SQL Server 빅 데이터 클러스터의 앱 배포 소개
적용 대상: ![]() SQL Server 2019(15.x)
SQL Server 2019(15.x)
중요
Microsoft SQL Server 2019 빅 데이터 클러스터 추가 기능이 사용 중지됩니다. SQL Server 2019 빅 데이터 클러스터에 대한 지원은 2025년 2월 28일에 종료됩니다. Software Assurance를 사용하는 SQL Server 2019의 모든 기존 사용자는 플랫폼에서 완전히 지원되며, 소프트웨어는 지원 종료 시점까지 SQL Server 누적 업데이트를 통해 계속 유지 관리됩니다. 자세한 내용은 공지 블로그 게시물 및 Microsoft SQL Server 플랫폼의 빅 데이터 옵션을 참조하세요.
애플리케이션 배포는 애플리케이션을 만들고 관리 및 실행하기 위한 인터페이스를 제공하여 SQL Server 빅 데이터 클러스터에 애플리케이션을 배포할 수 있도록 합니다. 빅 데이터 클러스터에 배포된 애플리케이션은 클러스터의 컴퓨팅 기능을 활용하며, 클러스터에서 사용할 수 있는 데이터에 액세스할 수 있습니다. 이렇게 하면 데이터가 있는 애플리케이션을 관리하면서 애플리케이션의 확장성 및 성능이 향상됩니다. SQL Server 빅 데이터 클러스터에서 지원되는 애플리케이션 런타임은 R, Python, dtexec, MLeap입니다.
다음 섹션에서는 애플리케이션 배포의 아키텍처 및 기능을 설명합니다.
애플리케이션 배포 아키텍처
애플리케이션 배포는 컨트롤러 및 앱 런타임 처리기로 구성됩니다. 애플리케이션을 만들 때 사양 파일(spec.yaml)이 제공됩니다. 이 spec.yaml 파일에는 컨트롤러가 애플리케이션을 성공적으로 배포하기 위해 알아야 할 모든 것이 포함되어 있습니다. 다음은 spec.yaml의 내용 샘플입니다.
#spec.yaml
name: add-app #name of your python script
version: v1 #version of the app
runtime: Python #the language this app uses (R or Python)
src: ./add.py #full path to the location of the app
entrypoint: add #the function that will be called upon execution
replicas: 1 #number of replicas needed
poolsize: 1 #the pool size that you need your app to scale
inputs: #input parameters that the app expects and the type
x: int
y: int
output: #output parameter the app expects and the type
result: int
컨트롤러는 runtime 파일에 지정된 spec.yaml을 검사하고 해당 런타임 처리기를 호출합니다. 런타임 처리기가 애플리케이션을 만듭니다. 먼저, 각각 배포할 애플리케이션을 포함하는 Pod가 하나 이상 포함된 Kubernetes ReplicaSet가 생성됩니다. Pod 수는 애플리케이션의 replicas 파일에 설정된 spec.yaml 매개 변수에 의해 정의됩니다. 각 Pod에는 하나 이상의 풀이 있을 수 있습니다. 풀 수는 poolsize 파일의 spec.yaml 매개 변수 집합에 의해 정의됩니다.
이러한 설정은 배포에서 병렬로 처리할 수 있는 요청의 양을 결정합니다. 지정된 한 시점의 최대 요청 수는 replicas에 poolsize를 곱한 값과 같습니다. 복제본(replica)당 5개의 복제본(replica) 및 2개의 풀이 있는 경우 배포는 10개의 요청을 병렬로 처리할 수 있습니다. replicas 및 poolsize의 그래픽 표현은 아래 이미지를 참조하세요.
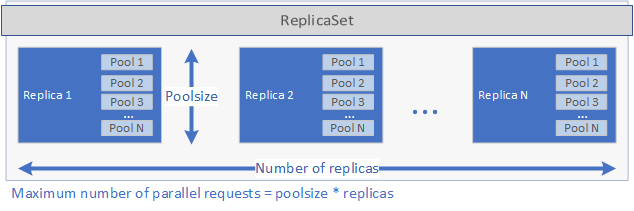
ReplicaSet이 만들어지고 Pod가 시작된 후 schedule이 spec.yaml 파일에 설정된 경우에는 cron 작업이 만들어집니다. 마지막으로 애플리케이션을 관리하고 실행하는 데 사용할 수 있는 Kubernetes 서비스가 만들어집니다(아래 참조).
애플리케이션이 실행되면 애플리케이션에 대한 Kubernetes 서비스가 요청을 복제본(replica) 프록시하고 결과를 반환합니다.
OpenShift에서의 애플리케이션 배포에 대한 보안 고려 사항
SQL Server 2019 CU5는 Red Hat OpenShift의 BDC 배포뿐만 아니라 BDC의 업데이트된 보안 모델도 지원하므로, 권한 있는 컨테이너가 더 이상 필요하지 않습니다. 권한 없는 컨테이너 외에도 컨테이너는 SQL Server 2019 CU5를 사용하는 모든 신규 배포에 대해 기본적으로 루트가 아닌 사용자로 실행됩니다.
CU5 릴리스 시 앱 배포 인터페이스를 사용하여 배포된 애플리케이션의 설정 단계는 계속해서 루트 사용자로 실행됩니다. 이 동작은 설치 도중에 애플리케이션에서 사용할 추가 패키지가 설치되기 때문에 필요합니다. 애플리케이션의 일부로 배포된 다른 사용자 코드는 권한이 낮은 사용자로 실행됩니다.
또한 CAP_AUDIT_WRITE 기능은 cron 작업을 사용하여 SSIS(SQL Server Integration Services) 애플리케이션 예약을 허용하는 데 필요한 선택적 기능입니다. 애플리케이션의 yaml 사양 파일이 일정을 지정하면 추가 기능이 필요한 cron 작업을 통해 애플리케이션이 트리거됩니다. 또는 azdata app run을 사용하여 웹 서비스 호출을 통해 요청 시 애플리케이션을 트리거할 수 있으며, 여기에는 CAP_AUDIT_WRITE 기능이 필요하지 않습니다. SQL Server 2019 CU8 릴리스부터는 cronjob에 CAP_AUDIT_WRITE 기능이 더 이상 필요하지 않습니다.
참고 항목
OpenShift 배포 문서의 사용자 지정 SCC는 BDC의 기본 배포에 필요하지 않기 때문에 이 기능을 포함하지 않습니다. 이 기능을 사용하려면 먼저 사용자 지정 SCC yaml 파일을 업데이트하여 CAP_AUDIT_WRITE을 포함해야 합니다.
...
allowedCapabilities:
- SETUID
- SETGID
- CHOWN
- SYS_PTRACE
- AUDIT_WRITE
...
빅 데이터 클러스터 내에서 앱 배포를 사용하는 방법
애플리케이션 배포를 위한 두 가지 기본 인터페이스는 다음과 같습니다.
RESTful 웹 서비스를 사용하여 애플리케이션을 실행할 수도 있습니다. 자세한 내용은 빅 데이터 클러스터에서 애플리케이션 사용을 참조하세요.
앱 배포 시나리오
애플리케이션 배포는 애플리케이션을 만들고 관리 및 실행하기 위한 인터페이스를 제공하여 SQL Server BDC에 애플리케이션을 배포할 수 있도록 합니다.
다음은 앱 배포에 대한 대상 시나리오입니다.
- 빅 데이터 클러스터 내에 Python 또는 R 웹 서비스를 배포하여 기계 학습 추론, API 서비스 등과 같은 다양한 사용 사례를 처리합니다.
- MLeap 엔진을 사용하여 기계 학습 추론 엔드포인트를 만듭니다.
- 데이터 변환 및 이동을 위해 dtexec 유틸리티를 사용하여 DTSX 파일에서 패키지를 예약하고 실행합니다.
앱 배포 Python 런타임 사용
앱 배포에서 BDC Python 런타임은 빅 데이터 클러스터 내의 Python 애플리케이션이 기계 학습 추론, API 서비스 등 다양한 사용 사례를 처리하도록 허용합니다.
앱 배포 Python 런타임은 SQL Server 빅 데이터 클러스터 CU10 이상에서 Python 3.8을 사용합니다.
앱 배포에서 spec.yaml은 컨트롤러가 애플리케이션을 배포하기 위해 알아야 하는 정보를 제공하는 위치입니다. 다음은 지정할 수 있는 필드입니다.
name: 애플리케이션 이름version: 애플리케이션 버전(예:v1)runtime: 앱 배포 런타임,Python로 지정 필요src: Python 애플리케이션의 경로entry point: 이 Python 애플리케이션에 대해 실행할 src 스크립트의 진입점 함수입니다.
위와는 별도로 Python 애플리케이션의 입력과 출력을 지정해야 합니다. 그러면 다음과 유사한 spec.yaml 파일이 생성됩니다.
#spec.yaml
name: add-app
version: v1
runtime: Python
src: ./add.py
entrypoint: add
replicas: 1
poolsize: 1
inputs:
x: int
y: int
output:
result: int
빅 데이터 클러스터에 실행되는 Python 앱을 배포하는 데 필요한 기본 폴더 및 파일 구조를 만들 수 있습니다.
azdata app init --template python --name hello-py --version v1
다음 단계를 위해 SQL Server 빅 데이터 클러스터에 앱을 배포하는 방법을 참조하세요.
앱 배포 Python 런타임의 제한 사항
앱 배포 Python 런타임은 예약 시나리오를 지원하지 않습니다. Python 앱이 배포되고 BDC에서 실행되면 들어오는 요청을 수신 대기하도록 RESTful 엔드포인트가 구성됩니다.
앱 배포 R 런타임 사용
앱 배포에서 BDC Python 런타임은 빅 데이터 클러스터 내의 R 애플리케이션이 기계 학습 추론, API 서비스 등 다양한 사용 사례를 처리하도록 허용합니다.
앱 배포 R 런타임은 SQL Server 빅 데이터 클러스터 CU10 이상에서 MRO(Microsoft R Open) 버전 3.5.2를 사용합니다.
사용 방법
앱 배포에서 spec.yaml은 컨트롤러가 애플리케이션을 배포하기 위해 알아야 하는 정보를 제공하는 위치입니다. 다음은 지정할 수 있는 필드입니다.
name: 애플리케이션 이름version: 애플리케이션 버전(예:v1)runtime: 앱 배포 런타임,R로 지정 필요src: R 애플리케이션의 경로entry point: 이 R 애플리케이션을 실행하는 진입점
위와는 별도로 R 애플리케이션의 입력과 출력을 지정해야 합니다. 그러면 다음과 유사한 spec.yaml 파일이 생성됩니다.
#spec.yaml
name: roll-dice
version: v1
runtime: R
src: ./roll-dice.R
entrypoint: rollEm
replicas: 1
poolsize: 1
inputs:
x: integer
output:
result: data.fram
다음 명령을 사용하여 새 R 애플리케이션을 배포하는 데 필요한 기본 폴더 및 파일 구조를 만들 수 있습니다.
azdata app init --template r --name hello-r --version v1
다음 단계를 위해 SQL Server 빅 데이터 클러스터에 앱을 배포하는 방법을 참조하세요.
R 런타임의 제한 사항
이러한 제한 사항은 2023년 7월 1일에 사용 중지된 Microsoft R 애플리케이션 네트워크와 일치합니다. 자세한 내용 및 해결 방법은 Microsoft R Application Network 사용 중지를 참조하세요.
앱 배포 dtexec 런타임 사용
앱 배포에서 빅 데이터 클러스터 런타임이 Linux의 SSIS(mssql-server-is)의 dtexec 유틸리티와 통합되었습니다. 앱 배포는 dtexec 유틸리티를 사용하여 *.dtsx 파일에서 패키지를 로드합니다. cron 스타일 일정 또는 웹 서비스 요청을 통한 주문형으로 SSIS 패키지 실행을 지원합니다.
이 기능은 SQL Server 2019 Integration Service on Linux의 /opt/ssis/bin/dtexec /FILE를 사용합니다. SQL Server 2019 Integration Service on Linux(mssql-server-is 15.0.2)에 대한 dtsx 형식을 지원합니다. dtexec 유틸리티에 대한 자세한 내용은 dtexec 유틸리티를 참조하세요.
앱 배포에서 spec.yaml은 컨트롤러가 애플리케이션을 배포하기 위해 알아야 하는 정보를 제공하는 위치입니다. 다음은 지정할 수 있는 필드입니다.
name: 애플리케이션nameversion: 애플리케이션 버전(예:v1)runtime: 앱 배포 런타임, dtexec 유틸리티를 실행하려면SSIS로 지정해야 함entrypoint: 진입점 지정, 일반적으로 .dtsx 파일입니다.options: 연결 문자열을 사용하여 데이터베이스에 연결하는 등의/opt/ssis/bin/dtexec /FILE에 대한 추가 옵션을 지정합니다. 다음 패턴을 따릅니다./REP V /CONN "sqldatabasename"\;"\"Data Source=xx;User ID=xx;Password=xx\""구문에 대한 자세한 내용은 dtexec 유틸리티를 참조하세요.
schedule: 작업을 실행해야 하는 빈도를 지정합니다. 예를 들어, cron 식을 사용하는 경우 이 값을 “*/1 * * * *”로 지정하면 작업이 1분 간격으로 실행됩니다.
다음 명령을 사용하여 새 SSIS 애플리케이션을 배포하는 데 필요한 기본 폴더 및 파일 구조를 만들 수 있습니다.
azdata app init --name hello-is –version v1 --template ssis
그러면 다음과 유사한 spec.yaml 파일이 생성됩니다.
#spec.yaml
entrypoint: ./hello.dtsx
name: hello-is
options: /REP V
poolsize: 2
replicas: 2
runtime: SSIS
schedule: '*/2 * * * *'
version: v1
이 예제에서는 샘플 hello.dtsx 패키지도 만듭니다.
모든 앱 파일이 spec.yaml과 동일한 디렉터리에 있는지 확인합니다. spec.yaml이 dtsx 파일을 포함하여 앱 소스 코드 디렉터리의 루트 수준에 있어야 합니다.
다음 단계를 위해 SQL Server 빅 데이터 클러스터에 앱을 배포하는 방법을 참조하세요.
dtexec 유틸리티 런타임의 제한 사항
SSIS(SQL Server Integration Services) on Linux에 대한 모든 제한 사항과 알려진 문제는 SQL Server 빅 데이터 클러스터에서 적용됩니다. SSIS on Linux의 제한 사항 및 알려진 문제에서 자세한 내용을 확인할 수 있습니다.
앱 배포 MLeap 런타임 사용
앱 배포 MLeap 런타임은 MLeap Service v0.13.0을 지원합니다.
앱 배포에서 spec.yaml은 컨트롤러가 애플리케이션을 배포하기 위해 알아야 하는 정보를 제공하는 위치입니다. 다음은 지정할 수 있는 필드입니다.
name: 애플리케이션 이름version: 애플리케이션 버전(예:v1)runtime: 앱 배포 런타임,Mleap로 지정 필요
위와는 별도로 MLeap 애플리케이션의 bundleFileName을 지정해야 합니다. 그러면 다음과 유사한 spec.yaml 파일이 생성됩니다.
#spec.yaml
name: mleap-census
version: v1
runtime: Mleap
bundleFileName: census-bundle.zip
replicas: 1
다음 명령을 사용하여 새 MLeap 애플리케이션을 배포하는 데 필요한 기본 폴더 및 파일 구조를 만들 수 있습니다.
azdata app init --template mleap --name hello-mleap --version v1
다음 단계를 위해 SQL Server 빅 데이터 클러스터에 앱을 배포하는 방법을 참조하세요.
MLeap 런타임의 제한 사항
제한 사항은 MLeap 오픈 소스 프로젝트 GitHub의 Combust의 비전과 일치합니다.
다음 단계
SQL Server 빅 데이터 클러스터에서 애플리케이션을 만들고 실행하는 방법에 대한 자세한 내용은 다음을 참조하세요.
SQL Server 빅 데이터 클러스터 대한 자세한 내용은 다음 개요를 참조하세요.