적용 대상:![]() SQL Server 2019(15.x)
SQL Server 2019(15.x)
Important
Microsoft SQL Server 2019 빅 데이터 클러스터는 사용 중지되었습니다. SQL Server 2019 빅 데이터 클러스터에 대한 지원은 2025년 2월 28일부터 종료되었습니다. 자세한 내용은 Microsoft SQL Server 플랫폼의 공지 블로그 게시물 및 빅 데이터 옵션을 참조하세요.
이 자습서에서는 SQL Server 2019 빅 데이터 클러스터의 Azure Data Studio에서 Notebook을 로드하고 실행하는 방법을 보여 줍니다. 이를 통해 데이터 과학자와 데이터 엔지니어는 클러스터에 대해 Python, R 또는 Scala 코드를 실행할 수 있습니다.
Tip
원하는 경우 이 자습서의 명령에 대한 스크립트를 다운로드하고 실행할 수 있습니다. 자세한 내용은 GitHub의 Spark 샘플을 참조하세요.
Prerequisites
-
빅 데이터 도구
- kubectl
- Azure Data Studio
- SQL Server 2019 확장
- 빅 데이터 클러스터에 샘플 데이터 로드
샘플 Notebook 파일 다운로드
다음 지침을 사용하여 샘플 Notebook 파일 spark-sql.ipynb 을 Azure Data Studio에 로드합니다.
Bash 명령 프롬프트(Linux) 또는 Windows PowerShell을 엽니다.
샘플 노트북 파일을 다운로드할 디렉터리로 이동하세요.
다음 curl 명령을 실행하여 GitHub에서 Notebook 파일을 다운로드합니다.
curl https://raw.githubusercontent.com/Microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/data-loading/transform-csv-files.ipynb -o transform-csv-files.ipynb
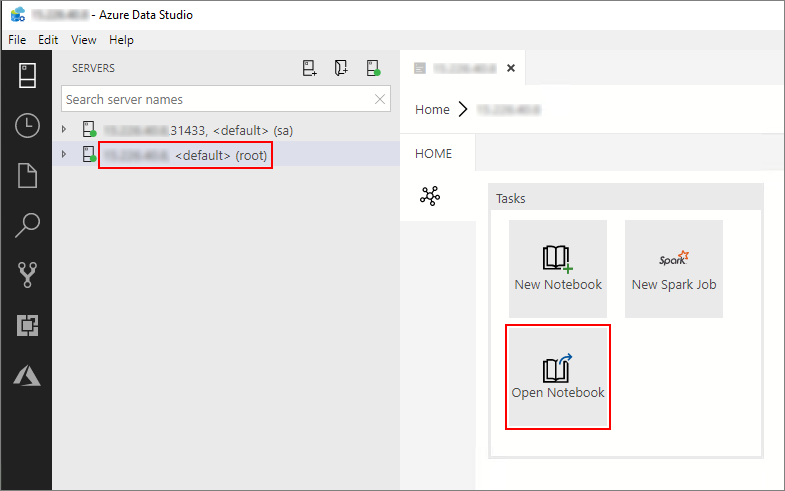
전자 필기장 열기
다음 단계에서는 Azure Data Studio에서 Notebook 파일을 여는 방법을 보여줍니다.
Azure Data Studio에서 빅 데이터 클러스터의 마스터 인스턴스에 연결합니다. 자세한 내용은 빅 데이터 클러스터에 연결을 참조하세요.
서버 창에서 HDFS/Spark 게이트웨이 연결을 두 번 클릭합니다. 그런 다음 전자 필기장 열기를 선택합니다.
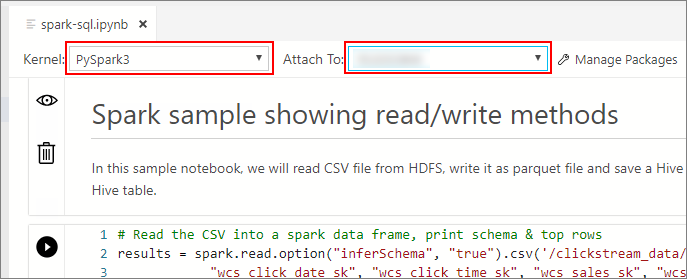
커널 및 대상 컨텍스트(연결 대상)가 채워질 때까지 기다립니다. 커널을 PySpark3로 세트하고 연결 대상을 빅 데이터 클러스터 엔드포인트의 IP 주소로 세트하세요.
Important
Azure Data Studio에서 모든 Spark Notebook 형식(Scala Spark, PySpark 및 SparkR)은 일반적으로 첫 번째 셀 실행 시 몇 가지 중요한 Spark 세션 관련 변수를 정의합니다. 이러한 변수는 다음과 sparkscsqlContext같습니다. 일괄 처리 제출을 위해 Notebook에서 논리를 복사하는 경우(예를 들어 실행할 Python 파일로 azdata bdc spark batch create ) 변수를 적절하게 정의해야 합니다.
노트북 셀을 실행하세요
셀 왼쪽의 재생 단추를 눌러 각 Notebook 셀을 실행할 수 있습니다. 셀 실행이 완료되면 결과가 Notebook에 나타납니다.

샘플 Notebook의 각 셀을 연속으로 실행합니다. SQL Server 빅 데이터 클러스터에서 Notebook을 사용하는 방법에 대한 자세한 내용은 다음 리소스를 참조하세요.
Next steps
Notebook에 대한 자세한 정보: