이 자습서에서는 Azure Open Datasets 및 Apache Spark를 사용하여 예비 데이터 분석을 수행하는 방법을 알아봅니다. 그런 다음, Azure Synapse Analytics의 Synapse Studio Notebook에서 결과를 시각화할 수 있습니다.
특히 뉴욕시(NYC) 택시 데이터 세트를 분석합니다. 데이터는 Azure 공개 데이터 세트를 통해 사용할 수 있습니다. 이 데이터 세트의 하위 집합에는 각 이동에 대한 정보, 시작 및 종료 시간과 위치, 비용 및 기타 흥미로운 특성 등 노란색 택시 이동에 대한 정보가 포함되어 있습니다.
시작하기 전 주의 사항:
Apache Spark 풀 자습서 만들기를 따라 Apache Spark 풀을 생성하십시오.
데이터 다운로드 및 준비
PySpark 커널을 사용하여 Notebook을 만듭니다. 지침은 전자 필기장 만들기를 참조하세요.
메모
PySpark 커널로 인해 컨텍스트를 명시적으로 만들 필요가 없습니다. Spark 컨텍스트는 첫 번째 코드 셀을 실행할 때 자동으로 만들어집니다.
이 자습서에서는 데이터 세트를 시각화하는 데 도움이 되는 여러 라이브러리를 사용합니다. 이 분석을 수행하려면 다음 라이브러리를 가져옵니다.
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd원시 데이터는 Parquet 형식이므로 Spark 컨텍스트를 사용하여 파일을 DataFrame으로 직접 메모리로 끌어올 수 있습니다. Open Datasets API를 통해 데이터를 검색하여 Spark DataFrame을 만듭니다. 여기서는 읽기 속성에 Spark DataFrame 스키마 를 사용하여 데이터 형식 및 스키마를 유추합니다.
from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())데이터를 읽은 후 데이터 세트를 정리하기 위해 몇 가지 초기 필터링을 수행하려고 합니다. 불필요한 열을 제거하고 중요한 정보를 추출하는 열을 추가할 수 있습니다. 또한 데이터 세트 내의 변칙을 필터링합니다.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
데이터 분석
데이터 분석가는 데이터에서 인사이트를 추출하는 데 도움이 되는 다양한 도구를 사용할 수 있습니다. 자습서의 이 부분에서는 Azure Synapse Analytics Notebook 내에서 사용할 수 있는 몇 가지 유용한 도구를 살펴보겠습니다. 이 분석에서는 선택한 기간 동안 더 높은 택시 팁을 생성하는 요인을 이해하려고 합니다.
Apache Spark SQL 매직
먼저 Azure Synapse Notebook을 사용하여 Apache Spark SQL 및 매직 명령을 통해 예비 데이터 분석을 수행합니다. 쿼리가 완료되면 기본 제공 chart options 기능을 사용하여 결과를 시각화합니다.
Notebook 내에서 새 셀을 만들고 다음 코드를 복사합니다. 이 쿼리를 사용하여 선택한 기간 동안 평균 팁 금액이 어떻게 변경되었는지 이해하려고 합니다. 또한 이 쿼리는 일일 최소/최대 팁 금액 및 평균 요금 금액을 포함하여 다른 유용한 인사이트를 식별하는 데 도움이 됩니다.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASC쿼리 실행이 완료되면 차트 보기로 전환하여 결과를 시각화할 수 있습니다. 이 예에서는
day_of_month필드를 키로 지정하고 값으로avgTipAmount을(를) 지정하여 꺾은선형 차트를 만듭니다. 선택한 후 적용 을 선택하여 차트를 새로 고칩니다.
데이터 시각화
기본 제공 Notebook 차트 옵션 외에도, 인기 있는 오픈 소스 라이브러리를 사용하여 사용자만의 시각화를 만들 수 있습니다. 다음 예제에서는 Seaborn 및 Matplotlib를 사용합니다. 데이터 시각화에 일반적으로 사용되는 Python 라이브러리입니다.
메모
기본적으로 Azure Synapse Analytics의 모든 Apache Spark 풀에는 일반적으로 사용되는 기본 라이브러리 집합이 포함되어 있습니다. Azure Synapse 런타임 설명서에서 라이브러리의 전체 목록을 볼 수 있습니다. 또한 타사 또는 로컬로 빌드된 코드를 애플리케이션에서 사용할 수 있도록 하기 위해 Spark 풀 중 하나에 라이브러리를 설치 할 수 있습니다.
개발을 더 쉽고 저렴하게 만들기 위해 데이터 세트를 다운샘플링합니다. 기본 제공 Apache Spark 샘플링 기능을 사용합니다. 또한 Seaborn 및 Matplotlib 모두 Pandas DataFrame 또는 NumPy 배열이 필요합니다. Pandas DataFrame을 얻으려면
toPandas()명령을 사용하여 DataFrame을 변환합니다.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()데이터 세트의 팁 배포를 이해하려고 합니다. Matplotlib을 사용하여 팁 양과 개수의 분포를 보여 주는 히스토그램을 만듭니다. 분포에 따라 팁이 $10보다 작거나 같은 금액으로 기울어진 것을 볼 수 있습니다.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()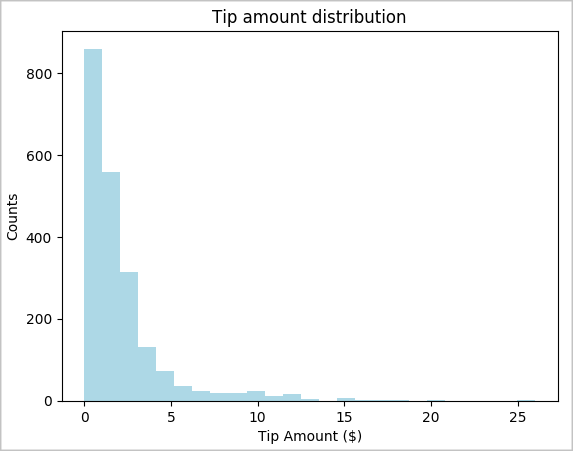
다음으로, 지정된 여행에 대한 팁과 요일 간의 관계를 이해하려고 합니다. Seaborn을 사용하여 각 요일의 추세를 요약하는 상자 플롯을 만듭니다.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()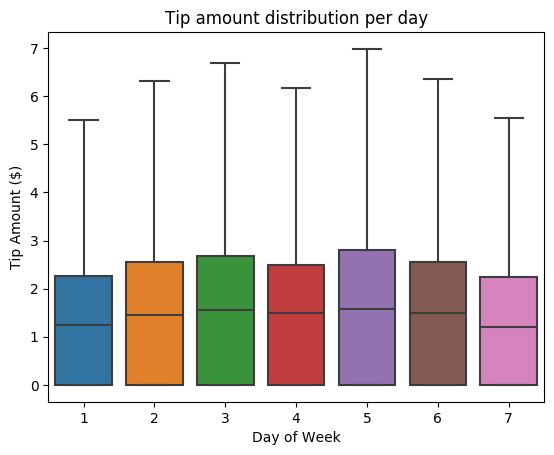
우리의 또 다른 가설은 승객 수와 총 택시 팁 금액 사이에 긍정적 인 관계가 있다는 것입니다. 이 관계를 확인하려면 다음 코드를 실행하여 각 승객 수에 따른 팁 분포를 보여주는 상자 플롯을 생성합니다.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()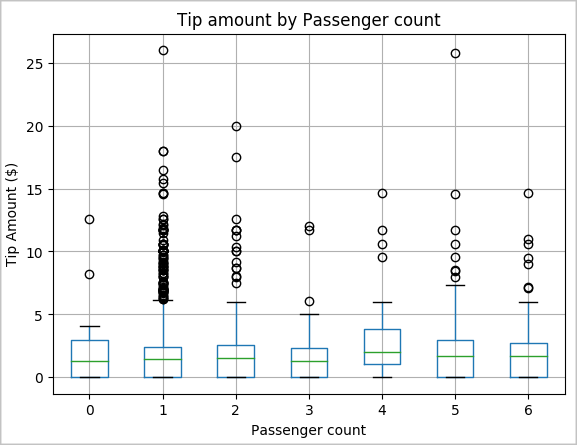
마지막으로, 요금 금액과 팁 금액 간의 관계를 이해하려고 합니다. 결과에 따라 사람들이 팁을 주지 않는 몇 가지 관찰이 있음을 알 수 있습니다. 그러나 전체 요금과 팁 금액 간에도 긍정적인 관계가 있습니다.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()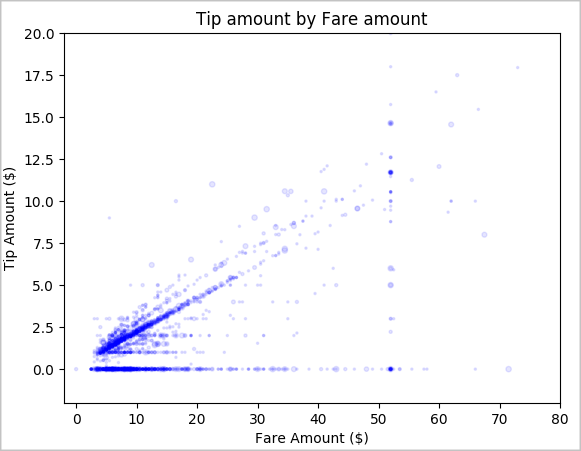
Spark 인스턴스 종료
애플리케이션 실행을 완료한 후 Notebook을 종료하여 리소스를 해제합니다. 탭을 닫거나 전자 필기장 아래쪽의 상태 패널에서 세션 종료 를 선택합니다.