Azure Stream Analytics 작업에서 UDF(사용자 정의 함수)로 기계 학습 모델을 구현하여 스트리밍 입력 데이터에 대한 실시간 채점 및 예측을 수행할 수 있습니다. Azure Machine Learning을 사용하면 TensorFlow, scikit, PyTorch 등의 인기 있는 오픈 소스 도구를 사용하여 모델을 준비, 학습 및 배포할 수 있습니다.
필수 조건
기계 학습 모델을 Stream Analytics 작업에 함수로 추가하기 전에 다음 단계를 완료합니다.
Azure Machine Learning을 사용하여 모델을 웹 서비스로 배포합니다.
기계 학습 엔드포인트에는 Stream Analytics가 입출력의 스키마를 이해할 수 있도록 하는 연결된 swagger가 있어야 합니다. 이 샘플 swagger 정의를 참조로 사용하여 올바르게 설정되었는지 확인할 수 있습니다.
웹 서비스가 JSON 직렬화된 데이터를 수락하고 반환하는지 확인합니다.
대규모 프로덕션 배포를 위한 모델을 Azure Kubernetes Service에 배포합니다. 웹 서비스가 작업에서 발생하는 요청 수를 처리할 수 없는 경우 Stream Analytics 작업의 성능이 저하되어 대기 시간에 영향을 줍니다. Azure Container Instances에 배포된 모델은 Azure Portal을 사용하는 경우에만 지원됩니다.
작업에 기계 학습 모델 추가
Azure Portal 또는 Visual Studio Code에서 직접 Stream Analytics 작업에 Azure Machine Learning 함수를 추가할 수 있습니다.
Azure Portal
Azure Portal의 Stream Analytics 작업으로 이동하고 작업 토폴로지에서 함수를 선택합니다. 그런 다음, +추가 드롭다운 메뉴에서 Azure Machine Learning Service를 선택합니다.
다음 속성 값을 사용하여 Azure Machine Learning Service 함수 양식을 채웁니다.
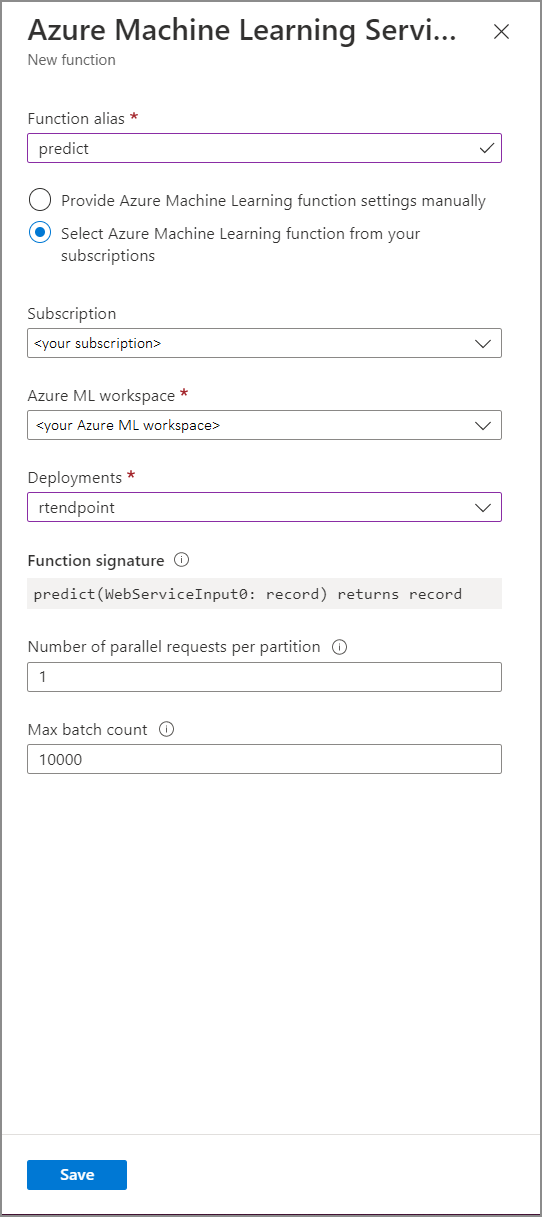
다음 표는 Stream Analytics에서 Azure Machine Learning Service 함수의 각 속성을 설명합니다.
| 속성 | 설명 |
|---|---|
| 함수 별칭 | 쿼리에서 함수를 호출할 이름을 입력합니다. |
| 구독 | Azure 구독. |
| Azure Machine Learning 작업 영역 | 모델을 웹 서비스로 배포하는 데 사용한 Azure Machine Learning 작업 영역입니다. |
| 엔드포인트 | 모델을 호스팅하는 웹 서비스입니다. |
| 함수 시그니처 | API의 스키마 사양에서 유추된 웹 서비스의 서명입니다. 서명을 로드하지 못하면 채점 스크립트에 샘플 입력 및 출력을 제공하여 스키마를 자동으로 생성했는지 확인합니다. |
| 파티션당 병렬 요청 수 | 이는 대규모의 처리량을 최적화하는 고급 구성입니다. 이 숫자는 작업의 각 파티션에서 웹 서비스로 전송되는 동시 요청을 나타냅니다. 6개 이하의 SU(스트리밍 단위)를 사용하는 작업에 하나의 파티션이 있습니다. 12개의 SU를 사용하는 작업에는 2개의 파티션이 있으며 18개의 SU 작업에는 3개의 파티션이 있습니다. 예를 들어 작업에 두 개의 파티션이 있고 이 매개 변수를 4로 설정하면 작업에서 웹 서비스로의 동시 요청이 8개가 됩니다. |
| 최대 일괄 처리 수 | 이는 대규모의 처리량을 최적화하기 위한 고급 구성입니다. 이 숫자는 웹 서비스로 전송되는 단일 요청에서 함께 일괄 처리되는 최대 이벤트 수를 나타냅니다. |
쿼리에서 기계 학습 엔드포인트 호출
Stream Analytics 쿼리가 Azure Machine Learning UDF를 호출하면 작업이 웹 서비스에 대한 JSON 직렬화된 요청을 만듭니다. 요청은 Stream Analytics가 엔드포인트의 swagger에서 유추하는 모델별 스키마를 기반으로 합니다.
경고
작업이 실행되고 있지 않으므로 Azure Portal 쿼리 편집기로 테스트할 때 Machine Learning 엔드포인트가 호출되지 않습니다. 포털에서 엔드포인트 호출을 테스트하려면 Stream Analytics 작업을 실행해야 합니다.
다음 Stream Analytics 쿼리는 Azure Machine Learning UDF를 호출하는 방법의 예입니다.
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
ML UDF로 전송된 입력 데이터가 예상되는 스키마와 일치하지 않는 경우 엔드포인트는 오류 코드 400이 포함된 응답을 반환하므로 Stream Analytics 작업이 실패 상태가 됩니다. 이러한 문제를 쉽게 디버그하고 해결할 수 있도록 작업에 대해 리소스 로그를 사용하도록 설정하는 것이 좋습니다. 따라서 다음을 수행하는 것이 좋습니다.
- ML UDF의 입력이 null이 아닌지 확인하십시오.
- 엔드포인트가 기대하는 것과 일치하는지 유효성 검사하기 위해 ML UDF에 대한 입력인 모든 필드의 형식의 유효성을 검사합니다.
참고 사항
ML UDF는 조건식(예: CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END)을 통해 호출되는 경우에도 지정된 쿼리 단계의 각 행에 대해 평가됩니다. 필요한 경우 WITH 절을 사용하여 분기 경로를 만들고 UNION을 사용하여 경로를 다시 병합하기 전에 필요한 경우에만 ML UDF를 호출합니다.
여러 입력 매개 변수를 UDF에 전달
기계 학습 모델에 대한 입력의 가장 일반적인 예는 numpy 배열과 데이터 프레임입니다. JavaScript UDF를 사용하여 배열을 만들고 WITH 절을 사용하여 JSON 직렬화된 데이터 프레임을 만들 수 있습니다.
입력 배열 만들기
N개의 입력 수를 허용하고 Azure Machine Learning UDF에 대한 입력으로 사용할 수 있는 배열을 만드는 JavaScript UDF를 만들 수 있습니다.
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
작업에 JavaScript UDF를 추가한 후에는 다음 쿼리를 사용하여 Azure Machine Learning UDF를 호출할 수 있습니다.
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
다음 JSON은 요청 예입니다.
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
Pandas 또는 PySpark 데이터 프레임 만들기
WITH 절을 사용하여 아래와 같이 Azure Machine Learning UDF에 대한 입력으로 전달될 수 있는 JSON 직렬화된 데이터 프레임을 만들 수 있습니다.
다음 쿼리는 필요한 필드를 선택하여 데이터 프레임을 만들고 Azure Machine Learning UDF에 대한 입력으로 데이터 프레임을 사용합니다.
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
다음 JSON은 이전 쿼리의 요청 예입니다.
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
Azure Machine Learning UDF의 성능 최적화
모델을 Azure Kubernetes Service에 배포하는 경우 모델을 프로파일링하여 리소스 사용률을 확인할 수 있습니다. 또한 배포하기 위해 App Insights를 사용하도록 설정하여 요청 속도, 응답 시간 및 실패율을 이해할 수 있습니다.
이벤트 처리량이 높은 시나리오에서는 Stream Analytics에서 다음 매개 변수를 변경하여 엔드투엔드 대기 시간을 단축하여 최적의 성능을 구현해야 할 수 있습니다.
- 최대 일괄 처리 수입니다.
- 파티션당 병렬 요청 수
올바른 일괄 처리 크기 결정
웹 서비스를 배포한 후에는 50 단위에서 수백 단위까지의 다양한 일괄 처리 크기로 샘플 요청을 보냅니다. 예를 들면 200, 500, 1000, 2000 등이 있습니다. 특정 일괄 처리 크기 이후에 응답의 대기 시간이 증가하는 것을 알 수 있습니다. 응답 대기 시간이 증가하는 지점은 작업의 최대 일괄 처리 수입니다.
파티션당 병렬 요청 수 결정
최적의 크기 조정 시 Stream Analytics 작업에서 웹 서비스로 여러 병렬 요청을 보내고 몇 밀리초 내에 응답을 받을 수 있어야 합니다. 웹 서비스 응답의 대기 시간은 Stream Analytics 작업의 대기 시간 및 성능에 직접적인 영향을 줄 수 있습니다. 작업에서 웹 서비스로의 호출에 오랜 시간이 걸리는 경우 워터마크 지연이 증가하며 백로그된 입력 이벤트 수가 증가할 수도 있습니다.
AKS(Azure Kubernetes Service) 클러스터가 적절한 수의 노드 및 복제본으로 프로비저닝되었는지 확인하여 짧은 대기 시간을 달성할 수 있습니다. 웹 서비스는 가용성이 높아야 하며 응답을 성공적으로 반환해야 합니다. 서비스 불가 응답(503)과 같이 다시 시도할 수 있는 오류가 작업에서 발생하면, 지수 백오프 기법을 사용하여 자동으로 다시 시도합니다. 작업이 엔드포인트에서 응답으로 이러한 오류 중 하나를 수신하면 작업은 실패 상태가 됩니다.
- 잘못된 요청(400)
- 충돌(409)
- 찾을 수 없음(404)
- 권한 없음(401)
제한 사항
Azure ML 관리형 엔드포인트 서비스를 사용하는 경우 Stream Analytics는 현재 공용 네트워크 액세스를 사용하도록 설정된 엔드포인트에만 액세스할 수 있습니다. Azure ML 프라이빗 엔드포인트에 대한 페이지에서 자세히 알아보세요.