비고
이 문서에서는 사용자 지정 커넥터에 대한 네이 티브 쿼리 지원 구현과 그 위에 있는 쿼리 폴딩 에 대한 고급 항목에 대해 설명합니다. 이 문서에서는 이러한 개념에 대한 실무 지식이 이미 있다고 가정합니다.
파워 쿼리 사용자 지정 커넥터에 대해 자세히 알아보려면 파워 쿼리 SDK 개요로 이동합니다.
파워 쿼리에서는 데이터 원본에 대해 사용자 지정 네이티브 쿼리를 실행하여 찾고 있는 데이터를 검색할 수 있습니다. 또한 이 프로세스 전체에서 쿼리 폴딩을 유지하고 파워 쿼리 내에서 수행되는 후속 변환 프로세스를 유지할 수 있습니다.
이 문서의 목표는 사용자 지정 커넥터에 대해 이러한 기능을 구현하는 방법을 보여 주는 것입니다.
필수 조건
이 문서에서는 데이터 원본에 SQL ODBC 드라이버를 사용하는 샘플 의 시작점으로 사용합니다. 네이티브 쿼리 기능의 구현은 현재 SQL-92 표준을 준수하는 ODBC 커넥터에 대해서만 지원됩니다.
샘플 커넥터는 SQL Server Native Client 11.0 드라이버를 사용합니다. 이 자습서와 함께 수행하도록 이 드라이버가 설치되어 있는지 확인합니다.
GitHub 리포지토리의 Finish 폴더 에서 샘플 커넥터의 완성된 버전을 볼 수도 있습니다.
커넥터의 SQLCapabilities를 수정하십시오.
SqlCapabilities 샘플 커넥터의 레코드에서 이름 Sql92Translation 및 값 PassThrough가 있는 레코드 필드를 찾을 수 있습니다. 이 새 필드는 유효성 검사 없이 파워 쿼리를 사용하여 네이티브 쿼리를 전달하는 데 필요합니다.
SqlCapabilities = Diagnostics.LogValue("SqlCapabilities_Options", defaultConfig[SqlCapabilities] & [
// Place custom overrides here
// The values below are required for the SQL Native Client ODBC driver, but might
// not be required for your data source.
SupportsTop = false,
SupportsDerivedTable = true,
Sql92Conformance = 8 /* SQL_SC_SQL92_FULL */,
GroupByCapabilities = 4 /* SQL_GB_NO_RELATION */,
FractionalSecondsScale = 3,
Sql92Translation = "PassThrough"
]),
앞으로 이동하기 전에 이 필드가 커넥터에 표시되는지 확인합니다. 그렇지 않은 경우 나중에 커넥터에서 선언되지 않으므로 지원되지 않는 기능을 사용하는 경우 경고 및 오류가 발생합니다.
커넥터 파일(.mez 또는.pqx)을 빌드하고 수동 테스트를 위해 Power BI Desktop에 로드하고 네이티브 쿼리의 대상을 정의합니다.
커넥터의 네이티브 쿼리 기능을 수동으로 테스트
비고
이 문서에서는 AdventureWorks2019 샘플 데이터베이스를 사용합니다. 그러나 선택한 모든 SQL Server 데이터베이스를 따라가서 선택한 데이터베이스의 세부 사항에 따라 필요한 변경을 수행할 수 있습니다.
이 문서에서 네이티브 쿼리 지원을 구현하는 방법은 사용자에게 다음 세 가지 값을 입력하도록 요청하는 것입니다.
- 서버 이름
- 데이터베이스 이름
- 데이터베이스 수준의 네이티브 쿼리
이제 Power BI Desktop 내에서 데이터 가져오기 환경으로 이동하여 SqlODBC 샘플이라는 이름의 커넥터를 찾습니다.
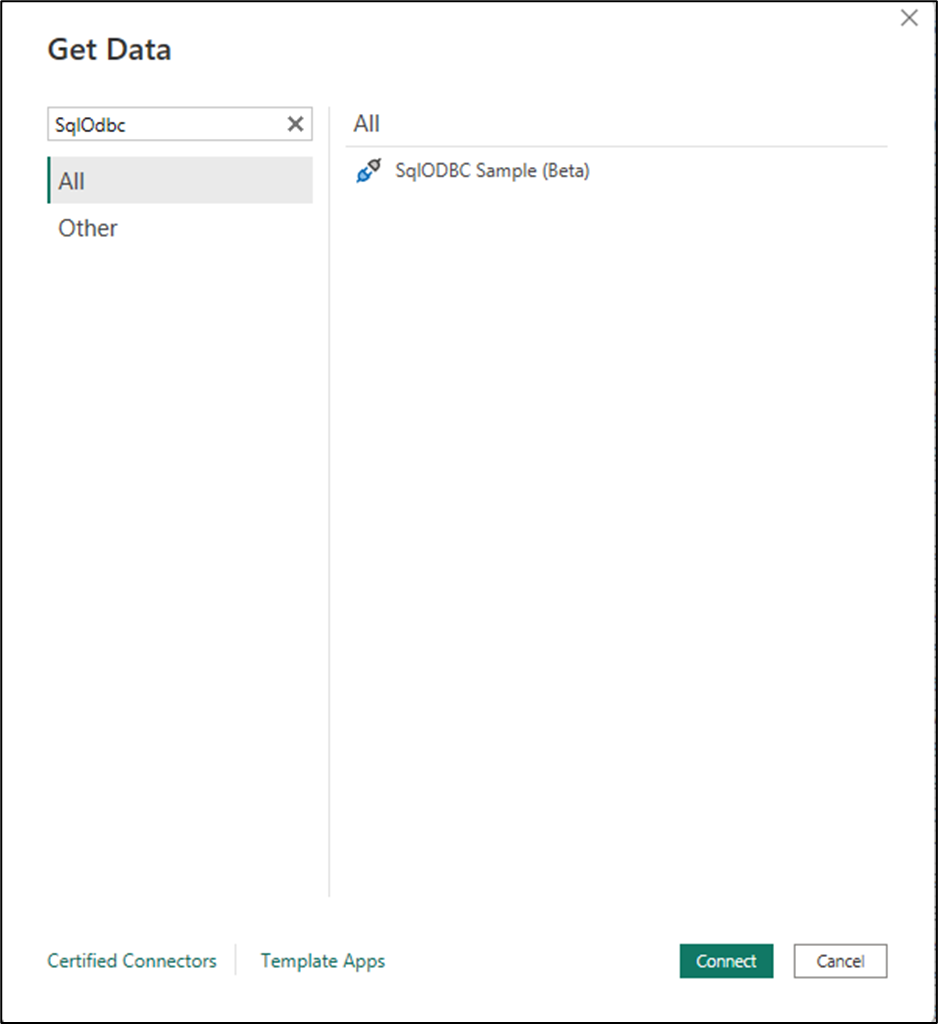
커넥터 대화 상자의 경우 서버 및 데이터베이스 이름에 대한 매개 변수를 입력합니다. 그런 다음 확인을 선택합니다.
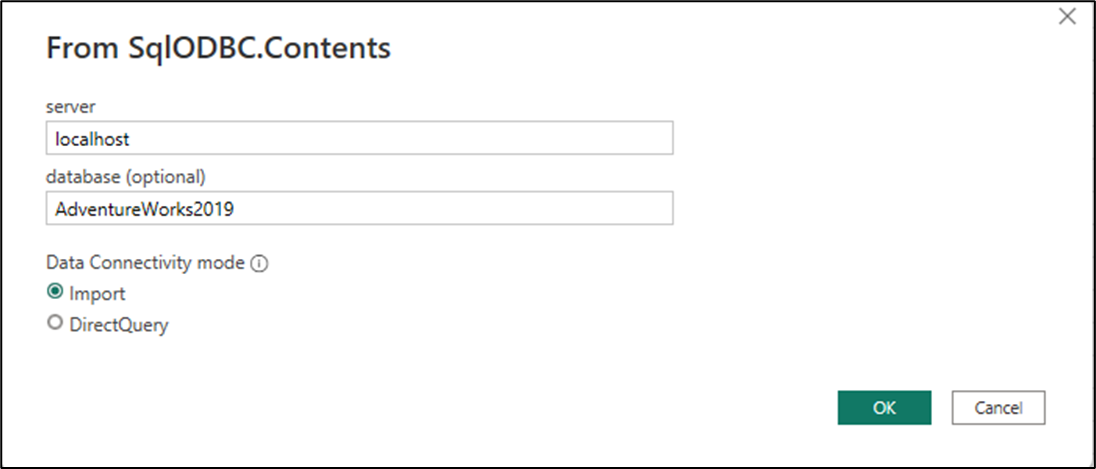
새 탐색기 창이 나타납니다. 탐색기에서 서버의 계층적 보기와 서버 내의 데이터베이스를 표시하는 SQL 드라이버에서 네이티브 탐색 동작을 볼 수 있습니다. AdventureWorks2019 데이터베이스를 마우스 오른쪽 단추로 클릭한 다음 데이터 변환을 선택합니다.
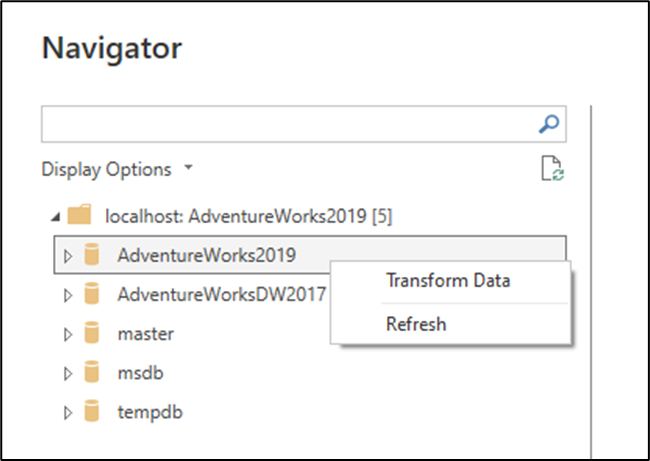
이 옵션을 선택하면 모든 네이티브 쿼리가 데이터베이스 수준에서 실행되어야 하기 때문에 파워 쿼리 편집기와 네이티브 쿼리의 대상에 대한 미리 보기가 제공됩니다. 마지막 단계의 수식 입력줄을 검사하여 커넥터를 실행하기 전에 네이티브 쿼리의 대상으로 이동하는 방법을 더 잘 이해합니다. 이 경우 수식 입력줄에는 다음 정보가 표시됩니다.
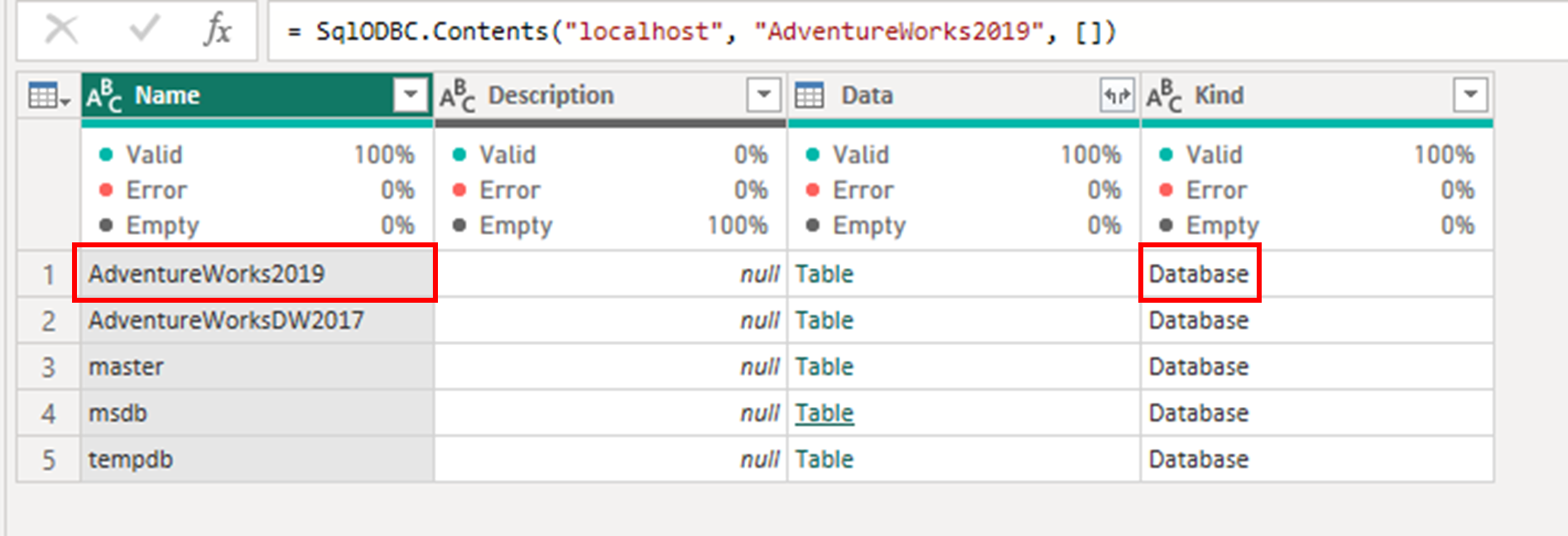
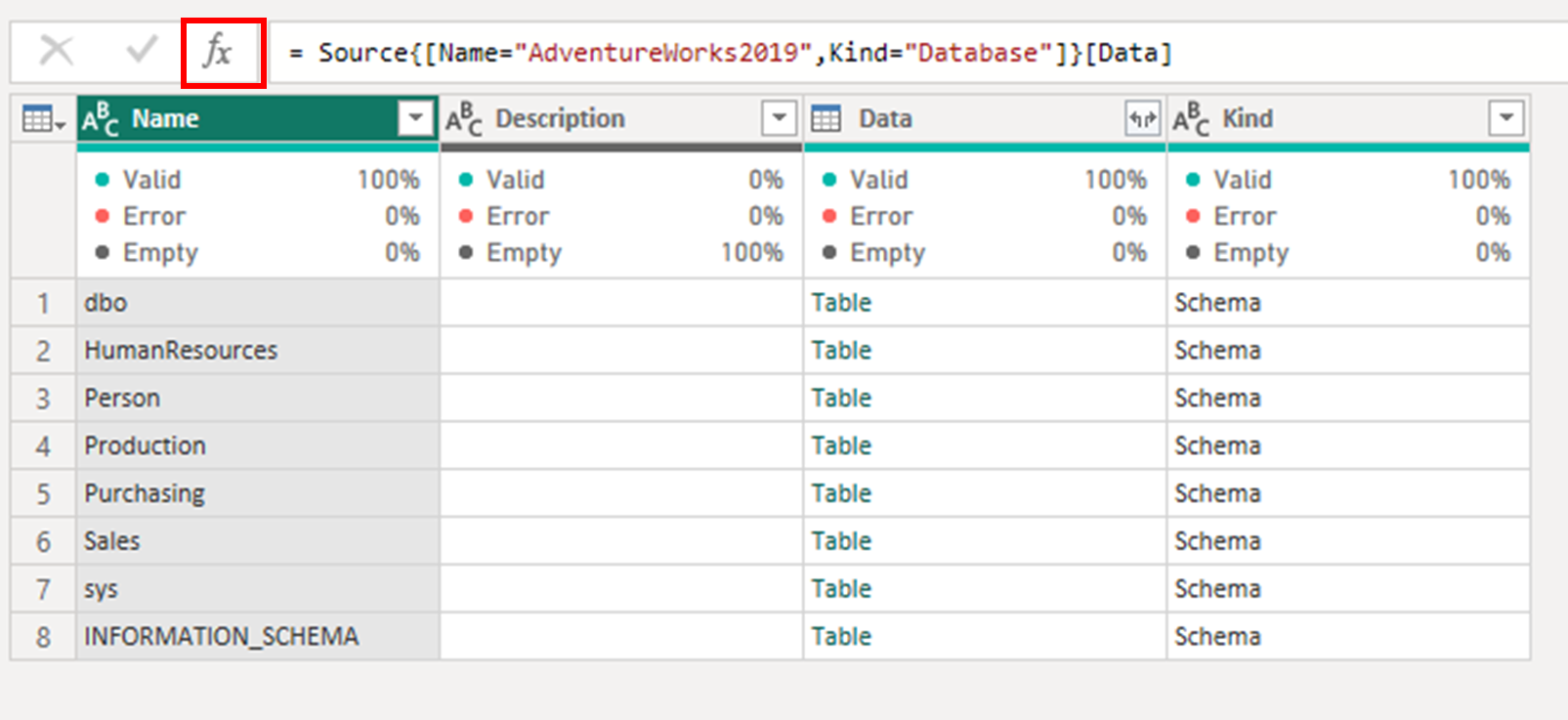
= Source{[Name="AdventureWorks2019",Kind="Database"]}[Data]
원본 은 이전 단계의 이름으로, 이 경우 매개 변수가 전달된 커넥터의 게시된 함수일 뿐입니다. 목록과 그 안의 레코드는 테이블을 특정 행으로 탐색하는 데 도움이 됩니다. 행은 이름 필드가 AdventureWorks2019 와 같아야 하고 종류 필드가 데이터베이스와 같아야 하는 레코드의 조건에 의해 정의됩니다. 행이 배치 [Data] 되면 목록 {} 외부를 통해 파워 쿼리가 데이터 필드 내의 값에 액세스할 수 있습니다. 이 경우 테이블입니다. 이전 단계(원본)로 돌아가서 이 탐색을 더 잘 이해할 수 있습니다.
네이티브 쿼리 테스트
이제 대상이 식별되면 수식 입력줄에서 fx 아이콘을 선택하여 탐색 단계 후에 사용자 지정 단계를 만듭니다.
수식 입력줄 안의 수식을 다음 수식으로 바꾼 다음 Enter 키를 선택합니다.
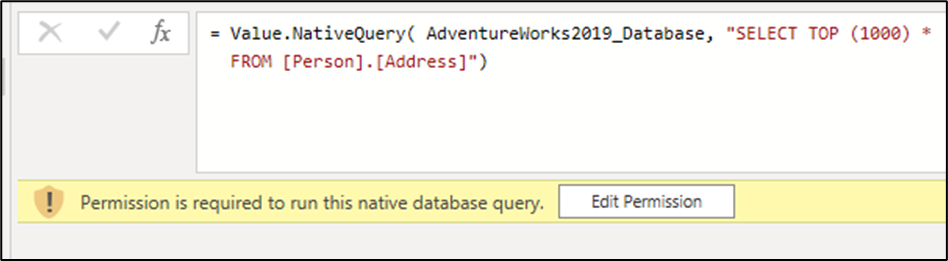
= Value.NativeQuery( AdventureWorks2019_Database, "SELECT TOP (1000) *
FROM [Person].[Address]")
이 변경 내용을 적용한 후에는 데이터 원본에 대해 네이티브 쿼리를 실행할 수 있는 권한을 요청하는 수식 입력줄 아래에 경고가 표시됩니다.
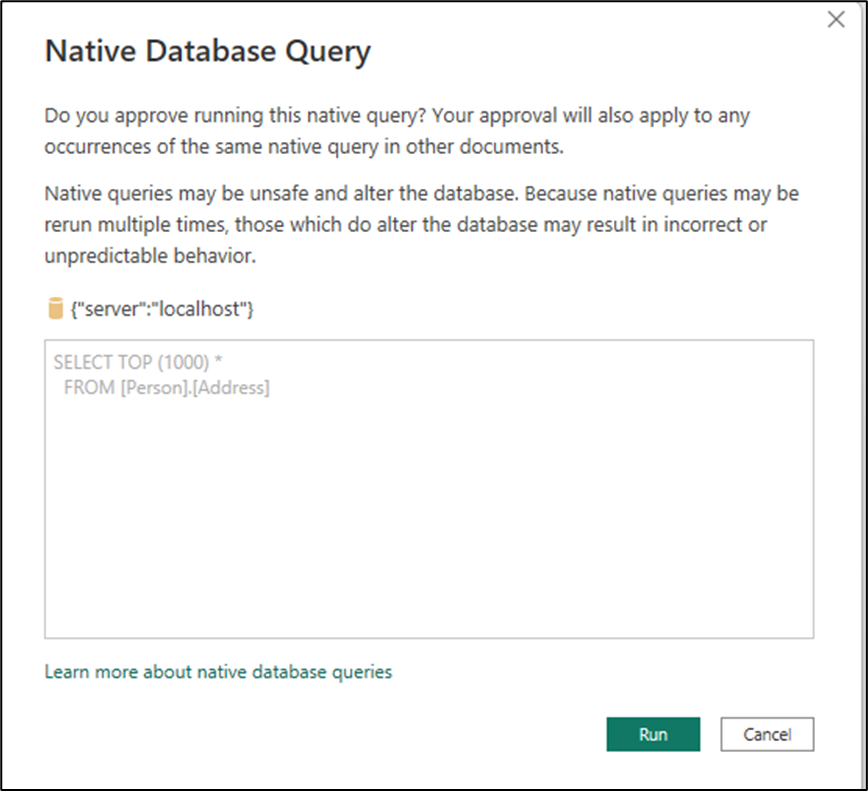
권한 수정을 선택합니다. 새로운 네이티브 데이터베이스 쿼리 대화 상자가 표시되어 네이티브 쿼리 실행의 가능성에 대해 경고합니다. 이 경우 이 SQL 문이 안전하다는 것을 알고 있으므로 실행을 선택하여 명령을 실행합니다.
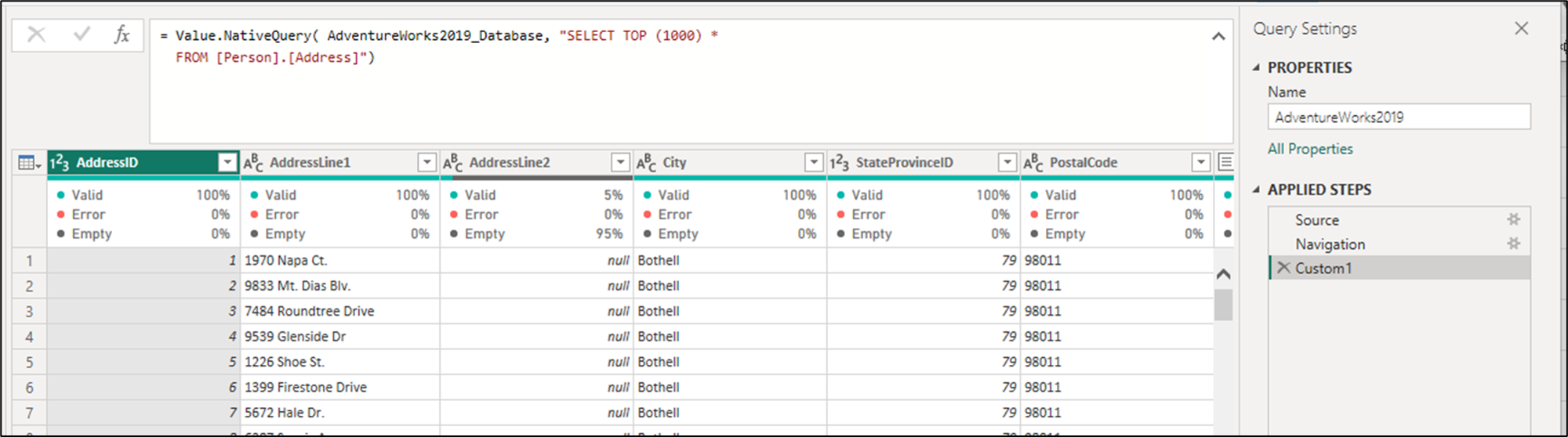
쿼리를 실행하면 파워 쿼리 편집기에서 쿼리 미리 보기가 표시됩니다. 이 미리 보기는 커넥터가 네이티브 쿼리를 실행할 수 있는지 확인합니다.
커넥터에서 네이티브 쿼리 논리 구현
이전 섹션에서 수집한 정보를 사용하여 이제 목표는 이러한 정보를 커넥터의 코드로 변환하는 것입니다.
이 번역을 수행하는 방법은 커넥터의 Publish 레코드에 새 NativeQueryProperties 레코드 필드를 추가하는 것입니다. 이 경우에 해당하는 레코드는 SqlODBC.Publish 입니다.
NativeQueryProperties 레코드는 커넥터가 Value.NativeQuery 함수와 상호 작용하는 방법을 정의하는 데 중요한 역할을 합니다.
새 레코드 필드는 다음 두 필드로 구성됩니다.
-
NavigationSteps: 이 필드는 커넥터에서 탐색을 수행하거나 처리하는 방법을 정의합니다. 함수를 사용하여
Value.NativeQuery쿼리하려는 특정 데이터로 이동하는 단계를 간략하게 설명하는 레코드 목록이 포함되어 있습니다. 각 레코드 내에서 이러한 탐색이 원하는 대상에 도달하기 위해 필요하거나 필요한 매개 변수를 정의합니다. -
DefaultOptions: 이 필드는 옵션 레코드에 특정 선택적 매개 변수를 포함하거나 추가하는 방법을 식별하는 데
Value.NativeQuery도움이 됩니다. 데이터 원본을 쿼리할 때 사용할 수 있는 기본 옵션 집합을 제공합니다.
NavigationSteps
탐색 단계는 두 그룹으로 분류할 수 있습니다. 첫 번째 값은 이 경우 서버 또는 데이터베이스의 이름과 같이 최종 사용자가 입력한 값을 포함합니다. 두 번째는 데이터 가져오기 환경 중에 사용자에게 표시되지 않는 필드의 이름과 같이 특정 커넥터 구현에서 파생된 값을 포함합니다. 이러한 필드에는 Name, Kind, Data 및 기타 여러 가지 필드가 커넥터 구현에 따라 포함될 수 있습니다.
이 경우 두 필드로 구성된 탐색 단계가 하나만 있었습니다.
-
이름: 이 필드는 최종 사용자가 전달한 데이터베이스의 이름입니다. 항상 이 필드를 최종 사용자가 데이터 가져오기 과정에서 입력한 내용 그대로 전달해야 합니다. 이번 경우에는
AdventureWorks2019이었습니다. -
종류: 이 필드는 최종 사용자에게 표시되지 않으며 커넥터 또는 드라이버 구현과 관련된 정보입니다. 이 경우 이 값은 액세스해야 하는 개체 유형을 식별합니다. 이 구현의 경우 이 필드는 문자열
Database로 구성된 고정 값이 됩니다.
이러한 정보는 다음 코드로 변환됩니다. 이 코드는 레코드에 새 필드로 추가되어야 합니다 SqlODBC.Publish .
NativeQueryProperties = [
NavigationSteps = {
[
Indices = {
[
FieldDisplayName = "database",
IndexName = "Name"
],
[
ConstantValue = "Database",
IndexName = "Kind"
]
},
FieldAccess = "Data"
]
}
]
중요합니다
필드 이름은 대/소문자를 구분하며 위의 샘플과 같이 사용해야 합니다. 필드 ConstantValue, IndexName, FieldDisplayName에 전달되는 모든 정보는 커넥터의 M 코드에서 파생되어야 합니다.
사용자가 입력한 값에서 전달되는 값의 경우 쌍 FieldDisplayName 을 IndexName사용할 수 있습니다. 고정되거나 미리 정의되어 있고 최종 사용자가 전달할 수 없는 값의 경우 쌍 ConstantValue 을 사용할 수 있습니다 IndexName. 이러한 의미에서 NavigationSteps 레코드는 다음 두 개의 필드로 구성됩니다.
-
인덱스: 함수의 대상이
Value.NativeQuery포함된 레코드로 이동하는 데 사용할 필드와 값을 정의합니다. - FieldAccess: 일반적으로 테이블인 대상을 보유하는 필드를 정의합니다.
기본 옵션
이 DefaultOptions 필드를 사용하면 커넥터에 대한 네이티브 쿼리 기능을 사용할 때 선택적 매개변수를 Value.NativeQuery 함수에 전달할 수 있습니다.
네이티브 쿼리 후 쿼리 폴딩을 유지하고 커넥터에 쿼리 폴딩 기능이 있다고 가정하려면 다음 샘플 코드를 EnableFolding = true사용할 수 있습니다.
NativeQueryProperties = [
NavigationSteps = {
[
Indices = {
[
FieldDisplayName = "database",
IndexName = "Name"
],
[
ConstantValue = "Database",
IndexName = "Kind"
]
},
FieldAccess = "Data"
]
},
DefaultOptions = [
EnableFolding = true
]
]
이러한 변경 내용이 있으면 커넥터를 빌드하고 테스트 및 유효성 검사를 위해 Power BI Desktop에 로드합니다.
커넥터 테스트 및 유효성 검사
새 사용자 지정 커넥터가 있는 Power BI Desktop에서 데이터 가져오기 환경에서 커넥터를 시작합니다. 커넥터를 실행할 때, 대화 상자에 이름이 네이티브 쿼리인 긴 텍스트 필드가 있으며, 괄호 안에는 이 기능이 작동하는 데 필요한 필드가 있다는 것을 알 수 있습니다. 커넥터를 테스트할 때 이전에 입력한 서버, 데이터베이스 및 SQL 문에 대해 동일한 값을 입력합니다.
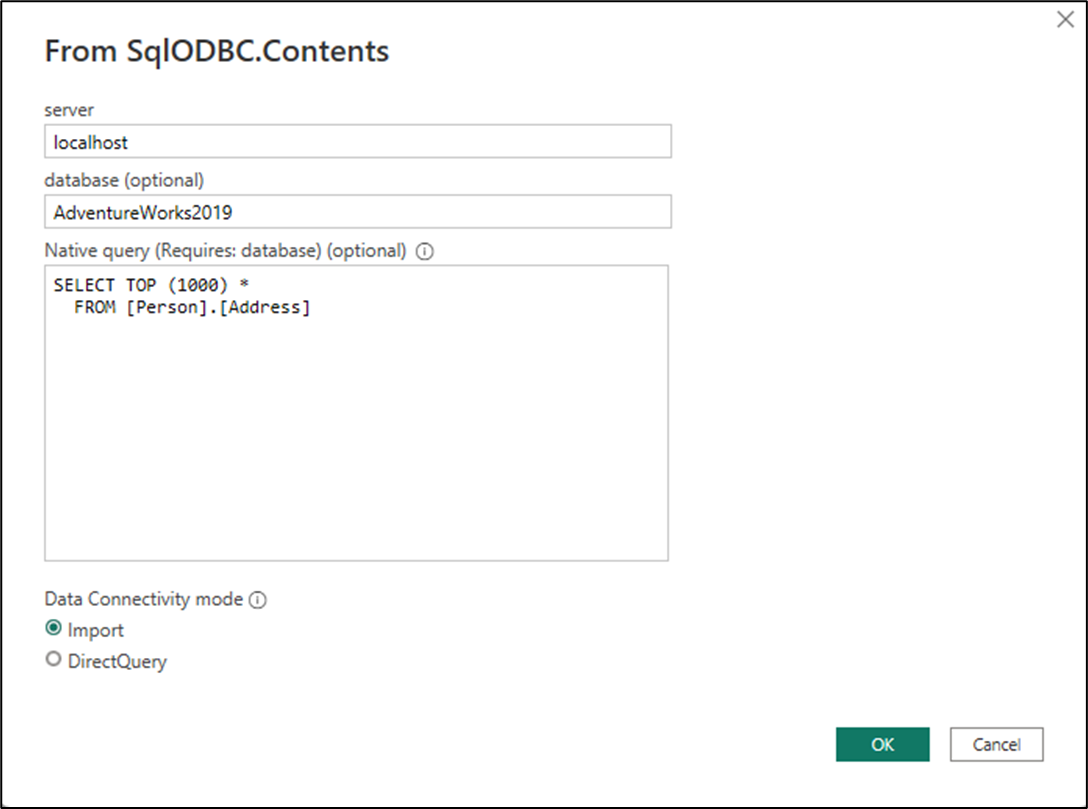
확인을 선택하면 실행된 네이티브 쿼리의 테이블 미리 보기가 새 대화 상자에 표시됩니다.
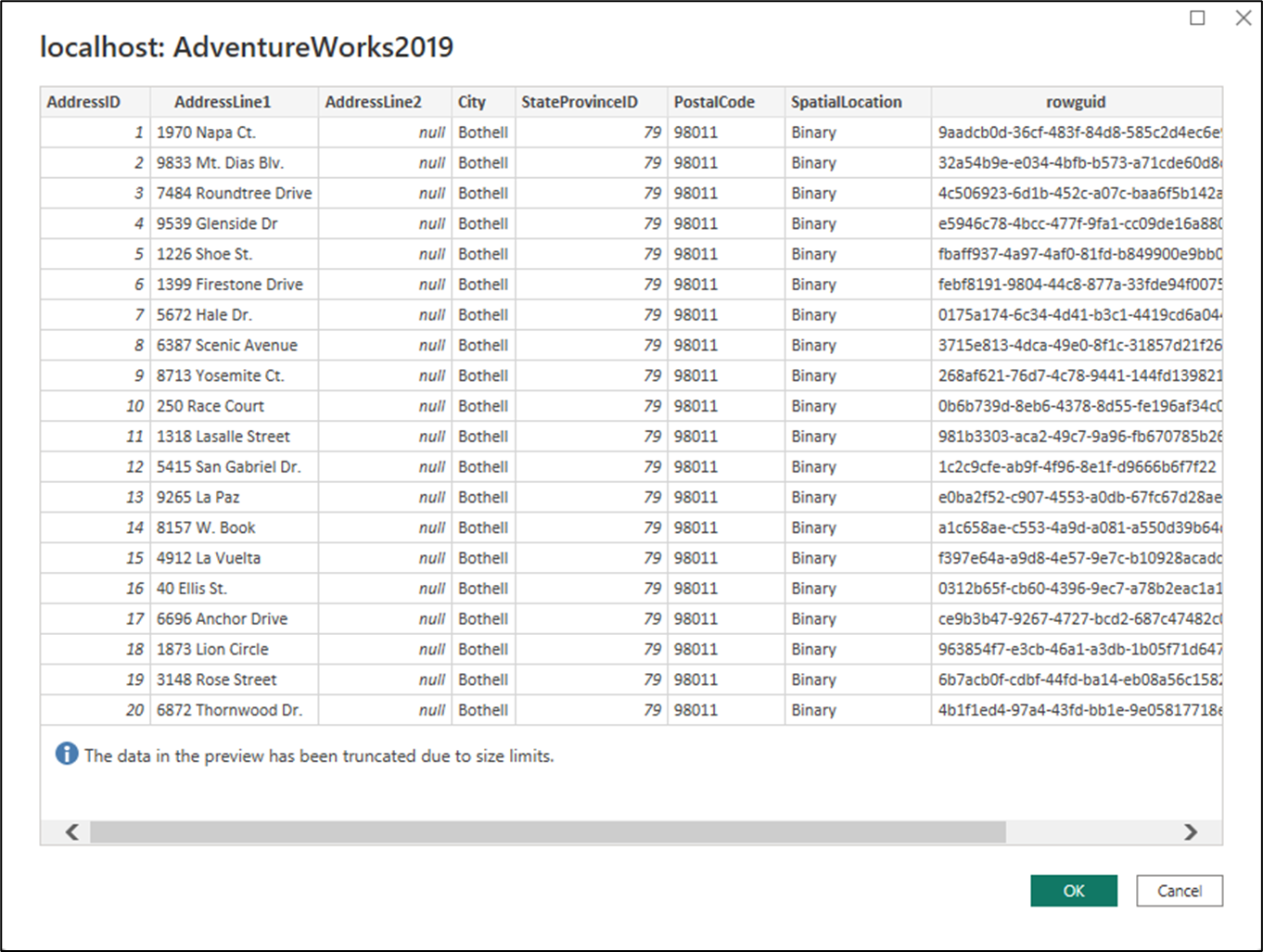
확인을 선택합니다. 이제 필요에 따라 커넥터를 추가로 테스트할 수 있는 새 쿼리가 파워 쿼리 편집기 내에 로드됩니다.
비고
커넥터에 쿼리 폴딩 기능이 있고 EnableFolding=true이 Value.NativeQuery의 선택적 레코드로 명시적으로 정의되어 있다면, 파워 쿼리 편집기에서 커넥터를 추가로 테스트하여 추가 변환 작업이 원본으로 다시 반환되는지 여부를 확인할 수 있습니다.