자습서: REST를 사용하여 Azure Storage에서 중첩된 JSON Blob 인덱싱
Azure AI 검색은 반정형 데이터를 읽는 방법을 아는 indexer를 사용하여 Azure Blob Storage의 JSON 문서와 어레이를 인덱싱할 수 있습니다. 반구조화된 데이터에는 데이터 내의 콘텐츠를 구분하는 태그 또는 표시가 포함되어 있습니다. 완전히 인덱싱되어야 하는 구조화되지 않은 데이터와 필드별로 인덱싱할 수 있는 관계형 데이터베이스 스키마와 같이 데이터 모델을 준수하는 공식적으로 구조화된 데이터 간의 차이를 분할합니다.
이 자습서에서는 중첩된 JSON 배열을 인덱싱하는 방법을 보여 줍니다. REST 클라이언트 및 Search REST API를 사용하여 다음 작업을 수행합니다.
- 샘플 데이터 설정 및
azureblob데이터 원본 구성 - 검색 가능한 콘텐츠를 포함하는 Azure AI 검색 인덱스 만들기
- 인덱서 만들기 및 실행하여 컨테이너를 읽고 검색 가능한 콘텐츠 추출
- 방금 만든 인덱스 검색
Azure 구독이 아직 없는 경우 시작하기 전에 체험 계정을 만듭니다.
필수 조건
참고 항목
이 자습서에서는 체험 서비스를 사용할 수 있습니다. 체험 검색 서비스에서는 인덱스, 인덱서 및 데이터 원본이 각각 3개로 제한됩니다. 이 자습서에서는 각각을 하나씩 만듭니다. 시작하기 전에 새 리소스를 수용할 수 있는 공간이 서비스에 있는지 확인하세요.
파일 다운로드
샘플 데이터 리포지토리의 zip 파일을 다운로드하고 콘텐츠를 추출합니다. 방법을 알아보세요.
샘플 데이터는 JSON 배열과 1,521개의 중첩된 JSON 요소를 포함하는 단일 JSON 파일입니다. 샘플 데이터는 Kaggle의 뉴욕 필하모닉 성능 기록에서 시작됩니다. 무료 계층의 스토리지 한도에 머물기 위해 JSON 파일 하나를 선택했습니다.
다음은 파일의 첫 번째 중첩된 JSON입니다. 파일의 나머지 부분에는 1,520개의 다른 콘서트 공연 인스턴스가 포함됩니다.
{
"id": "7358870b-65c8-43d5-ab56-514bde52db88-0.1",
"programID": "11640",
"orchestra": "New York Philharmonic",
"season": "2011-12",
"concerts": [
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-07T04:00:00Z",
"Time": "7:30PM"
},
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-08T04:00:00Z",
"Time": "7:30PM"
}
],
"works": [
{
"ID": "5733*",
"composerName": "Bernstein, Leonard",
"workTitle": "WEST SIDE STORY (WITH FILM)",
"conductorName": "Newman, David",
"soloists": []
},
{
"ID": "0*",
"interval": "Intermission",
"soloists": []
}
]
}
Azure Storage에 샘플 데이터 업로드
Azure Storage에서 새 컨테이너를 만들고 ny-philharmonic-free라고 이름을 붙입니다.
샘플 데이터 파일을 업로드합니다.
Azure AI 검색에서 연결을 공식화할 수 있도록 스토리지 연결 문자열을 가져옵니다.
왼쪽에서 액세스 키를 선택합니다.
키 1 또는 키 2의 연결 문자열을 복사합니다. 연결 문자열은 다음 예제와 유사합니다.
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
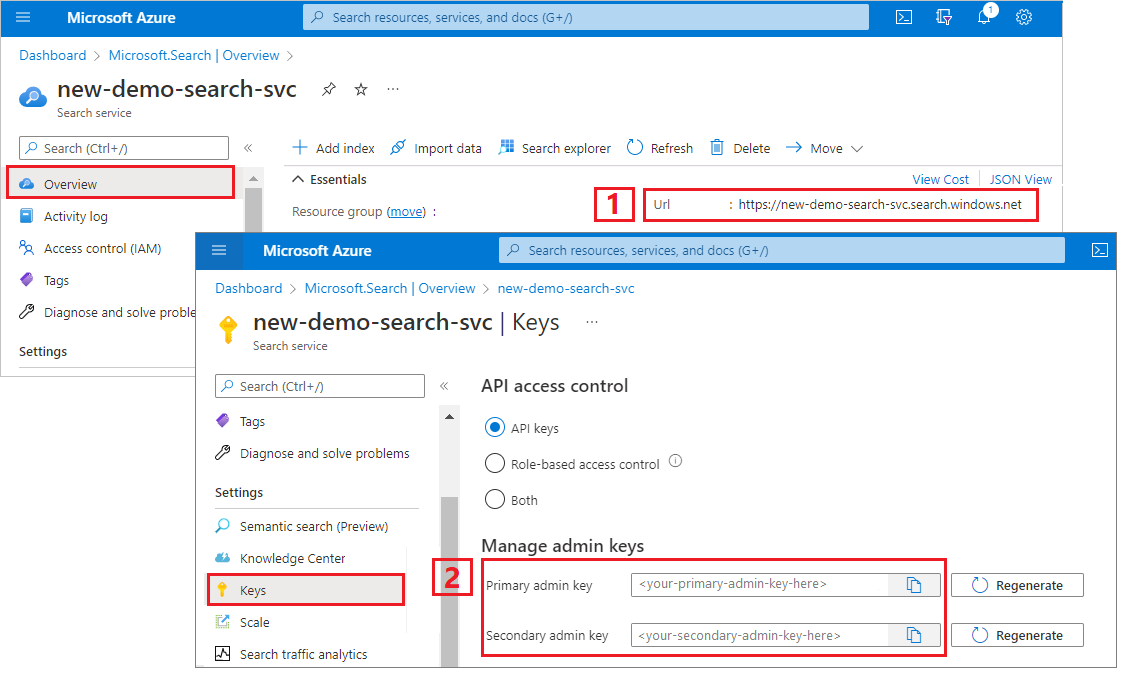
검색 서비스 URL 및 API 키 복사
이 자습서의 경우, Azure AI 검색에 연결하려면 엔드포인트와 API 키가 필요합니다. Azure Portal에서 이러한 값을 가져올 수 있습니다.
Azure Portal에 로그인하고 검색 서비스 개요 페이지로 이동한 다음, URL을 복사합니다. 엔드포인트의 예는 다음과 같습니다.
https://mydemo.search.windows.net설정>키에서 관리자 키를 복사합니다. 관리자 키는 개체를 추가, 수정, 삭제하는 데 사용됩니다. 교환 가능한 관리자 키는 2개입니다. 둘 중 하나를 복사합니다.
REST 파일 설정
Visual Studio Code 시작 및 새 파일 만들기
요청에 사용되는 변수에 대한 값을 제공합니다.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HERE.rest또는.http파일 확장자를 사용하여 파일을 저장합니다.
REST 클라이언트에 대한 도움이 필요한 경우 빠른 시작: REST를 사용하여 텍스트 검색을 참조하세요.
데이터 원본 만들기
REST(데이터 원본 만들기)에 인덱싱할 데이터를 지정하는 데이터 원본 연결을 만듭니다.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
요청을 보냅니다. 응답은 다음과 같아야 합니다.
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DC43A5FDB8448F"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('ny-philharmonic-ds')?api-version=2024-07-01
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 7ca53f73-1054-4959-bc1f-616148a9c74a
elapsed-time: 111
Date: Wed, 13 Mar 2024 21:38:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DC43A5FDB8448F\"",
"name": "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "ny-philharmonic-free",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null
}
인덱스 만들기
인덱스 만들기(REST) 검색 서비스에 검색 인덱스가 만들어집니다. 인덱스는 모든 매개 변수 및 해당 특성을 지정합니다.
중첩된 JSON의 경우 인덱스 필드는 원본 필드와 동일해야 합니다. 현재 Azure AI Search는 중첩된 JSON에 대한 필드 매핑을 지원하지 않습니다. 이러한 이유로 필드 이름 및 데이터 형식은 완전히 일치해야 합니다. 다음 인덱스는 원시 콘텐츠의 JSON 요소에 맞춥니다.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "ny-philharmonic-index",
"fields": [
{"name": "programID", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "orchestra", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "season", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{ "name": "concerts", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "eventType", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "Location", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Venue", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Date", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Time", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
},
{ "name": "works", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "ID", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "composerName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "workTitle", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "conductorName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "soloists", "type": "Collection(Edm.String)", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
}
]
}
주요 정보:
필드 매핑을 사용하여 필드 이름 또는 데이터 형식의 차이를 조정할 수 없습니다. 이 인덱스 스키마는 원시 콘텐츠를 미러링하도록 설계되었습니다.
중첩된 JSON은
Collection(Edm.ComplextType)(으)로 모델링됩니다. 원시 콘텐츠에는 매 시즌마다 여러 콘서트가 있으며 각 콘서트에 대한 여러 작품이 있습니다. 이 구조를 수용하려면 복합 형식에 컬렉션을 사용합니다.원시 콘텐츠에서
Date및Time문자열이므로 인덱스의 해당 데이터 형식도 문자열입니다.
인덱서 만들기 및 실행
인덱서 만들기 검색 서비스에 인덱서가 만들어집니다. 인덱서는 데이터 원본에 연결하고, 데이터를 로드 및 인덱싱하며, 선택적으로 데이터 새로 고침을 자동화하는 일정을 제공합니다.
인덱서 구성에는 jsonArray 구문 분석 모드 및 documentRoot이(가) 포함됩니다.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-indexer",
"dataSourceName" : "ny-philharmonic-ds",
"targetIndexName" : "ny-philharmonic-index",
"parameters" : {
"configuration" : {
"parsingMode" : "jsonArray", "documentRoot": "/programs"}
},
"fieldMappings" : [
]
}
주요 정보:
원시 콘텐츠 파일에는 1,526개의 중첩된 JSON 구조가 있는 JSON 배열(
"programs")이 포함됩니다.parsingMode을(를)jsonArray(으)로 설정하여 각 Blob에 JSON 배열이 포함되어 있음을 인덱서에 알릴 수 있습니다. 중첩된 JSON은 한 수준 아래로 시작하므로documentRoot을(를)/programs(으)로 설정합니다.인덱서는 몇 분 동안 실행됩니다. 쿼리를 실행하기 전에 인덱서 실행이 완료되기를 기다립니다.
쿼리 실행
첫 번째 문서를 로드하는 즉시 검색을 시작할 수 있습니다.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
요청을 보냅니다. 이것은 인덱스에 검색 가능으로 표시된 모든 필드를 문서 수와 함께 반환하는 지정되지 않은 전체 텍스트 검색 쿼리입니다. 응답은 다음과 같아야 합니다.
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a95c4021-f7b4-450b-ba55-596e59ecb6ec
elapsed-time: 106
Date: Wed, 13 Mar 2024 22:09:59 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('ny-philharmonic-index')/$metadata#docs(*)",
"@odata.count": 1521,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01"
}
문자열을 검색할 search 매개 변수를 추가합니다. select 매개 변수를 추가하여 결과를 더 적은 필드로 제한합니다. filter을(를) 추가하여 검색 범위를 더 좁힐 수 있습니다.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "puccini",
"count": true,
"select": "season, concerts/Date, works/composerName, works/workTitle",
"filter": "season gt '2015-16'"
}
응답에 두 개의 문서가 반환됩니다.
필터의 경우 논리 연산자(및, 그렇지 않음) 및 비교 연산자(eq, ne, gt, lt, ge, le)를 사용할 수도 있습니다. 문자열 비교는 대/소문자를 구분합니다. 자세한 내용 및 예제는 쿼리 만들기를 참조하세요.
참고 항목
$filter 매개 변수는 인덱스 생성 시 필터링 가능한 것으로 표시된 필드에서만 작동합니다.
다시 설정하고 다시 실행
인덱서를 다시 설정하여 실행 기록을 지울 수 있으므로 전체 다시 실행할 수 있습니다. 다음 GET 요청은 다시 설정한 다음 다시 실행합니다.
### Reset the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/reset?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/run?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/ny-philharmonic-indexer/status?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
리소스 정리
사용자 고유의 구독에서 작업하는 경우 프로젝트의 끝에서 더 이상 필요하지 않은 리소스를 제거하는 것이 좋습니다. 계속 실행되는 리소스에는 요금이 부과될 수 있습니다. 리소스를 개별적으로 삭제하거나 리소스 그룹을 삭제하여 전체 리소스 세트를 삭제할 수 있습니다.
포털을 사용하여 인덱스, 인덱서 및 데이터 원본을 삭제할 수 있습니다.
다음 단계
Azure Blob 인덱싱의 기본 사항을 익혔으면 Azure Storage의 JSON Blob에 대한 인덱서 구성에 대해 자세히 살펴보겠습니다.