자연어 Q&A에 대한 데이터 원본
Power BI의 Q&A 기능을 사용하면 자연어를 사용하여 데이터에 대한 질문을 함으로써 데이터에 대한 답변을 빠르게 얻을 수 있습니다. 이 문서에서는 Q&A에 지원되는 구성과 인덱싱 및 캐싱이 각 구성의 성능을 향상시키는 방법을 설명합니다.
지원되는 데이터 원본
Power BI Q&A는 Power BI Desktop에서 다음과 같은 데이터 원본 구성을 지원합니다.
- 가져오기 모드입니다.
- 온-프레미스 SQL Server Analysis Services, Azure Analysis Services 또는 Power BI 데이터 세트를 사용하는 라이브 연결 모드입니다. 그러나 DirectLake 및 Lakehouse Power BI 데이터 세트는 지원되지 않습니다.
- Azure Synapse Analytics, Azure SQL 또는 SQL Server 2019를 사용하는 DirectQuery입니다. 다른 원본은 직접 쿼리 모드에서 작동할 수 있지만 공식적으로 지원되지는 않습니다.
보고서에서 Q&시각적 개체를 사용하면 기본적으로 자연어 Q&A를 사용할 수 있습니다. DirectQuery 또는 라이브 연결을 사용하는 경우 프롬프트가 나타납니다.
Power BI Desktop에서 보고서에 대한 자연어 기능을 명시적으로 설정하거나 해제하려면 다음을 수행합니다.
- 파일>옵션 및 설정>옵션.
현재 파일 데이터 로드 아래에서, 데이터에 대한 자연어 질문을 할 수 있도록 Q&A 켜기를 선택하거나 선택 취소합니다.
Power BI Desktop Q&A 옵션을 보여주는 스크린샷 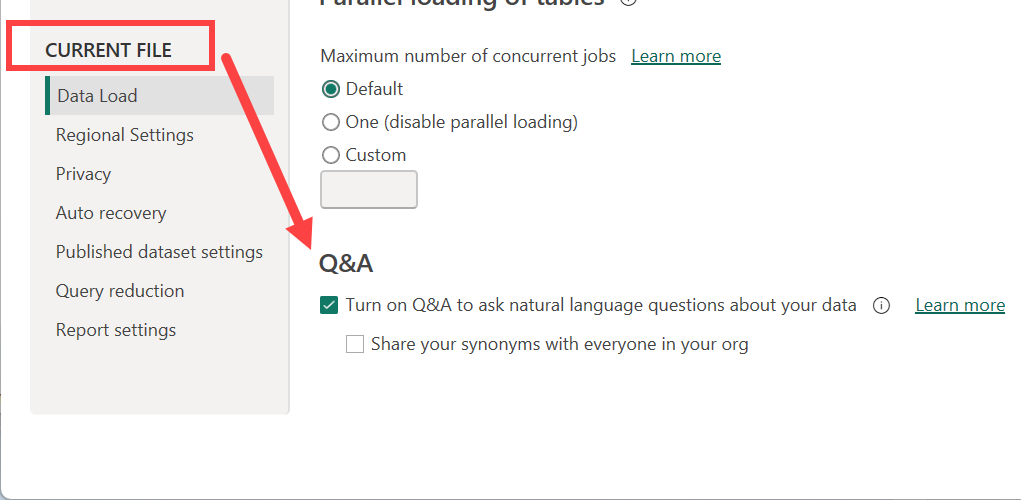
자세한 내용은 Power BI Q의 제한 사항&을 참조하세요.
Q&A 인덱싱
Q&A를 사용하도록 설정하면 인덱스가 작성되어 사용자에게 실시간 피드백을 신속하게 제공하고 질문을 해석할 수 있습니다. 인덱스가 빌드하는 데 다소 시간이 걸릴 수 있습니다. 인덱스에는 다음과 같은 특성이 있습니다.
- Q&A 도구 내에서 명시적으로 해제되지 않는 한 모든 열 이름과 테이블이 인덱스로 삽입됩니다.
- 100자 미만의 모든 텍스트 값이 인덱싱됩니다. 100자 이상의 텍스트 값은 인덱싱되지 않습니다.
- Q&A 인덱스가 최대 5백만 개의 고유 값을 저장합니다. 이 숫자를 초과하면 인덱스가 모든 잠재적 값을 보유하지 않으므로 Q&정확도가 저하될 수 있습니다.
- Q&A 인덱스는 처음 1,000개의 모델 엔터티(테이블 및 필드)를 기반으로 빌드됩니다. 데이터 모델이 이 수를 초과하면 인덱스에 잠재적인 모델 엔터티가 모두 포함되지 않으므로 Q&정확도가 저하될 수 있습니다.
- 인덱싱 중에 오류가 발생하면 인덱스는 부분 상태로 유지되고 다음 새로 고침 시 다시 만들어집니다.
인덱스 새로 고침 및 캐싱
Q&A를 사용하면 Power BI Desktop에서 인덱스가 만들어집니다. 인덱스를 작성할 때 작은 아이콘이 나타납니다. 인덱스가 빌드되는 동안 Q&시각적 요소 및 제안이 로드되는 데 시간이 다소 걸릴 수 있습니다.
모델이 변경되거나 인덱스가 오래되면 인덱스가 업데이트되어야 합니다. 인덱스를 다시 작성하는 데 시간이 걸릴 수 있으므로 변경이 발생할 때와 동일한 세션에서 Q&A를 사용하는 경우에만 인덱스가 업데이트됩니다.
Power BI 서비스에서 인덱스는 게시, 다시 게시 및 새로 고침 시 다시 생성됩니다. Q&인덱스 만들기는 항상 자동이 아니며 요청 시 데이터 세트 새로 고침을 최적화하기 위해 발생할 수 있습니다. DirectQuery의 경우, DirectQuery 원본에 미치는 영향을 줄이기 위해&데이터는 하루에 많아야 한 번 인덱싱 됩니다.
관련 콘텐츠
보고서에 자연어를 통합하는 방법에 대한 자세한 내용은 다음을 참조하세요.
- Power BI 보고서에서 시각적 개체 만들기 Q&
- Power BI
Q&A를 최적화하는 모범 사례