Azure Synapse Analytics의 Notebook(Synapse Notebook)은 라이브 코드, 시각화 및 설명 텍스트가 포함된 파일을 만들 수 있는 웹 인터페이스입니다. Notebook은 아이디어를 검증하고 빠른 실험을 사용하여 데이터를 통해 인사이트를 확보하기 좋은 도구입니다. Notebook은 데이터 준비, 데이터 시각화, 기계 학습 및 기타 빅 데이터 시나리오에서도 널리 사용됩니다.
Synapse Notebook의 이점은 다음과 같습니다.
- 시작에 필요한 설정 작업이 전혀 없습니다.
- 기본 제공 엔터프라이즈 보안 기능으로 데이터 보안을 유지할 수 있습니다.
- CSV, TXT, JSON 등의 원시 형식, Parquet, Delta Lake, ORC 등의 처리된 파일 형식, 그리고 Spark와 SQL에 대한 SQL 표 형식 데이터 파일의 데이터를 분석합니다.
- 향상된 제작 기능 및 기본 제공 데이터 시각화를 통해 생산성을 높일 수 있습니다.
이 문서에서는 Synapse Studio에서 Notebook을 사용하는 방법을 설명합니다.
Notebook 만들기
개체 탐색기에서 새 Notebook을 만들거나 Synapse 작업 영역으로 기존 Notebook을 가져올 수 있습니다. 개발 메뉴를 선택합니다. + 단추를 선택하고 Notebook을 선택하거나 Notebooks를 마우스 오른쪽 단추로 클릭한 다음 새 Notebook 또는 가져오기를 선택합니다. Synapse Notebook은 표준 Jupyter Notebook IPYNB 파일을 인식합니다.
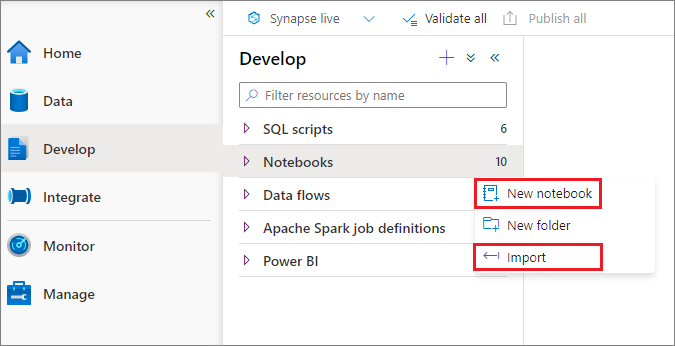
Notebook 개발
Notebooks는 셀로 구성됩니다. 셀은 독립적으로 또는 그룹으로 실행할 수 있는 개별 코드나 텍스트 블록입니다.
다음 섹션에서는 Notebook 개발 작업을 설명합니다.
- 셀 추가
- 주 언어 설정
- 여러 언어 사용
- 임시 테이블을 사용하여 언어 간 데이터 참조
- IDE 스타일 IntelliSense 사용
- 코드 족각 사용
- 도구 모음 단추를 사용하여 텍스트 셀 서식 지정
- 셀 작업 실행 취소 또는 다시 실행
- 코드 셀에 대한 메모
- 셀 이동
- 셀 복사
- 셀 삭제
- 셀 입력 축소
- 셀 출력 축소
- Notebook 개요 사용
참고
Notebook에서는 SparkSession 인스턴스가 자동으로 만들어져 spark라는 변수에 저장됩니다. SparkContext에 대해 sc라는 변수도 있습니다. 사용자는 이러한 변수에 직접 액세스할 수 있지만 이러한 변수의 값을 변경해서는 안 됩니다.
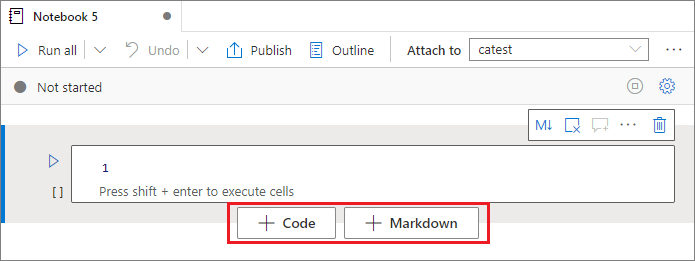
셀 추가
Notebook에 새 셀을 추가하는 방법은 여러 가지입니다.
두 셀 사이의 공간을 마우스로 가리키고 코드 또는 Markdown을 선택합니다.
명령 모드에서 바로 가기 키를 사용합니다. 현재 셀 위에 셀을 삽입하려면 A 키를 선택합니다. 현재 셀 아래에 셀을 삽입하려면 B 키를 선택합니다.
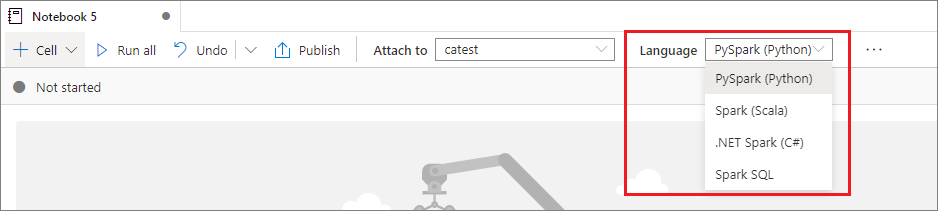
주 언어 설정
Synapse Notebook은 4개의 Apache Spark 언어를 지원합니다.
- PySpark(Python)
- Spark(Scala)
- Spark SQL
- .NET Spark(C#)
- SparkR(R)
새로 추가된 셀의 기본 언어를 상단 명령 모음의 언어 드롭다운 목록에서 설정할 수 있습니다.
여러 언어 사용
셀 시작 부분에 올바른 언어 매직 명령을 지정하면 Notebook 하나에서 여러 언어를 사용할 수 있습니다. 셀 언어를 전환하는 매직 명령은 다음 표에 나열되어 있습니다.
| 매직 명령 | 언어 | 설명 |
|---|---|---|
%%pyspark |
Python | SparkContext에 대해 Python 쿼리를 실행합니다. |
%%spark |
스칼라 | SparkContext에 대해 Scala 쿼리를 실행합니다. |
%%sql |
Spark SQL | SparkContext에 대해 Spark SQL 쿼리를 실행합니다. |
%%csharp |
.NET for Spark C# | SparkContext에 대해 Spark C# 쿼리를 위한 .NET을 실행합니다. |
%%sparkr |
R | SparkContext에 대해 R 쿼리를 실행합니다. |
다음 이미지는 Spark(Scala) Notebook에서 %%pyspark 매직 명령을 사용하여 PySpark 쿼리를 작성하는 방법 또는 %%sql 매직 명령을 사용하여 Spark SQL 쿼리를 작성하는 방법의 예를 보여 줍니다. Notebook의 기본 언어는 PySpark로 설정됩니다.
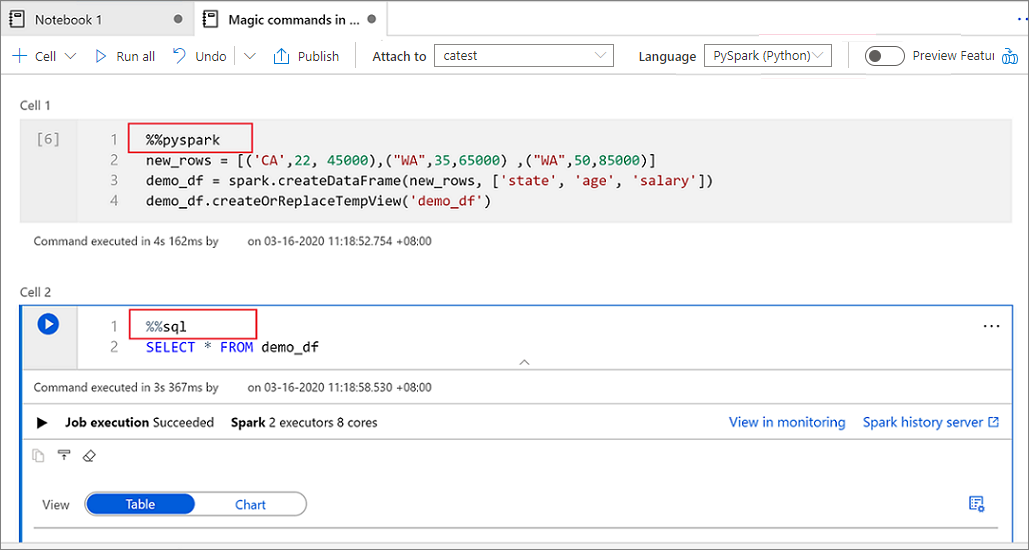
임시 테이블을 사용하여 언어 간 데이터 참조
Synapse Notebook의 여러 언어 간에 직접 데이터나 변수를 참조할 수 없습니다. Spark에서는 여러 언어에서 임시 테이블을 참조할 수 있습니다. 다음은 Spark 임시 테이블을 해결 방법으로 사용하여 PySpark와 Spark SQL에서 Scala DataFrame을 읽는 방법의 예입니다.
셀 1에서는 Scala를 사용하여 SQL 풀 커넥터에서 DataFrame을 읽고 임시 테이블을 생성합니다.
%%spark val scalaDataFrame = spark.read.sqlanalytics("mySQLPoolDatabase.dbo.mySQLPoolTable") scalaDataFrame.createOrReplaceTempView( "mydataframetable" )셀 2에서는 Spark SQL을 사용하여 데이터를 쿼리합니다.
%%sql SELECT * FROM mydataframetable셀 3에서는 PySpark의 데이터를 사용합니다.
%%pyspark myNewPythonDataFrame = spark.sql("SELECT * FROM mydataframetable")
IDE 스타일 IntelliSense 사용
Synapse Notebook은 Monaco 편집기와 통합되어 IDE 스타일 IntelliSense를 셀 편집기로 가져옵니다. 구문 강조 표시, 오류 표식, 자동 코드 완료 기능을 사용하면 코드를 작성하고 문제를 더 빠르게 식별할 수 있습니다.
IntelliSense 기능은 완성도 수준이 언어마다 다릅니다. 지원되는 기능은 다음 표를 참조하세요.
| 언어 | 구문 강조 표시 | 구문 오류 표식 | 구문 코드 완성 | 변수 코드 완성 | 시스템 함수 코드 완성 | 사용자 함수 코드 완성 | 스마트 들여쓰기 | 코드 접기 |
|---|---|---|---|---|---|---|---|---|
| PySpark(Python) | 예 | 예 | 예 | 예 | 예 | 예 | 예 | 예 |
| Spark(Scala) | 예 | 예 | 예 | 예 | 예 | 예 | 아니요 | 예 |
| Spark SQL | 예 | 예 | 예 | 예 | 예 | 아니요 | 아니요 | 아니요 |
| .NET for Spark(C#) | 예 | 예 | 예 | 예 | 예 | 예 | 예 | 예 |
.NET for Spark(C#)에 대한 변수 코드 완료, 시스템 함수 코드 완료 및 사용자 함수 코드 완료의 이점을 활용하려면 활성 Spark 세션이 필요합니다.
코드 조각 사용
Synapse Notebook은 일반적으로 사용되는 코드 패턴을 더 쉽게 입력할 수 있는 코드 조각을 제공합니다. 이러한 패턴에는 Spark 세션 구성, Spark DataFrame으로 데이터 읽기, Matplotlib을 사용하여 차트 그리기가 포함됩니다.
코드 조각은 IDE 스타일 IntelliSense의 바로 가기 키에 다른 제안 사항과 함께 표시됩니다. 코드 조각 콘텐츠는 코드 셀 언어에 따라 달라집니다. 코드 셀 편집기에서 snippet을 입력하거나 코드 조각 제목에 나타나는 키워드를 입력하면 사용 가능한 코드 조각을 볼 수 있습니다. 예를 들어 read를 입력하면 여러 데이터 원본으로부터 데이터 읽기를 위한 코드 조각 목록이 표시됩니다.

도구 모음 단추를 사용하여 텍스트 셀 서식 지정
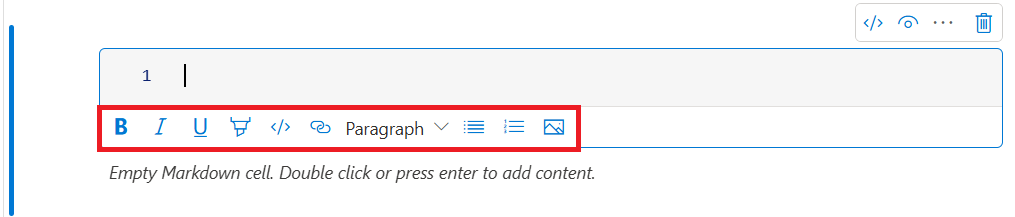
텍스트 셀 도구 모음의 서식 단추를 사용하여 일반적인 Markdown 작업을 수행할 수 있습니다. 이러한 작업에는 텍스트를 굵게 만들기, 기울임꼴로 만들기, 드롭다운 메뉴를 통해 문단과 제목 만들기, 코드 삽입, 순서가 지정되지 않은 목록 삽입, 순서가 지정된 목록 삽입, 하이퍼링크 삽입, URL에서 이미지 삽입 등이 포함됩니다.
셀 작업 실행 취소 또는 다시 실행
가장 최근의 셀 작업을 철회하려면 실행 취소 또는 다시 실행 단추를 선택하거나 Z 키나 Shift+Z를 선택합니다. 이제 최대 10개의 이전 셀 작업을 실행 취소하거나 다시 실행할 수 있습니다.

지원되는 셀 작업은 다음과 같습니다.
- 셀을 삽입하거나 삭제합니다. 실행 취소를 선택하면 삭제 작업을 철회할 수 있습니다. 이 작업을 수행하면 텍스트 콘텐츠가 셀과 함께 유지됩니다.
- 셀을 다시 정렬합니다.
- 매개 변수 셀을 켜거나 끕니다.
- 코드 셀과 Markdown 셀 사이를 변환합니다.
참고
셀에서의 텍스트 작업이나 메모 작성 작업은 실행 취소할 수 없습니다.
코드 셀에 대한 메모
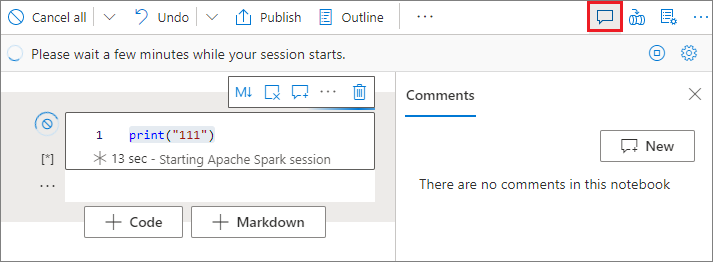
Notebook 도구 모음에서 메모 단추를 선택하여 메모 창을 엽니다.
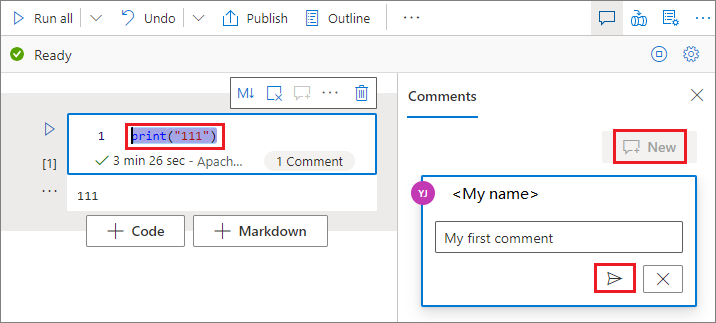
코드 셀에서 코드를 선택하고, 메모 창에서 새로 만들기를 선택하고, 메모를 추가한 다음, 메모 게시 단추를 선택합니다.
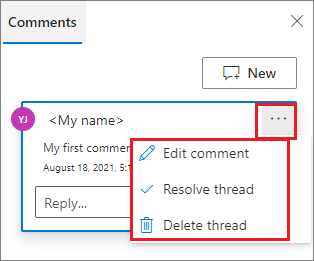
필요한 경우 메모 옆에 있는 자세히 줄임표(...)를 선택하여 메모 편집, 스레드 해결, 스레드 삭제 작업을 수행할 수 있습니다.
셀 이동
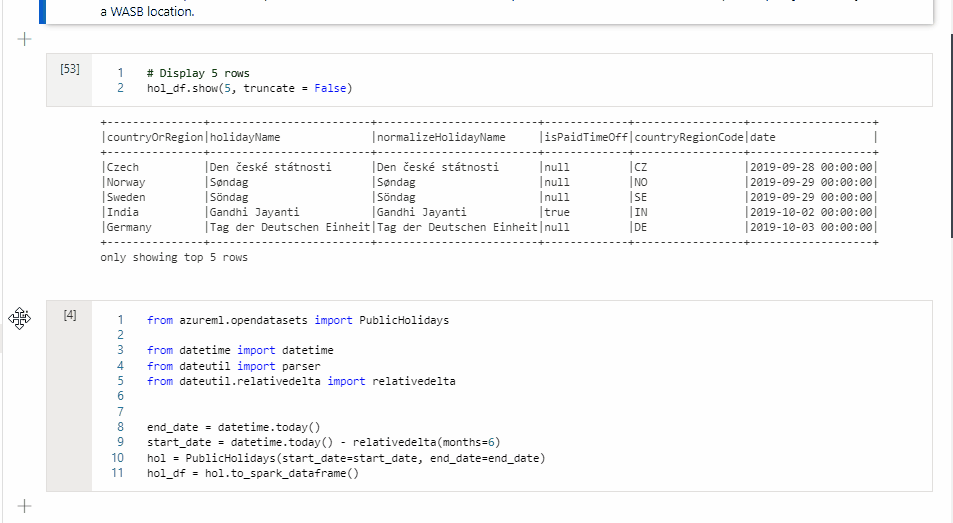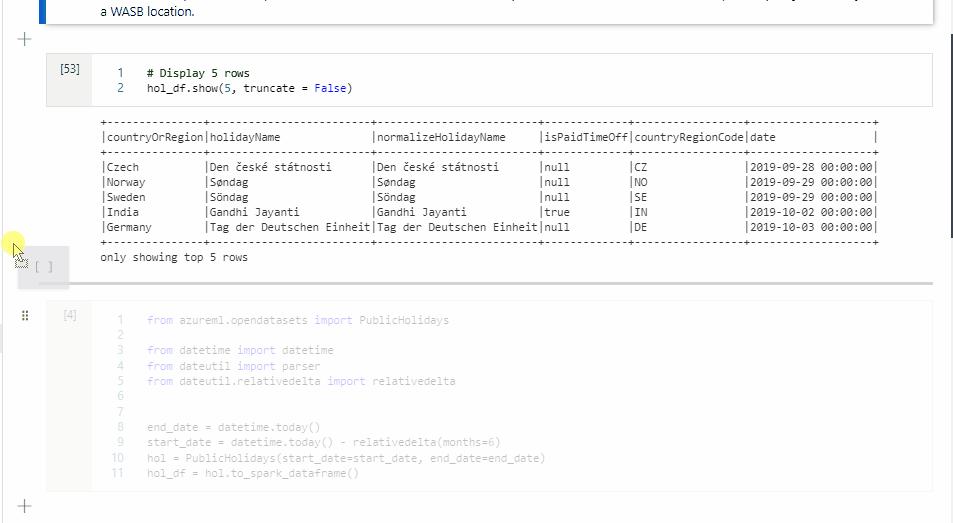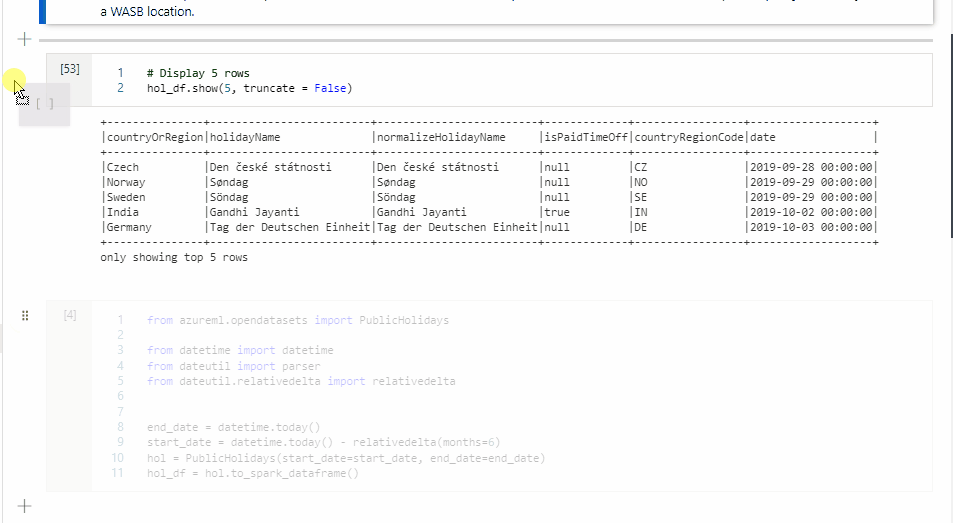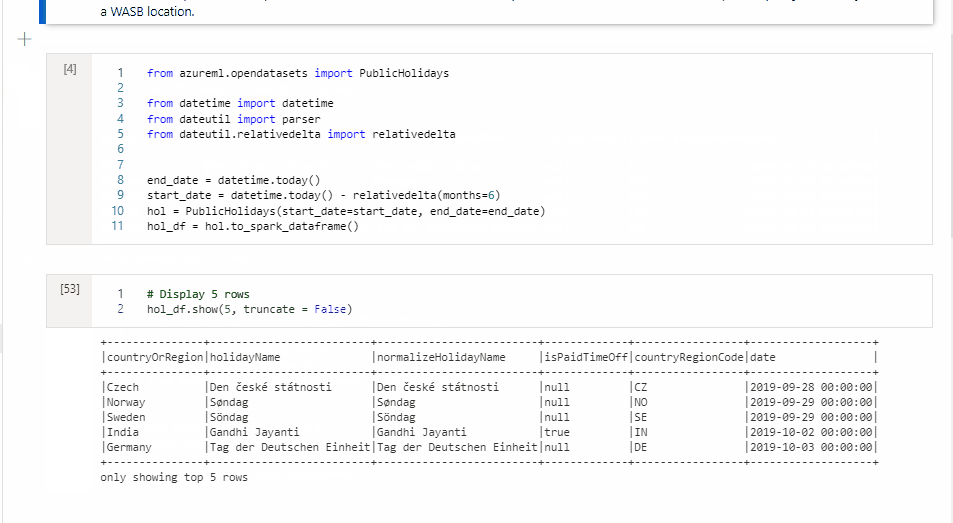
셀을 이동하려면 셀의 왼쪽을 선택하고 원하는 위치로 셀을 끕니다.
셀 복사
셀을 복사하려면 먼저 새 셀을 만든 다음, 원래 셀의 모든 텍스트를 선택하고, 텍스트를 복사한 다음, 새 셀에 붙여넣습니다. 셀이 편집 모드에 있을 때, 모든 텍스트를 선택하는 기존 바로 가기 키는 셀로 제한됩니다.
팁
또한 Synapse Notebook은 일반적으로 사용되는 코드 패턴의 스니핏을 제공합니다.
셀 삭제
셀을 삭제하려면 셀 오른쪽에 있는 삭제 단추를 선택합니다.
명령 모드에서 바로 가기 키를 사용할 수도 있습니다. 현재 셀을 삭제하려면 Shift+D를 선택합니다.
셀 입력 축소
현재 셀의 입력을 축소하려면 셀 도구 모음에서 추가 명령 줄임표(...)를 선택한 다음 입력 숨기기를 선택합니다. 입력을 확장하려면 셀이 축소된 상태에서 입력 표시를 선택합니다.
셀 출력 축소
현재 셀의 출력을 축소하려면 셀 도구 모음에서 추가 명령 줄임표(...)를 선택한 다음 출력 숨기기를 선택합니다. 출력을 확장하려면 셀의 출력이 숨겨진 상태에서 출력 표시를 선택합니다.
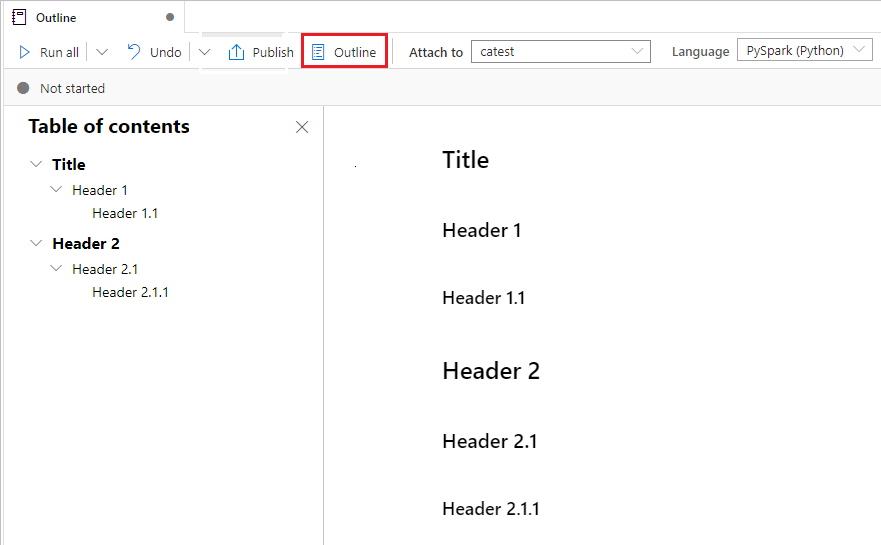
Notebook 개요 사용
개요(목차)는 빠른 탐색을 위해 사이드바 창에 있는 모든 Markdown 셀의 첫 번째 Markdown 헤더를 나타냅니다. 개요 사이드바는 가능한 최적의 방법으로 화면에 맞게 크기 조절 및 축소가 가능합니다. 사이드바를 열거나 숨기려면 Notebook 명령 모음에서 개요 단추를 선택합니다.
Notebook을 실행합니다.
Notebook의 코드 셀을 개별적으로 또는 한꺼번에 실행할 수 있습니다. 각 셀의 상태와 진행률은 Notebook에 나타납니다.
참고
Notebook을 삭제해도 현재 실행 중인 작업은 자동으로 취소되지 않습니다. 작업을 취소해야 하는 경우 모니터 허브로 이동하여 수동으로 취소합니다.
셀 실행
셀에서 코드를 실행하는 방법은 여러 가지가 있습니다.
실행하려는 셀 위에 마우스를 가리키고 셀 실행 단추를 선택하거나 Ctrl+Enter를 선택합니다.

명령 모드에서 바로 가기 키를 사용합니다. Shift+Enter를 누르면 현재 셀을 실행하고 그 아래 셀을 선택할 수 있습니다. 현재 셀을 실행하고 그 아래에 새 셀을 삽입하려면 Alt+Enter를 선택합니다.
모든 셀 실행
현재 Notebook의 모든 셀을 순서대로 실행하려면 모두 실행 단추를 선택합니다.

위 또는 아래 셀 모두 실행
현재 셀 위에 있는 모든 셀을 순서대로 실행하려면 모두 실행 단추의 드롭다운 목록을 확장한 다음, 위의 셀 실행을 선택합니다. 현재 셀 아래의 모든 셀을 순서대로 실행하려면 아래 셀 실행을 선택합니다.
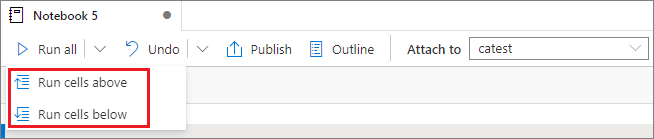
실행 중인 모든 셀 취소
실행 중인 셀이나 대기 중인 셀을 취소하려면 모두 취소 단추를 선택합니다.

Notebook 참조
현재 Notebook의 컨텍스트 내에서 다른 Notebook을 참조하려면 %run <notebook path> 매직 명령을 사용합니다. 참조 Notebook에 정의된 모든 변수는 현재 Notebook에서 사용할 수 있습니다.
예를 들면 다음과 같습니다.
%run /<path>/Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }
Notebook 참조는 대화형 모드와 파이프라인 모두에서 작동합니다.
%run 매직 명령에는 다음과 같은 제한 사항이 있습니다.
- 해당 명령은 중첩 호출은 지원하지만 재귀 호출은 지원하지 않습니다.
- 이 명령은 절대 경로나 Notebook 이름만 매개 변수로 전달하는 것을 지원합니다. 상대 경로는 지원하지 않습니다.
- 현재 이 명령은
int,float,bool,string의 네 가지 매개 변수 값 형식만 지원합니다. 변수 대체 작업은 지원하지 않습니다. - 참조된 Notebook은 게시되어야 합니다. 게시되지 않은 Notebook 참조를 사용하도록 설정하는 옵션을 선택하지 않는 한, 해당 Notebook을 참조하려면 해당 Notebook을 게시해야 합니다. Synapse Studio는 Git 리포지토리의 게시되지 않은 Notebook을 인식하지 못합니다.
- 참조된 Notebook은 5보다 큰 문장 깊이를 지원하지 않습니다.
변수 탐색기 사용
Synapse Notebook은 PySpark(Python) 셀에 대한 현재 Spark 세션의 변수를 나열하는 표 형태의 기본 제공 변수 탐색기를 제공합니다. 표에는 변수 이름, 형식, 길이, 값에 대한 열이 포함되어 있습니다. 코드 셀에 정의되는 변수가 많아질수록 자동으로 더 많은 변수가 나타납니다. 각 열 머리글을 선택하면 표의 변수가 정렬됩니다.
변수 탐색기를 열거나 숨기려면 Notebook 명령 모음에서 변수 단추를 선택합니다.
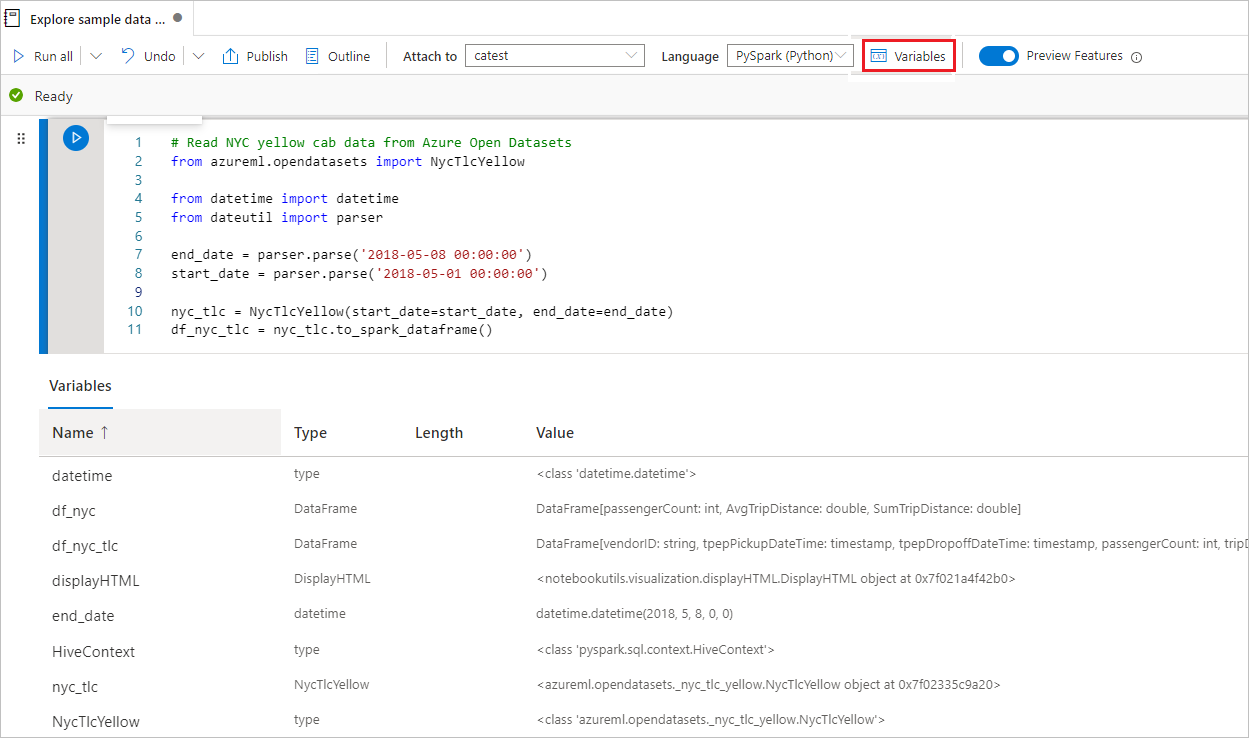
참고
변수 탐색기는 Python만 지원합니다.
셀 상태 표시기 사용
셀 실행의 단계별 상태가 셀 아래에 표시되어 현재 진행률을 확인할 수 있습니다. 셀 실행이 완료되면 전체 기간과 종료 시간이 포함된 요약이 나타나며 향후 참조를 위해 보관됩니다.

Spark 진행률 표시기 사용
Synapse Notebook은 순전히 Spark 기반입니다. 코드 셀은 서버리스 Apache Spark 풀에서 원격으로 실행됩니다. 실시간 진행률 막대가 있는 Spark 작업 진행률 표시줄을 통해 작업 실행 상태를 이해할 수 있습니다.
각 작업이나 단계에 대한 작업 수를 통해 Spark 작업의 병렬 수준을 식별할 수 있습니다. 작업(또는 스테이지) 이름에서 링크를 선택하여 특정 작업(또는 단계)의 Spark UI를 자세히 드릴할 수도 있습니다.
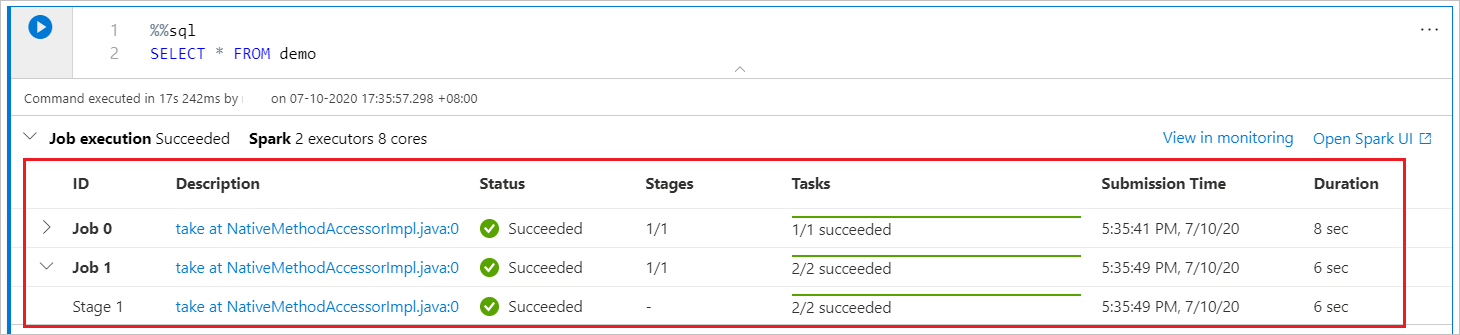
Spark 세션 구성
Notebook 상단의 기어 아이콘을 선택하면 찾을 수 있는 세션 구성 창에서 현재 Spark 세션에 제공할 시간 제한 기간, 실행기 수, 실행기 크기를 지정할 수 있습니다. 구성 변경 내용을 적용하려면 Spark 세션을 다시 시작합니다. 캐시된 Notebook 변수는 모두 지워집니다.
Apache Spark 구성에서 구성을 만들거나 기존 구성을 선택할 수도 있습니다. 자세한 내용은 Apache Spark 구성 관리를 참조하세요.

Spark 세션 구성을 위한 매직 명령
%%configure라는 매직의 명령을 통해 Spark 세션 설정을 지정할 수도 있습니다. 설정을 적용하려면 Spark 세션을 다시 시작합니다.
Notebook의 시작 부분에서 %%configure를 실행하는 것이 좋습니다. 다음은 샘플입니다. 유효한 매개 변수의 전체 목록은 GitHub의 Livy 정보를 참조하세요.
%%configure
{
//You can get a list of valid parameters to configure the session from https://github.com/cloudera/livy#request-body.
"driverMemory":"28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g", "472g"]
"driverCores":4, // Recommended values: [4, 8, 16, 32, 64, 80]
"executorMemory":"28g",
"executorCores":4,
"jars":["abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>/myjar.jar","wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>/myjar1.jar"],
"conf":{
//Example of a standard Spark property. To find more available properties, go to https://spark.apache.org/docs/latest/configuration.html#application-properties.
"spark.driver.maxResultSize":"10g",
//Example of a customized property. You can specify the count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows":"3000"
}
}
%%configure 매직 명령에 대한 몇 가지 고려 사항은 다음과 같습니다.
%%configure의driverMemory및executorMemory에 동일한 값을 사용하는 것이 좋습니다. 또한driverCores와executorCores가 같은 값을 갖는 것이 좋습니다.- Synapse 파이프라인에서
%%configure를 사용할 수 있지만 첫 번째 코드 셀에 설정하지 않으면 세션을 다시 시작할 수 없기 때문에 파이프라인 실행이 실패합니다. mssparkutils.notebook.run에서 사용된%%configure명령은 무시되지만%run <notebook>에서 사용된 명령은 계속 실행됩니다."conf"본문에서 표준 Spark 구성 속성을 사용해야 합니다. Spark 구성 속성에 대한 1차 참조는 지원되지 않습니다."spark.driver.cores","spark.executor.cores","spark.driver.memory","spark.executor.memory"및"spark.executor.instances"를 포함하여 일부 특수 Spark 속성은"conf"본문에서 적용되지 않습니다.
파이프라인의 매개 변수가 있는 세션 구성
매개 변수가 있는 세션 구성을 사용하면 %%configure 매직 명령의 값을 파이프라인 실행(Notebook 작업) 매개 변수로 바꿀 수 있습니다. %%configure 코드 셀을 준비할 때 다음과 같은 개체를 사용하여 기본값을 재정의할 수 있습니다.
{
"activityParameterName": "parameterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParameterFromPipelineNotebookActivity"
}
다음 예에서는 4 및 "2000"의 구성 가능한 기본값을 보여 줍니다.
%%configure
{
"driverCores":
{
"activityParameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"activityParameterName": "rows",
"defaultValue": "2000"
}
}
}
대화형 모드에서 Notebook을 직접 실행하거나 파이프라인 Notebook 작업이 "activityParameterName"과 일치하는 매개 변수를 제공하지 않는 경우 Notebook은 기본값을 사용합니다.
파이프라인 실행 모드에서 설정 탭을 사용하여 파이프라인 Notebook 작업에 대한 설정을 구성할 수 있습니다.
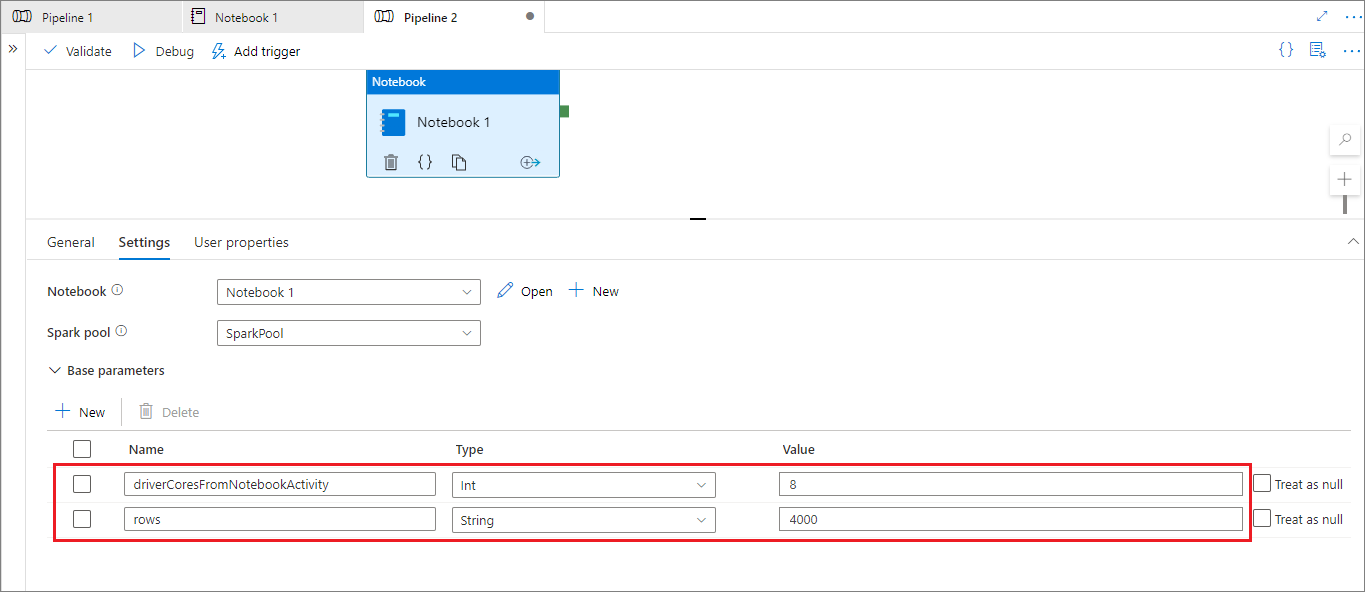
세션 구성을 변경하려면 파이프라인 Notebook 작업 매개 변수의 이름이 Notebook의 activityParameterName과 동일해야 합니다. 이 예에서 파이프라인 실행 중에 %%configure의 8이 driverCores를 바꾸고 4000이 livy.rsc.sql.num-rows를 바꿉니다.
%%configure 매직 명령을 사용한 후 파이프라인 실행이 실패하면 Notebook의 대화형 모드에서 %%configure 매직 셀을 실행하여 더 많은 오류 정보를 가져올 수 있습니다.
Notebook에 데이터 가져오기
다음 코드 샘플과 같이 Azure Data Lake Storage Gen 2, Azure Blob Storage 및 SQL 풀에서 데이터를 로드할 수 있습니다.
Azure Data Lake Storage Gen2에서 CSV 파일을 Spark DataFrame으로 읽기
from pyspark.sql import SparkSession
from pyspark.sql.types import *
account_name = "Your account name"
container_name = "Your container name"
relative_path = "Your path"
adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (container_name, account_name, relative_path)
df1 = spark.read.option('header', 'true') \
.option('delimiter', ',') \
.csv(adls_path + '/Testfile.csv')
Azure Blob Storage에서 Spark DataFrame으로 CSV 파일 읽기
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow Spark to access from Azure Blob Storage remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
df = spark.read.option("header", "true") \
.option("delimiter","|") \
.schema(schema) \
.csv(wasbs_path)
기본 스토리지 계정에서 데이터 읽기
기본 스토리지 계정의 데이터에 직접 액세스할 수 있습니다. 비밀 키를 제공할 필요가 없습니다. 데이터 탐색기에서 파일을 마우스 오른쪽 단추로 클릭하고 새 Notebook을 선택하면 자동으로 생성된 데이터 추출기가 있는 새 Notebook이 표시됩니다.
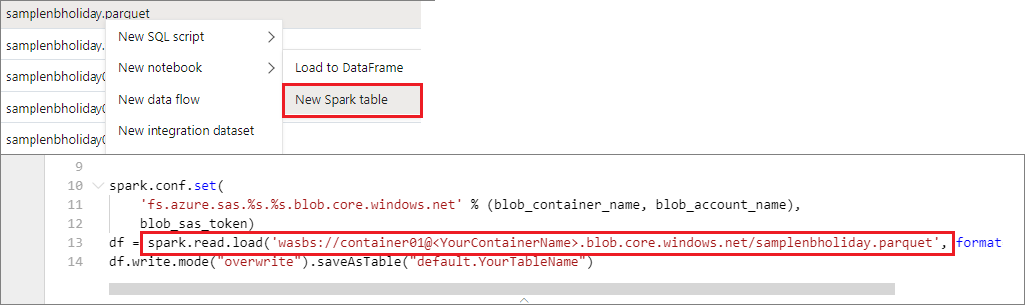
IPython 위젯 사용
위젯은 브라우저에서 슬라이더 또는 텍스트 상자와 같은 컨트롤로 표현되는 이벤트가 있는 Python 개체입니다. IPython 위젯은 Python 환경에서만 작동합니다. 현재 다른 언어(예: Scala, SQL, C#)에서는 지원되지 않습니다.
IPython 위젯을 사용하는 단계
Jupyter Widgets 프레임워크를 사용하려면
ipywidgets모듈을 가져옵니다.import ipywidgets as widgets최상위
display함수를 사용하여 위젯을 렌더링하거나 코드 셀의 마지막 줄에widget형식의 식을 남겨 둡니다.slider = widgets.IntSlider() display(slider)slider = widgets.IntSlider() slider셀을 실행합니다. 위젯은 출력 영역에 나타납니다.
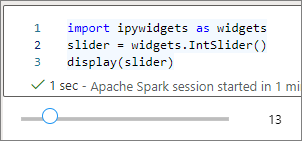
여러 display() 호출을 사용하여 동일한 위젯 인스턴스를 여러 번 렌더링할 수 있지만 서로 동기화된 상태를 유지합니다.
slider = widgets.IntSlider()
display(slider)
display(slider)
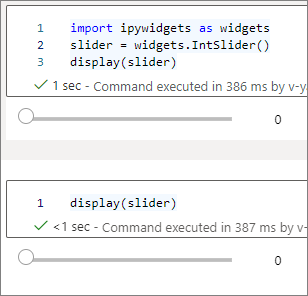
서로 독립적인 두 개의 위젯을 렌더링하려면 두 개의 위젯 인스턴스를 만듭니다.
slider1 = widgets.IntSlider()
slider2 = widgets.IntSlider()
display(slider1)
display(slider2)
지원되는 위젯
| 위젯 형식 | 위젯 |
|---|---|
| 숫자 | IntSlider, FloatSlider, FloatLogSlider, IntRangeSlider, FloatRangeSlider, IntProgress, FloatProgress, BoundedIntText, BoundedFloatText, IntText, FloatText |
| 부울 | ToggleButton, Checkbox, Valid |
| 선택 | Dropdown, RadioButtons, Select, SelectionSlider, SelectionRangeSlider, ToggleButtons, SelectMultiple |
| String | Text, Text area, Combobox, Password, Label, HTML, HTML Math, Image, Button |
| 재생(애니메이션) | Date picker, Color picker, Controller |
| 컨테이너/레이아웃 | Box, HBox, VBox, GridBox, Accordion, Tabs, Stacked |
알려진 제한 사항
다음 표에는 현재 지원되지 않는 위젯과 해결 방법이 나와 있습니다.
기능 해결 방법 Output위젯print()함수를 대신 사용하여stdout에 텍스트를 쓸 수 있습니다.widgets.jslink()widgets.link()함수를 사용하면 두 개의 유사한 위젯을 연결할 수 있습니다.FileUpload위젯사용 가능한 항목이 없습니다. Azure Synapse Analytics가 제공하는 전역
display함수는 한 번의 호출(즉,display(a, b))에서 여러 위젯을 표시하는 것을 지원하지 않습니다. 이 동작은 IPythondisplay함수와 다릅니다.IPython 위젯이 포함된 Notebook을 닫으면 해당 셀을 다시 실행할 때까지 위젯을 볼 수 없고 위젯과 상호 작용할 수도 없습니다.
Notebook 저장
작업 영역에 단일 Notebook 또는 모든 Notebook을 저장할 수 있습니다.
단일 Notebook에 변경한 내용을 저장하려면 노트북 명령 모음에서 게시 단추를 선택합니다.

작업 영역에 모든 노트북을 저장하려면 작업 영역 명령 모음에서 모두 게시 단추를 선택합니다.

Notebook의 속성 창에서 저장할 때 셀 출력을 포함할지 여부를 구성할 수 있습니다.
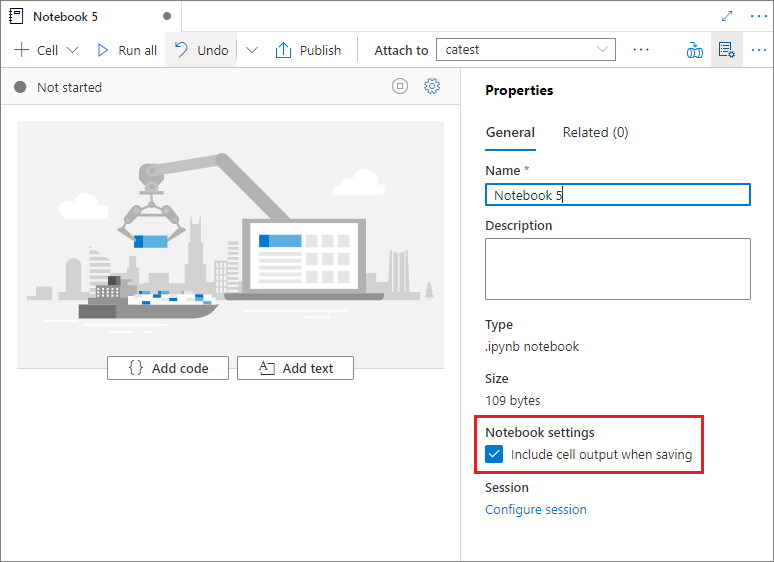
매직의 명령 사용
Synapse Notebook에서 익숙한 Jupyter 매직 명령을 사용할 수 있습니다. 현재 사용할 수 있는 매직 명령 목록을 살펴봅니다. 필요에 맞는 매직 명령을 계속 만들 수 있도록 GitHub에 사용 사례를 알려주세요.
참고
Synapse 파이프라인에서는 다음 매직 명령만 지원됩니다. %%pyspark, %%spark, %%csharp, %%sql.
라인에 사용 가능한 매직 명령:
%lsmagic, %time, %timeit, %history, %run, %load
셀에 사용 가능한 매직 명령:
%%time, %%timeit, %%capture, %%writefile, %%sql, %%pyspark, %%spark, %%csharp, %%html, %%configure
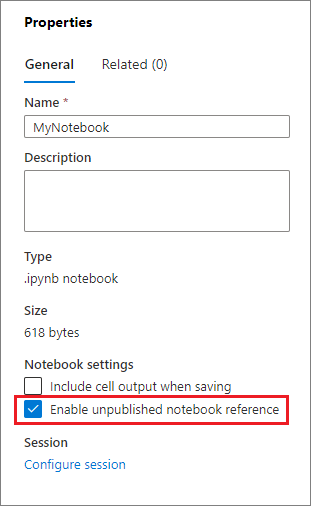
공개되지 않은 Notebook 참조
로컬에서 디버깅을 할 때 공개되지 않은 Notebook을 참조하는 것이 도움이 됩니다. 이 기능을 사용하도록 설정하면 Notebook 실행이 웹 캐시에 있는 현재 콘텐츠를 가져옵니다. 참조 Notebook 문이 포함된 셀을 실행하면 클러스터에 저장된 버전 대신 현재 Notebook 브라우저에서 표시된 Notebook을 참조하세요. 다른 Notebook은 변경 내용을 게시(라이브 모드)하거나 커밋(Git 모드)하지 않고도 Notebook 편집기에서 변경 내용을 참조할 수 있습니다. 이 방법을 사용하면 개발이나 디버깅 프로세스에서 공용 라이브러리의 오염을 방지할 수 있습니다.
속성 창에서 적절한 확인란을 선택하여 게시되지 않은 Notebook 참조를 사용하도록 설정할 수 있습니다.
다음 표에서는 사례를 비교합니다. %run 및 mssparkutils.notebook.run은 여기에서 동일한 동작을 하지만 표에서는 %run을 예로 사용합니다.
| 사례 | 사용 안 함 | 사용 |
|---|---|---|
| 라이브 모드 | ||
Nb1(게시됨) %run Nb1 |
게시된 Nb1 버전 실행 | 게시된 Nb1 버전 실행 |
Nb1(신규) %run Nb1 |
Error | 새 Nb1 실행 |
Nb1(이전에 게시됨, 편집됨) %run Nb1 |
게시된 Nb1 버전 실행 | 편집된 버전의 Nb1 실행 |
| Git 모드 | ||
Nb1(게시됨) %run Nb1 |
게시된 Nb1 버전 실행 | 게시된 Nb1 버전 실행 |
Nb1(신규) %run Nb1 |
Error | 새 Nb1 실행 |
Nb1(게시되지 않음, 커밋됨) %run Nb1 |
Error | 커밋된 Nb1 실행 |
Nb1(이전에 게시됨, 커밋됨) %run Nb1 |
게시된 Nb1 버전 실행 | 커밋된 버전의 Nb1 실행 |
Nb1(이전에 게시됨, 현재 분기의 새로운 기능) %run Nb1 |
게시된 Nb1 버전 실행 | 새 Nb1 실행 |
Nb1(게시되지 않음, 이전에 커밋됨, 편집됨) %run Nb1 |
Error | 편집된 버전의 Nb1 실행 |
Nb1(이전에 게시됨 및 커밋됨, 편집됨) %run Nb1 |
게시된 Nb1 버전 실행 | 편집된 버전의 Nb1 실행 |
요약하면 다음과 같습니다.
- 게시되지 않은 Notebook 참조를 사용하지 않도록 설정한 경우 항상 게시된 버전을 실행합니다.
- 게시되지 않은 Notebook 참조를 사용하도록 설정하면 참조 실행은 항상 Notebook UX에 나타나는 Notebook의 현재 버전을 채택합니다.
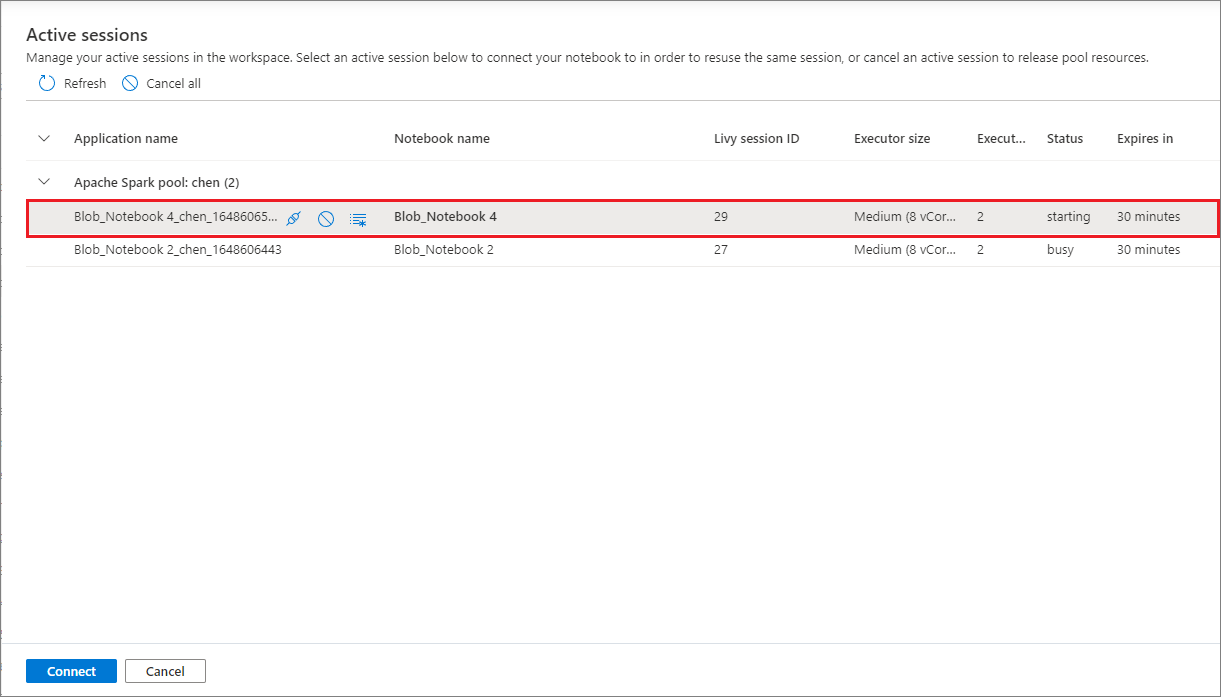
활성 세션 관리
새 Notebook 세션을 시작하지 않고도 기존 Notebook 세션을 다시 사용할 수 있습니다. Synapse Notebook에서는 활성 세션을 단일 목록에서 관리할 수 있습니다. 목록을 열려면 줄임표(...)를 선택한 다음 세션 관리를 선택합니다.
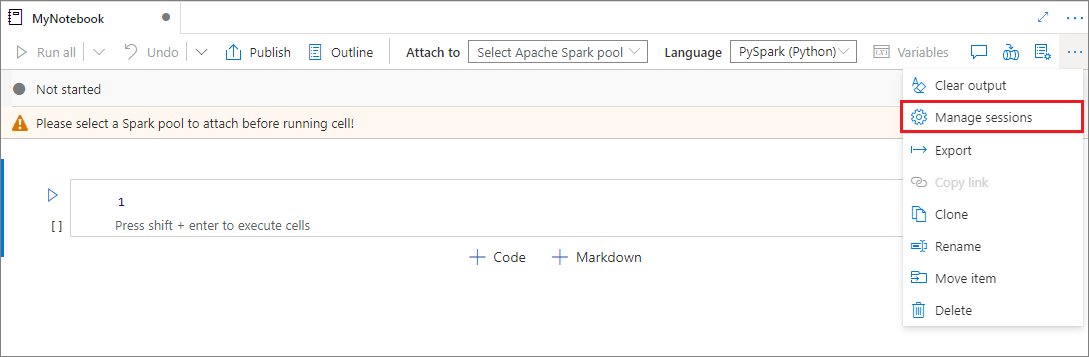
활성 세션 창에는 Notebook에서 시작한 현재 작업 영역의 모든 세션이 나열됩니다. 목록에는 세션 정보와 해당 Notebook이 표시됩니다. Notebook과 분리, 세션 중지 및 모니터링에서 보기 작업은 여기에서 사용할 수 있습니다. 또한, 선택한 Notebook을 다른 Notebook에서 시작된 활성 세션에 연결할 수 있습니다. 그러면 세션이 이전 Notebook에서 분리되고(유휴 상태가 아닌 경우) 현재 Notebook에 연결됩니다.
Notebook에서 Python 로그 사용
다음 샘플 코드를 사용하여 Python 로그를 찾고 다양한 로그 수준과 형식을 설정할 수 있습니다.
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize the log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# Logger that uses the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# Logger that uses the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
입력 명령 기록 보기
Synapse Notebook은 현재 세션의 입력 명령 기록을 출력하는 매직의 명령인 %history를 지원합니다. %history 매직 명령은 표준 Jupyter IPython 명령과 유사하며 Notebook의 여러 언어 컨텍스트에서 작동합니다.
%history [-n] [range [range ...]]
이전 코드에서 -n은 인쇄 실행 번호입니다. range 값은 다음이 될 수 있습니다.
N: 실행된Nth셀의 코드를 인쇄합니다.M-N:Mth에서 실행된 셀인Nth에 코드를 인쇄합니다.
예를 들어, 첫 번째 실행된 셀부터 두 번째 실행된 셀까지의 입력 내역을 출력하려면 %history -n 1-2를 사용합니다.
Notebook 통합
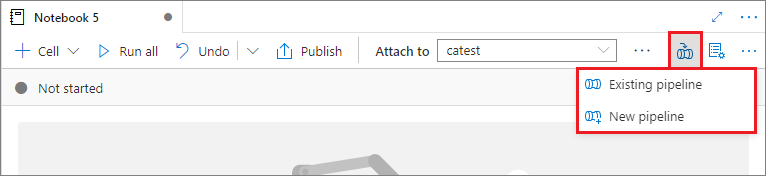
파이프라인에 Notebook 추가
기존 파이프라인에 Notebook을 추가하거나 새 파이프라인을 만들려면 오른쪽 상단 모서리에 있는 파이프라인에 추가 단추를 선택합니다.
매개 변수 셀 지정
Notebook을 매개 변수화하려면 줄임표(...)를 선택하여 셀 도구 모음에서 더 많은 명령에 액세스합니다. 그런 다음, 매개 변수 셀 설정/해제를 선택하여 셀을 매개 변수 셀로 지정합니다.
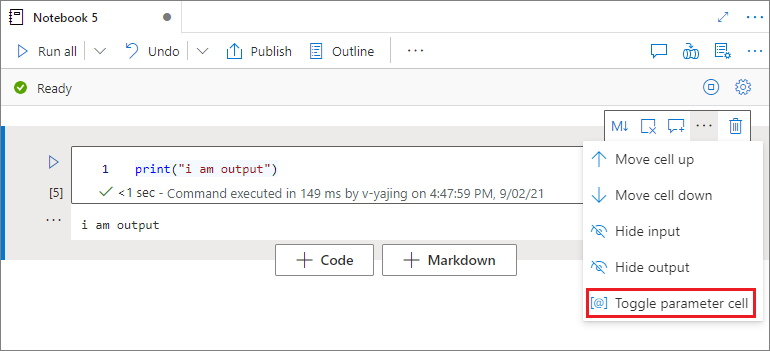
Azure Data Factory는 매개 변수 셀을 찾고 이 셀을 실행 시점에 전달된 매개 변수의 기본값으로 처리합니다. 실행 엔진은 매개 변수 셀 아래에 입력 매개 변수가 있는 새 셀을 추가하여 기본값을 덮어씁니다.
파이프라인에서 매개 변수 값 할당
매개 변수가 있는 Notebook을 만든 후에는 Synapse Notebook 작업을 사용하여 파이프라인에서 Notebook을 실행할 수 있습니다. 파이프라인 캔버스에 작업을 추가한 후 설정 탭의 기본 매개 변수 섹션에서 매개 변수 값을 설정할 수 있습니다.
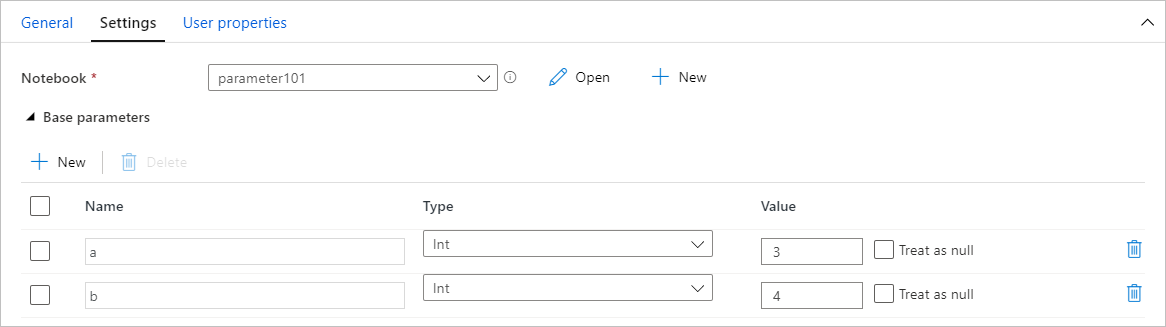
매개 변수 값을 할당할 때 파이프라인 식 언어 또는 시스템 변수를 사용할 수 있습니다.
바로 가기 키 사용
Jupyter Notebook과 마찬가지로 Synapse Notebook에는 모달 사용자 인터페이스가 있습니다. 키보드는 Notebook 셀이 있는 모드에 따라 다른 작업을 수행합니다. Synapse Notebook은 코드 셀에 대해 다음 두 가지 모드를 지원합니다.
명령 모드: 텍스트 커서가 입력을 요구하지 않을 때 셀은 명령 모드에 있습니다. 셀이 명령 모드에 있으면 Notebook을 전체적으로 편집할 수 있지만 개별 셀에는 입력할 수 없습니다. Esc 키를 선택하거나 마우스를 사용하여 셀의 편집기 영역 외부를 선택하면 명령 모드로 들어갑니다.

편집 모드: 셀이 편집 모드에 있으면 텍스트 커서가 나타나 셀에 입력하라는 메시지를 표시합니다. Enter 키를 선택하거나 마우스를 사용하여 셀의 편집기 영역을 선택하여 편집 모드로 들어갑니다.

명령 모드의 바로 가기 키
| 작업 | Synapse Notebook 바로 가기 |
|---|---|
| 현재 셀을 실행하고 아래 선택 | Shift+Enter |
| 현재 셀을 실행하고 아래에 삽입 | Alt+Enter |
| 현재 셀 실행 | Ctrl+Enter |
| 위 셀 선택 | 위로 |
| 아래 셀 선택 | 아래로 |
| 이전 셀 선택 | K |
| 다음 셀 선택 | J |
| 위에 셀 삽입 | A |
| 아래에 셀 삽입 | b |
| 선택한 셀 삭제 | Shift+D |
| 편집 모드로 전환 | Enter |
편집 모드의 바로 가기 키
| 작업 | Synapse Notebook 바로 가기 |
|---|---|
| 커서를 위로 이동 | 위로 |
| 커서를 아래로 이동 | 아래로 |
| 실행 취소 | Ctrl+Z |
| 다시 실행 | Ctrl+Y |
| 주석 처리/주석 처리 제거 | Ctrl+/ |
| 이전 단어 삭제 | Ctrl+Backspace |
| 다음 단어 삭제 | Ctrl+Delete |
| 셀 시작으로 이동 | Ctrl+Home |
| 셀 끝으로 이동 | Ctrl+End |
| 한 단어 왼쪽으로 이동 | Ctrl+왼쪽 화살표 |
| 한 단어 오른쪽으로 이동 | Ctrl+오른쪽 화살표 |
| 모두 선택 | Ctrl+A |
| 들여쓰기 | Ctrl+] |
| 내어쓰기 | Ctrl+[ |
| 명령 모드로 전환 | Esc |