중요합니다
이 기능은 프리뷰 상태입니다.
패브릭 런타임은 Microsoft Fabric 에코시스템 내에서 원활한 통합을 제공하여 Apache Spark에서 제공하는 데이터 엔지니어링 및 데이터 과학 프로젝트를 위한 강력한 환경을 제공합니다.
이 문서에서는 Microsoft Fabric의 빅 데이터 계산을 위해 설계된 최신 런타임인 Fabric Runtime 2.0 공개 미리 보기를 소개합니다. 이 릴리스를 확장 가능한 분석 및 고급 워크로드를 위한 중요한 단계로 만드는 주요 기능 및 구성 요소를 강조 표시합니다.
Fabric Runtime 2.0은 데이터 처리 기능을 향상시키기 위해 설계된 다음 구성 요소 및 업그레이드를 통합합니다.
- Apache Spark 4.1
- 운영 체제: Azure Linux 3.0(Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.13
- 델타 레이크: 4.1
- R: 4.5.2
중요합니다
Fabric 런타임 2.0이 Spark 4.1, Delta Lake 4.1 및 Python 3.13으로 업데이트되었습니다. 포털에 표시되는 Fabric 런타임 버전(환경 UX의 작업 영역 설정 및 런타임 옵션)은 변경되지 않습니다.
| Component | 이전 버전 | 현재 버전 |
|---|---|---|
| Spark | 4.0 | 4.1 |
| Delta Lake | 4.0 | 4.1 |
| Python | 3.12 | 3.13 |

변경 내용 중단: Python 업그레이드를 사용하려면 라이브러리가 있는 모든 환경을 다시 게시해야 합니다. 다시 게시할 때까지 공용 라이브러리 및 사용자 지정 라이브러리 탭이 비어 있으며 영향을 받는 환경을 대상으로 하는 Spark 작업은 "모듈을 찾을 수 없음" 또는 "클래스를 찾을 수 없음" 오류로 실패합니다.
필요한 작업
- 각 환경에서 라이브러리 목록을 기록하거나 내보냅니다.
- 라이브러리를 다시 추가하고 게시 를 선택하여 Spark 4.1에 대해 다시 빌드합니다.
팁 (조언)
패브릭 런타임 2.0에는 더 많은 비용 없이 성능을 크게 향상시킬 수 있는 네이티브 실행 엔진에 대한 지원이 포함되어 있습니다. 모든 작업 및 Notebook이 향상된 성능 기능을 자동으로 상속하도록 환경 수준에서 네이티브 실행 엔진을 사용하도록 설정할 수 있습니다.
런타임 2.0 사용
작업 영역 수준 또는 환경 항목 수준에서 런타임 2.0을 사용하도록 설정할 수 있습니다. 작업 영역 설정을 사용하여 작업 영역의 모든 Spark 워크로드에 대한 기본값으로 런타임 2.0을 적용합니다. 또는 특정 Notebook 또는 Spark 작업 정의와 함께 사용할 수 있는 환경 항목을 생성하고, 이를 통해 작업 영역 기본값을 런타임 2.0으로 재정의합니다.
작업 영역 설정에서 런타임 2.0 사용
런타임 2.0을 전체 작업 영역의 기본값으로 설정하려면 다음을 수행합니다.
패브릭 작업 영역 내의 작업 영역 설정 페이지로 이동합니다.
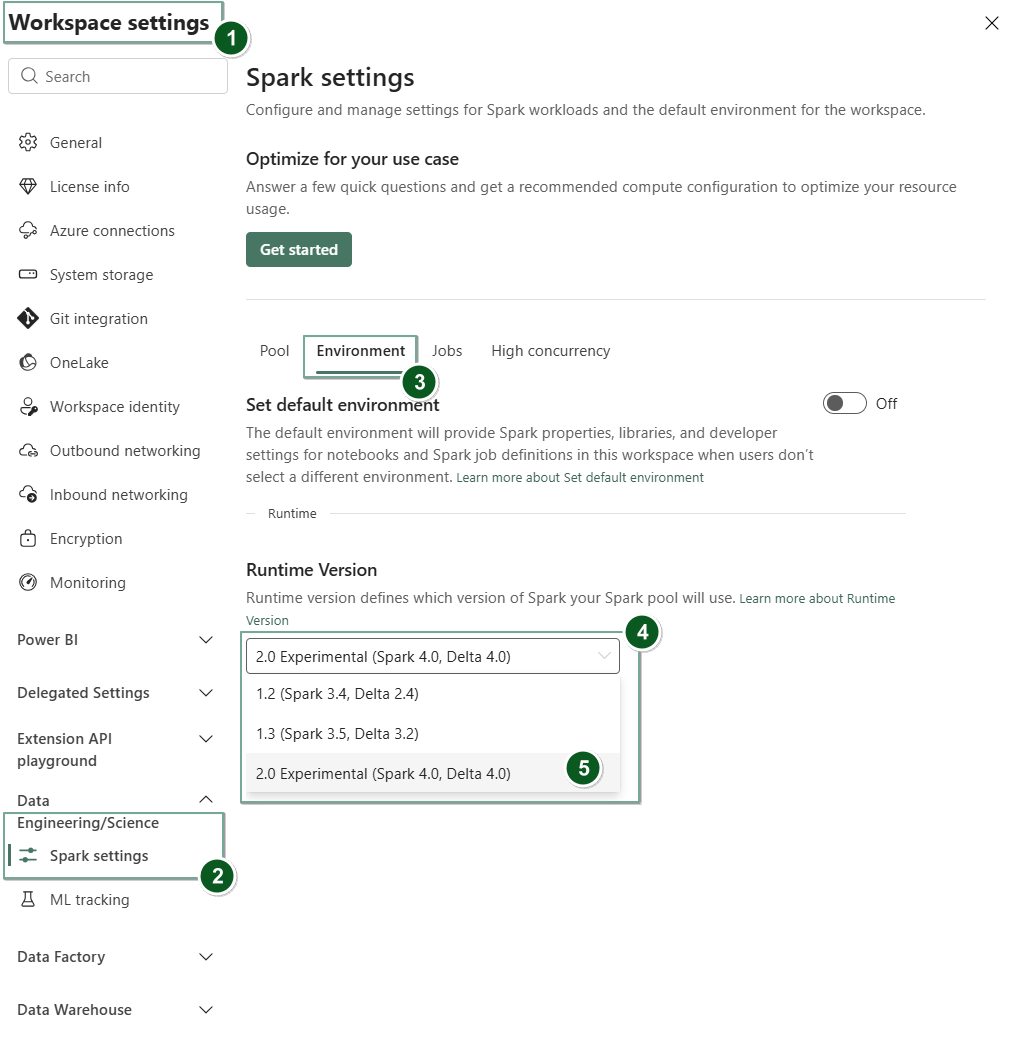
데이터 엔지니어링/과학 탭을 선택한 다음, Spark 설정을 선택합니다.
환경 탭을 선택합니다.
런타임 버전 드롭다운에서 2.0 공개 미리 보기(Spark 4.1, Delta 4.1)를 선택하고 변경 내용을 저장합니다.
런타임 2.0은 작업 영역에 대한 기본 런타임으로 설정됩니다.

환경 항목에서 런타임 2.0 사용
특정 Notebook 또는 Spark 작업 정의와 함께 런타임 2.0을 사용하려면 다음을 수행합니다.
새 환경 항목을 만들거나 기존 환경 항목을 엽니다.
런타임 드롭다운에서 2.0 공개 미리 보기(Spark 4.1, Delta 4.1)를 선택하고 변경 내용을 저장하고 게시합니다.
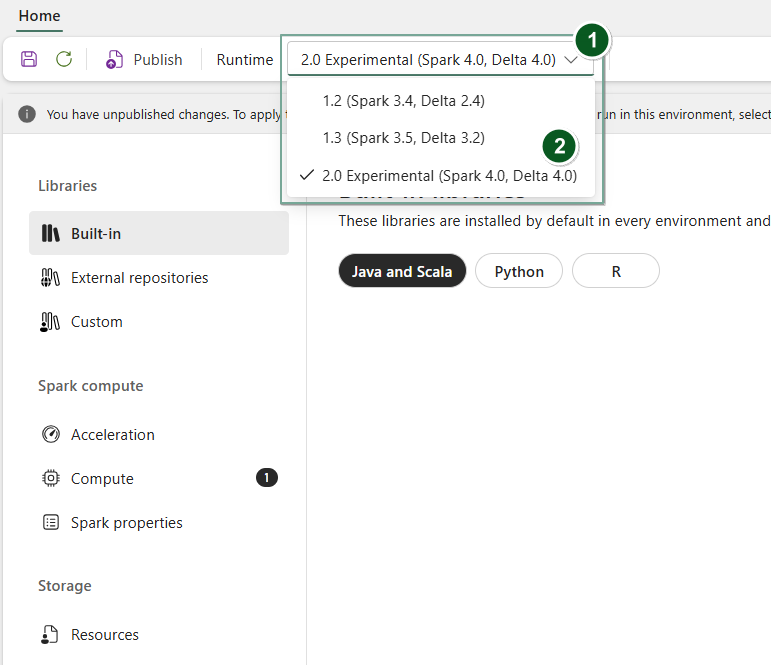
다음으로 이 환경 항목을 Notebook 또는 Spark 작업 정의와 함께 사용할 수 있습니다.

이제 Fabric 런타임 2.0(Spark 4.1 및 Delta Lake 4.1)에 도입된 최신 개선 사항 및 기능 실험을 시작할 수 있습니다.
비고
GPv2(범용 v2) Azure Storage 계정에 대한 WASB 프로토콜은 더 이상 사용되지 않습니다. GPv2 스토리지 계정에서 읽고 쓰는 대신 최신 ABFS 프로토콜을 사용해야 합니다.
공개 미리 보기
Fabric 런타임 2.0 공개 미리 보기 단계에서는 Spark 4.1 및 Delta Lake 4.1 모두에서 새로운 기능 및 API에 액세스할 수 있습니다. 미리 보기를 사용하면 최신 Spark 및 델타 기반의 향상된 기능을 즉시 사용할 수 있을 뿐만 아니라 최신 Java, Scala 및 Python 버전과 같은 향상된 변경 내용을 위한 원활한 준비 및 전환을 보장할 수 있습니다.
팁 (조언)
최신 정보, 자세한 변경 내용 목록 및 Fabric 런타임에 대한 특정 릴리스 정보는 Spark 런타임 릴리스 및 업데이트를 확인하고 구독 합니다.
주요 하이라이트
성능 및 실행 엔진 향상
패브릭 런타임 2.0에는 오픈 소스 Spark보다 성능이 크게 향상되는 네이티브 실행 엔진이 포함되어 있습니다. 엔진은 벡터화된 처리를 사용하여 코드를 변경하지 않고도 Lakehouse 인프라에서 Spark 쿼리를 가속화합니다.
런타임 2.0의 주요 성능 기능:
- 최대 6배 더 빠른: 벤치마크는 TPC-DS 워크로드의 오픈 소스 Spark에 비해 최대 6배 더 빠른 성능을 보여줍니다.
- 벡터화된 CSV 구문 분석: 네이티브 실행 엔진에는 CSV 수집 및 쿼리 워크로드를 가속화하는 벡터화된 CSV 파서가 포함되어 있습니다. 향후 업데이트를 위해 벡터화된 JSON 구문 분석 및 Spark 구조적 스트리밍 지원이 계획되어 있습니다.
네이티브 실행 엔진을 사용하도록 설정하려면 패브릭 데이터 엔지니어링에 대한 네이티브 실행 엔진을 참조하세요.
Apache Spark 4.1
Apache Spark 4.0은 4.x 시리즈의 첫 번째 릴리스로 중요한 이정표를 표시하여 활기찬 오픈 소스 커뮤니티의 공동 노력을 구현했습니다. Fabric 런타임 2.0은 이제 Apache Spark 4.1에서 실행되며 추가 개선 사항으로 해당 기반을 기반으로 합니다.
이 버전에서 Spark SQL은 VARIANT 데이터 형식 지원, SQL 사용자 정의 함수, 세션 변수, 파이프 구문 및 문자열 데이터 정렬과 같은 SQL 워크로드의 표현력과 다양성을 향상하도록 설계된 강력한 새 기능으로 크게 보강되었습니다. PySpark는 기능적 폭과 전체 개발자 환경 모두에 대한 지속적인 헌신을 통해 네이티브 그리기 API, 새로운 Python 데이터 원본 API, Python UTF 지원 및 PySpark UDF에 대한 통합 프로파일링과 다양한 다른 향상된 기능을 제공합니다. 구조적 스트리밍은 보다 유연한 상태 관리를 위한 임의 상태 API v2 및 더 쉬운 디버깅을 위한 상태 데이터 원본을 도입하는 등 더 큰 제어와 디버깅의 용이성을 제공하는 주요 추가 기능으로 발전합니다.
여기에서 전체 목록 및 자세한 변경 내용을 확인할 수 있습니다.
비고
Spark 4.x에서는 SparkR이 더 이상 사용되지 않으며 이후 버전에서 제거될 수 있습니다.
Delta Lake 4.1
Delta Lake 4.1은 Delta Lake 4.0 마일스톤 릴리스를 기반으로 하며, Delta Lake를 형식 간에 상호 운용 가능하고, 작업하기 쉽고, 성능이 향상되도록 하기 위한 노력을 계속합니다. 여기에는 강력한 새로운 기능, 성능 최적화 및 개방형 데이터 레이크하우스의 미래를 위한 기본 개선 사항이 포함됩니다.
여기에서 Delta Lake 3.3, 4.0 및 4.1에 도입된 전체 목록 및 자세한 변경 내용을 확인할 수 있습니다.
데이터 레이아웃 및 최적화
런타임 2.0은 델타 테이블에 대한 데이터 레이아웃 및 최적화 기능을 지원합니다.
- Z 순서 지정: 필터링된 쿼리에 대한 쿼리 성능을 향상시키기 위해 지정된 열을 통해 델타 테이블 파일 내의 데이터를 구성합니다.
- Liquid Clustering: 수동 유지 관리 없이 데이터 레이아웃을 자동으로 최적화하는 유연한 클러스터링 접근 방식입니다.
- 병렬 델타 스냅샷 로드: 네이티브 실행 엔진은 델타 테이블 스냅샷을 병렬로 로드하여 큰 테이블에 대한 쿼리 시작 시간을 줄입니다.
중요합니다
Delta Lake 4.1 특정 기능은 실험적이며 Notebook 및 Spark 작업 정의와 같은 Spark 환경에서만 작동합니다. 여러 Microsoft Fabric 워크로드에서 동일한 Delta Lake 테이블을 사용해야 하는 경우 이러한 기능을 사용하도록 설정하지 마세요. 모든 Microsoft Fabric 환경에서 호환되는 프로토콜 버전 및 기능에 대해 자세히 알아보려면 Delta Lake 테이블 형식 상호 운용성을 참조하세요.
런타임 2.0의 컴퓨팅 관리
런타임 2.0은 다음과 같은 컴퓨팅 관리 기능을 지원합니다.
- 리소스 프로필: 워크로드 요구 사항 및 제어 비용에 맞게 Spark 세션에 대해 미리 정의된 리소스 할당을 구성합니다.
- 사용자 지정 라이브 풀(미리 보기): 세션 시작 시간을 줄이는 미리 준비된 전용 Spark 풀을 만듭니다. 사용자 지정 라이브 풀은 런타임 2.0 워크로드에 대해 미리 보기로 사용할 수 있습니다.
제한 사항 및 참고 사항
- Delta Lake 4.x 특정 기능은 실험적이며 Notebook 및 Spark 작업 정의와 같은 Spark 환경에서만 작동합니다. 여러 패브릭 워크로드에서 동일한 Delta Lake 테이블을 사용해야 하는 경우 이러한 기능을 사용하도록 설정하지 마세요. 자세한 내용은 Delta Lake 테이블 형식 상호 운용성을 참조하세요.
- 런타임 2.0은 공개 미리 보기로 제공됩니다. 일부 기능 및 API는 일반 공급 전에 변경 될 수 있습니다.
- Fabric Spark용 VS Code 확장은 Notebook 및 Spark 작업 정의 개발을 위해 런타임 2.0을 지원합니다.