방법: Microsoft Fabric에서 Lakehouse 및 Notebook의 미러된 Azure Cosmos DB 데이터에 액세스(미리 보기)
이 가이드에서는 Microsoft Fabric에서 Lakehouse 및 Notebook의 미러된 Azure Cosmos DB 데이터에 액세스하는 방법(미리 보기)을 알아봅니다.
Important
Azure Cosmos DB의 미러링은 현재 프리뷰로 제공됩니다. 프로덕션 워크로드는 미리 보기 중에 지원되지 않습니다. 현재는 Azure Cosmos DB for NoSQL 계정만 지원됩니다.
필수 조건
- 기존 Azure Cosmos DB API for NoSQL 계정.
- Azure 구독이 없는 경우 Azure Cosmos DB for NoSQL을 무료로 사용해 보세요.
- 기존 Azure 구독이 있는 경우 새 Azure Cosmos DB for NoSQL 계정을 만듭니다.
- 기존 Fabric 용량입니다. 기존 용량이 없는 경우 Fabric 평가판을 시작합니다.
- Azure Cosmos DB for NoSQL 계정을 Fabric 미러링에 대해 구성해야 합니다. 자세한 내용은 계정 요구 사항을 참조하세요.
팁
공개 미리 보기 중에는 백업에서 신속하게 복구할 수 있는 기존 Azure Cosmos DB 데이터의 테스트 또는 개발 복사본을 사용하는 것이 좋습니다.
미러링 설정 및 필수 구성 요소
Azure Cosmos DB for NoSQL 데이터베이스에 대한 미러링을 구성합니다. 미러링을 구성하는 방법을 잘 모르는 경우 미러된 데이터베이스 구성 자습서를 참조하세요.
Fabric 포털로 이동합니다.
Azure Cosmos DB 계정의 자격 증명을 사용하여 새 연결 및 미러된 데이터베이스를 만듭니다.
복제가 데이터의 초기 스냅샷을 완료할 때까지 기다립니다.
Lakehouse 및 notebook의 미러된 데이터에 액세스
Lakehouse를 사용하면 Azure Cosmos DB for NoSQL 미러된 데이터를 분석하는 데 사용할 수 있는 도구 수를 더욱 늘릴 수 있습니다. 여기서는 Lakehouse를 사용하여 Spark Notebook을 빌드하여 데이터를 쿼리합니다.
다시 Fabric 포털 홈으로 이동합니다.
탐색 메뉴에서 만들기를 선택합니다.
만들기를 선택하고 데이터 엔지니어링 섹션을 찾은 다음 Lakehouse를 선택합니다.
Lakehouse의 이름을 입력한 다음 만들기를 선택합니다.
이제 데이터 가져오기를 선택한 다음 새 바로 가기를 선택합니다. 바로 가기 옵션 목록에서 Microsoft OneLake를 선택합니다.
Fabric 작업 영역의 미러된 데이터베이스 목록에서 미러된 Azure Cosmos DB for NoSQL 데이터베이스를 선택합니다. Lakehouse에서 사용할 테이블을 선택하고 다음을 선택한 다음 만들기를 선택합니다.
Lakehouse에서 테이블의 컨텍스트 메뉴를 열고 새로 만들기 또는 기존 Notebook을 선택합니다.
새 Notebook이 자동으로 열리고
SELECT LIMIT 1000을 사용하여 데이터 프레임을 로드합니다.Spark를 사용하여
SELECT *와 같은 쿼리를 실행합니다.df = spark.sql("SELECT * FROM Lakehouse.OrdersDB_customers LIMIT 1000") display(df)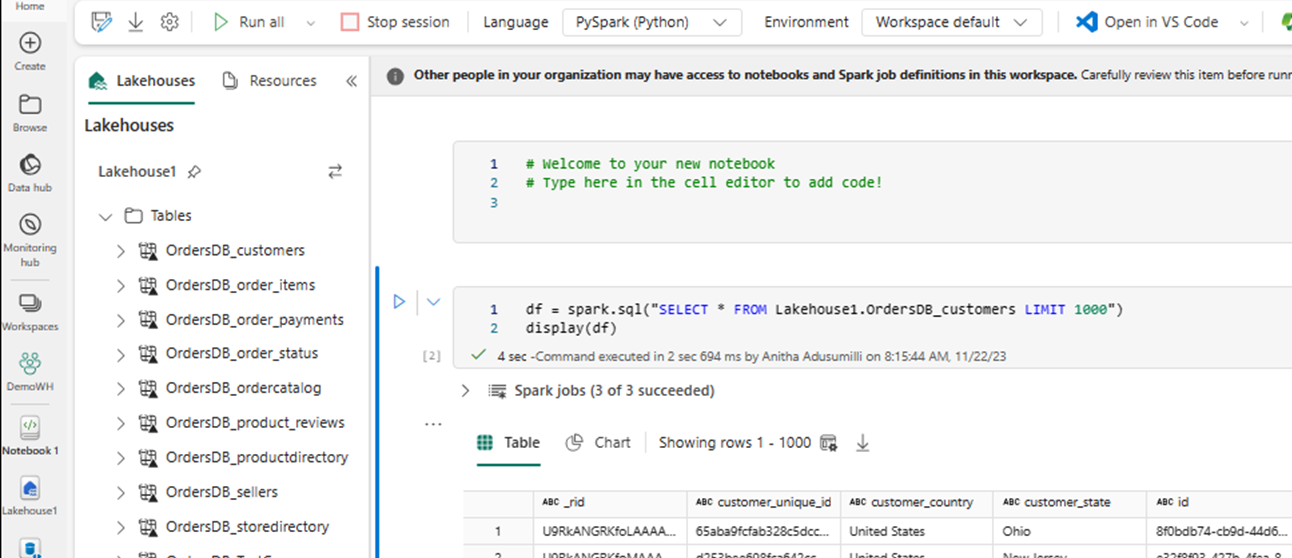
참고 항목
이 예제에서는 테이블의 이름을 가정합니다. Spark 쿼리를 작성할 때 사용자 고유 테이블을 사용합니다.

Spark를 사용하여 다시 쓰기
마지막으로 Spark 및 Python 코드를 사용하여 Fabric의 Notebooks에서 원본 Azure Cosmos DB 계정에 데이터를 다시 쓸 수 있습니다. 분석 결과를 Cosmos DB에 다시 쓰기 위해 이 작업을 수행할 수 있으며, 이는 OLTP 애플리케이션의 서비스 평면으로 사용할 수 있습니다.
Notebook 내에 4개의 코드 셀을 만듭니다.
먼저 미러된 데이터를 쿼리합니다.
fMirror = spark.sql("SELECT * FROM Lakehouse1.OrdersDB_ordercatalog")팁
이러한 샘플 코드 블록의 테이블 이름은 특정 데이터 스키마를 가정합니다. 이를 사용자 고유의 테이블 및 열 이름으로 자유롭게 바꿀 수 있습니다.
이제 데이터를 변환하고 집계합니다.
dfCDB = dfMirror.filter(dfMirror.categoryId.isNotNull()).groupBy("categoryId").agg(max("price").alias("max_price"), max("id").alias("id"))다음으로 자격 증명, 데이터베이스 이름 및 컨테이너 이름을 사용하여 Azure Cosmos DB for NoSQL 계정에 다시 쓰도록 Spark를 구성합니다.
writeConfig = { "spark.cosmos.accountEndpoint" : "https://xxxx.documents.azure.com:443/", "spark.cosmos.accountKey" : "xxxx", "spark.cosmos.database" : "xxxx", "spark.cosmos.container" : "xxxx" }마지막으로 Spark를 사용하여 원본 데이터베이스에 다시 씁니다.
dfCDB.write.mode("APPEND").format("cosmos.oltp").options(**writeConfig).save()모든 코드 셀을 실행합니다.
Important
Azure Cosmos DB에 쓰기 작업은 RU(요청 단위)를 사용합니다.