요약
| 항목 | 설명 |
|---|---|
| 릴리스 상태 | 일반 공급 |
| 제품 | Excel Power BI(의미 체계 모델) Power BI(데이터 흐름) 패브릭(데이터 흐름 Gen2) Power Apps(데이터 흐름) Analysis Services |
| 지원되는 인증 유형 | 기본 데이터베이스 Windows |
| 함수 참조 설명서 | SapHana.Database |
참고 항목
일부 기능은 한 제품에 있을 수 있지만 배포 일정 및 호스트별 기능으로 인해 다른 기능은 없을 수 있습니다.
필수 조건
웹 사이트에 로그인하고 드라이버를 다운로드하려면 SAP 계정이 필요합니다. 확실하지 않은 경우 조직의 SAP 관리자에게 문의하세요.
Power BI Desktop 또는 Excel에서 SAP HANA를 사용하려면 SAP HANA 데이터 연결이 제대로 작동하려면 로컬 클라이언트 컴퓨터에 SAP HANA ODBC 드라이버가 설치되어 있어야 합니다. 필요한 ODBC 드라이버가 들어 있는 SAP Development Tools에서 SAP HANA 클라이언트 도구를 다운로드할 수 있습니다. 또는 SAP 소프트웨어 다운로드 센터에서 다운로드할 수 있습니다. 소프트웨어 포털에서 Windows 컴퓨터용 SAP HANA CLIENT를 검색해 보세요. SAP 소프트웨어 다운로드 센터는 구조가 자주 변경되기 때문에 더 구체적인 사이트 탐색 지침은 제공할 수 없습니다. SAP HANA ODBC 드라이버 설치에 대한 지침은 Windows 64 비트에 SAP HANA ODBC 드라이버 설치로 이동 하세요.
Excel에서 SAP HANA를 사용하려면 로컬 클라이언트 컴퓨터에 32비트 또는 64비트 버전의 Excel을 사용하는지 여부에 따라 32비트 또는 64비트 SAP HANA ODBC 드라이버가 설치되어 있어야 합니다.
이 기능은 Office 2019 또는 Microsoft 365 구독이 있는 경우에만 Windows용 Excel에서 사용할 수 있습니다. Microsoft 365 구독자 인 경우 최신 버전의 Office가 있는지 확인합니다.
HANA 1.0 SPS 12rev122.09, 2.0 SPS 3rev30 및 BW/4HANA 2.0이 지원됩니다.
지원되는 기능
- 가져오기
- 직접 쿼리(Power BI 의미 체계 모델)
- 고급
- SQL 문
파워 쿼리 데스크톱에서 SAP HANA 데이터베이스로 커넥트
파워 쿼리 데스크톱에서 SAP HANA 데이터베이스에 연결하려면 다음을 수행합니다.
Excel의 데이터 > 리본에서 Power BI Desktop 또는 SAP HANA 데이터베이스에서 데이터 > 가져오기 SAP HANA 데이터베이스 를 선택합니다.
연결할 SAP HANA 서버의 이름과 포트를 입력합니다. 다음 그림의 예제는 포트
30015에서 사용합니다SAPHANATestServer.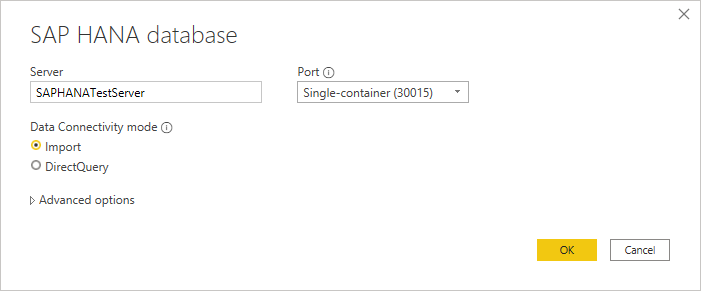
기본적으로 포트 번호는 단일 컨테이너 데이터베이스를 지원하도록 설정됩니다. SAP HANA 데이터베이스에 둘 이상의 다중 테넌트 데이터베이스 컨테이너를 포함할 수 있는 경우 다중 컨테이너 시스템 데이터베이스(30013)를 선택합니다. 기본 인스턴스 번호가 아닌 테넌트 데이터베이스 또는 데이터베이스에 연결하려면 포트 드롭다운 메뉴에서 사용자 지정을 선택합니다.
Power BI Desktop에서 SAP HANA 데이터베이스에 연결하는 경우 가져오기 또는 DirectQuery를 선택하는 옵션도 제공됩니다. 이 문서의 예제에서는 기본값인 Import(Excel의 유일한 모드)를 사용합니다. Power BI Desktop에서 DirectQuery를 사용하여 데이터베이스에 연결하는 방법에 대한 자세한 내용은 Power BI에서 DirectQuery를 사용하여 SAP HANA 데이터 원본에 커넥트.
SQL 문을 입력하거나 고급 옵션에서 열 바인딩을 사용하도록 설정할 수도 있습니다. 고급 옵션을 사용하여 커넥트 추가 정보
모든 옵션을 입력한 후 확인을 선택합니다.
데이터베이스에 처음으로 액세스하는 경우 인증을 위해 자격 증명을 입력하라는 메시지가 표시됩니다. 이 예제에서 SAP HANA 서버에는 데이터베이스 사용자 자격 증명이 필요하므로 데이터베이스를 선택하고 사용자 이름과 암호를 입력합니다. 필요한 경우 서버 인증서 정보를 입력합니다.
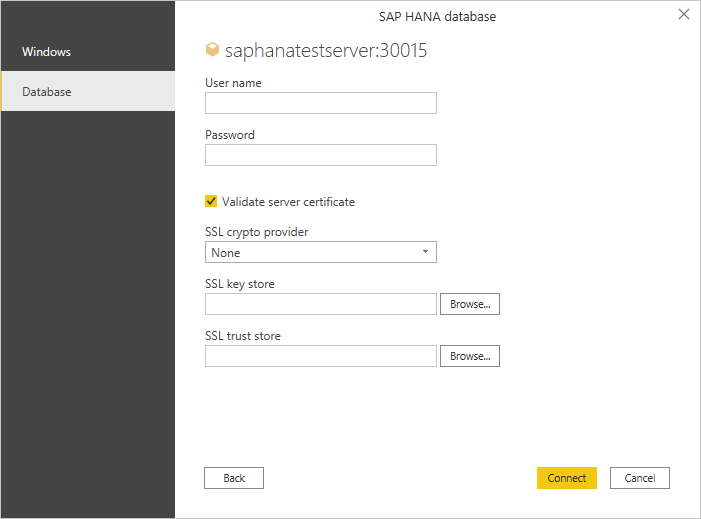
또한 서버 인증서의 유효성을 검사해야 할 수도 있습니다. 서버 인증서 선택 유효성 검사 사용에 대한 자세한 내용은 SAP HANA 암호화 사용을 참조하세요. Power BI Desktop 및 Excel에서는 기본적으로 서버 인증서 선택의 유효성을 검사할 수 있습니다. ODBC Data Source 관리istrator에서 이러한 선택 항목을 이미 설정한 경우 서버 인증서 유효성 검사 검사 확인란의 선택을 취소합니다. ODBC 데이터 원본 관리istrator를 사용하여 이러한 선택을 설정하는 방법에 대한 자세한 내용은 SAP HANA에 대한 ODBC 클라이언트 액세스에 대한 SSL 구성으로 이동하세요.
인증에 대한 자세한 내용은 데이터 원본을 사용한 인증으로 이동하세요.
모든 필수 정보를 입력했으면 커넥트 선택합니다.
탐색기 대화 상자에서 데이터 변환을 선택하여 파워 쿼리 편집기에서 데이터를 변환하거나 로드를 선택하여 데이터를 로드할 수 있습니다.
파워 쿼리 Online에서 SAP HANA 데이터베이스로 커넥트
파워 쿼리 Online에서 SAP HANA 데이터에 연결하려면 다음을 수행합니다.
데이터 원본 페이지에서 SAP HANA 데이터베이스를 선택합니다.
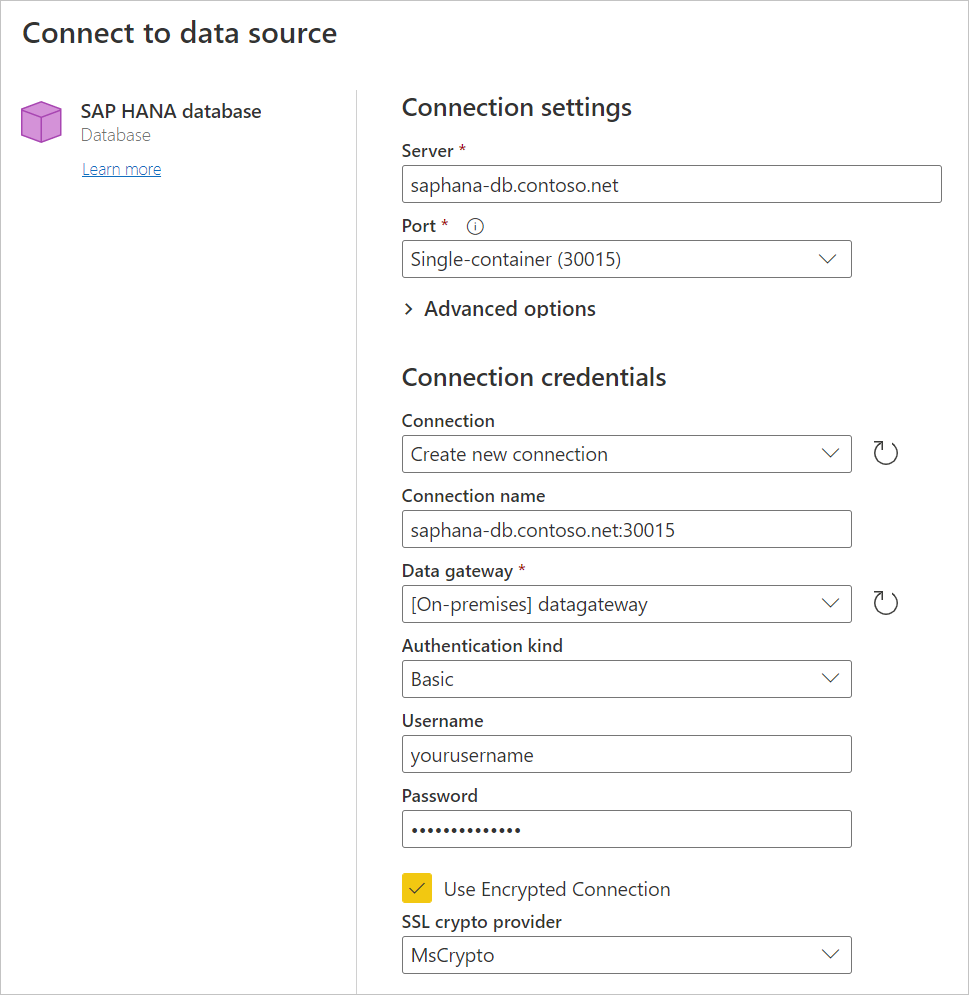
연결할 SAP HANA 서버의 이름과 포트를 입력합니다. 다음 그림의 예제는 포트
30015에서 사용합니다SAPHANATestServer.데이터베이스에 액세스하는 데 사용할 온-프레미스 데이터 게이트웨이의 이름을 선택합니다.
참고 항목
데이터가 로컬인지 온라인인지 여부에 관계없이 이 커넥터에서 온-프레미스 데이터 게이트웨이를 사용해야 합니다.
데이터에 액세스하는 데 사용할 인증 종류를 선택합니다. 또한 사용자 이름과 암호를 입력해야 합니다.
참고 항목
현재 파워 쿼리 온라인은 기본 인증만 지원합니다.
암호화된 연결을 사용하는 경우 암호화된 커넥트ion 사용을 선택한 다음, SSL 암호화 공급자를 선택합니다. 암호화된 연결을 사용하지 않는 경우 암호화된 커넥트 사용 취소합니다. 추가 정보: SAP HANA에 암호화 사용
다음을 선택하여 작업을 계속할 수 있습니다.
탐색기 대화 상자에서 데이터 변환을 선택하여 파워 쿼리 편집기에서 데이터를 변환하거나 로드를 선택하여 데이터를 로드할 수 있습니다.
고급 옵션을 사용하여 연결
파워 쿼리는 필요한 경우 쿼리에 추가할 수 있는 고급 옵션 집합을 제공합니다.
다음 표에서는 파워 쿼리에서 설정할 수 있는 모든 고급 옵션에 대해 설명합니다.
| 고급 옵션 | 설명 |
|---|---|
| SQL 문 | 자세한 정보, 네이티브 데이터베이스 쿼리를 사용하여 데이터베이스에서 데이터 가져오기 |
| 열 바인딩 사용 | 데이터를 가져올 때 SAP HANA 결과 집합의 열에 변수를 바인딩합니다. 메모리 사용률을 약간 더 높이면 성능이 향상될 가능성이 있습니다. 이 옵션은 파워 쿼리 Desktop에서만 사용할 수 있습니다. 추가 정보: 열 바인딩 사용 |
| ConnectionTimeout | 서버에 연결하려는 시도를 중단하기 전에 대기하는 시간을 제어하는 기간입니다. 기본값은 15초입니다. |
| CommandTimeout | 서버 쪽 쿼리가 취소되기 전에 실행할 수 있는 기간을 제어하는 기간입니다. 기본값은 10분입니다. |
SAP HANA에 대해 지원되는 기능
다음 목록에서는 SAP HANA에 대해 지원되는 기능을 보여줍니다. 여기에 나열된 모든 기능이 SAP HANA 데이터베이스 커넥터의 모든 구현에서 지원되는 것은 아닙니다.
SAP HANA 데이터베이스용 Power BI Desktop 및 Excel 커넥터는 모두 SAP ODBC 드라이버를 사용하여 최상의 사용자 환경을 제공합니다.
Power BI Desktop에서 SAP HANA는 DirectQuery 및 가져오기 옵션을 모두 지원합니다.
Power BI Desktop은 분석 및 계산 뷰와 같은 HANA 정보 모델을 지원하며 탐색을 최적화했습니다.
SAP HANA를 사용하면 네이티브 데이터베이스 쿼리 SQL 문의 SQL 명령을 사용하여 탐색기 환경에서 제공하는 분석/계산 뷰에 포함되지 않은 HANA 카탈로그 테이블의 행 및 열 테이블에 연결할 수도 있습니다. ODBC 커넥터를 사용하여 이러한 테이블을 쿼리할 수도 있습니다.
Power BI Desktop에는 HANA 모델에 대한 최적화된 탐색이 포함되어 있습니다.
Power BI Desktop은 SAP HANA 변수 및 입력 매개 변수를 지원합니다.
Power BI Desktop은 HDI 컨테이너 기반 계산 뷰를 지원합니다.
이제 SapHana.Database 함수는 연결 및 명령 시간 제한을 지원합니다. 추가 정보: 고급 옵션을 사용하여 커넥트
Power BI에서 HDI 컨테이너 기반 계산 뷰에 액세스하려면 Power BI와 함께 사용하는 HANA 데이터베이스 사용자에게 액세스하려는 보기를 저장하는 HDI 런타임 컨테이너에 액세스할 수 있는 권한이 있는지 확인합니다. 이 액세스 권한을 부여하려면 HDI 컨테이너에 대한 액세스를 허용하는 역할을 만듭니다. 그런 다음 Power BI에서 사용할 HANA 데이터베이스 사용자에게 역할을 할당합니다. (이 사용자는 평소와 같이 _SYS_BI 스키마의 시스템 테이블에서 읽을 수 있는 권한이 있어야 합니다.) 데이터베이스 역할을 만들고 할당하는 방법에 대한 자세한 지침은 공식 SAP 설명서를 참조하세요. 이 SAP 블로그 게시물 은 시작하기에 좋은 장소일 수 있습니다.
현재 HDI 기반 계산 뷰에 연결된 HANA 변수에 대한 몇 가지 제한 사항이 있습니다. 해당 제한 사항은 HANA 쪽의 오류 때문에 발생합니다. 먼저 HDI 컨테이너 기반 계산 뷰의 공유 열에 HANA 변수를 적용할 수 없습니다. 이 제한을 해결하려면 HANA 2 버전 37.02 이상으로 업그레이드하거나 HANA 2 버전 42 이상으로 업그레이드하세요. 둘째, 변수 및 매개 변수의 다중 항목 기본값은 현재 Power BI UI에 표시되지 않습니다. SAP HANA의 오류 때문에 이러한 제한이 발생하지만 SAP에서 아직 수정을 발표하지 않았습니다.
열 바인딩 사용
데이터 원본에서 가져온 데이터는 애플리케이션이 이 목적을 위해 할당한 변수로 애플리케이션에 반환됩니다. 이 작업을 수행하기 전에 애플리케이션은 이러한 변수를 결과 집합의 열에 연결하거나 바인딩해야 합니다. 개념적으로 이 프로세스는 문 매개 변수에 애플리케이션 변수를 바인딩하는 것과 같습니다. 애플리케이션이 결과 집합 열에 변수를 바인딩할 때 해당 변수(주소, 데이터 형식 등)를 드라이버에 설명합니다. 드라이버는 이 정보를 해당 문에 대해 기본 구조에 저장하고 행을 가져올 때 이 정보를 사용하여 열에서 값을 반환합니다.
현재 파워 쿼리 데스크톱을 사용하여 SAP HANA 데이터베이스에 연결하는 경우 열 바인딩 사용 고급 옵션을 선택하여 열 바인딩 을 사용하도록 설정할 수 있습니다.
파워 쿼리 수식 입력줄 또는 고급 편집기에서 연결에 옵션을 수동으로 추가하여 EnableColumnBinding 기존 쿼리 또는 파워 쿼리 Online에서 사용되는 쿼리에서 열 바인딩을 사용하도록 설정할 수도 있습니다. 예시:
SapHana.Database("myserver:30015", [Implementation = "2.0", EnableColumnBinding = true]),
옵션을 수동으로 추가하는 것과 관련된 제한 사항이 있습니다.EnableColumnBinding
- 열 바인딩 사용은 가져오기 및 DirectQuery 모드 모두에서 작동합니다. 그러나 이 고급 옵션을 사용하도록 기존 DirectQuery 쿼리를 개조할 수는 없습니다. 대신 이 기능이 제대로 작동하려면 새 쿼리를 만들어야 합니다.
- SAP HANA Server 버전 2.0 이상에서는 열 바인딩이 전부 또는 전혀 없습니다. 일부 열을 바인딩할 수 없는 경우 바인딩되지 않으며 사용자가 예외(예:
DataSource.Error: Column MEASURE_UNIQUE_NAME of type VARCHAR cannot be bound (20002 > 16384)>)를 받게 됩니다. - SAP HANA 버전 1.0 서버가 항상 올바른 열 길이를 보고하는 것은 아닙니다. 이 컨텍스트
EnableColumnBinding에서는 부분 열 바인딩을 허용합니다. 일부 쿼리의 경우 열이 바인딩되지 않음을 의미할 수 있습니다. 열이 바인딩되지 않으면 성능상의 이점을 얻을 수 없습니다.
SAP HANA 데이터베이스 커넥터의 네이티브 쿼리 지원
파워 쿼리 SAP HANA 데이터베이스 커넥터는 네이티브 쿼리를 지원합니다. 파워 쿼리에서 네이티브 쿼리를 사용하는 방법에 대한 자세한 내용은 네이티브 데이터베이스 쿼리를 사용하여 데이터베이스에서 데이터 가져오기로 이동하세요.
네이티브 쿼리의 쿼리 폴딩
파워 쿼리 SAP HANA 데이터베이스 커넥터는 이제 네이티브 쿼리에서 쿼리 폴딩을 지원합니다. 추가 정보: 네이티브 쿼리에서 쿼리 폴딩
참고 항목
파워 쿼리 SAP HANA 데이터베이스 커넥터에서 네이티브 쿼리는 true로 설정된 경우 EnableFolding 중복 열 이름을 지원하지 않습니다.
네이티브 쿼리의 매개 변수
파워 쿼리 SAP HANA 데이터베이스 커넥터는 이제 네이티브 쿼리의 매개 변수를 지원합니다. Value.NativeQuery 구문을 사용하여 네이티브 쿼리에서 매개 변수를 지정할 수 있습니다.
다른 커넥터와 달리 SAP HANA 데이터베이스 커넥터는 EnableFolding = True 매개 변수를 동시에 지원하고 지정합니다.
쿼리에서 매개 변수를 사용하려면 코드에 물음표(?)를 자리 표시자로 배치합니다. 매개 변수를 지정하려면 텍스트 값과 해당 SqlType Value값을 사용합니다SqlType. Value 는 M 값일 수 있지만 지정된 SqlType값에 할당해야 합니다.
매개 변수를 지정하는 방법에는 여러 가지가 있습니다.
값만 목록으로 제공:
{ “Seattle”, 1, #datetime(2022, 5, 27, 17, 43, 7) }값 및 형식을 목록으로 제공:
{ [ SqlType = "CHAR", Value = "M" ], [ SqlType = "BINARY", Value = Binary.FromText("AKvN", BinaryEncoding.Base64) ], [ SqlType = "DATE", Value = #date(2022, 5, 27) ] }다음 두 가지를 혼합하고 일치합니다.
{ “Seattle”, 1, [ SqlType = "SECONDDATE", Value = #datetime(2022, 5, 27, 17, 43, 7) ] }
SqlType 는 SAP HANA에서 정의한 표준 형식 이름을 따릅니다. 예를 들어 다음 목록에는 사용되는 가장 일반적인 형식이 포함되어 있습니다.
- BIGINT
- BINARY
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- INTEGER
- NVARCHAR
- SECONDDATE
- SHORTTEXT
- SMALLDECIMAL
- SMALLINT
- TIME
- timestamp
- VARBINARY
- VARCHAR
다음 예제에서는 매개 변수 값 목록을 제공하는 방법을 보여 줍니다.
let
Source = Value.NativeQuery(
SapHana.Database(
"myhanaserver:30015",
[Implementation = "2.0"]
),
"select ""VARCHAR_VAL"" as ""VARCHAR_VAL""
from ""_SYS_BIC"".""DEMO/CV_ALL_TYPES""
where ""VARCHAR_VAL"" = ? and ""DATE_VAL"" = ?
group by ""VARCHAR_VAL""
",
{"Seattle", #date(1957, 6, 13)},
[EnableFolding = true]
)
in
Source
다음 예제에서는 레코드 목록을 제공하거나 값과 레코드를 혼합하는 방법을 보여 줍니다.
let
Source = Value.NativeQuery(
SapHana.Database(Server, [Implementation="2.0"]),
"select
""COL_VARCHAR"" as ""COL_VARCHAR"",
""ID"" as ""ID"",
sum(""DECIMAL_MEASURE"") as ""DECIMAL_MEASURE""
from ""_SYS_BIC"".""DEMO/CV_ALLTYPES""
where
""COL_ALPHANUM"" = ? or
""COL_BIGINT"" = ? or
""COL_BINARY"" = ? or
""COL_BOOLEAN"" = ? or
""COL_DATE"" = ?
group by
""COL_ALPHANUM"",
""COL_BIGINT"",
""COL_BINARY"",
""COL_BOOLEAN"",
""COL_DATE"",
{
[ SqlType = "CHAR", Value = "M" ], // COL_ALPHANUM - CHAR
[ SqlType = "BIGINT", Value = 4 ], // COL_BIGINT - BIGINT
[ SqlType = "BINARY", Value = Binary.FromText("AKvN", BinaryEncoding.Base64) ], // COL_BINARY - BINARY
[ SqlType = "BOOLEAN", Value = true ], // COL_BOOLEAN - BOOLEAN
[ SqlType = "DATE", Value = #date(2022, 5, 27) ], // COL_DATE - TYPE_DATE
} ,
[EnableFolding=false]
)
in
Source
동적 특성 지원
SAP HANA 데이터베이스 커넥터가 계산 열을 처리하는 방식이 개선되었습니다. SAP HANA 데이터베이스 커넥터는 "큐브" 커넥터이며 "큐브" 공간에서 발생하는 몇 가지 작업 집합(항목 추가, 열 축소 등)이 있습니다. 이 큐브 공간은 파워 쿼리 데스크톱 및 파워 쿼리 온라인 사용자 인터페이스에 더 일반적인 "테이블" 아이콘을 대체하는 "큐브" 아이콘으로 표시됩니다.
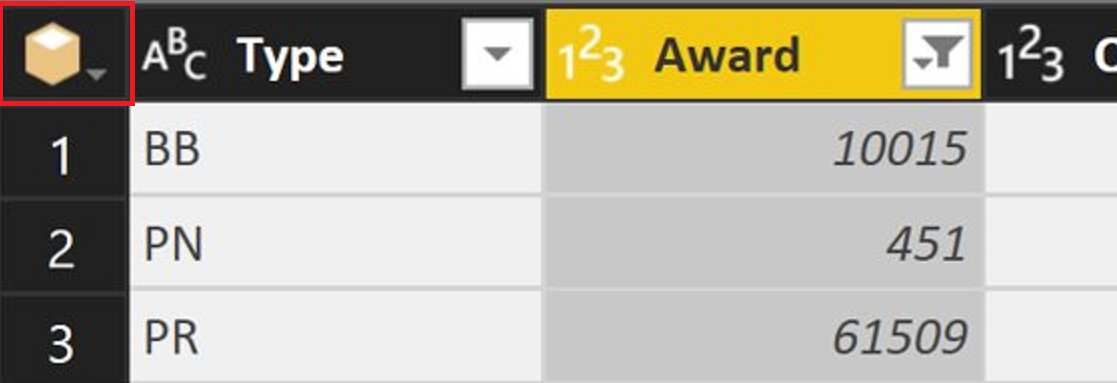
이전에는 테이블 열(또는 내부적으로 열을 추가하는 다른 변환)을 추가했을 때 쿼리가 "큐브 공간 중에서 삭제"되고 모든 작업이 테이블 수준에서 수행됩니다. 이 드롭아웃으로 인해 쿼리가 폴딩을 중지할 수 있습니다. 열을 추가한 후 큐브 작업을 수행할 수 없습니다.
이 변경으로 추가된 열은 큐브 내에서 동적 특성으로 처리됩니다. 이 작업을 위해 큐브 공간에 쿼리를 다시 기본 경우 열을 추가한 후에도 큐브 작업을 계속 사용할 수 있다는 장점이 있습니다.
참고 항목
이 새로운 기능은 SAP HANA Server 버전 2.0 이상의 계산 뷰에 연결하는 경우에만 사용할 수 있습니다.
다음 샘플 쿼리는 이 새로운 기능을 활용합니다. 과거에는 Cube.CollapseAndRemoveColumns를 적용할 때 "값이 큐브가 아닙니다" 예외가 발생합니다.
let
Source = SapHana.Database(“someserver:someport”, [Implementation="2.0"]),
Contents = Source{[Name="Contents"]}[Data],
SHINE_CORE_SCHEMA.sap.hana.democontent.epm.models = Contents{[Name="SHINE_CORE_SCHEMA.sap.hana.democontent.epm.models"]}[Data],
PURCHASE_ORDERS1 = SHINE_CORE_SCHEMA.sap.hana.democontent.epm.models{[Name="PURCHASE_ORDERS"]}[Data],
#"Added Items" = Cube.Transform(PURCHASE_ORDERS1,
{
{Cube.AddAndExpandDimensionColumn, "[PURCHASE_ORDERS]", {"[HISTORY_CREATEDAT].[HISTORY_CREATEDAT].Attribute", "[Product_TypeCode].[Product_TypeCode].Attribute", "[Supplier_Country].[Supplier_Country].Attribute"}, {"HISTORY_CREATEDAT", "Product_TypeCode", "Supplier_Country"}},
{Cube.AddMeasureColumn, "Product_Price", "[Measures].[Product_Price]"}
}),
#"Inserted Year" = Table.AddColumn(#"Added Items", "Year", each Date.Year([HISTORY_CREATEDAT]), Int64.Type),
#"Filtered Rows" = Table.SelectRows(#"Inserted Year", each ([Product_TypeCode] = "PR")),
#"Added Conditional Column" = Table.AddColumn(#"Filtered Rows", "Region", each if [Supplier_Country] = "US" then "North America" else if [Supplier_Country] = "CA" then "North America" else if [Supplier_Country] = "MX" then "North America" else "Rest of world"),
#"Filtered Rows1" = Table.SelectRows(#"Added Conditional Column", each ([Region] = "North America")),
#"Collapsed and Removed Columns" = Cube.CollapseAndRemoveColumns(#"Filtered Rows1", {"HISTORY_CREATEDAT", "Product_TypeCode"})
in
#"Collapsed and Removed Columns"
다음 단계
다음 문서에는 SAP HANA debase에 연결할 때 유용할 수 있는 추가 정보가 포함되어 있습니다.