Azure HDInsight와 OneLake 통합
Azure HDInsight는 조직이 대량의 데이터를 처리하는 데 도움이 되는 빅 데이터 분석을 위한 관리형 클라우드 기반 서비스입니다. 이 자습서에서는 Azure HDInsight 클러스터에서 Jupyter Notebook을 사용하여 OneLake에 연결하는 방법을 보여 줍니다.
Azure HDInsight 사용
HDInsight 클러스터에서 Jupyter Notebook을 사용하여 OneLake에 연결하려면 다음을 수행합니다.
HDI(HDInsight) Apache Spark 클러스터를 만듭니다. HDInsight에서 클러스터 설정 지침을 따릅니다.
클러스터 정보를 제공하는 동안 클러스터에 액세스하려면 나중에 필요하므로 클러스터 로그인 사용자 이름 및 암호를 기억하세요.
UAMI(사용자가 할당한 관리 ID) 만들기: Azure HDInsight - UAMI용을 만들고 스토리지 화면에서 ID로 선택합니다.
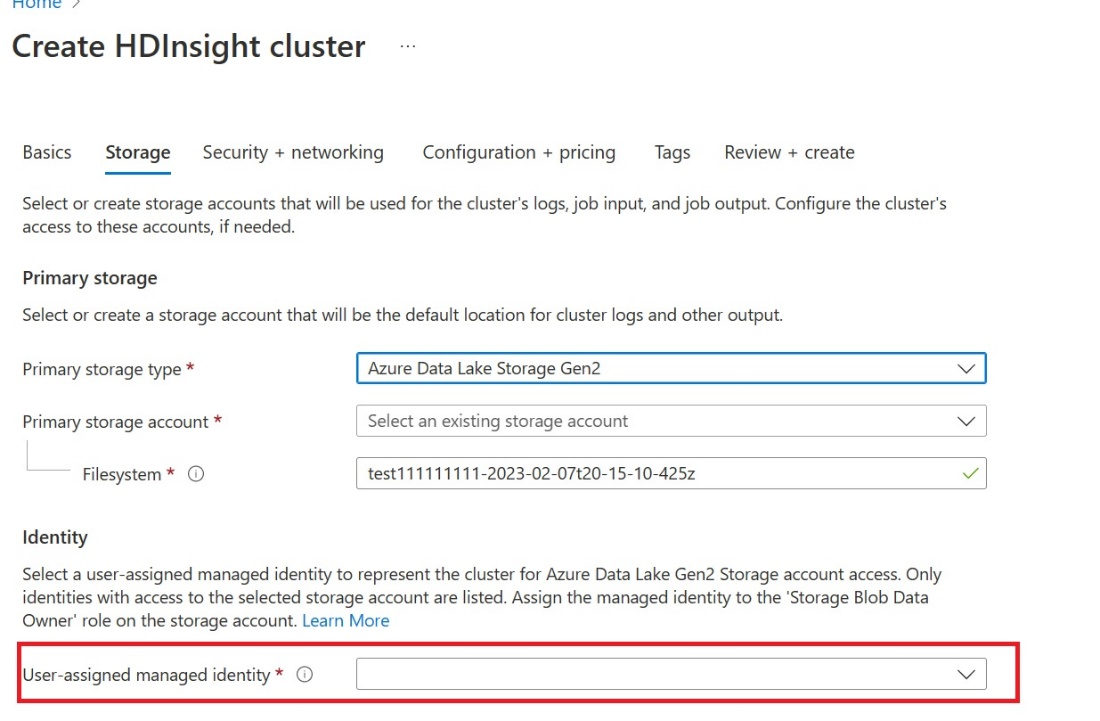
이 UAMI에 항목이 포함된 패브릭 작업 영역에 대한 액세스 권한을 부여합니다. 가장 적합한 역할을 결정하는 데 도움이 되도록 작업 영역 역할을 참조하세요.
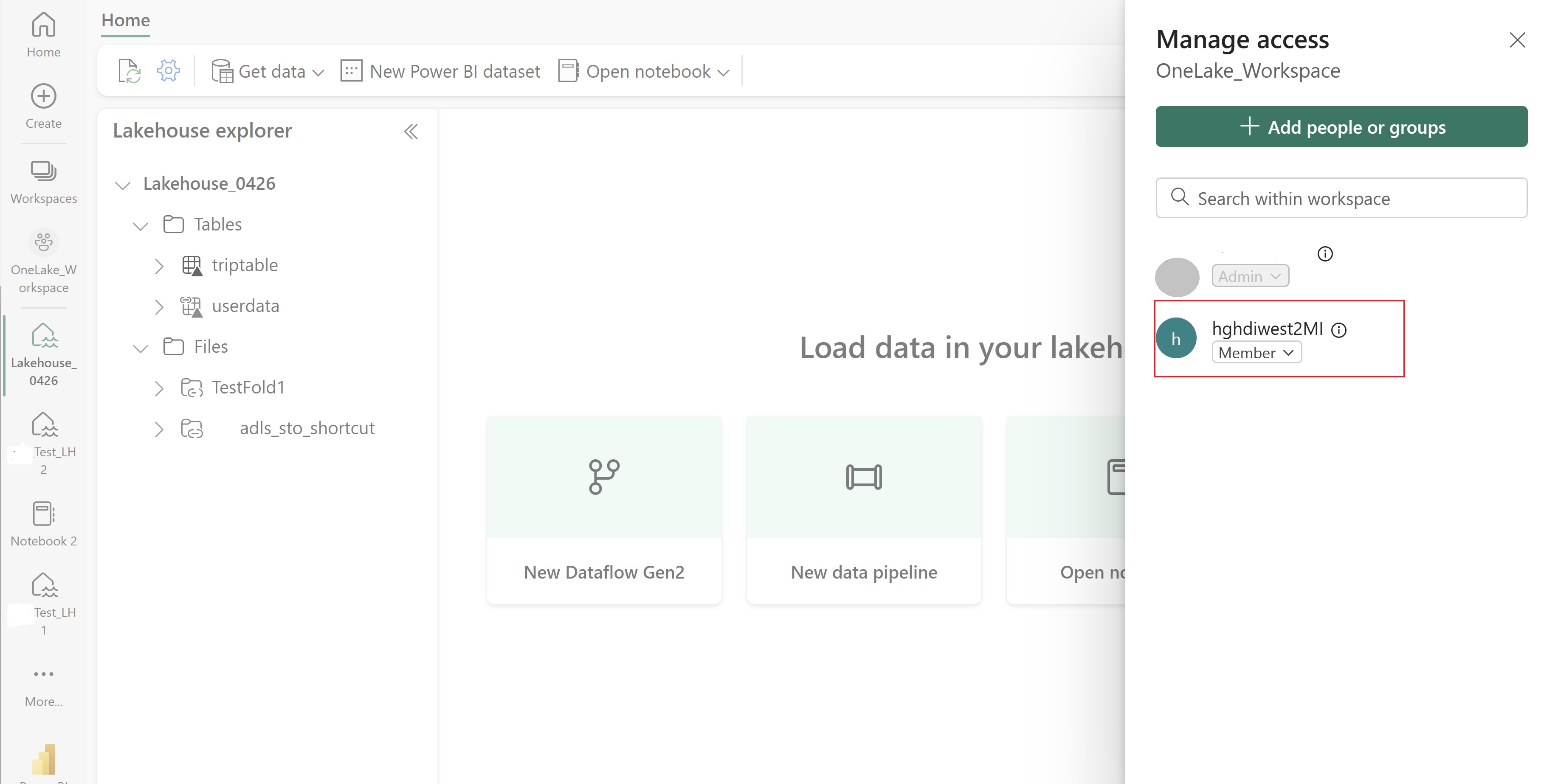
레이크하우스로 이동하여 작업 영역 및 레이크하우스의 이름을 찾습니다. 레이크하우스의 URL 또는 파일의 속성 창에서 찾을 수 있습니다.
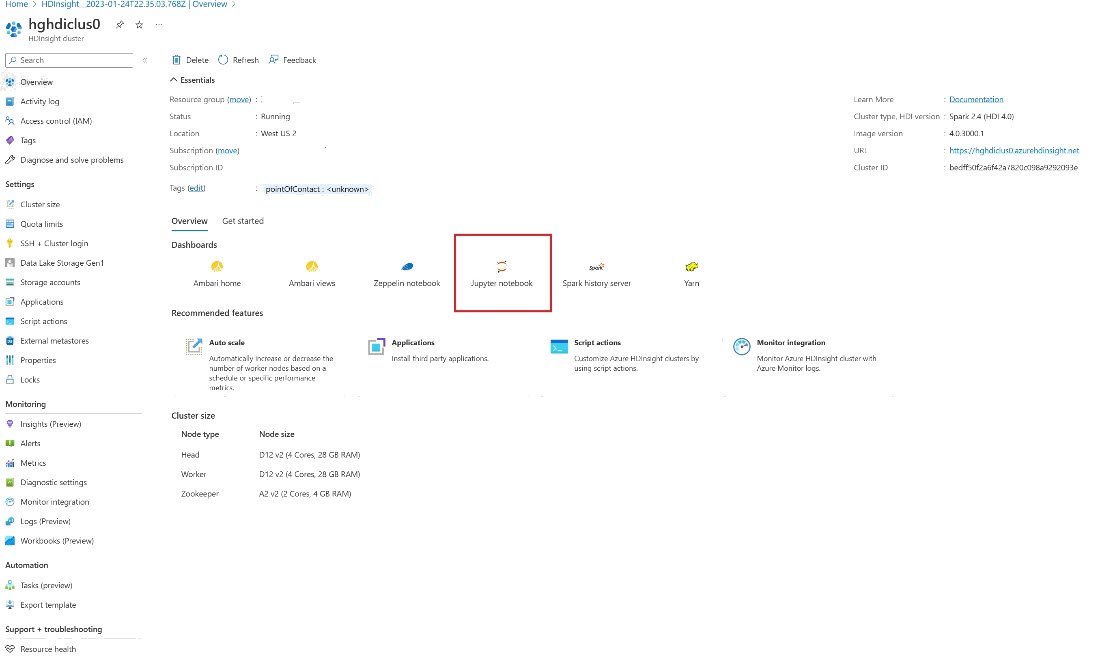
Azure Portal에서 클러스터를 찾아 Notebook을 선택합니다.
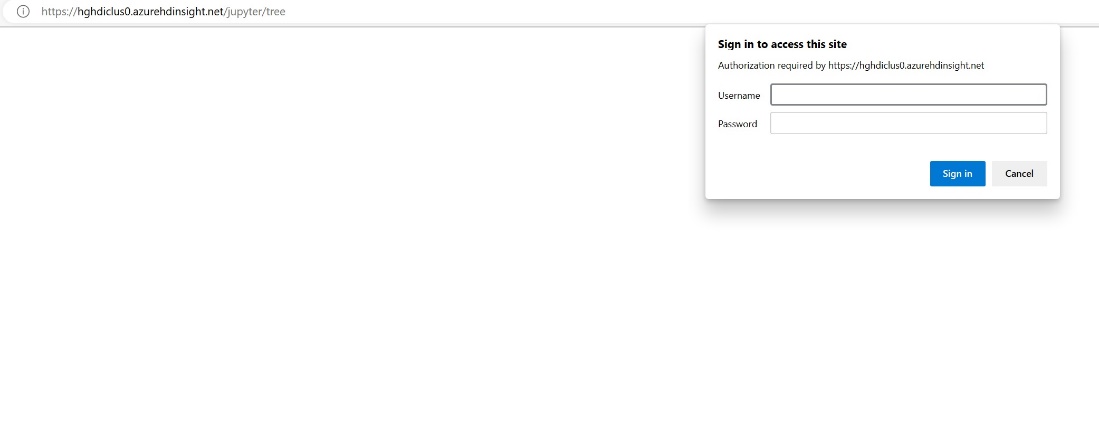
클러스터를 만드는 동안 제공한 자격 증명 정보를 입력합니다.
새 Apache Spark Notebook을 만듭니다.
작업 영역 및 레이크하우스 이름을 Notebook에 복사하고 레이크하우스에 대한 OneLake URL을 작성합니다. 이제 이 파일 경로에서 모든 파일을 읽을 수 있습니다.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()레이크하우스에 일부 데이터를 작성해 보세요.
writecsvdf = df.write.format("csv").save(fp + "out.csv")레이크하우스에서 확인하거나 새로 로드된 파일을 읽어 데이터가 성공적으로 작성되었는지 테스트합니다.




이제 HDI Spark 클러스터의 Jupyter Notebook을 사용하여 OneLake에서 데이터를 읽고 쓸 수 있습니다.