Azure Stream Analytics는 스트림 처리를 위한 완전히 관리되는 PaaS(Platform-as-a-Service)입니다. 이 문서에서는 Stream Analytics 클러스터의 개념, 작업 및 작업의 구성 요소를 소개하여 Stream Analytics의 리소스 모델을 설명합니다.
Stream Analytics 작업
Stream Analytics 작업은 스트림 처리 논리를 정의하고 실행할 수 있는 Stream Analytics의 기본 단위입니다. 작업은 다음 세 가지 주요 구성 요소로 구성됩니다.
- 입력
- 출력
- 쿼리
입력
작업에는 데이터를 지속적으로 읽을 하나 이상의 입력이 있을 수 있습니다. 이러한 스트리밍 입력 데이터 원본은 Azure Event Hubs, Azure IoT Hub 또는 Azure Storage일 수 있습니다. Stream Analytics는 스트리밍 데이터를 보강하는 데 자주 사용되는 정적 또는 느린 변경 입력 데이터(참조 데이터라고 함)를 읽는 것도 지원합니다. 이러한 입력을 작업에 추가하는 것은 코드가 없는 작업입니다.
출력
작업에는 데이터를 지속적으로 쓸 하나 이상의 출력이 있을 수 있습니다. Stream Analytics는 Azure SQL Database, Azure Data Lake Storage, Azure Cosmos DB, Power BI 등 12개의 출력 싱크를 지원합니다. 이러한 출력을 작업에 추가하는 것도 코드가 없는 작업입니다.
쿼리
작업에서 SQL 쿼리를 작성하여 스트림 처리 논리를 구현할 수 있습니다. 풍부한 SQL 언어 지원을 통해 복잡한 JSON 구문 분석, 값 필터링, 집계 컴퓨팅, 조인 수행, 지리 공간적 분석 및 변칙 검색과 같은 고급 사용 사례와 같은 시나리오를 해결할 수 있습니다. JavaScript UDF(사용자 정의 함수) 및 UDA(사용자 정의 집계)를 사용하여 이 SQL 언어를 확장할 수도 있습니다. 또한 Stream Analytics를 사용하면 작업 설정에서 간단한 구성을 통해 지연 및 순서가 벗어난 이벤트에 대해 쉽게 조정할 수 있습니다. 입력 소스에서 입력 이벤트의 도착 시간 또는 이벤트 원본에서 이벤트가 생성된 시간에 따라 쿼리를 실행하도록 선택할 수도 있습니다.
작업 실행
입력, 출력 및 쿼리를 구성하여 작업을 개발한 후에는 스트리밍 단위 수를 지정하여 작업을 시작할 수 있습니다. 작업이 시작되면 실행 중 상태로 전환되고 명시적으로 중지되거나 복구할 수 없는 실패로 실행될 때까지 해당 상태로 유지됩니다. 작업이 실행 중일 때 입력 소스에서 데이터를 지속적으로 끌어오고, 쿼리 논리를 실행하여 밀리초 단위의 엔드 투 엔드 지연 시간으로 출력 싱크에 기록되는 결과를 생성합니다.
작업이 시작되면 Stream Analytics 서비스는 쿼리 컴파일을 처리하고 작업에 구성된 스트리밍 단위 수에 따라 특정 양의 컴퓨팅 및 메모리를 할당합니다. 기본 인프라는 클러스터 유지 관리, 보안 패치는 플랫폼에서 자동으로 처리되므로 걱정할 필요가 없습니다. 표준 SKU에서 작업을 실행하는 경우 작업이 실행되는 경우에만 스트리밍 단위에 대한 요금이 청구됩니다.
Stream Analytics 클러스터
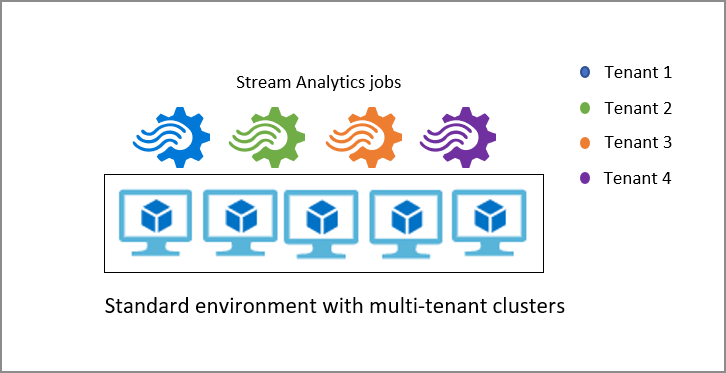
기본적으로 Stream Analytics 작업은 표준 SKU를 구성하는 표준 다중 테넌트 환경에서 실행됩니다. 또한 Stream Analytics는 사용자가 속한 전체 Stream Analytics 클러스터를 프로비전할 수 있는 전용 SKU를 제공합니다. 이렇게 하면 클러스터에서 실행되는 작업을 완전히 제어할 수 있습니다. Stream Analytics 클러스터의 최소 크기는 12 스트리밍 단위이며 프로비전될 때부터 전체 클러스터 용량에 대한 요금이 청구됩니다. Stream Analytics 클러스터의 이점 및 사용 시기에 대해 자세히 알아볼 수 있습니다.

다음 단계
Azure Stream Analytics 및 기타 개념을 관리하는 방법을 알아봅니다.