Red Hat Enterprise Linux에 배포된 SAP HANA 스케일 아웃 시스템의 고가용성
이 문서에서는 스케일 아웃 구성에서 고가용성 SAP HANA 시스템을 배포하는 방법을 설명합니다. 특히 이 구성은 Azure Red Hat Enterprise Linux VM(가상 머신)에서 HSR(HANA 시스템 복제) 및 Pacemaker를 사용합니다. 제시된 아키텍처의 공유 파일 시스템은 NFS 탑재이며 Azure NetApp Files 또는 Azure Files의 NFS 공유에서 제공됩니다.
예제 구성, 설치 명령 등에서 HANA 인스턴스는 03이고 HANA 시스템 ID는 HN1입니다.
필수 조건
일부 독자는 이 문서의 주제를 계속 진행하기 전에 다양한 SAP Note 및 리소스를 참조하는 것이 좋습니다.
- SAP Note 1928533에는 다음이 포함되어 있습니다.
- SAP 소프트웨어 배포에 지원되는 Azure VM 크기 목록
- Azure VM 크기에 대한 중요한 용량 정보.
- 지원되는 SAP 소프트웨어 및 운영 체제와 데이터베이스 조합
- Microsoft Azure에서 Windows 및 Linux에 필요한 SAP 커널 버전.
- SAP Note 2015553: Azure에서 SAP를 지원하는 SAP 소프트웨어 배포에 대한 필수 구성 요소를 나열합니다.
- SAP Note [2002167]: RHEL에 대한 권장 운영 체제 설정이 있습니다.
- SAP Note 2009879: RHEL에 대한 SAP HANA 지침이 있습니다.
- SAP Note 3108302에는 Red Hat Enterprise Linux 9.x용 SAP HANA 지침이 있습니다.
- SAP Note 2178632: Azure에서 SAP에 대해 보고된 모든 모니터링 메트릭에 대한 자세한 정보가 포함되어 있습니다.
- SAP Note 2191498: Azure에서 Linux에 필요한 SAP 호스트 에이전트 버전이 포함되어 있습니다.
- SAP Note: 2243692: Azure에서 Linux의 SAP 라이선스에 대한 정보가 포함되어 있습니다.
- SAP Note 1999351: SAP용 Azure 향상된 모니터링 확장에 대한 추가 문제 해결 정보가 포함되어 있습니다.
- SAP Note 1900823: SAP HANA 스토리지 요구 사항에 대한 정보가 포함되어 있습니다.
- SAP Community Wiki: Linux에 필요한 모든 SAP Note가 포함되어 있습니다.
- Linux에서 SAP용 Azure Virtual Machines 계획 및 구현.
- Linux에서 SAP용 Azure Machines 배포
- Linux에서 SAP용 Azure Virtual Machines DBMS 배포
- SAP HANA 네트워크 요구 사항
- 일반 RHEL 설명서:
- Azure 특정 RHEL 설명서:
- Azure NetApp Files 설명서
- SAP HANA용 Azure NetApp Files의 NFS v4.1 볼륨
- Azure Files 설명서
개요
HANA 스케일 아웃 설치용 HANA 고가용성을 달성하려면 HANA 시스템 복제를 구성하고 Pacemaker 클러스터로 솔루션을 보호하여 자동 장애 조치(failover)를 허용하면 됩니다. 활성 노드에 오류가 발생하면 클러스터는 HANA 리소스를 다른 사이트로 장애 조치(failover)합니다.
다음 다이어그램에는 각 사이트에 3개의 HANA 노드가 있고 "분할 브레인" 시나리오를 방지하기 위한 주 결정자 노드가 있습니다. HANA DB 노드로 VM을 더 포함하도록 지침을 수정할 수 있습니다.
제시된 아키텍처의 HANA 공유 파일 시스템 /hana/shared는 Azure NetApp Files 또는 Azure Files의 NFS 공유에서 제공할 수 있습니다. HANA 공유 파일 시스템은 동일한 HANA 시스템 복제 사이트의 각 HANA 노드에 NFS 탑재됩니다. 파일 시스템 /hana/data 이며 /hana/log 로컬 파일 시스템이며 HANA DB 노드 간에 공유되지 않습니다. SAP HANA는 비공유 모드로 설치됩니다.
권장 SAP HANA 저장소 구성은 SAP HANA Azure VM 저장소 구성을 참조하세요.
Important
성능이 핵심인 프로덕션 시스템의 경우 Azure NetApp Files에 모든 HANA 파일 시스템을 배포하는 경우 SAP HANA용 Azure NetApp Files 애플리케이션 볼륨 그룹을 평가하고 사용하는 것이 좋습니다.

위의 다이어그램에서 3개의 서브넷은 단일 Azure 가상 네트워크 내에 표시되며, SAP HANA 네트워크 권장 사항을 따릅니다.
- 클라이언트 통신의 경우:
client10.23.0.0/24 - 내부 HANA 노드 간 통신의 경우:
inter10.23.1.128/26 - HANA 시스템 복제의 경우:
hsr10.23.1.192/26
/hana/data 및 /hana/log는 로컬 디스크에 배포되기 때문에 스토리지와 통신하기 위해 별도의 서브넷 및 별도의 가상 네트워크 카드를 배포할 필요가 없습니다.
Azure NetApp Files를 사용하는 경우 NFS 볼륨 /hana/shared은 별도의 서브넷 에 배포되고 Azure NetApp Files: anf 10.23.1.0/26에 위임됩니다.
인프라 설정
다음 지침에서는 리소스 그룹, 즉 3개의 Azure 네트워크 서브넷 client, inter 및 hsr가 있는 Azure 가상 네트워크를 만들었다고 가정합니다.
Azure Portal을 통한 Linux 가상 머신 배포
Azure VM을 배포합니다. 이 구성의 경우 7개의 가상 머신을 배포합니다.
- HANA 복제 사이트 1용 HANA DB 노드로 사용될 가상 머신 3개: hana-s1-db1, hana-s1-db2 및 hana-s1-db3
- HANA 복제 사이트 2용 HANA DB 노드로 사용될 가상 머신 3개: hana-s2-db1, hana-s2-db2 및 hana-s2-db3
- 주 결정자 역할을 하는 작은 가상 머신: hana-s-mm
SAP DB HANA 노드로 배포된 VM은 SAP HANA 하드웨어 디렉터리에 게시된 대로 SAP에서 HANA용으로 인증해야 합니다. HANA DB 노드를 배포할 때는 가속화된 네트워크를 선택해야 합니다.
주 결정자 노드는 이 VM이 SAP HANA 리소스를 실행하지 않기 때문에 작은 VM을 배포할 수 있습니다. 주 결정자 VM은 분할 브레인 시나리오에서 홀수 클러스터 노드를 얻기 위해 클러스터 구성에 사용됩니다. 이 예제에서는 주 결정자 VM이
client서브넷에서 하나의 가상 네트워크 인터페이스만 필요로 합니다./hana/data및/hana/log용 로컬 관리 디스크를 배포합니다./hana/data및/hana/log의 최소 권장 스토리지 구성에 관한 설명이 SAP HANA Azure VM 스토리지 구성에 나옵니다.client가상 네트워크 서브넷의 각 VM별 기본 네트워크 인터페이스를 배포합니다. Azure Portal을 통해 VM을 배포하는 경우 네트워크 인터페이스 이름이 자동으로 생성됩니다. 이 문서에서는 자동으로 생성된 기본 네트워크 인터페이스를 hana-s1-db1-client, hana-s1-db2-client, hana- s1-db3-client 등으로 지칭합니다. 이러한 네트워크 인터페이스는clientAzure 가상 네트워크 서브넷에 연결됩니다.Important
선택하는 운영 체제가 사용 중인 특정 VM 유형에서 SAP HANA용으로 인증된 SAP인지 확인하세요. SAP HANA 인증 VM 유형과 이러한 유형의 운영 체제 릴리스 목록은 SAP HANA 인증 IaaS 플랫폼 사이트에서 확인할 수 있습니다. 특정 유형의 SAP HANA 지원 OS 릴리스 전체 목록을 보려면 목록에 있는 VM 유형의 세부 정보를 살펴보세요.
inter가상 네트워크 서브넷에 HANA DB 가상 머신마다 하나씩 총 6개의 네트워크 인터페이스를 만듭니다(이 예에서는 hana-s1-db1-inter, hana-s1-db2-inter, hana-s1-db3-inter, hana-s2-db1-inter, hana-s2-db2-inter, hana-s2-db3-inter).hsr가상 네트워크 서브넷에 HANA DB 가상 머신마다 하나씩 총 6개의 네트워크 인터페이스를 만듭니다(이 예에서는 hana-s1-db1-hsr, hana-s1-db2-hsr, hana-s1-db3-hsr, hana-s2-db1-hsr, hana-s2-db2-hsr, hana-s2-db3-hsr).새로 만든 가상 네트워크 인터페이스를 해당 가상 머신에 연결합니다.
- Azure Portal에서 가상 머신으로 이동합니다.
- 왼쪽 창에서 Virtual Machines를 선택합니다. 가상 머신 이름(예: hana-s1-db1)을 필터링한 다음, 가상 머신을 선택합니다.
- 개요 창에서 중지를 선택하여 가상 머신의 할당을 취소합니다.
- 네트워킹을 선택하고 네트워크 인터페이스를 연결합니다. 네트워크 인터페이스 연결 드롭다운 목록에서
inter및hsr서브넷용으로 이미 생성된 네트워크 인터페이스를 선택합니다. - 저장을 선택합니다.
- 재기본 가상 머신에 대해 e단계를 반복합니다(예: hana-s1-db2, hana-s1-db3, hana-s2-db1, hana-s2-db2 및 hana-s2-db3).
- 지금은 가상 머신을 중지 상태로 둡니다.
다음을 수행하여
inter및hsr서브넷의 추가 네트워크 인터페이스에 가속화된 네트워킹을 사용하도록 설정합니다.Azure Portal에서 Azure Cloud Shell을 엽니다.
다음 명령을 실행하여
inter및hsr서브넷에 연결된 추가 네트워크 인터페이스에 가속화된 네트워킹을 사용하도록 설정합니다.az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-hsr --accelerated-networking true
HANA DB 가상 머신을 시작합니다.
Azure Load Balancer 구성
VM 구성 중에 네트워킹 섹션에서 기존 부하 분산 장치를 만들거나 선택할 수 있는 옵션이 있습니다. HANA 데이터베이스의 고가용성 설정을 위해 표준 Load Balancer를 설정하려면 아래 단계를 따릅니다.
참고 항목
- HANA 스케일 아웃의 경우 백 엔드 풀에 가상 머신을
client추가할 때 서브넷에 대한 NIC를 선택합니다. - Azure CLI 및 PowerShell의 전체 명령 집합은 백 엔드 풀에 기본 NIC가 있는 VM을 추가합니다.
- Azure Portal
- Azure CLI
- PowerShell
Azure Portal을 사용하여 고가용성 SAP 시스템에 대한 표준 부하 분산 장치를 설정하려면 부하 분산 장치 만들기의 단계를 따릅니다. 부하 분산 장치를 설정하는 동안 다음 사항을 고려합니다.
- 프런트 엔드 IP 구성: 프런트 엔드 IP를 만듭니다. 데이터베이스 가상 머신과 동일한 가상 네트워크 및 서브넷 이름을 선택합니다.
- 백 엔드 풀: 백 엔드 풀을 만들고 데이터베이스 VM을 추가합니다.
- 인바운드 규칙: 부하 분산 규칙을 만듭니다. 두 부하 분산 규칙에 대해 동일한 단계를 수행합니다.
- 프런트 엔드 IP 주소: 프런트 엔드 IP를 선택합니다.
- 백 엔드 풀: 백 엔드 풀을 선택합니다.
- 고가용성 포트: 이 옵션을 선택합니다.
- 프로토콜: TCP를 선택합니다.
- 상태 프로브: 다음 세부 정보를 사용하여 상태 프로브를 만듭니다.
- 프로토콜: TCP를 선택합니다.
- 포트: 예를 들어 인스턴스 가 625<개입니다>.
- 간격: 5를 입력 합니다.
- 프로브 임계값: 2를 입력합니다.
- 유휴 시간 제한(분): 30을 입력합니다.
- 부동 IP 사용: 이 옵션을 선택합니다.
참고 항목
포털에서 비정상 임계값이라고도 하는 상태 프로브 구성 속성numberOfProbes은 적용되지 않습니다. 성공 또는 실패한 연속 프로브 수를 제어하려면 속성을 probeThreshold2.로 설정합니다. 현재 Azure Portal을 사용하여 이 속성을 설정할 수 없으므로 Azure CLI 또는 PowerShell 명령을 사용합니다.
Important
부동 IP는 부하 분산 시나리오의 NIC 보조 IP 구성에서 지원되지 않습니다. 자세한 내용은 Azure Load Balancer 제한 사항을 참조하세요. VM에 대한 추가 IP 주소가 필요한 경우 두 번째 NIC를 배포합니다.
참고 항목
표준 부하 분산 장치를 사용하는 경우 다음과 같은 제한 사항을 알고 있어야 합니다. 내부 부하 분산 장치의 백 엔드 풀에 공용 IP 주소가 없는 VM을 배치하면 아웃바운드 인터넷이 연결되지 않습니다. 퍼블릭 엔드포인트에 대한 라우팅을 허용하려면 추가 구성을 수행해야 합니다. 자세한 내용은 SAP 고가용성 시나리오에서 Azure Standard Load Balancer를 사용하는 가상 머신에 대한 퍼블릭 엔드포인트 연결을 참조하세요.
Important
Azure Load Balancer 뒤에 배치되는 Azure VM에서 TCP 타임스탬프를 사용하도록 설정하면 안 됩니다. TCP 타임스탬프를 사용하도록 설정하면 상태 프로브에 오류가 발생합니다. net.ipv4.tcp_timestamps 매개 변수를 0으로 설정합니다. 자세한 내용은 Load Balancer 상태 프로브 및 SAP Note 2382421을 참조하세요.
NFS 배포
/hana/shared에 대한 Azure 네이티브 NFS 배포에는 두 가지 옵션이 있습니다. Azure NetApp Files 또는 Azure Files의 NFS 공유에 NFS 볼륨을 배포할 수 있습니다. Azure 파일은 NFSv4.1 프로토콜을 지원하며, Azure NetApp 파일의 NFS는 NFSv4.1 및 NFSv3을 모두 지원합니다.
다음 섹션에서는 NFS를 배포하는 단계에 대해 설명합니다. 옵션 중 하나만 선택해야 합니다.
팁
Azure Files의 NFS 공유 또는 Azure NetApp Files의 NFS 볼륨에 /hana/shared를 배포하도록 선택했습니다.
Azure NetApp Files 인프라 배포
/hana/shared 파일 시스템에 대한 Azure NetApp Files 볼륨을 배포합니다. HANA 시스템 복제 사이트마다 별도의 /hana/shared 볼륨이 필요합니다. 자세한 내용은 Azure NetApp Files 인프라 설정을 참조하세요.
이 예제에서는 다음과 같은 Azure NetApp Files 볼륨을 사용합니다.
- 볼륨 HN1-shared-s1(nfs://10.23.1.7/HN1-shared-s1)
- 볼륨 HN1-shared-s2(nfs://10.23.1.7/HN1-shared-s2)
Azure Files의 NFS 인프라 배포
/hana/shared 파일 시스템에 대한 Azure Files NFS 공유를 배포합니다. 각 HANA 시스템 복제본(replica) 사이트에 대해 별도의 /hana/shared Azure Files NFS 공유가 필요합니다. 자세한 내용은 NFS 공유를 만드는 방법을 참조하세요.
이 예에서는 다음 Azure Files NFS 공유가 사용되었습니다.
- hn1-shared-s1 공유(sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1)
- hn1-shared-s2 공유(sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2)
운영 체제 구성 및 준비
다음 섹션의 지침에는 다음 약어 중 하나가 접두사로 추가됩니다.
- [A]: 모든 노드에 적용 가능
- [AH]: 모든 HANA DB 노드에 적용 가능
- [M]: 주 결정자 노드에 적용 가능
- [AH1]: SITE 1의 모든 HANA DB 노드에 적용 가능
- [AH2]: SITE 2의 모든 HANA DB 노드에 적용 가능
- [1]: SITE 1의 HANA DB 노드 1에만 적용 가능
- [2]: SITE 2의 HANA DB 노드 1에만 적용 가능
다음을 수행하여 운영 체제를 구성하고 준비합니다.
[A] 가상 머신에서 호스트 파일을 유지 관리합니다. 모든 서브넷에 대한 항목을 포함합니다. 이 예제에서는 다음 항목이
/etc/hosts에 추가됩니다.# Client subnet 10.23.0.11 hana-s1-db1 10.23.0.12 hana-s1-db1 10.23.0.13 hana-s1-db2 10.23.0.14 hana-s2-db1 10.23.0.15 hana-s2-db2 10.23.0.16 hana-s2-db3 10.23.0.17 hana-s-mm # Internode subnet 10.23.1.138 hana-s1-db1-inter 10.23.1.139 hana-s1-db2-inter 10.23.1.140 hana-s1-db3-inter 10.23.1.141 hana-s2-db1-inter 10.23.1.142 hana-s2-db2-inter 10.23.1.143 hana-s2-db3-inter # HSR subnet 10.23.1.202 hana-s1-db1-hsr 10.23.1.203 hana-s1-db2-hsr 10.23.1.204 hana-s1-db3-hsr 10.23.1.205 hana-s2-db1-hsr 10.23.1.206 hana-s2-db2-hsr 10.23.1.207 hana-s2-db3-hsr[A] Azure용 Microsoft 구성 설정을 사용하여 구성 파일 /etc/sysctl.d/ms-az.conf 를 만듭니다.
vi /etc/sysctl.d/ms-az.conf # Add the following entries in the configuration file net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10팁
SAP 호스트 에이전트가 포트 범위를 관리할 수 있도록
sysctl구성 파일에서net.ipv4.ip_local_port_range및net.ipv4.ip_local_reserved_ports를 명시적으로 설정하지 마세요. 자세한 내용은 SAP Note 2382421을 참조하세요.[A] NFS 클라이언트 패키지를 설치합니다.
yum install nfs-utils[AH] HANA 구성을 위한 Red Hat입니다.
Red Hat 고객 포털 및 다음 SAP Note에 설명된 대로 RHEL을 구성합니다.
파일 시스템 준비
다음 섹션에서는 파일 시스템을 준비하는 단계를 제공합니다. Azure Files의 NFS 공유 또는 Azure NetApp Files의 NFS 볼륨에 /hana/shared'를 배포하도록 선택했습니다.
공유 파일 시스템 탑재(Azure NetApp Files NFS)
이 예에서는 공유 HANA 파일 시스템이 Azure NetApp Files에 배포되고 NFSv4.1을 통해 탑재됩니다. Azure NetApp Files에서 NFS를 사용하는 경우에만 이 섹션의 단계를 따릅니다.
[AH] NFS를 사용하여 NetApp Systems에서 SAP HANA를 실행하기 위한 OS를 준비합니다. SAP 참고 3024346 - NetApp NFS용 Linux 커널 설정 설명합니다. NetApp 구성 설정에 대한 구성 파일 /etc/sysctl.d/91-NetApp-HANA.conf를 만듭니다.
vi /etc/sysctl.d/91-NetApp-HANA.conf # Add the following entries in the configuration file net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[AH] SAP note 3024346 - NetApp NFS용 Linux 커널 설정 권장되는 대로 sunrpc 설정을 조정합니다.
vi /etc/modprobe.d/sunrpc.conf # Insert the following line options sunrpc tcp_max_slot_table_entries=128[AH] HANA 데이터베이스 볼륨의 탑재 지점을 만듭니다.
mkdir -p /hana/shared[AH] NFS 도메인 설정을 확인합니다. 도메인이 기본 Azure NetApp Files 도메인
defaultv4iddomain.com으로 구성되어 있는지 확인합니다. 매핑이nobody로 설정되어 있는지 확인합니다.
(이 단계는 Azure NetAppFiles NFS v4.1을 사용하는 경우에만 필요합니다.)Important
VM의
/etc/idmapd.conf에서 NFS 도메인을 Azure NetApp Files의 기본 도메인 구성(defaultv4iddomain.com)과 일치하도록 설정해야 합니다. NFS 클라이언트의 도메인 구성과 NFS 서버가 일치하지 않는 경우 VM에 탑재된 Azure NetApp 볼륨의 파일에 대한 사용 권한이nobody로 표시됩니다.sudo cat /etc/idmapd.conf # Example [General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobody[AH]
nfs4_disable_idmapping을 확인합니다.Y로 설정되어야 합니다.nfs4_disable_idmapping이 있는 디렉터리 구조를 만들려면 mount 명령을 실행합니다. 커널 또는 드라이버용으로 액세스가 예약되어 있기 때문에 /sys/modules 아래에 디렉터리를 수동으로 만들 수 없습니다.
이 단계는 Azure NetAppFiles NFSv 4.1을 사용하는 경우에만 필요합니다.# Check nfs4_disable_idmapping cat /sys/module/nfs/parameters/nfs4_disable_idmapping # If you need to set nfs4_disable_idmapping to Y mkdir /mnt/tmp mount 10.9.0.4:/HN1-shared /mnt/tmp umount /mnt/tmp echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping # Make the configuration permanent echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.confnfs4_disable_idmapping매개 변수를 변경하는 방법에 대한 자세한 내용은 Red Hat 고객 포털을 참조하세요.[AH1] SITE1 HANA DB VM에 공유 Azure NetApp Files 볼륨을 탑재합니다.
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s1 /hana/shared[AH2] SITE2 HANA DB VM에 공유 Azure NetApp Files 볼륨을 탑재합니다.
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s2 /hana/shared[AH] 해당
/hana/shared/파일 시스템이 NFS 프로토콜 버전 NFSv4를 사용하는 모든 HANA DB VM에 탑재되어 있는지 확인합니다.sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7
공유 파일 시스템 탑재(Azure Files NFS)
이 예에서 공유 HANA 파일 시스템은 Azure Files의 NFS에 배포됩니다. Azure Files에서 NFS를 사용하는 경우에만 이 섹션의 단계를 따릅니다.
[AH] HANA 데이터베이스 볼륨의 탑재 지점을 만듭니다.
mkdir -p /hana/shared[AH1] SITE1 HANA DB VM에 공유 Azure NetApp Files 볼륨을 탑재합니다.
sudo vi /etc/fstab # Add the following entry sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount all volumes sudo mount -a[AH2] SITE2 HANA DB VM에 공유 Azure NetApp Files 볼륨을 탑재합니다.
sudo vi /etc/fstab # Add the following entries sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount the volume sudo mount -a[AH] 해당
/hana/shared/파일 시스템이 NFS 프로토콜 버전 NFSv4.1을 사용하는 모든 HANA DB VM에 탑재되어 있는지 확인합니다.sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
데이터 및 로그 로컬 파일 시스템 준비
제시된 구성에서는 관리 디스크에 파일 시스템 /hana/data 및 /hana/log를 배포하고 이러한 파일 시스템을 각 HANA DB VM에 로컬로 연결합니다. 다음 단계를 실행하여 각 HANA DB 가상 머신에 로컬 데이터 및 로그 볼륨을 만듭니다.
LVM(논리 볼륨 관리자)을 사용하여 디스크 레이아웃을 설정합니다. 다음 예제에서는 각 HANA 가상 머신에 3개의 데이터 디스크가 연결되어 있고, 이러한 디스크를 사용하여 2개의 볼륨을 만든다고 가정합니다.
[AH] 사용 가능한 모든 디스크를 나열합니다.
ls /dev/disk/azure/scsi1/lun*예제 출력:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2[AH] 사용하려는 모든 디스크의 물리적 볼륨을 만듭니다.
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2[AH] 데이터 파일에 대한 볼륨 그룹을 만듭니다. 로그 파일에 대해 한 볼륨 그룹, SAP HANA의 공유 디렉터리에 대해 한 볼륨을 사용합니다.
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2[AH] 논리 볼륨을 만듭니다.
-i스위치 없이lvcreate를 사용하는 경우 선형 볼륨이 만들어집니다. 더 나은 I/O 성능을 위해 스트라이프 볼륨을 만드는 것이 좋습니다. 스트라이프 크기를 SAP HANA VM 스토리지 구성에 설명된 값에 맞춥니다.-i인수는 기본 실제 볼륨의 수여야 하며-I인수는 스트라이프 크기입니다. 이 문서에서는 2개의 실제 볼륨이 데이터 볼륨에 사용되므로-i스위치 인수가2로 설정됩니다. 데이터 볼륨의 스트라이프 크기는256 KiB입니다. 하나의 실제 볼륨이 로그 볼륨에 사용되므로 로그 볼륨 명령에 명시적인-i또는-I스위치를 사용할 필요가 없습니다.Important
각 데이터 또는 로그 볼륨에 대해 하나 이상의 실제 볼륨을 사용하는 경우
-i스위치를 사용하고 기본 실제 볼륨 수로 설정합니다. 스트라이프 볼륨을 만들 때-I스위치를 사용하여 스트라이프 크기를 지정합니다. 스트라이프 크기 및 디스크 수를 비롯한 권장되는 스토리지 구성은 SAP HANA VM 스토리지 구성을 참조하세요.sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log[AH] 탑재 디렉터리를 만들고 모든 논리 볼륨의 UUID를 복사합니다.
sudo mkdir -p /hana/data/HN1 sudo mkdir -p /hana/log/HN1 # Write down the ID of /dev/vg_hana_data_HN1/hana_data and /dev/vg_hana_log_HN1/hana_log sudo blkid[AH] 논리 볼륨에 대한
fstab항목을 만들고 탑재합니다.sudo vi /etc/fstab/etc/fstab파일에서 다음 줄을 삽입합니다./dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_data_HN1-hana_data /hana/data/HN1 xfs defaults,nofail 0 2 /dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_log_HN1-hana_log /hana/log/HN1 xfs defaults,nofail 0 2새 볼륨을 탑재합니다.
sudo mount -a
설치
이 예제에서는 Azure VM에서 HSR을 사용하여 스케일 아웃 구성에 SAP HANA를 배포하기 위해 HANA 2.0 SP4를 사용했습니다.
HANA 설치 준비
[AH] HANA 설치 전에 루트 암호를 설정합니다. 설치가 완료된 후 루트 암호를 사용하지 않도록 설정할 수 있습니다.
root명령passwd으로 실행하여 암호를 설정합니다.[1,2]
/hana/shared의 사용 권한을 변경합니다.chmod 775 /hana/shared[1] 암호를 묻는 메시지를 표시하지 않고도 SSH(보안 셸)를 통해 hana-s1-db2 및 hana-s1-db3에 로그인할 수 있는지 확인합니다. 이에 해당하지 않으면 키 기반 인증 사용에 설명된 대로
ssh키를 교환합니다.ssh root@hana-s1-db2 ssh root@hana-s1-db3[2] 암호를 묻는 메시지를 표시하지 않고도 SSH를 통해 hana-s2-db2 및 hana-s2-db3에 로그인할 수 있는지 확인합니다. 이에 해당하지 않으면 키 기반 인증 사용에 설명된 대로
ssh키를 교환합니다.ssh root@hana-s2-db2 ssh root@hana-s2-db3[AH] HANA 2.0 SP4에 필요한 추가 패키지를 설치합니다. 자세한 내용은 RHEL 7에 대한 SAP 노트 2593824를 참조하세요.
# If using RHEL 7 yum install libgcc_s1 libstdc++6 compat-sap-c++-7 libatomic1 # If using RHEL 8 yum install libatomic libtool-ltdl.x86_64[A] HANA 설치를 방해하지 않도록 방화벽을 일시적으로 사용하지 않도록 설정합니다. HANA 설치가 완료된 후 다시 사용하도록 설정할 수 있습니다.
# Execute as root systemctl stop firewalld systemctl disable firewalld
각 사이트의 첫 번째 노드에 HANA 설치
[1]SAP HANA 2.0 설치 및 업데이트 가이드의 지침에 따라 SAP HANA를 설치합니다. 다음 지침에서는 SITE 1의 첫 번째 노드에 SAP HANA를 설치하는 방법을 보여 줍니다.
hdblcm프로그램을 HANA 설치 소프트웨어 디렉터리의root로 시작합니다.internal_network매개 변수를 사용하고, 내부 HANA 노드 간 통신에 사용되는 서브넷의 주소 공간을 전달합니다../hdblcm --internal_network=10.23.1.128/26프롬프트에서 다음 값을 입력합니다.
- 작업 선택에 1(설치하는 경우)을 입력합니다.
- 설치할 추가 구성 요소에 2, 3을 입력합니다.
- 설치 경로에서 Enter 키(기본 경로: /hana/shared)를 누릅니다.
- 로컬 호스트 이름에서 Enter 키를 눌러 기본값을 적용합니다.
- 시스템에 호스트를 추가하시겠습니까?에 n을 입력합니다.
- SAP HANA 시스템 ID에 HN1을 입력합니다.
- 인스턴스 번호 [00]에 03을 입력합니다.
- 로컬 호스트 작업자 그룹 [기본값]에 Enter 키를 눌러 기본값을 적용합니다.
- 시스템 사용량 선택/인덱스 입력 [4]에 4를 입력합니다(사용자 지정의 경우).
- 데이터 볼륨의 위치 [/hana/data/HN1]에서 Enter 키를 눌러 기본값을 적용합니다.
- 로그 볼륨의 위치 [/hana/log/HN1]에서 Enter 키를 눌러 기본값을 적용합니다.
- 최대 메모리 할당을 제한하시겠습니까? [n]에 n을 입력합니다.
- 호스트 hana-s1-db1의 인증서 호스트 이름 [hana-s1-db1]에서 Enter 키를 눌러 기본값을 적용합니다.
- SAP 호스트 에이전트 사용자(sapadm) 암호에 암호를 입력합니다.
- SAP 호스트 에이전트 사용자(sapadm) 암호 확인에 암호를 입력합니다.
- 시스템 관리자(hn1adm) 암호에 암호를 입력합니다.
- 시스템 관리자 홈 디렉터리 [/usr/sap/HN1/home]에서 Enter 키를 눌러 기본값을 적용합니다.
- 시스템 관리자 로그인 셸 [/bin/sh]에서 Enter 키를 눌러 기본값을 적용합니다.
- 시스템 관리자 사용자 ID [1001]에서 Enter 키를 눌러 기본값을 적용합니다.
- 사용자 그룹의 ID 입력(sapsys) [79]에서 Enter 키를 눌러 기본값을 적용합니다.
- 시스템 데이터베이스 사용자(system) 암호에 시스템 암호를 입력합니다.
- 시스템 데이터베이스 사용자(system) 암호 확인에 시스템 암호를 입력합니다.
- 컴퓨터를 다시 부팅한 후 다시 시작하시겠습니까? [n]에 n을 입력합니다.
- 계속하시겠습니까?(y/n)에 요약의 유효성을 검사하고 모든 항목이 양호하면 y를 입력합니다.
[2] 이전 단계를 반복하여 SITE 2의 첫 번째 노드에 SAP HANA를 설치합니다.
[1,2]global.ini를 확인합니다.
global.ini를 표시하고, 내부 SAP HANA 노드 간 통신에 대한 구성이 준비되었는지 확인합니다.
communication섹션을 확인합니다.inter서브넷의 주소 공간이 있어야 하고listeninterface가.internal로 설정되어야 합니다.internal_hostname_resolution섹션을 확인합니다.inter서브넷에 속하는 HANA 가상 머신의 IP 주소가 있어야 합니다.sudo cat /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini # Example from SITE1 [communication] internal_network = 10.23.1.128/26 listeninterface = .internal [internal_hostname_resolution] 10.23.1.138 = hana-s1-db1 10.23.1.139 = hana-s1-db2 10.23.1.140 = hana-s1-db3[1,2] SAP Note 2080991에 설명된 대로 비공유 환경에 global.ini를 설치할 준비를 합니다.
sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini [persistence] basepath_shared = no[1,2] SAP HANA를 다시 시작하여 변경 내용을 활성화합니다.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem[1,2] 클라이언트 인터페이스가 통신을 위해
client서브넷의 IP 주소를 사용하는지 확인합니다.# Execute as hn1adm /usr/sap/HN1/HDB03/exe/hdbsql -u SYSTEM -p "password" -i 03 -d SYSTEMDB 'select * from SYS.M_HOST_INFORMATION'|grep net_publicname # Expected result - example from SITE 2 "hana-s2-db1","net_publicname","10.23.0.14"구성을 확인하는 방법은 SAP Note 2183363 - SAP HANA 내부 네트워크 구성을 참조하세요.
[AH] HANA 설치 오류를 방지하려면 데이터 및 로그 디렉터리에 대한 사용 권한을 변경합니다.
sudo chmod o+w -R /hana/data /hana/log[1] 보조 HANA 노드를 설치합니다. 이 단계의 예제 지침은 SITE 1에 해당합니다.
상주
hdblcm프로그램을root로 시작합니다.cd /hana/shared/HN1/hdblcm ./hdblcm프롬프트에서 다음 값을 입력합니다.
- 작업 선택에 2를 입력합니다(호스트 추가의 경우).
- 추가할 쉼표로 구분된 호스트 이름 입력에 hana-s1-db2, hana-s1-db3을 입력합니다.
- 설치할 추가 구성 요소에 2, 3을 입력합니다.
- 루트 사용자 이름 [root] 입력에서 Enter 키를 눌러 기본값을 적용합니다.
- 호스트 'hana-s1-db2'의 역할 선택 [1]에서 1을 선택합니다(작업자의 경우).
- 호스트 'hana-s1-db2'의 호스트 장애 조치(failover) 그룹 입력 [기본값]에 Enter 키를 눌러 기본값을 적용합니다.
- 호스트 'hana-s1-db2'의 스토리지 파티션 번호 입력 [<<자동 할당>>]에서 Enter 키를 눌러 기본값을 적용합니다.
- 호스트 'hana-s1-db2'의 작업자 그룹 입력 [기본값]에서 Enter 키를 눌러 기본값을 적용합니다.
- 호스트 'hana-s1-db3'의 역할 선택 [1]에서 1을 선택합니다(작업자의 경우).
- 호스트 'hana-s1-db3'의 호스트 장애 조치(failover) 그룹 입력 [기본값]에서 Enter 키를 눌러 기본값을 적용합니다.
- 호스트 'hana-s1-db3'의 스토리지 파티션 번호 입력 [<<자동 할당>>]에서 Enter 키를 눌러 기본값을 적용합니다.
- 호스트 'hana-s1-db3'의 작업자 그룹 입력 [기본값]에서 Enter 키를 눌러 기본값을 적용합니다.
- 시스템 관리자(hn1adm) 암호에 암호를 입력합니다.
- SAP 호스트 에이전트 사용자(sapadm) 암호 입력에 암호를 입력합니다.
- SAP 호스트 에이전트 사용자(sapadm) 암호 확인에 암호를 입력합니다.
- 호스트 hana-s1-db2의 인증서 호스트 이름 [hana-s1-db2]에서 Enter 키를 눌러 기본값을 적용합니다.
- 호스트 hana-s1-db3의 인증서 호스트 이름 [hana-s1-db3]에서 Enter 키를 눌러 기본값을 적용합니다.
- 계속하시겠습니까?(y/n)에 요약의 유효성을 검사하고 모든 항목이 양호하면 y를 입력합니다.
[2] SITE 2에 보조 SAP HANA 노드를 설치하는 이전 단계를 반복합니다.
SAP HANA 2.0 시스템 복제 구성
다음 단계에서는 시스템 복제를 설정합니다.
[1] SITE 1에서 시스템 복제 구성:
데이터베이스를 hn1adm으로 백업합니다.
hdbsql -d SYSTEMDB -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')"시스템 PKI 파일을 보조 사이트에 복사합니다.
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/기본 사이트를 만듭니다.
hdbnsutil -sr_enable --name=HANA_S1[2] SITE 2에서 시스템 복제 구성:
두 번째 사이트를 등록하여 시스템 복제를 시작합니다. 다음 명령을 <hanasid>adm으로 실행합니다.
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 sapcontrol -nr 03 -function StartSystem[1] 복제 상태를 확인하고 모든 데이터베이스가 동기화될 때까지 기다립니다.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | ------------- | ----- | ------------ | --------- | ------- | --------- | ------------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 1 | HANA_S1 | hana-s2-db3 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 1 | HANA_S1 | hana-s2-db1 | 30301 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 1 | HANA_S1 | hana-s2-db1 | 30307 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 1 | HANA_S1 | hana-s2-db1 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 1 | HANA_S1 | hana-s2-db2 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # # mode: PRIMARY # site id: 1 # site name: HANA_S1[1,2] HANA 시스템 복제 가상 네트워크 인터페이스를 통해 전달된 경우 HANA 시스템 복제용 통신이 되도록 HANA 구성을 변경합니다.
두 사이트에서 HANA를 중지합니다.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem HDBglobal.ini를 편집하여 HANA 시스템 복제용 호스트 매핑을 추가합니다.
hsr서브넷의 IP 주소를 사용합니다.sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini #Add the section [system_replication_hostname_resolution] 10.23.1.202 = hana-s1-db1 10.23.1.203 = hana-s1-db2 10.23.1.204 = hana-s1-db3 10.23.1.205 = hana-s2-db1 10.23.1.206 = hana-s2-db2 10.23.1.207 = hana-s2-db3두 사이트에서 HANA를 시작합니다.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem HDB
자세한 내용은 시스템 복제용 호스트 이름 확인을 참조하세요.
[AH] 방화벽을 다시 사용하도록 설정하고 필요한 포트를 엽니다.
방화벽을 다시 사용하도록 설정합니다.
# Execute as root systemctl start firewalld systemctl enable firewalld필요한 방화벽 포트를 엽니다. HANA 인스턴스 번호에 대한 포트를 조정해야 합니다.
Important
HANA 노드 간 통신 및 클라이언트 트래픽을 허용하는 방화벽 규칙을 만듭니다. 필수 포트 목록은 모든 SAP 제품의 TCP/IP 포트에 나와 있습니다. 다음 명령은 예제입니다. 이 시나리오에서는 시스템 번호 03을 사용합니다.
# Execute as root sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp --permanent sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp
Pacemaker 클러스터 만들기
기본 Pacemaker 클러스터를 만들려면 Azure의 Red Hat Enterprise Linux에서 Pacemaker 설정의 단계를 따릅니다. 클러스터의 주 결정자를 비롯한 모든 가상 머신을 포함합니다.
Important
quorum expected-votes를 2로 설정하지 마세요. 2노드 클러스터가 아닙니다. 노드 펜싱이 역직렬화되도록 클러스터 속성 concurrent-fencing을 사용하도록 설정해야 합니다.
파일 시스템 리소스 만들기
이 프로세스의 다음 부분에서는 파일 시스템 리소스를 만들어야 합니다. 이 경우 가능한 방법은 다음과 같습니다.
[1,2] 두 복제 사이트에서 SAP HANA를 중지합니다. <sid>adm으로 실행합니다.
sapcontrol -nr 03 -function StopSystem[AH] 모든 HANA DB VM에 설치하기 위해 일시적으로 탑재된 파일 시스템인
/hana/shared를 탑재 해제합니다. 탑재 해제하려면 먼저 파일 시스템을 사용하는 프로세스 및 세션을 중지해야 합니다.umount /hana/shared[1] 사용 안 함 상태의
/hana/shared에 대한 파일 시스템 클러스터 리소스를 만듭니다. 탑재를 사용하려면 먼저 위치 제약 조건을 정의해야 하므로--disabled를 사용합니다.
Azure Files의 NFS 공유 또는 Azure NetApp Files의 NFS 볼륨에 /hana/shared'를 배포하도록 선택했습니다.이 예제에서는 '/hana/shared' 파일 시스템이 Azure NetApp Files에 배포되고 NFSv4.1을 통해 탑재됩니다. Azure NetApp Files에서 NFS를 사용하는 경우에만 이 섹션의 단계를 따릅니다.
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=true
제안된 시간 제한 값을 사용하면 클러스터 리소스가 Azure NetApp Files의 NFSv4.1 임대 갱신과 관련된 프로토콜별 일시 중지를 견딜 수 있습니다. 자세한 내용은 NetApp의 NFS 모범 사례를 참조하세요.
이 예제에서는 '/hana/shared' 파일 시스템이 Azure Files의 NFS에 배포됩니다. Azure Files에서 NFS를 사용하는 경우에만 이 섹션의 단계를 따릅니다.
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=trueOCF_CHECK_LEVEL=20특성이 모니터 작업에 추가되어 모니터 작업에서 파일 시스템의 읽기/쓰기 테스트를 수행합니다. 이 특성이 없으면 모니터 작업은 파일 시스템이 탑재되어 있는지만 확인합니다. 이는 연결이 끊어질 때 파일 시스템에 액세스할 수 없는 경우에도 탑재된 상태를 유지할 수 있기 때문에 문제가 될 수 있습니다.on-fail=fence특성도 모니터 작업에 추가됩니다. 이 옵션을 사용하면 노드에서 모니터 작업이 실패하는 경우 해당 노드가 즉시 펜싱됩니다. 이 옵션이 없으면 기본 동작으로 실패한 리소스에 종속된 모든 리소스를 중지하고, 실패한 리소스를 다시 시작한 다음, 실패한 리소스에 종속된 모든 리소스를 시작합니다. 이 동작은 SAP Hana 리소스가 실패한 리소스에 의존하는 경우 시간이 오래 걸릴 뿐만 아니라 완전히 실패할 수도 있습니다. HANA 이진 파일이 있는 NFS 공유에 액세스할 수 없는 경우 SAP Hana 리소스를 중지할 수 없습니다.위 구성의 시간 제한은 특정 SAP 설정에 맞게 조정해야 할 수 있습니다.
[1] 노드 특성을 구성하고 확인합니다. 복제 사이트 1의 모든 SAP HANA DB 노드에는
S1특성이 할당되고, 복제 사이트 2의 모든 SAP HANA DB 노드에는S2특성이 할당됩니다.# HANA replication site 1 pcs node attribute hana-s1-db1 NFS_SID_SITE=S1 pcs node attribute hana-s1-db2 NFS_SID_SITE=S1 pcs node attribute hana-s1-db3 NFS_SID_SITE=S1 # HANA replication site 2 pcs node attribute hana-s2-db1 NFS_SID_SITE=S2 pcs node attribute hana-s2-db2 NFS_SID_SITE=S2 pcs node attribute hana-s2-db3 NFS_SID_SITE=S2 # To verify the attribute assignment to nodes execute pcs node attribute[1] NFS 파일 시스템이 탑재되는 위치를 결정하는 제약 조건을 구성하고 파일 시스템 리소스를 사용하도록 설정합니다.
# Configure the constraints pcs constraint location fs_hana_shared_s1-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S1 pcs constraint location fs_hana_shared_s2-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S2 # Enable the file system resources pcs resource enable fs_hana_shared_s1 pcs resource enable fs_hana_shared_s2파일 시스템 리소스를 사용하도록 설정하면 클러스터에서
/hana/shared파일 시스템을 탑재합니다.[AH] Azure NetApp Files 볼륨이 두 사이트의 모든 HANA DB VM에서
/hana/shared에 탑재되었는지 확인합니다.예를 들어 Azure NetApp Files를 사용하는 경우:
sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7예를 들어 Azure Files NFS를 사용하는 경우:
sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
[1] 다음과 같이 특성 리소스를 구성 및 복제하고 제약 조건을 구성합니다.
# Configure the attribute resources pcs resource create hana_nfs_s1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s1_active pcs resource create hana_nfs_s2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s2_active # Clone the attribute resources pcs resource clone hana_nfs_s1_active meta clone-node-max=1 interleave=true pcs resource clone hana_nfs_s2_active meta clone-node-max=1 interleave=true # Configure the constraints, which will set the attribute values pcs constraint order fs_hana_shared_s1-clone then hana_nfs_s1_active-clone pcs constraint order fs_hana_shared_s2-clone then hana_nfs_s2_active-clone팁
구성에 /
hana/shared이외의 파일 시스템이 포함되어 있고 이러한 파일 시스템이 NFS 탑재된 경우sequential=false옵션을 포함합니다. 이 옵션은 파일 시스템 간에 순서 종속성이 없도록 합니다. 모든 NFS 탑재 파일 시스템은 해당 특성 리소스보다 먼저 시작해야 하지만, NFS 탑재 파일 시스템 간에는 특별한 시작 순서가 없습니다. 자세한 내용은 HANA 파일 시스템이 NFS 공유인 경우 Pacemaker 클러스터에서 SAP HANA 스케일 아웃 HSR을 구성하려면 어떻게 해야 하나요?를 참조하세요.[1] Pacemaker를 유지 관리 모드로 전환하여 HANA 클러스터 리소스 만들기를 준비합니다.
pcs property set maintenance-mode=true
SAP HANA 클러스터 리소스 만들기
이제 클러스터 리소스를 만들 준비가 되었습니다.
[A] 주 결정자 노드를 포함하여 모든 클러스터 노드에 HANA 스케일 아웃 리소스 에이전트를 설치합니다.
yum install -y resource-agents-sap-hana-scaleout참고 항목
운영 체제 릴리스에 지원되는 패키지
resource-agents-sap-hana-scaleout의 최소 버전은 RHEL HA 클러스터에 대한 지원 정책 - 클러스터에서 SAP HANA 관리를 참조하세요.[1,2] 각 시스템 복제 사이트의 HANA DB 노드 하나에 HANA 시스템 복제 후크를 설치합니다. SAP HANA는 여전히 다운된 상태여야 합니다.
후크를
root로 준비합니다.mkdir -p /hana/shared/myHooks cp /usr/share/SAPHanaSR-ScaleOut/SAPHanaSR.py /hana/shared/myHooks chown -R hn1adm:sapsys /hana/shared/myHooksglobal.ini를 조정합니다.# add to global.ini [ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /hana/shared/myHooks execution_order = 1 [trace] ha_dr_saphanasr = info
[AH] 클러스터에서 <sid>adm용 클러스터 노드에 sudoers 구성을 요구합니다. 이 예제에서는 새 파일을 만들어 이 작업을 수행합니다. 명령을
root로 실행합니다.sudo visudo -f /etc/sudoers.d/20-saphana # Insert the following lines and then save Cmnd_Alias SOK = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SFAIL -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SOK, SFAIL Defaults!SOK, SFAIL !requiretty[1,2] 두 복제 사이트에서 SAP HANA를 시작합니다. <sid>adm으로 실행합니다.
sapcontrol -nr 03 -function StartSystem[1] 후크 설치를 확인합니다. 활성 HANA 시스템 복제 사이트에서 <sid>adm으로 실행합니다.
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example entries # 2020-07-21 22:04:32.364379 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:46.905661 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:52.092016 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:52.782774 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:53.117492 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:06:35.599324 ha_dr_SAPHanaSR SOK[1] HANA 클러스터 리소스를 만듭니다. 다음 명령을
root로 실행합니다.클러스터가 이미 유지 관리 모드인지 확인합니다.
그런 다음, HANA 토폴로지 리소스를 만듭니다.
RHEL 7.x 클러스터를 빌드하는 경우 다음 명령을 사용합니다.pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopologyScaleOut \ SID=HN1 InstanceNumber=03 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueRHEL >= 8.x 클러스터를 빌드하는 경우 다음 명령을 사용합니다.
pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopology \ SID=HN1 InstanceNumber=03 meta clone-node-max=1 interleave=true \ op methods interval=0s timeout=5 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=trueHANA 인스턴스 리소스를 만듭니다.
참고 항목
이 문서에는 Microsoft에서 더 이상 사용하지 않는 용어에 대한 참조가 포함되어 있습니다. 소프트웨어에서 용어가 제거되면 이 문서에서 해당 용어가 제거됩니다.
RHEL 7.x 클러스터를 빌드하는 경우 다음 명령을 사용합니다.
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource master msl_SAPHana_HN1_HDB03 SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=trueRHEL >= 8.x 클러스터를 빌드하는 경우 다음 명령을 사용합니다.
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op demote interval=0s timeout=320 op methods interval=0s timeout=5 \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource promotable SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=trueImportant
장애 조치(failover) 테스트를 수행하는 동안 실패한 주 인스턴스가 자동으로 보조 인스턴스로 등록되지 않도록
AUTOMATED_REGISTER를false로 설정하는 것이 좋습니다. 테스트 후 모범 사례로AUTOMATED_REGISTER를true로 설정하여 인수 후 시스템 복제가 자동으로 다시 시작될 수 있도록 합니다.가상 IP 및 연결된 리소스를 만듭니다.
pcs resource create vip_HN1_03 ocf:heartbeat:IPaddr2 ip=10.23.0.18 op monitor interval="10s" timeout="20s" sudo pcs resource create nc_HN1_03 azure-lb port=62503 sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03클러스터 제약 조건을 만듭니다.
RHEL 7.x 클러스터를 빌드하는 경우 다음 명령을 사용합니다.
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then msl_SAPHana_HN1_HDB03 pcs constraint colocation add g_ip_HN1_03 with master msl_SAPHana_HN1_HDB03 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne trueRHEL >= 8.x 클러스터를 빌드하는 경우 다음 명령을 사용합니다.
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then SAPHana_HN1_HDB03-clone pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_HDB03-clone 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne true
[1] 클러스터를 유지 관리 모드에서 제외시킵니다. 클러스터 상태가
ok이며 모든 리소스가 시작되었는지 확인합니다.sudo pcs property set maintenance-mode=false #If there are failed cluster resources, you may need to run the next command pcs resource cleanup참고 항목
앞의 구성에서 시간 제한은 단지 예제이며 특정 HANA 설정에 맞게 조정해야 할 수 있습니다. 예를 들어 SAP HANA 데이터베이스를 시작하는 데 시간이 더 오래 걸리는 경우 시작 시간 제한을 늘려야 할 수 있습니다.
HANA 활성/읽기 지원 시스템 복제 구성
SAP HANA 2.0 SPS 01부터 SAP는 SAP HANA 시스템 복제를 위한 활성/읽기 지원 설정을 허용합니다. 이 기능을 사용하면 읽기 집약적인 워크로드에 대해 SAP HANA 시스템 복제의 보조 시스템을 적극적으로 사용할 수 있습니다. 클러스터에서 이러한 설정을 지원하려면 클라이언트가 보조 읽기 지원 SAP HANA 데이터베이스에 액세스할 수 있도록 두 번째 가상 IP 주소가 필요합니다. 인수가 발생한 후에도 보조 복제 사이트에 액세스할 수 있도록 클러스터에서 가상 IP 주소를 SAP Hana 리소스의 보조로 이동해야 합니다.
이 섹션에서는 두 번째 가상 IP 주소를 사용하여 Red Hat 고가용성 클러스터에서 이러한 유형의 시스템 복제를 관리하기 위해 수행해야 하는 추가 단계에 대해 설명합니다.
계속 진행하기 전에 이 문서의 앞부분에서 설명한 대로 SAP HANA 데이터베이스를 관리하는 Red Hat 고가용성 클러스터를 완전히 구성했는지 확인합니다.
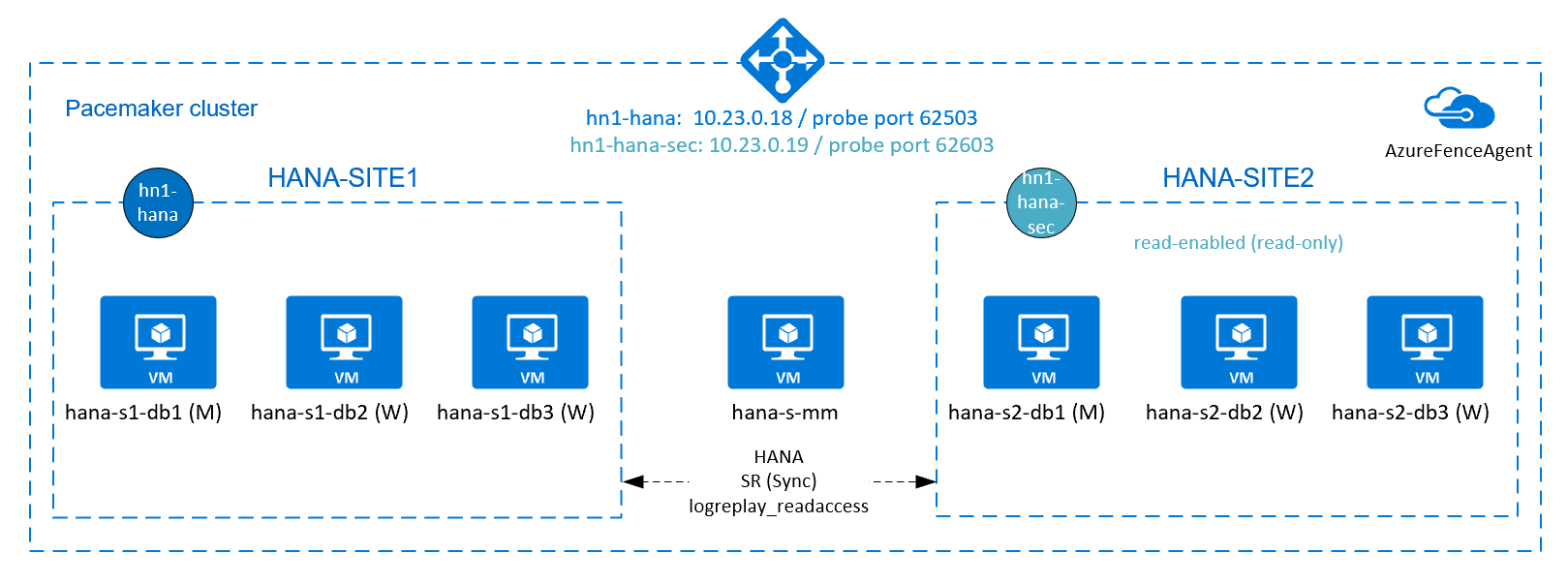
활성/읽기 지원 설정을 위한 Azure Load Balancer의 추가 설정
두 번째 가상 IP 프로비저닝을 계속하려면 Azure Load Balancer 구성에 설명된 대로 Azure Load Balancer를 구성했는지 확인합니다.
표준 부하 분산 장치의 경우 이전 섹션에서 만든 것과 동일한 부하 분산 장치에서 이러한 추가 단계를 수행합니다.
두 번째 프런트 엔드 IP 풀 만들기:
- 부하 분산 장치를 열고, 프런트 엔드 IP 풀을 선택하고, 추가를 선택합니다.
- 두 번째 프런트 엔드 IP 풀의 이름을 입력합니다(예: hana-secondaryIP).
- 할당을 고정으로 설정하고 IP 주소(예: 10.23.0.19)를 입력합니다.
- 확인을 선택합니다.
- 새 프런트 엔드 IP 풀을 만든 후, 풀 IP 주소를 적어 둡니다.
다음으로, 상태 프로브를 만듭니다.
- 부하 분산 장치를 열고, 상태 프로브를 선택한 다음, 추가를 선택합니다.
- 새 상태 프로브의 이름(예: hana-secondaryhp)을 입력합니다.
- 프로토콜 및 포트 62603으로 TCP를 선택합니다. 5로 설정된 간격 값, 2로 설정된 비정상 임계값 값을 유지합니다.
- 확인을 선택합니다.
다음으로 부하 분산 규칙을 만듭니다.
- 부하 분산 장치를 열고, 부하 분산 규칙을 선택한 다음, 추가를 선택합니다.
- 새 부하 분산 장치 규칙의 이름(예: hana-secondarylb)을 입력합니다.
- 이전에 만든 프런트 엔드 IP 주소, 백 엔드 풀, 상태 프로브를 선택합니다(예: hana-secondaryIP, hana-backend 및 hana-secondaryhp).
- HA 포트를 선택합니다.
- 부동 IP를 사용하도록 설정했는지 확인합니다.
- 확인을 선택합니다.
HANA 활성/읽기 지원 시스템 복제 구성
HANA 시스템 복제를 구성하는 단계는 SAP HANA 2.0 시스템 복제 구성 섹션에 설명되어 있습니다. 읽기 지원 보조 시나리오를 배포하는 경우 두 번째 노드에서 시스템 복제를 구성하는 동안 hanasidadm으로 다음 명령을 실행합니다.
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 --operationMode=logreplay_readaccess
활성/읽기 지원 설정에 대한 보조 가상 IP 주소 리소스 추가
다음 명령을 사용하여 두 번째 가상 IP와 추가 제약 조건을 구성할 수 있습니다. 보조 인스턴스가 다운되면 보조 가상 IP가 주 인스턴스로 전환됩니다.
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.23.0.19"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
# RHEL 8.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote SAPHana_HN1_HDB03-clone then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave SAPHana_HN1_HDB03-clone 5
# RHEL 7.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote msl_SAPHana_HN1_HDB03 then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave msl_SAPHana_HN1_HDB03 5
pcs property set maintenance-mode=false
클러스터 상태가 ok이며 모든 리소스가 시작되었는지 확인합니다. 두 번째 가상 IP는 보조 사이트에서 SAP Hana 보조 리소스와 함께 실행됩니다.
# Example output from crm_mon
#Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#
#Active resources:
#
#rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm
#Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1]
# Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03]
# Masters: [ hana-s1-db1 ]
# Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1
#Resource Group: g_secip_HN1_03
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1
다음 섹션에서는 실행할 일반적인 장애 조치(failover) 테스트 세트를 찾을 수 있습니다.
읽기 지원 보조로 구성된 HANA 클러스터를 테스트하는 경우 보조 가상 IP의 다음 동작에 유의해야 합니다.
클러스터 리소스 SAPHana_HN1_HDB03 보조 사이트(S2)로 이동하면 두 번째 가상 IP가 다른 사이트 hana-s1-db1로 이동합니다.
AUTOMATED_REGISTER="false"를 구성하고 HANA 시스템 복제가 자동으로 등록되지 않은 경우 두 번째 가상 IP가 hana-s2-db1에서 실행됩니다.서버 충돌을 테스트할 때 두 번째 가상 IP 리소스(rsc_secip_HN1_HDB03)와 Azure Load Balancer 포트 리소스(rsc_secnc_HN1_HDB03)는 주 가상 IP 리소스와 함께 주 서버에서 실행됩니다. 보조 서버가 다운 상태인 동안 읽기 사용 HANA 데이터베이스에 연결된 애플리케이션은 주 HANA 데이터베이스에 연결됩니다. 이 동작이 예상됩니다. 보조 서버를 사용할 수 없는 동안 읽기 지원 HANA 데이터베이스에 연결된 애플리케이션이 작동할 수 있습니다.
장애 조치(failover) 및 대체 중에 두 번째 가상 IP를 사용하여 HANA 데이터베이스에 연결하는 애플리케이션의 기존 연결이 중단될 수 있습니다.
SAP HANA 장애 조치 테스트
테스트를 시작하기 전에 클러스터와 SAP HANA 시스템 복제 상태를 확인합니다.
실패한 클러스터 작업이 없는지 확인합니다.
#Verify that there are no failed cluster actions pcs status # Example #Stack: corosync #Current DC: hana-s-mm (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum #Last updated: Thu Sep 24 06:00:20 2020 #Last change: Thu Sep 24 05:59:17 2020 by root via crm_attribute on hana-s1-db1 # #7 nodes configured #45 resources configured # #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: # #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm #Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1SAP HANA 시스템 복제가 동기화되었는지 확인
# Verify HANA HSR is in sync sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" #| Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary| Secondary | Secondary | Secondary | Replication | Replication | Replication | #| | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | #| -------- | ----------- | ----- | ------------ | --------- | ------- | --------- | ------------- | -------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | #| HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 2 | HANA_S1 | hana-s2-db3 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 2 | HANA_S1 | hana-s2-db2 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 2 | HANA_S1 | hana-s2-db1 | 30301 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 2 | HANA_S1 | hana-s2-db1 | 30307 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 2 | HANA_S1 | hana-s2-db1 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #status system replication site "1": ACTIVE #overall system replication status: ACTIVE #Local System Replication State #~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ #mode: PRIMARY #site id: 1 #site name: HANA_S1
노드가 NFS 공유(
/hana/shared)에 대한 액세스 권한을 상실하면 장애 시나리오에 대한 클러스터 구성을 확인합니다.SAP HANA 리소스 에이전트는
/hana/shared에 저장된 이진 파일에 의존하여 장애 조치(failover) 중에 작업을 수행합니다. 파일 시스템/hana/shared은 제시된 구성에서 NFS를 통해 탑재됩니다. 수행할 수 있는 테스트는 주 사이트 VM 중 하나에서/hana/sharedNFS가 탑재된 파일 시스템에 대한 액세스를 차단하는 임시 방화벽 규칙을 만드는 것입니다. 이 방식은 활성 시스템 복제 사이트에서/hana/shared에 대한 액세스 권한을 상실할 때 클러스터 장애 조치(failover)가 이루어지는지 확인합니다.예상 결과: 기본 사이트 VM 중 하나에서
/hana/sharedNFS가 탑재된 파일 시스템에 대한 액세스를 차단하면 파일 시스템에서 읽기/쓰기를 수행하는 모니터링 작업에 실패합니다. 이는 파일 시스템에 액세스하지 못해 HANA 리소스 장애조치를 트리거하기 때문입니다. HANA 노드가 NFS 공유에 액세스할 수 없는 경우에도 동일한 결과가 예상됩니다.crm_mon또는pcs status를 실행하여 클러스터 리소스 상태를 확인할 수 있습니다. 테스트 시작 전 리소스 상태:# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1/hana/shared에 대한 실패를 시뮬레이션하려면:- ANF의 NFS를 사용하는 경우 먼저 주 사이트에서
/hana/sharedANF 볼륨의 IP 주소를 확인합니다. 를 실행df -kh|grep /hana/shared하여 수행할 수 있습니다. - Azure Files의 NFS를 사용하는 경우 먼저 스토리지 계정에 대한 프라이빗 엔드포인트의 IP 주소를 확인합니다.
그런 다음 기본 HANA 시스템 복제 사이트 VM 중 하나에서 다음 명령을 실행하여
/hana/sharedNFS 파일 시스템의 IP 주소에 대한 액세스를 차단하는 임시 방화벽 규칙을 설정합니다.이 예제에서는 ANF 볼륨
/hana/shared에 대해 hana-s1-db1에서 명령을 실행했습니다.iptables -A INPUT -s 10.23.1.7 -j DROP; iptables -A OUTPUT -d 10.23.1.7 -j DROP클러스터 구성에 따라
/hana/shared에 대한 액세스 권한을 상실한 HANA VM을 다시 시작하거나 중지해야 합니다. 클러스터 리소스가 다른 HANA 시스템 복제 사이트로 마이그레이션됩니다.다시 시작된 VM에서 클러스터가 시작되지 않으면 다음을 실행하여 클러스터를 시작합니다.
# Start the cluster pcs cluster start클러스터가 시작되면 파일 시스템
/hana/shared가 자동으로 탑재됩니다.AUTOMATED_REGISTER="false"를 설정하는 경우 보조 사이트에 SAP HANA 시스템 복제를 구성해야 합니다. 이 경우 다음 명령을 실행하여 SAP HANA를 보조로 다시 구성할 수 있습니다.# Execute on the secondary su - hn1adm # Make sure HANA is not running on the secondary site. If it is started, stop HANA sapcontrol -nr 03 -function StopWait 600 10 # Register the HANA secondary site hdbnsutil -sr_register --name=HANA_S1 --remoteHost=hana-s2-db1 --remoteInstance=03 --replicationMode=sync # Switch back to root and clean up failed resources pcs resource cleanup SAPHana_HN1_HDB03테스트 후의 리소스 상태는 다음과 같습니다.
# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s2-db1 ] # Slaves: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1- ANF의 NFS를 사용하는 경우 먼저 주 사이트에서
RHEL의 Azure VM에서 SAP HANA에 대한 HA에 설명된 테스트도 수행하여 SAP HANA 클러스터 구성을 철저히 테스트하는 것이 좋습니다.
다음 단계
- SAP용 Azure Virtual Machines 계획 및 구현
- SAP용 Azure Virtual Machines 배포
- SAP용 Azure Virtual Machines DBMS 배포
- SAP HANA용 Azure NetApp Files 기반 NFS v4.1 볼륨
- Azure VM에서 SAP HANA의 재해 복구를 계획하고 고가용성을 설정하는 방법을 알아보려면 의 SAP HANA 고가용성을 참조하세요.