이 문서에서는 OneLake에서 새 테이블 또는 기존 테이블로 데이터를 가져오는 방법을 알아봅니다.
필수 조건
- Microsoft Fabric 지원 용량이 있는 작업 공간
- 레이크하우스
- 편집 권한이 있는 KQL 데이터베이스
1단계: 원본
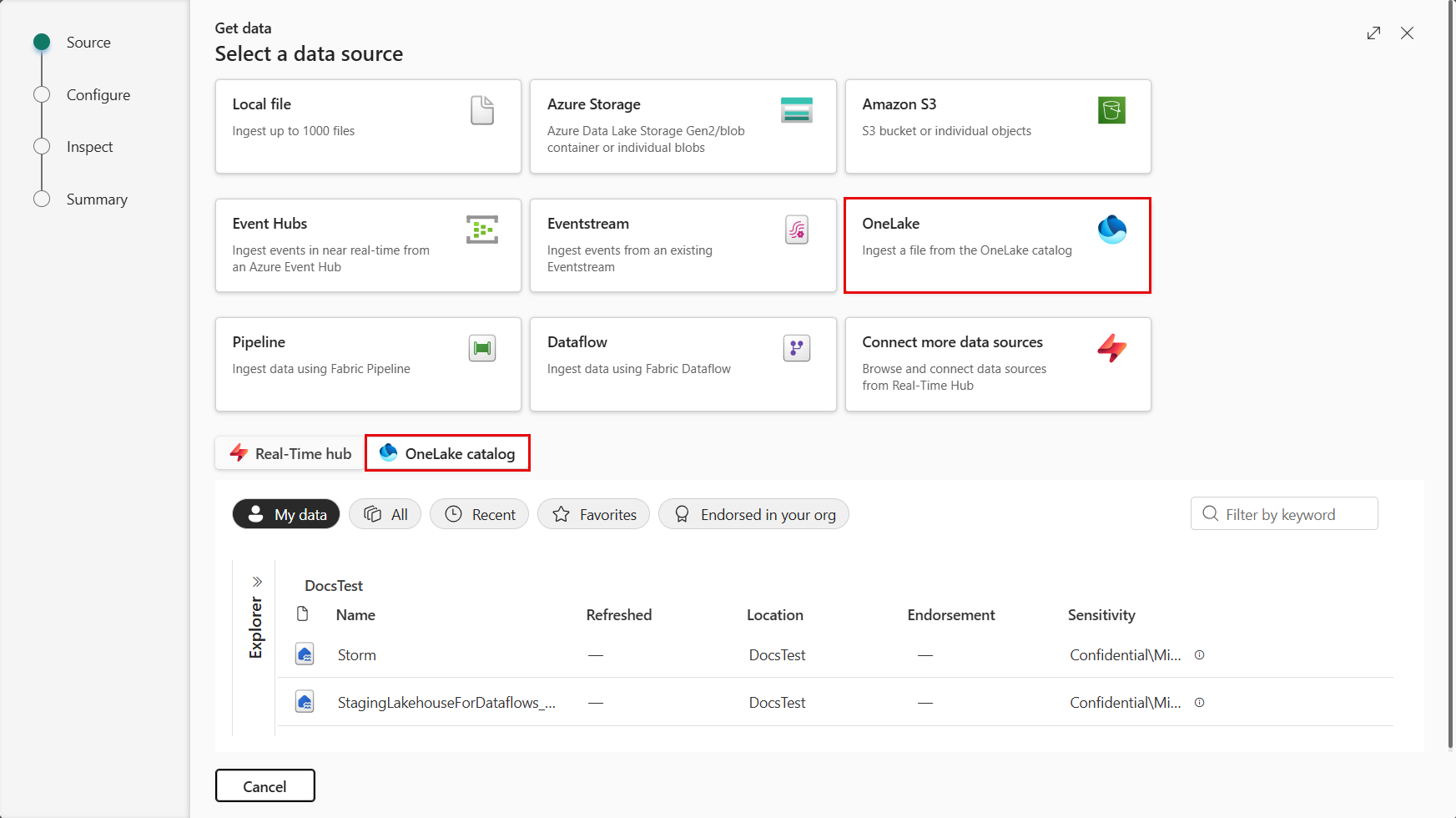
다음과 같이 데이터 원본으로 OneLake를 선택합니다.
KQL 데이터베이스의 아래쪽 리본에서 데이터 가져오기를 선택하여 데이터 가져오기 창의 원본 탭을 엽니다.
데이터 원본을 선택합니다. 이 예제에서는 OneLake 또는 포함된 OneLake 카탈로그의 목록에서 데이터를 수집합니다.
비고
포함된 OneLake 카탈로그의 목록에서 원본을 선택하면 범주 단추를 사용하거나 키워드별로 필터링하여 특정 소스를 검색할 수 있습니다.

2단계: 구성
대상 테이블을 선택하고 다음과 같이 원본을 구성합니다.
대상 테이블을 선택합니다. 새 테이블에 데이터를 수집하려면 + 새 테이블을 선택하고 테이블 이름을 입력합니다.
비고
테이블 이름은 공백, 영숫자, 하이픈 및 밑줄을 포함하여 최대 1,024자 까지 사용하실 수 있습니다. 특수 문자는 지원되지 않습니다.
수집할 OneLake 파일을 선택합니다.
원본으로 OneLake를 선택하는 경우 드롭다운에서 작업 영역, Lakehouse 및 파일을 지정해야 합니다.
포함된 OneLake 카탈로그 를 원본으로 선택하면 작업 영역 과 Lakehouse 가 자동으로 채워집니다. 수집할 파일을 지정해야 합니다.

다음을 선택합니다.

3단계: 검사
데이터 미리 보기가 있는 검사 탭이 열립니다.
완료하려면 인제스트 프로세스를 종료를 선택합니다.

수집된 데이터를 보고, 검사하고, 구성할 수 있습니다. 이미지의 숫자는 다음 옵션에 해당합니다.
(1) 입력에서 생성된 자동 명령을 보시고 복사하시기 위해서 명령 보기를 선택합니다.
(2) 스키마 정의 파일 드롭다운을 사용하여 스키마가 추론된 파일을 변경합니다.
(3) 드롭다운에서 원하는 형식을 선택하여 자동으로 유추된 데이터 형식을 변경합니다. 자세한 내용은 실시간 인텔리전스에서 지원하는 데이터 형식을 참조하세요.
(4) 열을 편집합니다.
(5) 데이터 형식에 따른 고급 옵션을 탐색합니다.
열을 편집합니다
비고
- 테이블 형식(CSV, TSV, PSV)의 경우 열을 두 번 매핑할 수 없습니다. 기존 열에 매핑하려면 먼저 새 열을 삭제합니다.
- 기존 열 유형은 변경할 수 없습니다. 다른 형식의 열에 매핑하려고 하면 빈 열이 생길 수 있습니다.
테이블에서 변경할 수 있는 사항은 다음 매개 변수에 따라 다릅니다.
- 테이블 유형은 신규 또는 기존입니다.
- 매핑 유형은 신규 또는 기존입니다.
| 테이블 유형입니다. | 매핑 유형 | 사용 가능한 조정 |
|---|---|---|
| 새 테이블 | 새 매핑 | 열 이름 바꾸기, 데이터 형식 변경, 데이터 원본 변경, 매핑 변환, 열 추가, 열 삭제 |
| 기존 테이블 | 새 매핑 | 열 추가(여기서 데이터 형식 변경, 이름 바꾸기 및 업데이트 가능) |
| 기존 테이블 | 기존 매핑 | 없음 |

맵 변환
일부 데이터 형식 매핑(Parquet, JSON 및 Avro)은 간단한 수집 시간 변환을 지원합니다. 매핑 변환을 적용하려면 열 편집 창에서 열을 만들거나 업데이트합니다.
매핑 변환은 형식 문자열 또는 날짜/시간의 열에서 수행할 수 있으며 원본의 데이터 형식이 int 또는 long입니다. 자세한 내용은 지원되는 매핑 변환의 전체 목록을 참조하세요.
데이터 형식에 따른 고급 옵션
테이블 형식(CSV, TSV, PSV):
기존 테이블에서 테이블 형식을 수집하는 경우 고급>테이블 스키마 유지를 선택할 수 있습니다. 테이블 형식 데이터에는 원본 데이터를 기존 열에 매핑하는 데 사용되는 열 이름이 반드시 포함되지는 않습니다. 이 옵션을 선택하면 매핑은 순서대로 수행되고 테이블 스키마는 동일하게 유지됩니다. 이 옵션을 선택하지 않으면 데이터 구조에 관계없이 수신 데이터에 대해 새 열이 만들어집니다.
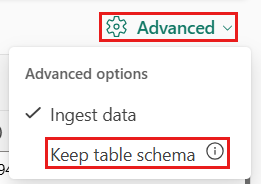
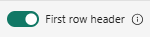
테이블 형식 데이터에는 원본 데이터를 기존 열에 매핑하는 데 사용되는 열 이름이 반드시 포함되지는 않습니다. 첫 번째 행을 열 이름으로 사용하기 위해서는 첫 번째 행을 열 머리글로 선택해 주세요.
4단계: 요약
데이터 수집이 완료되면 데이터 준비 창에서 세 단계가 모두 녹색 확인 표시로 나타납니다. 쿼리할 카드를 선택하거나, 수집된 데이터를 삭제하거나, 수집 요약의 대시보드를 볼 수 있습니다.
