이 자습서에서는 데이터 시각화 기술을 사용하여 주요 특성을 요약하면서 데이터를 검사하고 조사하는 EDA(탐색적 데이터 분석)를 수행하는 방법을 알아봅니다.
데이터 프레임 및 배열에서 시각적 개체를 빌드하기 위한 고급 인터페이스를 제공하는 Python 데이터 시각화 라이브러리인 seaborn를 사용합니다.
seaborn에 대한 자세한 내용은 Seaborn: 통계 데이터 시각화를 참조하세요.
또한 탐색적 데이터 분석 및 정리를 수행하는 몰입형 환경을 제공하는 Notebook 기반 도구인 데이터 랭글러를 사용할 수 있습니다.
이 자습서의 주요 단계는 다음과 같습니다.
- 레이크하우스의 델타 테이블에 저장된 데이터를 읽습니다.
- Spark DataFrame을 Python 시각화 라이브러리가 지원하는 Pandas DataFrame으로 변환합니다.
- 데이터 랭글러를 사용하여 초기 데이터 정리 및 변환을 수행합니다.
-
seaborn을 사용하여 탐색적 데이터 분석을 수행합니다.
필수 조건
Microsoft Fabric 구독을 구매합니다. 또는 무료 Microsoft Fabric 평가판에 등록합니다.
Microsoft Fabric에 로그인합니다.
홈 페이지의 왼쪽 아래에 있는 환경 전환기를 사용하여 패브릭으로 전환합니다.

이 문서는 자습서의 시리즈 5부 중 2부입니다. 이 자습서를 완료하려면 먼저 다음을 완료합니다.
Notebooks에서 따라 하기
이 자습서에는 2-explore-cleanse-data.ipynb Notebook이 함께 제공됩니다.
이 자습서와 함께 제공된 노트북을 열려면 데이터 과학 자습서를 위한 시스템 준비의 지침을 따라 노트북을 작업 공간으로 가져오십시오.
이 페이지에서 코드를 복사하여 붙여넣으려는 경우 새 Notebook을 만들 수 있습니다.
코드 실행을 시작하기 전에 Notebook에 레이크하우스를 연결해야 합니다.
중요 사항
1부에서 사용한 것과 동일한 레이크하우스를 연결합니다.
레이크하우스에서 원시 데이터 읽기
레이크하우스의 파일 섹션에서 원시 데이터를 읽습니다. 이 데이터는 이전 Notebook에서 업로드되었습니다. 이 코드를 실행하기 전에 1부에서 사용한 것과 동일한 레이크하우스를 이 Notebook에 연결했는지 확인합니다.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
데이터 세트에서 Pandas DataFrame 만들기
더 쉽게 처리하고 시각화할 수 있도록 spark DataFrame을 Pandas DataFrame으로 변환합니다.
df = df.toPandas()
원시 데이터 표시
display로 원시 데이터를 탐색하고, 몇 가지 기본 통계를 수행하고, 차트 보기를 표시합니다. 데이터 분석 및 시각화를 위해서는 먼저 Numpy, Pnadas, Seaborn, Matplotlib와 같은 필수 라이브러리를 가져와야 합니다.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
# Code generated by Data Wrangler for pandas DataFrame
def clean_data(df):
# Drop duplicate rows in columns: 'CustomerId', 'RowNumber'
df = df.drop_duplicates(subset=['CustomerId', 'RowNumber'])
# Drop rows with missing data across all columns
df = df.dropna()
# Drop columns: 'CustomerId', 'RowNumber', 'Surname'
df = df.drop(columns=['CustomerId', 'RowNumber', 'Surname'])
return df
df_clean = clean_data(df.copy())
df_clean.head()
데이터 랭글러를 사용하여 초기 데이터 정리 수행
Notebook에서 Pandas 데이터 프레임을 탐색하고 변환하려면 Notebook에서 직접 데이터 랭글러를 시작합니다.
참고 항목
Notebook 커널이 사용 중인 동안에는 데이터 랭글러를 열 수 없습니다. 데이터 랭글러를 시작하기 전에 셀 실행이 완료되어야 합니다.
- Notebook 리본의 데이터 탭에서 데이터 랭글러 시작을 선택합니다. 편집 가능한 활성화된 Pandas DataFrames 목록이 표시됩니다.
- 데이터 랭글러에서 열려는 DataFrame을 선택합니다. 이 Notebook에는 DataFrame
df하나만 포함되어 있으므로df를 선택합니다.
데이터 랭글러가 시작되고 데이터에 대한 설명이 포함된 개요를 생성합니다. 가운데에 있는 테이블은 각 데이터 열을 보여줍니다. 테이블 옆에 있는 요약 패널에는 DataFrame에 대한 정보를 보여줍니다. 테이블에서 열을 선택하면 요약이 선택한 열에 대한 정보로 업데이트됩니다. 일부 경우에는 표시되고 요약된 데이터가 DataFrame에서 보기가 잘린 상태로 나타납니다. 이 경우 요약 창에 경고 이미지가 표시됩니다. 이 경고 위에 커서를 올리면 상황을 설명하는 텍스트를 볼 수 있습니다.

수행할 각 작업은 몇 번의 클릭만으로 적용할 수 있으며, 실시간으로 데이터 표시를 업데이트하고, 재사용 가능한 함수로 Notebook에 다시 저장할 수 있는 코드를 생성할 수 있습니다.
이 섹션의 나머지 부분에서는 데이터 랭글러를 사용하여 데이터 정리를 수행하는 단계를 안내합니다.
중복 행 삭제
왼쪽 패널에는 데이터 세트에서 수행할 수 있는 작업 목록(예: 찾기 및 바꾸기, 서식, 수식, 숫자)이 있습니다.
찾기 및 바꾸기를 확장하여 중복 행 삭제를 선택합니다.
중복 행을 정의하기 위해 비교할 열 목록을 선택할 수 있는 패널이 나타납니다. RowNumber 및 CustomerId를 선택합니다.
가운데 패널에는 이 작업의 결과에 대한 미리 보기가 있습니다. 미리 보기 아래에는 작업을 수행하는 코드가 있습니다. 이 경우 데이터는 변경되지 않은 것으로 보입니다. 그러나 보기가 잘린 상태로 보고 있으므로 작업을 계속 적용하는 것이 좋습니다.
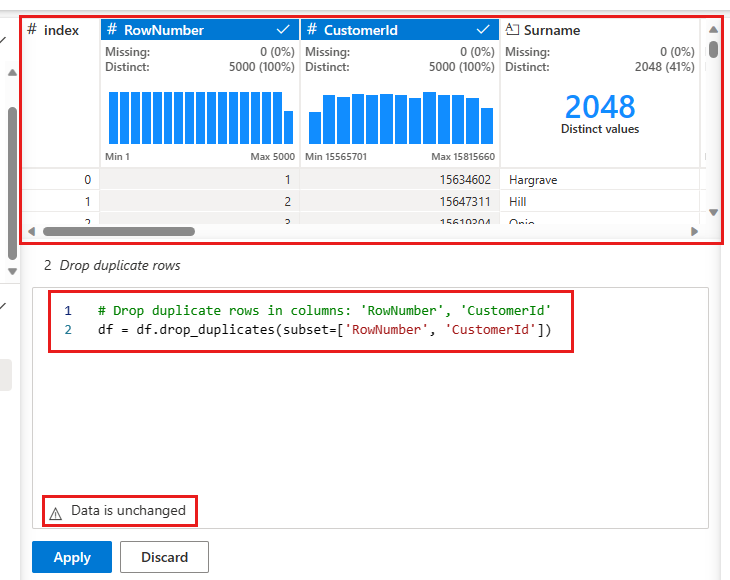
적용(측면 또는 아래쪽)을 선택하여 다음 단계로 이동합니다.

데이터가 누락된 행 삭제
데이터 랭글러를 사용하여 모든 열에 걸쳐 데이터가 누락된 행을 삭제합니다.
찾기 및 바꾸기에서 누락된 값 삭제를 선택합니다.
대상 열에서 모두 선택을 선택합니다.
적용을 선택하여 다음 단계로 이동합니다.

열 삭제
필요하지 않은 열을 삭제하려면 데이터 랭글러를 사용합니다.
스키마를 확장하여 열 삭제를 선택합니다.
RowNumber, CustomerId, Surname을 선택합니다. 이러한 열은 미리 보기에 빨간색으로 표시되어 코드에 의해 변경되었음을 나타냅니다(이 경우 삭제됨).
적용을 선택하여 다음 단계로 이동합니다.

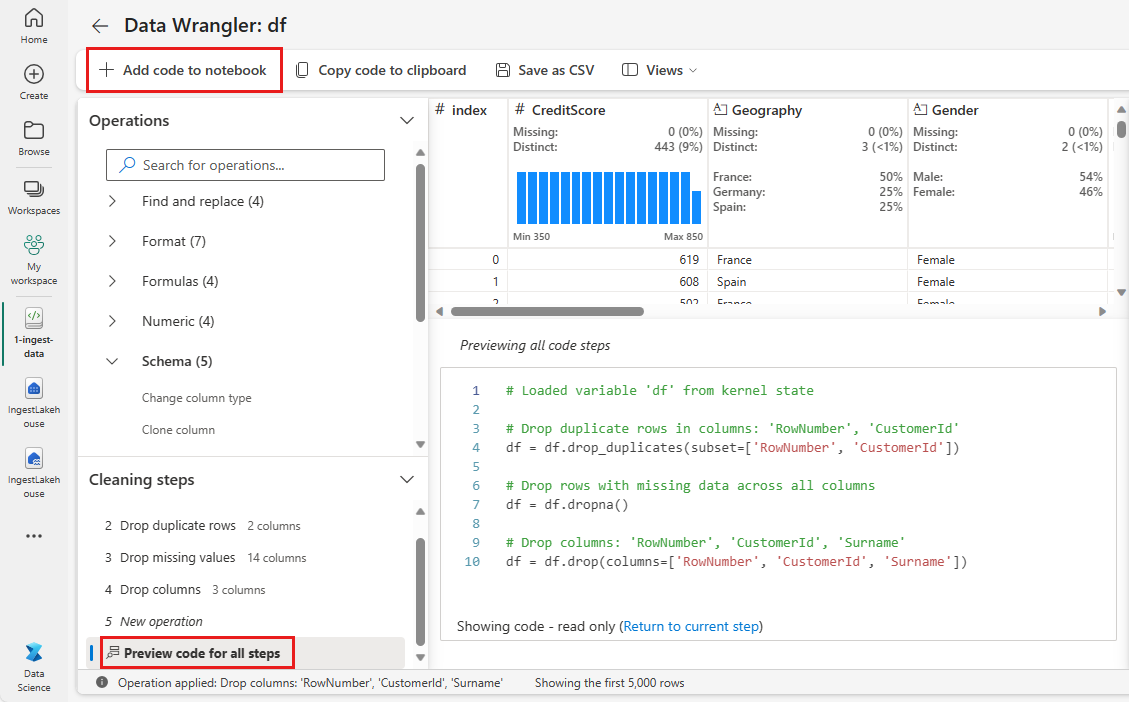
Notebook에 코드 추가
적용을 선택할 때마다 왼쪽 아래에 있는 정리 단계 패널에 새 단계가 만들어집니다. 패널 아래쪽에서 모든 단계에 대한 미리 보기 코드를 선택하여 모든 개별 단계의 조합을 확인합니다.
왼쪽 위에 있는 Notebook에 코드 추가를 선택하여 데이터 랭글러를 닫고 자동으로 코드를 추가합니다. Notebook에 코드 추가는 코드를 함수로 래핑한 다음 함수를 호출합니다.
팁
데이터 랭글러에서 생성된 코드는 새 셀을 수동으로 실행할 때까지 적용되지 않습니다.
데이터 랭글러를 사용하지 않은 경우 대신 이 다음 코드 셀을 사용할 수 있습니다.
이 코드는 데이터 랭글러에서 생성한 코드와 비슷하지만 생성된 각 단계에 인수 inplace=True를 추가합니다.
inplace=True를 설정하면 Pandas는 새 DataFrame을 출력으로 생성하는 대신 원래 DataFrame을 덮어씁니다.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
데이터 탐색
정리된 데이터의 요약 및 시각화를 표시합니다.
범주, 숫자 및 대상 특성 결정
이 코드를 사용하면 범주, 숫자 및 대상 특성을 결정할 수 있습니다.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
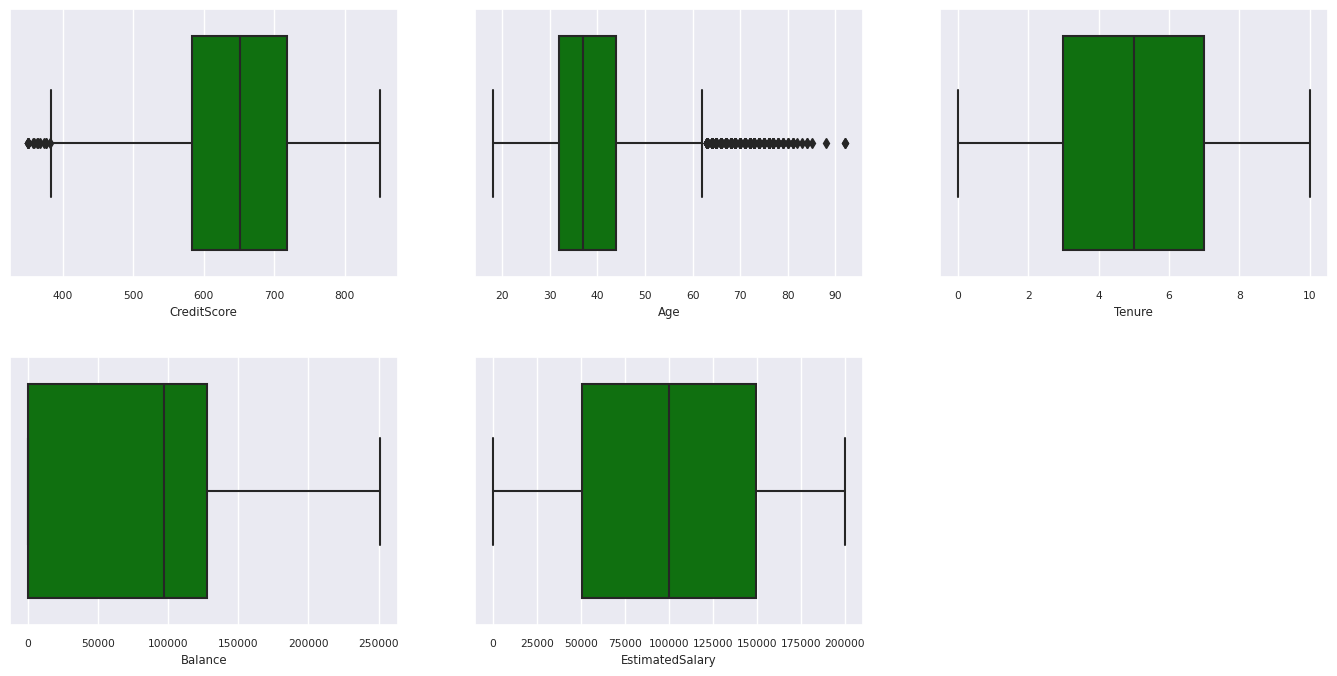
5개 숫자 요약
상자 플롯을 사용하여 숫자 특성에 대한 5개 숫자 요약(최소 점수, 1사분위수, 중앙값, 3사분위수, 최대 점수)을 표시합니다.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
종료 고객 및 미종료 고객의 분포
범주 특성에 걸쳐 종료 고객 및 미종료 고객의 분포를 표시합니다.
df_clean['Exited'] = df_clean['Exited'].astype(str)
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
df_clean['Exited'] = df_clean['Exited'].astype(str)
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
print(ind, item)
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
df_clean['Exited'] = df_clean['Exited'].astype(int)

숫자 특성 분포
히스토그램을 사용하여 숫자 특성의 빈도 분포를 보여줍니다.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

기능 엔지니어링 수행
기능 엔지니어링을 수행하여 현재 특성을 기반으로 새 특성을 생성합니다.
df_clean['Tenure'] = df_clean['Tenure'].astype(int)
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
데이터 랭글러를 사용하여 원-핫 인코딩 수행
데이터 랭글러를 사용하여 원-핫 인코딩을 수행할 수도 있습니다. 이렇게 하려면 데이터 랭글러를 다시 엽니다. 이번에는 df_clean 데이터를 선택합니다.
- 수식을 확장하여 원-핫 인코딩을 선택합니다.
- 원-핫 인코딩을 수행하려는 열 목록을 선택할 수 있는 패널이 나타납니다. 지역 및 성별을 선택합니다.
생성된 코드를 복사하고, 데이터 랭글러를 닫고 Notebook으로 돌아간 다음, 새 셀에 붙여넣을 수 있습니다. 또는 왼쪽 위에 있는 Notebook에 코드 추가를 선택하여 데이터 랭글러를 닫고 자동으로 코드를 추가합니다.
데이터 랭글러를 사용하지 않은 경우 대신 이 다음 코드 셀을 사용할 수 있습니다.
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
for column in ['Geography', 'Gender']:
insert_loc = df_clean.columns.get_loc(column)
df_clean = pd.concat([df_clean.iloc[:,:insert_loc], pd.get_dummies(df_clean.loc[:, [column]]), df_clean.iloc[:,insert_loc+1:]], axis=1)
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
탐색적 데이터 분석에서 얻은 관찰 결과 요약
- 스페인과 독일에 비해 대부분의 고객이 프랑스 출신이며, 스페인은 프랑스와 독일에 비해 이탈률이 가장 낮습니다.
- 대부분의 고객이 신용 카드를 가지고 있습니다.
- 연령과 신용 점수가 각각 60세 이상과 400 미만인 고객이 있지만 이를 이상값으로 간주할 수는 없습니다.
- 은행 상품을 두 개 이상 보유한 고객은 거의 없습니다.
- 활성 상태가 아닌 고객은 이탈률이 높습니다.
- 성별과 재직 연수는 고객이 은행 계좌를 해지하겠다는 결정에 영향을 미치지 않는 것으로 보입니다.
정리된 데이터에 대한 델타 테이블 만들기
이 데이터는 이 시리즈의 다음 Notebook에서 사용됩니다.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
다음 단계
이 데이터로 기계 학습 모델 학습 및 등록: