Azure Synapse Analytics의 Apache Spark Advisor(미리 보기)
Apache Spark Advisor는 Spark에서 실행하는 명령 및 코드를 분석하고 Notebook 실행 시 실시간 조언을 표시합니다. Spark Advisor에는 사용자가 일반적인 실수를 방지하고, 코드 최적화에 대한 권장 사항을 제공하고, 오류 분석을 수행하고, 오류의 근본 원인을 찾는 데 도움이 되는 기본 제공 패턴이 있습니다.
기본 제공 조언
'randomSplit'를 사용할 때 일관되지 않은 결과를 반환할 수 있습니다.
'randomSplit' 메서드의 결과를 사용할 때 일관되지 않거나 부정확한 결과가 반환될 수 있습니다. 'randomSplit' 메서드를 사용하기 전에 RDD(Apache Spark) 캐싱을 사용합니다.
randomSplit() 메서드는 데이터 프레임에서 sample()을 여러 번 수행하는 것과 동일하며, 각 샘플은 파티션 내에서 데이터 프레임을 다시 가져오고, 분할하고, 정렬합니다. randomSplit() 및 sample() 모두 파티션 및 정렬 순서에 대한 데이터 분포가 중요합니다. 데이터를 다시 가져올 때 둘 중 하나가 변경되면 중복되거나 누락된 값이 있을 수 있으며 동일한 시드를 사용하는 동일한 샘플이 다른 결과를 생성할 수 있습니다.
이러한 불일치가 모든 실행에서 발생하는 것은 아니지만 완전히 제거하려면 데이터 프레임을 캐시하거나 열에서 다시 분할하거나 groupBy와 같은 집계 함수를 적용합니다.
테이블/뷰 이름이 이미 사용 중임
생성된 테이블과 동일한 이름의 뷰가 이미 존재하거나 생성된 뷰와 동일한 이름의 테이블이 이미 존재합니다. 쿼리나 애플리케이션에서 이 이름을 사용하면 어느 것이 먼저 만들어지든 관계없이 뷰만 반환됩니다. 충돌을 방지하려면 테이블이나 뷰의 이름을 바꿉니다.
힌트를 인식할 수 없음
선택한 쿼리에 인식되지 않는 힌트가 포함되어 있습니다. 힌트의 철자가 올바른지 확인하세요.
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
지정된 관계 이름을 찾을 수 없음
힌트에 지정된 관계를 찾을 수 없습니다. 관계의 철자가 올바르고 힌트 범위 내에서 액세스 가능한지 확인하세요.
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
쿼리의 힌트는 다른 힌트가 적용되는 것을 방지함
선택한 쿼리에 다른 힌트가 적용되지 않도록 하는 힌트가 포함되어 있습니다.
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
반올림 오류 전파를 줄이기 위해 'park.advise.divisionExprConvertRule.enable'을 사용하도록 설정
이 쿼리에는 Double 형식의 식이 포함됩니다. 나누기 식을 줄이고 반올림 오류 전파를 줄이는 데 도움이 되는 'park.advise.divisionExprConvertRule.enable' 구성을 사용하도록 설정하는 것이 좋습니다.
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
쿼리 성능을 개선하기 위해 'park.advise.nonEqJoinConvertRule.enable'을 사용하도록 설정
이 쿼리에는 쿼리 내의 "Or" 조건으로 인해 시간이 오래 걸리는 조인이 포함되어 있습니다. 이 쿼리를 가속화하기 위해 "Or" 조건에 의해 트리거된 조인을 SMJ 또는 BHJ로 변환하는 데 도움이 될 수 있는 'park.advise.nonEqJoinConvertRule.enable' 구성을 사용하도록 설정하는 것이 좋습니다.
작은 파일 압축을 사용하여 델타 테이블 최적화
이 쿼리는 작은 파일이 많은 델타 테이블에 있습니다. 쿼리 성능을 개선하려면 델타 테이블에서 OPTIMIZE 명령을 실행합니다. 자세한 내용은 이 문서에서 확인할 수 있습니다.
ZOrder를 사용하여 델타 테이블 최적화
이 쿼리는 델타 테이블에 있으며 매우 선택적인 필터를 포함합니다. 쿼리 성능을 개선하려면 델타 테이블에서 OPTIMIZE ZORDER BY 명령을 실행합니다. 자세한 내용은 이 문서에서 확인할 수 있습니다.
사용자 환경
Apache Spark Advisor는 Notebook 셀 출력에서 정보, 경고, 오류를 포함한 조언을 실시간으로 표시합니다.
정보
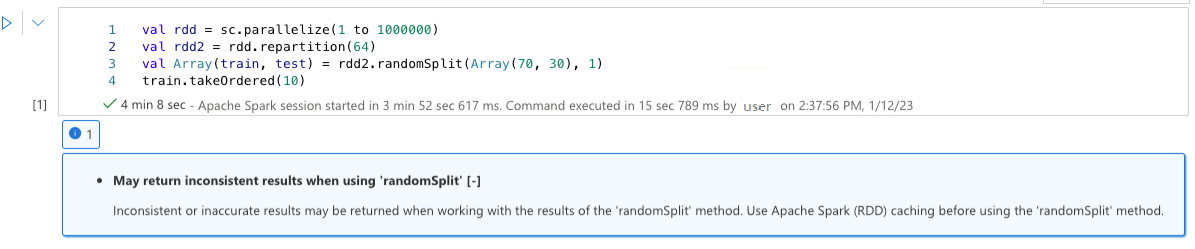
Warning

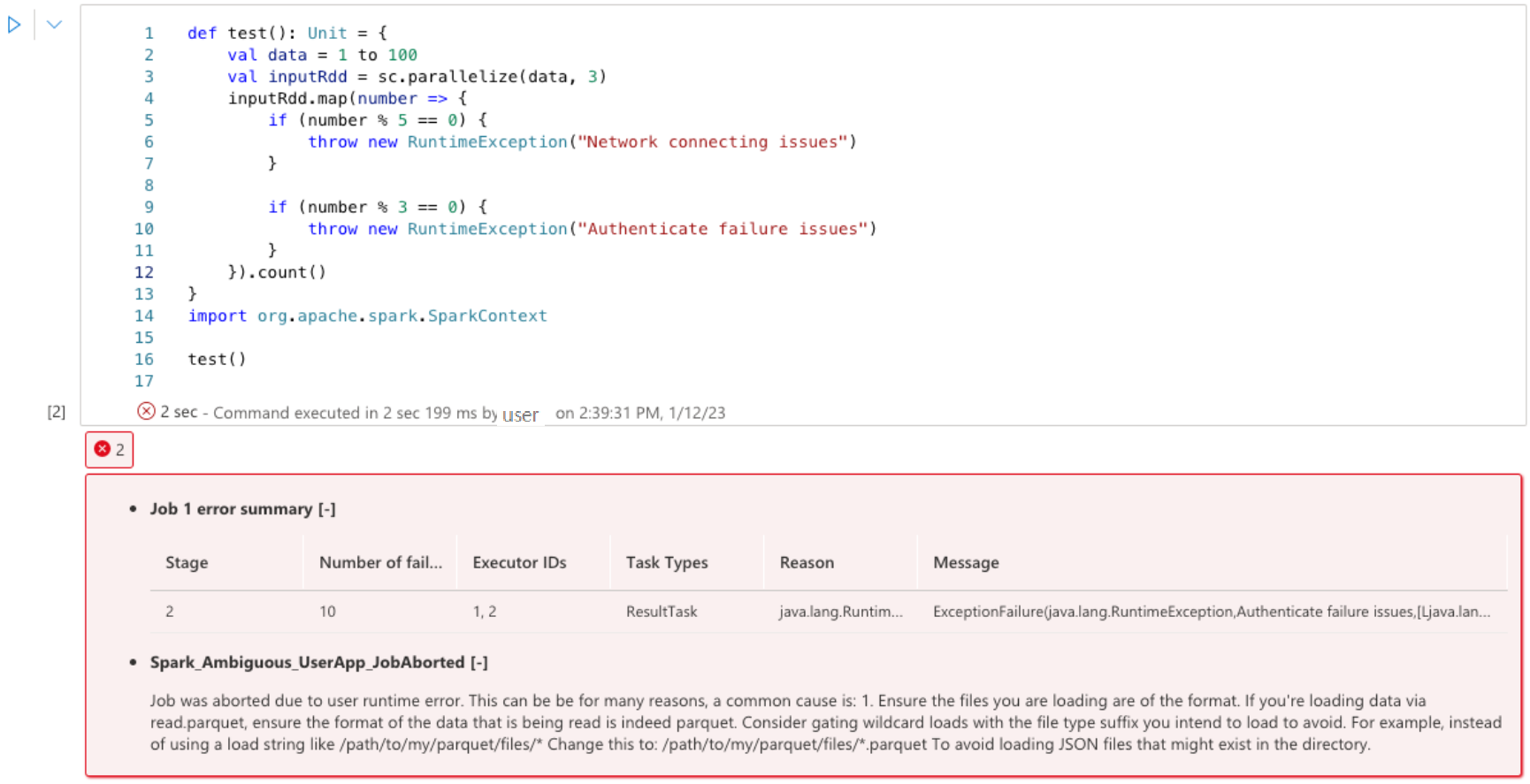
Errors
다음 단계
Apache Spark 애플리케이션 모니터링에 대한 자세한 내용은 Synapse Studio에서 Apache Spark 애플리케이션 모니터링 문서를 참조하세요.
Notebook을 만드는 방법에 대한 자세한 내용은 Synapse Notebook을 사용하는 방법을 참조하세요.