Important
Microsoft SQL Server 2019 빅 데이터 클러스터는 사용 중지되었습니다. SQL Server 2019 빅 데이터 클러스터에 대한 지원은 2025년 2월 28일부터 종료되었습니다. 자세한 내용은 Microsoft SQL Server 플랫폼의 공지 블로그 게시물 및 빅 데이터 옵션을 참조하세요.
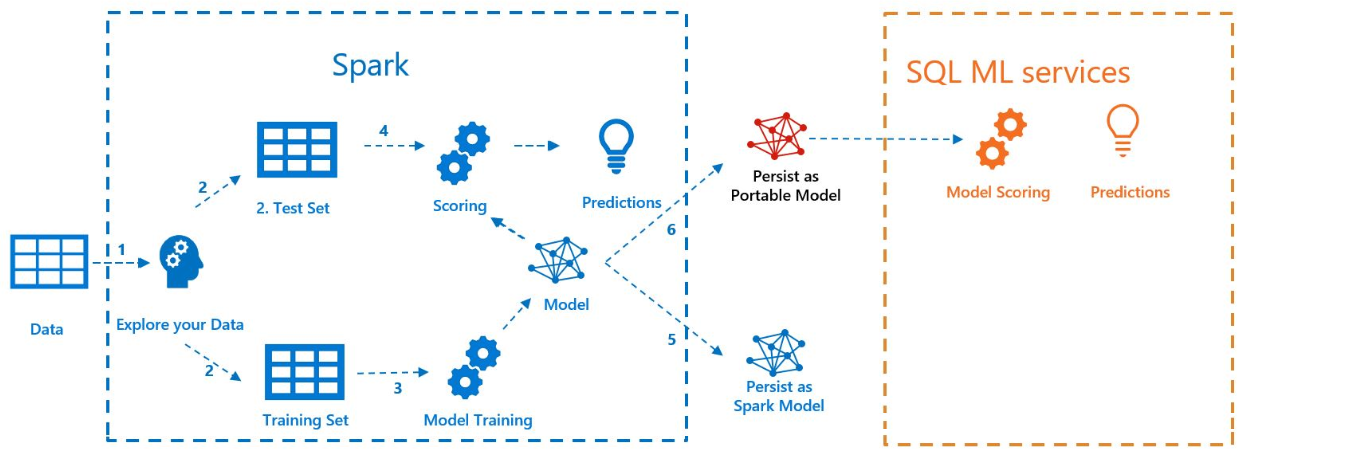
다음 샘플에서는 Spark ML을 사용하여 모델을 빌드하고, 모델을 MLeap으로 내보내고, Java 언어 확장을 사용하여 SQL Server에서 모델의 점수를 매기는 방법을 보여줍니다. 이 작업은 SQL Server 빅 데이터 클러스터의 컨텍스트에서 수행됩니다.
다음 다이어그램은 이 샘플에서 수행되는 작업을 보여줍니다.
Prerequisites
이 샘플의 모든 파일은 https://github.com/microsoft/sql-server-samples/tree/master/samples/features/sql-big-data-cluster/spark/sparkml에 있습니다.
또한 샘플을 실행하기 위한 사전 요구 사항은 다음과 같습니다.
-
- kubectl
- curl
- Azure Data Studio
Spark ML을 사용하여 모델 학습
이 샘플에서는 Spark ML 파이프라인 모델을 빌드하기 위해 인구 조사 데이터(AdultCensusIncome.csv)가 사용됩니다.
mleap_sql_test/setup.sh 파일을 사용하여 인터넷에서 데이터 집합을 다운로드하고 SQL Server 빅 데이터 클러스터의 HDFS에 배치합니다. 이렇게 하면 Spark에서 액세스할 수 있습니다.
그런 다음 샘플 Notebook train_score_export_ml_models_with_spark.ipynb를 다운로드합니다. PowerShell 또는 bash 명령줄에서 다음 명령을 실행하여 Notebook을 다운로드합니다.
curl -o mssql_spark_connector.ipynb "https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/sparkml/train_score_export_ml_models_with_spark.ipynb"이 노트북에는 샘플의 이 섹션에 필요한 명령이 포함된 셀이 있습니다.
Azure Data Studio에서 Notebook을 열고 각 코드 블록을 실행합니다. Notebook 사용 방법에 대한 자세한 내용은 SQL Server에서 Notebook을 사용하는 방법을 참조하세요.
데이터가 먼저 Spark로 읽혀진 후 학습 및 테스트 데이터 세트로 분할됩니다. 그런 다음, 코드는 학습 데이터를 사용하여 파이프라인 모델을 학습합니다. 마지막으로 모델을 MLeap 번들로 내보냅니다.
Tip
mleap_sql_test/mleap_pyspark.py 파일의 Notebook 외부에서 이러한 단계와 연결된 Python 코드를 검토하거나 실행할 수도 있습니다.
SQL Server를 사용하여 모델 점수 매기기
이제 Spark ML 파이프라인 모델이 일반 직렬화 MLeap 번들 형식이므로, Spark가 없어도 Java로 모델을 채점할 수 있습니다.
이 샘플에서는 SQL Server에서 Java 언어 확장을 사용합니다. SQL Server에서 모델에 점수를 매기려면 먼저 모델을 Java에 로드하고 점수를 매길 수 있는 Java 애플리케이션을 빌드해야 합니다. 이 Java 애플리케이션에 대한 샘플 코드는 mssql-mleap-app 폴더에서 확인할 수 있습니다.
샘플을 빌드한 후 Transact-SQL을 사용하여 Java 애플리케이션을 호출하고 데이터베이스 테이블로 모델의 점수를 매깁니다. mleap_sql_test/mleap_sql_tests.py 소스 파일에서 볼 수 있습니다.
Next steps
빅 데이터 클러스터에 대한 자세한 내용은 Kubernetes에 SQL Server 빅 데이터 클러스터를 배포하는 방법을 참조하세요.