Notebook을 사용하여 Lakehouse에 데이터 로드
이 자습서에서는 Notebook을 사용하여 레이크하우스에 데이터를 읽고 쓰는 방법을 알아봅니다. 이 목표를 달성하기 위해 Spark API 및 Pandas API가 지원됩니다.
Apache Spark API를 사용하여 데이터 로드
Notebook의 코드 셀에서 다음 코드 예제를 사용하여 원본에서 데이터를 읽고 Lakehouse의 파일, 테이블 또는 두 섹션 모두에 로드합니다.
읽을 위치를 지정하려면 데이터가 현재 Notebook의 기본 레이크하우스에 있는 경우 상대 경로를 사용하거나 데이터가 다른 레이크하우스에서 온 경우 절대 ABFS 경로를 사용할 수 있습니다. 데이터의 상황에 맞는 메뉴에서 이 경로를 복사할 수 있습니다.
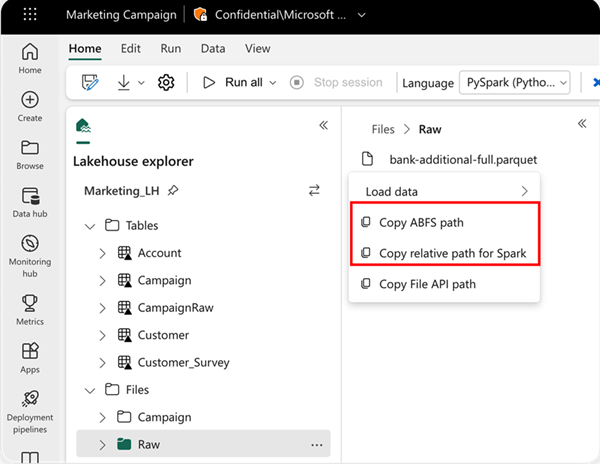
ABFS 경로 복사: 파일의 절대 경로를 반환합니다.
Spark 에 대한 상대 경로 복사: 기본 레이크하우스에서 파일의 상대 경로를 반환합니다.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default Lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default Lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default Lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Pandas API를 사용하여 데이터 로드
Pandas API를 지원하기 위해 기본 Lakehouse가 Notebook에 자동으로 탑재됩니다. 탑재 지점은 '/lakehouse/default/'입니다. 이 탑재 지점을 사용하여 기본 레이크하우스에서 데이터를 읽고 쓸 수 있습니다. 상황에 맞는 메뉴의 "파일 API 경로 복사" 옵션은 해당 탑재 지점에서 파일 API 경로를 반환합니다. ABFS 복사 경로 옵션 에서 반환된 경로 는 Pandas API에서도 작동합니다.
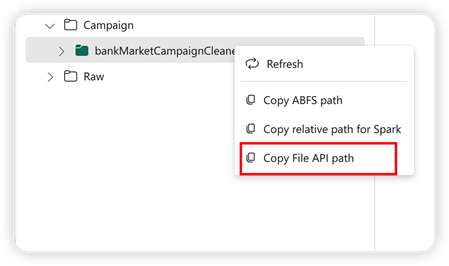
파일 복사 API 경로 : 기본 레이크 하우스의 탑재 지점 아래 경로를 반환합니다.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
팁
Spark API의 경우 ABFS 경로 복사 또는 Spark의 상대 경로 복사 옵션을 사용하여 파일의 경로를 가져옵니다. Pandas API의 경우 ABFS 경로 복사 또는 파일 API 복사 경로를 사용하여 파일 경로를 가져옵니다.
코드를 Spark API 또는 Pandas API와 함께 사용하는 가장 빠른 방법은 데이터 로드 옵션을 사용하고 사용하려는 API를 선택하는 것입니다. 코드는 Notebook의 새 코드 셀에 자동으로 생성됩니다.

관련 콘텐츠
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기