수를 사용할 수 있습니다. 각 매개 변수는 다른 시나리오 집합을 지원합니다.
search와 queryType를 사용하거나 semanticQuery를 통해 지정된 쿼리는 일반 텍스트여야 하며, 비워 둘 수 없습니다. 빈 쿼리로 인해 의미 체계 순위가 결과에 적용되지 않습니다.
| 의미 체계 순위 매개 변수 | 일반 텍스트 검색 | 단순 텍스트 검색 구문 | 전체 텍스트 검색 구문 | 벡터 검색 | 하이브리드 검색 | 의미론적 답변 및 설명 |
|---|---|---|---|---|---|---|
queryType-semantic
1 |
✅ | ❌ | ❌ | ❌ | ✅ | ✅ |
semanticQuery="<your plain text query>"
2 |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
1queryType=semantic은 명시적 simple 또는 full 값을 지원할 수 없습니다. queryType 매개 변수가 semantic에 사용되고 있기 때문입니다. 유효 쿼리 동작은 단순 파서의 기본값입니다.
2 매개 변수는 semanticQuery 모든 쿼리 형식에 사용할 수 있습니다. 그러나 Azure Portal 검색 탐색기에서는 지원되지 않습니다.
선택한 매개 변수에 관계없이 인덱스에는 풍부한 의미 체계 콘텐츠와 의미 체계 구성이 있는 텍스트 필드가 포함되어야 합니다.
검색 탐색기에는 의미 체계 순위에 대한 옵션이 포함되어 있습니다. Azure Portal에서는 매개 변수를 semanticQuery 설정할 수 없습니다.
Azure Portal에 로그인합니다.
검색 인덱스 열기 및 검색 탐색기를 선택합니다.
쿼리 옵션을 선택합니다. 의미 체계 구성을 이미 정의한 경우 기본적으로 선택됩니다. 인덱스가 없는 경우 인덱스의 의미 체계 구성을 만듭니다.
"좋은 음식이 있는 역사적인 호텔"과 같은 쿼리를 입력하고 검색을 선택합니다.
또는 JSON 보기를 선택하고 쿼리 편집기에 정의를 붙여넣습니다. Azure Portal은
semanticQuery사용을 지원하지 않으므로queryType을"semantic"으로 설정해야 합니다.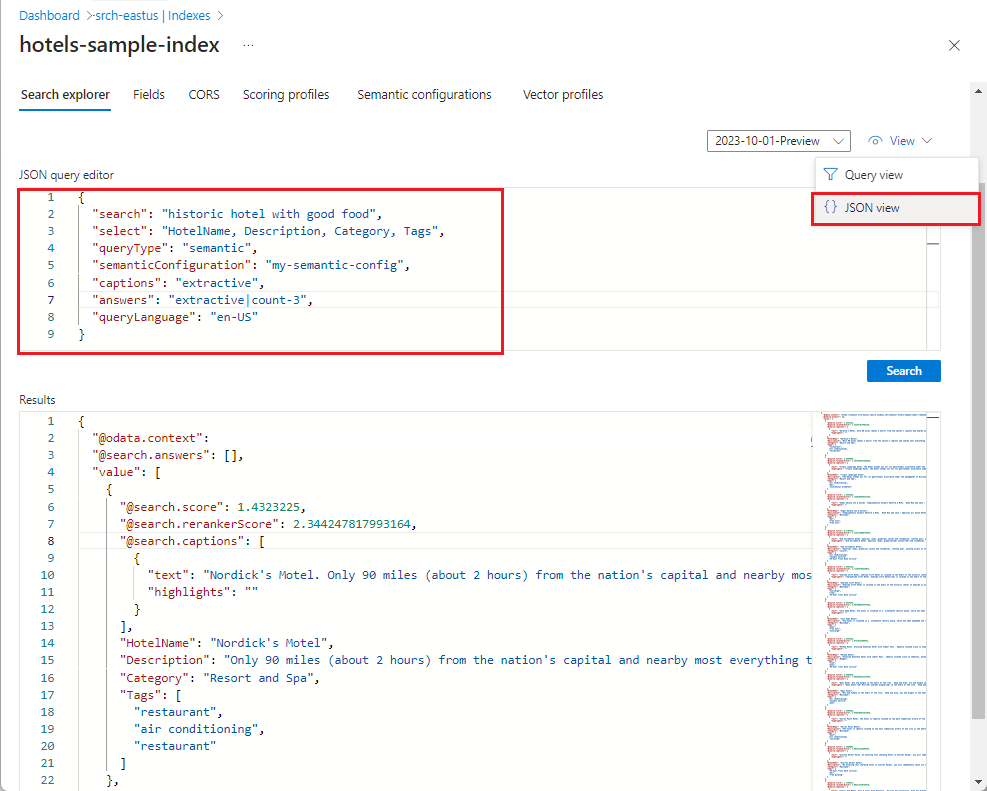
쿼리 형식을 뷰에 붙여넣을 수 있는 의미 체계로 설정하는 JSON 예제:
{ "search": "funky or interesting hotel with good food on site", "count": true, "queryType": "semantic", "semanticConfiguration": "my-semantic-config", "captions": "extractive|highlight-true", "answers": "extractive|count-3", "highlightPreTag": "<strong>", "highlightPostTag": "</strong>", "select": "HotelId,HotelName,Description,Category" }
응답 평가
초기 결과의 상위 50개 일치 항목만 의미 체계 순위를 지정할 수 있습니다. 모든 쿼리와 마찬가지로 응답은 검색 가능으로 표시된 모든 필드 또는 select 매개 변수에 나열된 필드로 구성됩니다. 응답에는 원본 관련성 점수 및 요청을 작성한 방법에 따라 개수 또는 일괄 처리된 결과가 포함될 수 있습니다.
의미 체계 순위에서 응답에는 새로운 의미 체계 순위 관련성 점수, 선택 사항인 일반 텍스트 캡션 및 강조 표시, 선택 사항인 답변과 같은 더 많은 요소가 있습니다. 결과에 이러한 추가 요소가 포함되지 않은 경우 쿼리가 잘못 구성되었을 수 있습니다. 문제 해결을 위한 첫 번째 단계로 의미 체계 구성을 확인하여 인덱스 정의와 쿼리 모두에 지정되었는지 확인합니다.
클라이언트 앱에서는 특정 필드의 전체 내용이 아니라 일치 항목에 대한 설명으로 캡션을 포함하도록 검색 페이지를 구성할 수 있습니다. 이 접근 방식은 검색 결과 페이지의 개별 필드가 너무 조밀한 경우 유용합니다.
위의 예제 쿼리에 대한 응답("구내에 레스토랑이 있고 아늑한 로비 또는 공유 구역이 있는 흥미로운 호텔")은 세 가지 답변("answers": "extractive|count-e")을 반환합니다. "captions" 속성이 일반 텍스트 및 강조 표시된 버전으로 설정되었으므로 캡션이 반환됩니다. 답변을 확인할 수 없는 경우 응답에서 생략됩니다. 간단히 하기 위해 이 예제에서는 쿼리에서 세 가지 답변과 세 가지 가장 높은 점수 매기기 결과를 보여 줍니다.
{
"@odata.count": 29,
"@search.answers": [
{
"key": "24",
"text": "Chic hotel near the city. High-rise hotel in downtown, within walking distance to theaters, art galleries, restaurants and shops. Visit Seattle Art Museum by day, and then head over to Benaroya Hall to catch the evening's concert performance.",
"highlights": "Chic hotel near the city. <strong>High-rise hotel in downtown, </strong>within<strong> walking distance to </strong>theaters, art<strong> galleries, restaurants and shops.</strong> Visit Seattle Art Museum by day, and then head over to Benaroya Hall to catch the evening's concert performance.",
"score": 0.9340000152587891
},
{
"key": "40",
"text": "Only 8 miles from Downtown. On-site bar/restaurant, Free hot breakfast buffet, Free wireless internet, All non-smoking hotel. Only 15 miles from airport.",
"highlights": "Only 8 miles from Downtown. <strong>On-site bar/restaurant, Free hot breakfast buffet, Free wireless internet, </strong>All non-smoking<strong> hotel.</strong> Only 15 miles from airport.",
"score": 0.9210000038146973
},
{
"key": "38",
"text": "Nature is Home on the beach. Explore the shore by day, and then come home to our shared living space to relax around a stone fireplace, sip something warm, and explore the library by night. Save up to 30 percent. Valid Now through the end of the year. Restrictions and blackouts may apply.",
"highlights": "Nature is Home on the beach. Explore the shore by day, and then come home to our<strong> shared living space </strong>to relax around a stone fireplace, sip something warm, and explore the library by night. Save up to 30 percent. Valid Now through the end of the year. Restrictions and blackouts may apply.",
"score": 0.9200000166893005
}
],
"value": [
{
"@search.score": 3.2328331,
"@search.rerankerScore": 2.575303316116333,
"@search.captions": [
{
"text": "The best of old town hospitality combined with views of the river and cool breezes off the prairie. Our penthouse suites offer views for miles and the rooftop plaza is open to all guests from sunset to 10 p.m. Enjoy a complimentary continental breakfast in the lobby, and free Wi-Fi throughout the hotel.",
"highlights": "The best of old town hospitality combined with views of the river and cool breezes off the prairie. Our<strong> penthouse </strong>suites offer views for miles and the rooftop<strong> plaza </strong>is open to all guests from sunset to 10 p.m. Enjoy a<strong> complimentary continental breakfast in the lobby, </strong>and free Wi-Fi<strong> throughout </strong>the hotel."
}
],
"HotelId": "50",
"HotelName": "Head Wind Resort",
"Description": "The best of old town hospitality combined with views of the river and cool breezes off the prairie. Our penthouse suites offer views for miles and the rooftop plaza is open to all guests from sunset to 10 p.m. Enjoy a complimentary continental breakfast in the lobby, and free Wi-Fi throughout the hotel.",
"Category": "Suite"
},
{
"@search.score": 0.632956,
"@search.rerankerScore": 2.5425150394439697,
"@search.captions": [
{
"text": "Every stay starts with a warm cookie. Amenities like the Counting Sheep sleep experience, our Wake-up glorious breakfast buffet and spacious workout facilities await.",
"highlights": "Every stay starts with a warm cookie. Amenities like the<strong> Counting Sheep sleep experience, </strong>our<strong> Wake-up glorious breakfast buffet and spacious workout facilities </strong>await."
}
],
"HotelId": "34",
"HotelName": "Lakefront Captain Inn",
"Description": "Every stay starts with a warm cookie. Amenities like the Counting Sheep sleep experience, our Wake-up glorious breakfast buffet and spacious workout facilities await.",
"Category": "Budget"
},
{
"@search.score": 3.7076726,
"@search.rerankerScore": 2.4554927349090576,
"@search.captions": [
{
"text": "Chic hotel near the city. High-rise hotel in downtown, within walking distance to theaters, art galleries, restaurants and shops. Visit Seattle Art Museum by day, and then head over to Benaroya Hall to catch the evening's concert performance.",
"highlights": "Chic hotel near the city. <strong>High-rise hotel in downtown, </strong>within<strong> walking distance to </strong>theaters, art<strong> galleries, restaurants and shops.</strong> Visit Seattle Art Museum by day, and then head over to Benaroya Hall to catch the evening's concert performance."
}
],
"HotelId": "24",
"HotelName": "Uptown Chic Hotel",
"Description": "Chic hotel near the city. High-rise hotel in downtown, within walking distance to theaters, art galleries, restaurants and shops. Visit Seattle Art Museum by day, and then head over to Benaroya Hall to catch the evening's concert performance.",
"Category": "Suite"
},
. . .
]
}
예상 작업
의미 체계 순위 지정의 경우 검색 서비스는 복제본당 최대 10개의 동시 쿼리를 지원할 것으로 예상해야 합니다.
볼륨이 너무 높으면 서비스는 의미 체계 순위 지정 요청을 제한합니다. 다음 구가 포함된 오류 메시지는 서비스가 의미 체계 순위 지정을 지정할 수 있는 용량에 도달했음을 나타냅니다.
Error in search query: Operation returned an invalid status 'Partial Content'`
@search.semanticPartialResponseReason`
CapacityOverloaded
이 수준에 가깝거나 이상인 일관된 처리량 요구 사항이 예상되는 경우 워크로드를 프로비전할 수 있도록 지원 티켓을 제출하세요.
다음 단계
의미 체계 순위는 키워드 검색과 벡터 검색을 단일 요청 및 통합 응답으로 결합하는 하이브리드 쿼리에서 사용할 수 있습니다.