SQL Server에서 스핀 잠금 경합 진단 및 해결
이 문서에서는 높은 동시성 시스템의 SQL Server 애플리케이션에서 스핀 잠금 경합과 관련된 문제를 식별하고 해결하는 방법에 대한 자세한 정보를 제공합니다.
참고 항목
여기서 설명하는 권장 사항과 모범 사례는 실제 OLTP 시스템을 개발하고 배포하면서 겪은 실제 경험을 기반으로 합니다. 원래 Microsoft SQL Server SQLCAT(고객 자문 팀) 팀에서 게시했습니다.
배경
과거에는 상용 Windows Server 컴퓨터가 하나 또는 두 개의 마이크로프로세서/CPU 칩만 사용했으며 CPU는 단일 프로세서 또는 "코어"로만 설계되었습니다. 컴퓨터 처리 용량의 증가는 트랜지스터 밀도의 발전을 통해 가능해진 더 빠른 CPU를 사용하여 달성되었습니다. "Moore's Law"에 이어 1971년 최초의 범용 단일 칩 CPU가 개발된 이후 2년마다 통합 회로에 배치할 수 있는 트랜지스터 밀도 또는 트랜지스터 수가 지속적으로 두 배로 증가했습니다. 최근 몇 년간 여러 개의 CPU가 포함된 컴퓨터를 구축함으로써 더 빠른 CPU로 컴퓨터 처리 용량을 늘이는 기존 방식이 확대되었습니다. 이 문서 작성을 기준으로 Intel Nehalem CPU 아키텍처는 CPU당 최대 8개의 코어를 수용하며, 8개의 소켓 시스템에서 사용되는 경우 동시 다중 스레딩(SMT) 기술을 사용하여 128개의 논리 프로세서로 두 배가 될 수 있습니다. Intel CPU에서 SMT를 하이퍼 스레딩이라고 합니다. x86 호환 컴퓨터의 논리 프로세서 수가 증가함에 따라 논리 프로세서가 리소스를 놓고 경쟁함에 따라 동시성 관련 문제가 증가합니다. 이 가이드에서는 일부 워크로드가 있는 높은 동시성 시스템에서 SQL Server 애플리케이션을 실행할 때 관찰되는 특정 리소스 경합 문제를 식별하고 해결하는 방법을 설명합니다.
이 섹션에서는 스핀 잠금 경합 문제를 진단하고 해결하여 SQLCAT 팀에서 배운 교훈을 분석합니다. 스핀 잠금 경합은 대규모 시스템의 실제 고객 워크로드에서 관찰되는 동시성 문제의 한 가지 유형입니다.
스핀 잠금 경합의 증상 및 원인
이 섹션에서는 SQL Server에서 OLTP 애플리케이션의 성능에 해로운 스핀 잠금 경합 문제를 진단하는 방법을 설명합니다. 스핀 잠금 진단 및 문제 해결은 고급 주제로 간주되어야 하며, 디버깅 도구 및 Windows 내부 요소에 대한 지식이 필요합니다.
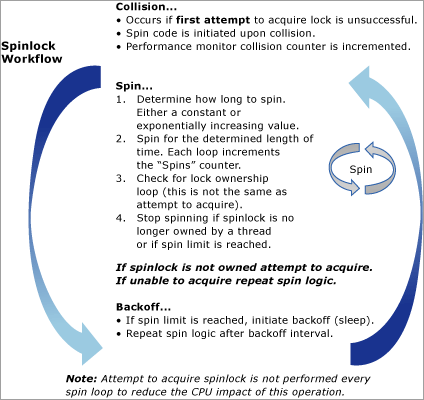
Spinlock은 데이터 구조에 대한 액세스를 보호하는 데 사용되는 간단한 동기화 기본 형식입니다. 스핀 잠금은 SQL Server에 고유하지 않습니다. 지정된 데이터 구조에 짧은 시간 동안만 액세스하면 되는 경우 운영 체제에서 스핀 잠금을 사용합니다. 스핀 잠금을 획득하려는 스레드가 액세스를 얻을 수 없는 경우 루프에서 주기적으로 검사 실행하여 리소스를 즉시 생성하는 대신 사용할 수 있는지 확인합니다. 일정 시간 후에는 스핀 잠금을 기다리는 스레드가 리소스를 획득하기 전에 생성됩니다. 출력을 사용하면 동일한 CPU에서 실행되는 다른 스레드를 실행할 수 있습니다. 이 동작을 백오프라고 하며 이 문서의 뒷부분에서 자세히 설명합니다.
SQL Server는 스핀 잠금을 사용하여 일부 내부 데이터 구조에 대한 액세스를 보호합니다. 스핀 잠금은 래치와 비슷한 방식으로 특정 데이터 구조에 대한 액세스를 직렬화하기 위해 엔진 내에서 사용됩니다. 래치와 스핀록의 기본 차이점은 스핀 잠금이 데이터 구조의 가용성을 위해 검사 일정 기간 동안 스핀(루프 실행)을 실행한다는 사실이며, 래치로 보호되는 구조에 대한 액세스를 획득하려는 스레드는 리소스를 사용할 수 없는 경우 즉시 생성됩니다. 출력하려면 다른 스레드를 실행할 수 있도록 CPU에서 스레드를 컨텍스트 전환해야 합니다. 이는 비교적 비용이 많이 드는 작업이며, 짧은 기간 동안 유지되는 리소스의 경우 리소스 가용성을 위해 주기적으로 검사 루프에서 스레드를 실행할 수 있도록 하는 것이 전반적으로 더 효율적입니다.
SQL Server 2022(16.x)에 도입된 데이터베이스 엔진 내부적으로 조정하면 스핀 잠금의 효율성이 높아집니다.
증상
사용량이 많은 높은 동시성 시스템에서는 스핀 잠금으로 보호되는 자주 액세스하는 구조체에서 활성 경합을 보는 것이 정상입니다. 이 사용량은 경합으로 인해 상당한 CPU 오버헤드가 발생하는 경우에만 문제가 되는 것으로 간주됩니다. 스핀 잠금 통계는 SQL Server 내의 sys.dm_os_spinlock_stats DMV(동적 관리 뷰)에 의해 노출됩니다. 예를 들어 이 쿼리는 다음 출력을 생성합니다.
참고 항목
이 DMV에서 반환된 정보를 해석하는 방법에 대한 자세한 내용은 이 문서의 뒷부분에서 설명합니다.
SELECT * FROM sys.dm_os_spinlock_stats
ORDER BY spins DESC;
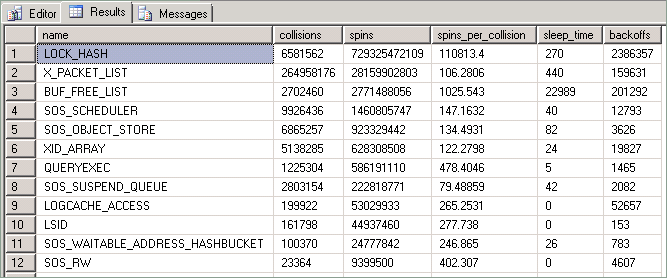
이 쿼리를 통해 노출되는 통계는 다음과 같습니다.
| 열 | 설명 |
|---|---|
| 충돌 | 이 값은 스핀 잠금으로 보호된 리소스에 대한 스레드 액세스가 차단될 때마다 증가합니다. |
| 회전 | 이 값은 스핀 잠금을 사용할 수 있게 될 때까지 기다리는 동안 스레드가 루프를 실행할 때마다 증가합니다. 이는 스레드가 리소스를 획득하는 동안 수행하는 작업량의 측정값입니다. |
| Spins_per_collision | 충돌당 스핀 비율입니다. |
| 중지 시간 | 백오프 이벤트와 관련된 경우 그러나 이 문서에 설명된 기술과는 관련이 없습니다. |
| 백오프 | 보류된 리소스에 액세스하려는 "회전" 스레드가 동일한 CPU의 다른 스레드를 실행할 수 있도록 허용해야 한다고 결정한 경우에 발생합니다. |
이 논의의 목적을 위해 특정 관심 통계는 시스템이 부하가 많은 특정 기간 내에 발생하는 충돌, 스핀 및 백오프 이벤트의 수입니다. 스레드가 스핀 잠금으로 보호된 리소스에 액세스하려고 하면 충돌이 발생합니다. 충돌이 발생하면 충돌 횟수가 증가하고, 스레드가 루프로 스핀을 시작하여 리소스를 사용할 수 있는지 주기적으로 확인합니다. 스레드가 회전(루프)할 때마다 스핀 수가 증가합니다.
충돌당 스핀은 스레드에 의해 스핀 잠금이 유지되는 동안 발생하는 스핀의 양을 측정하고 스레드가 스핀 잠금을 보유하는 동안 발생하는 스핀 수를 알려줍니다. 예를 들어 충돌당 작은 스핀과 높은 충돌 횟수는 스핀 잠금에서 발생하는 스핀의 양이 적고 많은 스레드가 경합한다는 것을 의미합니다. 스핀량이 많으면 스핀 잠금 코드에서 스핀하는 데 걸린 시간이 상대적으로 길었음을 의미합니다. 즉, 코드가 해시 버킷의 많은 항목을 처리하고 있습니다. 경합이 증가함에 따라(따라서 충돌 횟수가 증가) 스핀 수도 증가합니다.
백오프는 스핀과 비슷한 방식으로 생각할 수 있습니다. 의도적으로 과도한 CPU 낭비를 방지하기 위해 스핀 잠금은 보류된 리소스에 액세스할 수 있을 때까지 무기한 회전하지 않습니다. 스핀 잠금이 CPU 리소스를 과도하게 사용하지 않도록 하려면 백오프를 스핀 잠금하거나 회전 및 "절전 모드"를 중지합니다. 스핀 잠금은 대상 리소스의 소유권 획득 여부에 관계없이 백오프합니다. 이는 다른 스레드가 CPU에서 예약될 수 있도록 하기 위해 수행됩니다. 이렇게 하면 생산성이 향상될 수 있습니다. 엔진의 기본 동작은 백오프를 수행하기 전에 먼저 일정한 시간 간격으로 회전하는 것입니다. 스핀 잠금을 가져오려면 캐시 동시성 상태를 기본 가져와야 합니다. 이는 회전하는 CPU 비용에 비해 CPU를 많이 사용하는 작업입니다. 따라서 스핀 잠금을 획득하려는 시도는 드물게 수행되며 스레드가 회전할 때마다 수행되지 않습니다. SQL Server에서 특정 스핀 잠금 유형(예: LOCK_HASH)은 스핀 잠금을 획득하려는 시도 간에 기하급수적으로 증가하는 간격(최대 특정 제한)을 활용하여 개선되었으며, 이는 CPU 성능에 미치는 영향을 줄이는 경우가 많습니다.
다음 다이어그램은 스핀 잠금 알고리즘의 개념적 보기를 제공합니다.
일반적인 시나리오
스핀 잠금 경합은 데이터베이스 디자인 결정과 관련이 없는 여러 가지 이유로 발생할 수 있습니다. 스핀 잠금은 내부 데이터 구조에 대한 게이트 액세스를 차단하기 때문에 스키마 디자인 선택 및 데이터 액세스 패턴의 직접적인 영향을 받는 버퍼 래치 경합과 같은 방식으로 스핀 잠금 경합이 나타나지 않습니다.
주로 스핀 잠금 경합과 관련된 증상은 많은 수의 스핀과 동일한 스핀 잠금을 획득하려는 많은 스레드의 결과로 높은 CPU 사용량입니다. 일반적으로 이것은 = 24이고 가장 일반적으로 >= 32 CPU 코어 시스템의 시스템에서 >관찰되었습니다. 앞에서 설명한 것처럼 스핀 잠금에 대한 일정 수준의 경합은 상당한 부하가 있는 높은 동시성 OLTP 시스템에 대해 정상이며, 오랫동안 실행되어 온 시스템의 DMV에서 sys.dm_os_spinlock_stats 보고된 스핀(수십억/수조)이 많은 경우가 많습니다. 다시 말하지만, 지정된 스핀 잠금 유형에 대해 많은 수의 스핀을 관찰하는 것은 워크로드 성능에 부정적인 영향을 미친다는 것을 결정하기에 충분한 정보가 아닙니다.
다음 몇 가지 증상의 조합은 스핀 잠금 경합을 나타낼 수 있습니다.
특정 스핀 잠금 유형에 대해 많은 수의 스핀 및 백오프가 관찰됩니다.
시스템의 CPU 사용률이 높거나 CPU 사용량이 급증합니다. CPU가 많은 시나리오에서는 SOS_SCHEDULER_YIELD(DMV
sys.dm_os_wait_stats에서 보고됨)에서 높은 신호 대기가 표시됩니다.시스템의 동시성이 높습니다.
CPU 사용량 및 스핀이 처리량에 불균형적으로 증가합니다.
Important
위의 각 조건이 맞더라도 높은 CPU 사용량의 근본 원인은 다른 곳에 있습니다. 실제로 대부분의 경우 CPU 증가는 스핀 잠금 경합 이외의 이유로 인해 발생합니다. CPU 사용량 증가에 대한 일반적인 원인은 다음과 같습니다.
기본 데이터가 증가하여 시간에 따라 비용이 늘어나는 쿼리로 인해 메모리 상주 데이터의 논리적 읽기를 추가로 수행해야 합니다.
쿼리 계획이 변경되어 최적이 않은 실행이 발생합니다.
이러한 모든 조건이 충족되면 가능한 스핀 잠금 경합 문제에 대한 추가 조사를 수행합니다.
쉽게 진단할 수 있는 일반적인 현상 중 하나는 처리량 및 CPU 사용량의 상당한 차이입니다. 많은 OLTP 워크로드에는 (시스템의 처리량/사용자 수) 및 CPU 사용량 간에 관계가 있습니다. CPU 사용량 및 처리량의 상당한 차이와 함께 관찰된 높은 스핀은 CPU 오버헤드를 발생시키는 스핀 잠금 경합의 표시일 수 있습니다. 여기서 유의해야 할 중요한 점은 특정 쿼리가 시간이 지남에 따라 비용이 더 많이 들 때 시스템에서 이러한 유형의 차이를 확인하는 것이 일반적이라는 것입니다. 예를 들어 시간에 따라 논리적 읽기를 추가로 수행하는 데이터 세트에 대해 실행되는 쿼리도 비슷한 증상을 유발할 수 있습니다.
이러한 유형의 문제를 해결할 때 높은 CPU의 다른 일반적인 원인을 배제하는 것이 중요합니다.
예제
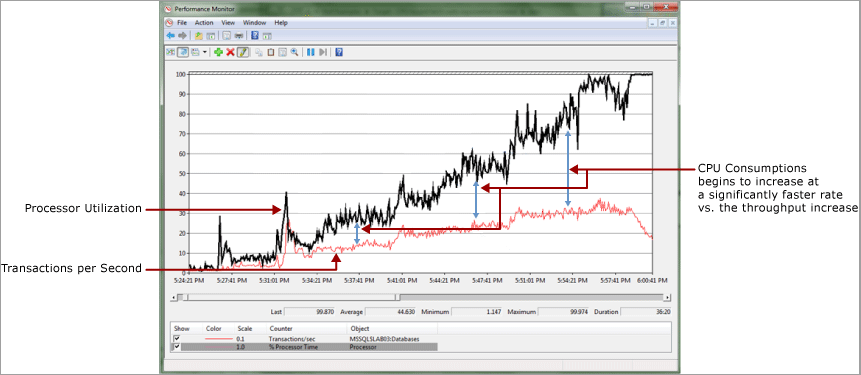
다음 예제에서는 초당 트랜잭션으로 측정된 CPU 사용량과 처리량 간에 거의 선형 관계가 있습니다. 워크로드가 증가함에 따라 오버헤드가 발생하기 때문에 여기서 약간의 차이를 보는 것이 정상입니다. 여기서 볼 수 있듯이 이 차이는 상당히 커집니다. CPU 사용량이 100%에 도달하면 처리량이 급격히 감소합니다.
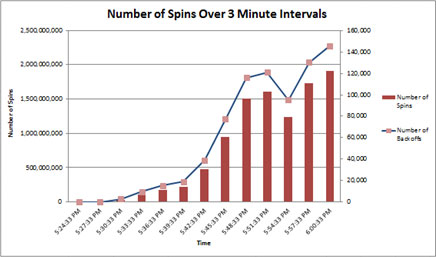
3분 간격으로 스핀 횟수를 측정하면 스핀 횟수 증가가 선형보다 더 가파른 것을 확인할 수 있으며, 스핀 잠금 경합이 문제가 될 수 있음을 나타냅니다.
앞에서 설명한 것처럼 스핀 잠금은 부하가 많은 높은 동시성 시스템에서 가장 일반적입니다.
이 문제가 발생하기 쉬운 몇 가지 시나리오는 다음과 같습니다.
개체 이름을 정규화하지 못하여 발생하는 이름 확인 문제입니다. 자세한 내용은 컴파일 잠금으로 인한 SQL Server 차단에 대한 설명을 참조 하세요. 이 특정 문제는 이 문서 내에서 자세히 설명합니다.
자주 동일한 잠금에 액세스하는 워크로드(예: 자주 읽는 행의 공유 잠금)에 대한 잠금 관리자의 잠금 해시 버킷에 대한 경합입니다. 이 유형의 경합은 LOCK_HASH 형식 스핀 잠금으로 표시됩니다. 한 가지 특정 경우에 이 문제가 테스트 환경에서 잘못 모델링된 액세스 패턴의 결과로 발생하는 것을 발견했습니다. 이 환경에서는 잘못 구성된 테스트 매개 변수로 인해 예상되는 스레드 수보다 많은 스레드가 정확히 동일한 행에 지속적으로 액세스했습니다.
MSDTC 트랜잭션 코디네이터 간에 대기 시간이 높은 경우 DTC 트랜잭션 비율이 높습니다. 이 특정 문제는 DTC 관련 대기 및 DTC의 확장성 조정을 해결하는 SQLCAT 블로그 항목에 자세히 설명되어 있습니다.
스핀 잠금 경합 진단
이 섹션에서는 SQL Server 스핀 잠금 경합을 진단하기 위한 정보를 제공합니다. 스핀 잠금 경합을 진단하는 데 사용되는 기본 도구는 다음과 같습니다.
| 도구 | 사용 |
|---|---|
| 성능 모니터 | 높은 CPU 조건 또는 처리량과 CPU 사용량 간의 차이를 찾습니다. |
sys.dm_os_spinlock 통계 DMV** |
일정 기간 동안 많은 수의 스핀 및 백오프 이벤트를 찾습니다. |
| SQL Server 확장 이벤트 | 스핀 수가 많은 스핀 잠금에 대한 호출 스택을 추적하는 데 사용됩니다. |
| 메모리 덤프 | 경우에 따라 SQL Server 프로세스 및 Windows 디버깅 도구의 메모리 덤프가 있습니다. 일반적으로 이 수준의 분석은 Microsoft SQL Server 지원 팀이 참여할 때 수행됩니다. |
SQL Server 스핀 잠금 경합을 진단하는 일반적인 기술 프로세스는 다음과 같습니다.
1단계: 스핀 잠금과 관련된 경합이 있는지 확인합니다.
2단계: _ os_spinlock_stats 통계를 캡처하여 경합이 가장 많은 스핀 잠금 유형을 찾습니다
sys.dm.3단계: sqlservr.exe(sqlservr.pdb)에 대한 디버그 기호를 가져오고 SQL Server 인스턴스에 대한 SQL Server 서비스 .exe 파일(sqlservr.exe)과 동일한 디렉터리에 기호를 배치합니다.\ 백오프 이벤트에 대한 호출 스택을 보려면 실행 중인 특정 버전의 SQL Server에 대한 기호가 있어야 합니다. SQL Server에 대한 기호는 Microsoft 기호 서버에서 사용할 수 있습니다. Microsoft 기호 서버에서 기호를 다운로드하는 방법에 대한 자세한 내용은 기호가 있는 디버깅을 참조 하세요.
4단계: SQL Server 확장 이벤트를 사용하여 관심 있는 스핀 잠금 유형에 대한 백오프 이벤트를 추적합니다.
확장 이벤트는 "백오프" 이벤트를 추적하고 스핀 잠금을 얻기 위해 가장 널리 사용되는 작업에 대한 호출 스택을 캡처하는 기능을 제공합니다. 호출 스택을 분석하여 특정 스핀 잠금에 대한 경합에 기여하는 작업 유형을 확인할 수 있습니다.
진단 연습
다음 연습에서는 도구와 기술을 사용하여 실제 시나리오에서 스핀 잠금 경합 문제를 진단하는 방법을 보여 줍니다. 이 연습은 고객 참여를 기반으로 하며 1TB 메모리가 있는 8소켓, 물리적 64코어 서버에서 약 6,500명의 동시 사용자를 시뮬레이트하는 벤치마크 테스트를 실행합니다.
증상
CPU 사용률을 거의 100%까지 푸시하는 주기적 CPU 급증이 관찰되었습니다. 처리량과 CPU 사용량 간의 차이가 관찰되어 문제가 발생했습니다. 큰 CPU 스파이크가 발생했을 때 특정 간격으로 CPU 사용량이 많은 시간 동안 많은 스핀이 발생하는 패턴이 설정되었습니다.
이것은 경합이 스핀 잠금 호송 조건을 만드는 극단적 인 경우였다. 호송은 스레드가 더 이상 워크로드 서비스를 진행할 수 없고 대신 잠금에 대한 액세스 권한을 얻기 위해 모든 처리 리소스를 소비할 때 발생합니다. 성능 모니터 로그는 트랜잭션 로그 처리량과 CPU 사용량 간의 이러한 차이를 보여 줍니다. 궁극적으로 CPU 사용률이 크게 급증합니다.
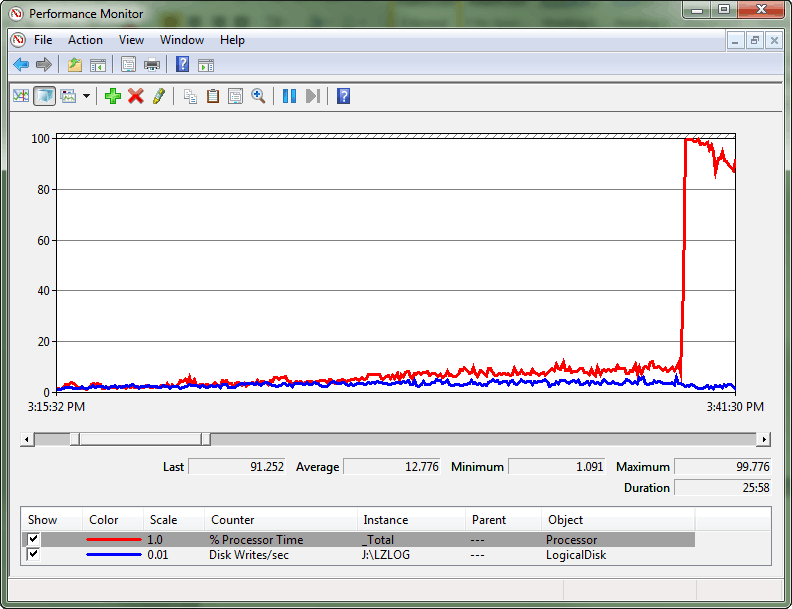
SOS_CACHESTORE 상당한 경합이 있는지 확인하기 위해 쿼리 sys.dm_os_spinlock_stats 한 후 확장 이벤트 스크립트를 사용하여 관심 있는 스핀 잠금 유형의 백오프 이벤트 수를 측정했습니다.
| 이름 | 충돌 | 스핀 횟수 | 충돌당 스핀 횟수 | 백오프 |
|---|---|---|---|---|
SOS_CACHESTORE |
14,752,117 | 942,869,471,526 | 63,914 | 67,900,620 |
SOS_SUSPEND_QUEUE |
69,267,367 | 473,760,338,765 | 6,840 | 2,167,281 |
LOCK_HASH |
5,765,761 | 260,885,816,584 | 45,247 | 3,739,208 |
MUTEX |
2,802,773 | 9,767,503,682 | 3,485 | 350,997 |
SOS_SCHEDULER |
1,207,007 | 3,692,845,572 | 3,060 | 109,746 |
스핀의 영향을 정량화하는 가장 간단한 방법은 스핀 수가 가장 많은 스핀 잠금 유형에 sys.dm_os_spinlock_stats 대해 동일한 1분 간격으로 노출된 백오프 이벤트 수를 보는 것입니다. 이 메서드는 스레드가 스핀 잠금을 획득하기 위해 대기하는 동안 스핀 제한을 소모하는 시기를 나타내기 때문에 상당한 경합을 감지하는 것이 가장 좋습니다. 다음 스크립트는 확장 이벤트를 활용하여 관련 백오프 이벤트를 측정하고 경합이 있는 특정 코드 경로를 식별하는 고급 기술을 보여 줍니다.
SQL Server의 확장 이벤트에 대한 자세한 내용은 SQL Server 확장 이벤트 소개를 참조 하세요.
스크립트
/*
This script is provided "AS IS" with no warranties, and confers no rights.
This script will monitor for backoff events over a given period of time and
capture the code paths (callstacks) for those.
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
Examples:
61LOCK_HASH
144 SOS_CACHESTORE
08MUTEX
*/
--create the even session that will capture the callstacks to a bucketizer
--more information is available in this reference: http://msdn.microsoft.com/en-us/library/bb630354.aspx
CREATE EVENT SESSION spin_lock_backoff ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
OR TYPE = 144 --SOS_CACHESTORE
OR TYPE = 8 --MUTEX
) ADD TARGET package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
);
--Ensure the session was created
SELECT * FROM sys.dm_xe_sessions
WHERE name = 'spin_lock_backoff';
--Run this section to measure the contention
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = START;
--wait to measure the number of backoffs over a 1 minute period
WAITFOR DELAY '00:01:00';
--To view the data
--1. Ensure the sqlservr.pdb is in the same directory as the sqlservr.exe
--2. Enable this trace flag to turn on symbol resolution
DBCC TRACEON (3656, -1);
--Get the callstacks from the bucketize target
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spin_lock_backoff';
--clean up the session
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = STOP;
DROP EVENT SESSION spin_lock_backoff ON SERVER;
출력을 분석하여 SOS_CACHESTORE 스핀에 대한 가장 일반적인 코드 경로에 대한 호출 스택을 볼 수 있습니다. 반환된 호출 스택의 일관성을 위해 CPU 사용률이 검사 높은 시간 동안 스크립트가 몇 번 실행되었습니다. 슬롯 버킷 수가 가장 높은 호출 스택은 두 출력(35,668 및 8,506) 간에 일반적입니다. 이러한 호출 스택에는 다음으로 높은 항목보다 큰 크기의 두 순서인 "슬롯 수"가 있습니다. 이 조건은 관심 있는 코드 경로를 나타냅니다.
참고 항목
이전 스크립트에서 반환된 호출 스택을 보는 것은 드문 일이 아닙니다. 스크립트가 1분 동안 실행되었을 때 슬롯 수가 > 1,000인 호출 스택이 문제가 되는 것을 확인했지만 슬롯 수가 더 높기 때문에 슬롯 수가 > 10,000개일수록 문제가 될 가능성이 더 큽니다.
참고 항목
다음 출력의 서식은 읽기 쉽도록 정리되었습니다.
출력 1
<BucketizerTarget truncated="0" buckets="256">
<Slot count="35668" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid
CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey
CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="752" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
출력 2
<BucketizerTarget truncated="0" buckets="256">
<Slot count="8506" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep+c7 [ @ 0+0x0 SpinlockBase::Backoff Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="190" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
이전 예제에서 가장 흥미로운 스택은 슬롯 개수(35,668 및 8,506)가 가장 높으며, 실제로 슬롯 수는 > 1000개입니다.
이제 질문은 "이 정보로 무엇을 해야 하나요"일 수 있습니다. 일반적으로 호출 스택 정보를 사용하려면 SQL Server 엔진에 대한 심층 지식이 필요하므로 이 시점에서 문제 해결 프로세스가 회색 영역으로 이동합니다. 이 특정 경우 호출 스택을 살펴보면 문제가 발생하는 코드 경로가 보안 및 메타데이터 조회와 관련이 있음을 알 수 있습니다(다음 스택 프레임에서 알 수 있음 CMEDCatalogOwner::GetProxyOwnerBySID & CMEDProxyDatabase::GetOwnerBySID)).
이 정보를 사용하여 문제를 해결하는 것은 어렵지만 문제를 추가로 격리하기 위해 추가 문제 해결에 집중할 수 있는 몇 가지 아이디어를 제공합니다.
해당 이슈는 보안 관련 검사를 수행하는 코드 경로와 관련된 것 같으므로 데이터베이스에 연결하는 애플리케이션 사용자에게 sysadmin 권한을 부여하는 테스트를 실행하기로 결정했습니다. 이 기술은 프로덕션 환경에서는 권장되지 않지만 테스트 환경에서는 유용한 문제 해결 단계로 입증되었습니다. 상승된 권한(sysadmin)을 사용하여 세션을 실행하면 경합과 관련된 CPU 스파이크가 사라졌습니다.
옵션 및 해결 방법
스핀 잠금 경합 문제 해결은 확실히 사소한 작업이 아닐 수 있습니다. "하나의 일반적인 가장 좋은 방법"은 없습니다. 성능 문제를 해결하고 해결하는 첫 번째 단계는 근본 원인을 식별하는 것입니다. 이 문서에서 설명하는 기술과 도구를 사용하는 것은 스핀 잠금 관련 경합 지점을 이해하는 데 필요한 분석을 수행하는 첫 번째 단계입니다.
최신 SQL Server 버전이 개발됨에 따라 높은 동시성 시스템에 최적화된 코드를 구현함으로써 엔진의 스케일링 성능이 계속 향상되고 있습니다. SQL Server는 높은 동시성 시스템을 위한 많은 최적화를 도입했으며, 그 중 하나가 가장 일반적인 경합 지점에 대한 지수 백오프입니다. 엔진 내의 모든 스핀 잠금에 지수 백오프 알고리즘을 활용하여 구체적으로 이 특정 영역을 향상하는 특정 개선 사항이 SQL Server 2012부터 도입되었습니다.
뛰어난 성능과 규모가 필요한 고급 애플리케이션을 디자인할 때 SQL Server 내에서 필요한 코드 경로를 최대한 짧게 유지하는 방법을 고려합니다. 코드 경로가 짧을수록 데이터베이스 엔진에서 수행하는 작업이 줄어들고 경합 지점이 자연스럽게 방지됩니다. 대부분의 모범 사례는 엔진에 필요한 작업의 양을 줄여 워크로드 성능을 최적화하는 부작용이 있습니다.
이 문서의 앞부분에서 몇 가지 모범 사례를 예로 들어 보세요.
정규화된 이름: 모든 개체의 이름을 정규화하면 SQL Server에서 이름을 확인하는 데 필요한 코드 경로를 실행할 필요가 없습니다. 저장 프로시저 호출에서 정규화된 이름을 사용하지 않을 때 발생하는 SOS_CACHESTORE 스핀 잠금 유형에서도 경합 지점을 관찰했습니다. 이러한 이름을 정규화하지 못하면 SQL Server에서 사용자의 기본 스키마를 조회해야 하므로 SQL을 실행하는 데 더 긴 코드 경로가 필요합니다.
매개 변수가 있는 쿼리: 또 다른 예제는 매개 변수가 있는 쿼리 및 저장 프로시저 호출을 활용하여 실행 계획을 생성하는 데 필요한 작업을 줄이는 것입니다. 이렇게 하면 실행 코드 경로가 짧아지게됩니다.
LOCK_HASH 경합: 특정 잠금 구조 또는 해시 버킷 충돌에 대한 경합은 경우에 따라 불가피합니다. SQL Server 엔진이 대부분의 잠금 구조를 분할하더라도 잠금을 획득하면 동일한 해시 버킷에 액세스할 수 있는 경우도 있습니다. 예를 들어 애플리케이션은 여러 스레드에 의해 동일한 행에 동시에 액세스합니다(즉, 참조 데이터). 이러한 유형의 문제는 데이터베이스 스키마 내에서 이 참조 데이터를 확장하거나 가능한 경우 NOLOCK 힌트를 사용하는 기술로 접근할 수 있습니다.
SQL Server 워크로드 튜닝의 첫 번째 방어선은 항상 표준 튜닝 방법(예: 인덱싱, 쿼리 최적화, I/O 최적화 등)입니다. 그러나 표준 튜닝 외에도 작업 수행에 필요한 코드 양을 줄이는 방법을 따르는 것이 중요합니다. 모범 사례를 따르는 경우에도 사용량이 많은 동시성 시스템에서 스핀 잠금 경합이 발생할 수 있습니다. 이 문서의 도구와 기술을 사용하면 이러한 유형의 문제를 격리하거나 배제하고 적절한 Microsoft 리소스를 사용해야 하는 시기를 결정하는 데 도움이 될 수 있습니다.
이러한 기술이 이러한 유형의 문제 해결에 유용한 방법론과 SQL Server에서 사용할 수 있는 고급 성능 프로파일링 기술 중 일부에 대한 인사이트를 모두 제공할 수 있기를 바랍니다.
부록: 메모리 덤프 캡처 자동화
다음 확장 이벤트 스크립트는 스핀 잠금 경합이 중요해질 때 메모리 덤프 컬렉션을 자동화하는 데 유용한 것으로 입증되었습니다. 경우에 따라 메모리 덤프는 문제를 완전히 진단해야 하거나 Microsoft 지원 팀이 심층 분석을 수행하도록 요청합니다. SQL Server 2008에는 버킷타이저에서 캡처한 호출 스택에 16개의 프레임이 제한되며, 이는 엔진에서 호출 스택이 입력되는 위치를 정확하게 결정할 만큼 충분히 깊지 않을 수 있습니다. SQL Server 2012에서는 버킷타이저에서 캡처한 호출 스택의 프레임 수를 32개로 늘려 개선되었습니다.
다음 SQL 스크립트를 사용하여 메모리 덤프를 캡처하는 프로세스를 자동화하여 스핀 잠금 경합을 분석할 수 있습니다.
/*
This script is provided "AS IS" with no warranties, and confers no rights.
Use: This procedure will monitor for spinlocks with a high number of backoff events
over a defined time period which would indicate that there is likely significant
spin lock contention.
Modify the variables noted below before running.
Requires:
xp_cmdshell to be enabled
sp_configure 'xp_cmd', 1
go
reconfigure
go
*********************************************************************************************************/
USE tempdb;
GO
IF object_id('sp_xevent_dump_on_backoffs') IS NOT NULL
DROP PROCEDURE sp_xevent_dump_on_backoffs
GO
CREATE PROCEDURE sp_xevent_dump_on_backoffs (
@sqldumper_path NVARCHAR(max) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"',
@dump_threshold INT = 500, --capture mini dump when the slot count for the top bucket exceeds this
@total_delay_time_seconds INT = 60, --poll for 60 seconds
@PID INT = 0,
@output_path NVARCHAR(MAX) = 'c:\',
@dump_captured_flag INT = 0 OUTPUT
)
AS
/*
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
*/
IF EXISTS (
SELECT *
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump'
)
DROP EVENT SESSION spinlock_backoff_with_dump
ON SERVER
CREATE EVENT SESSION spinlock_backoff_with_dump ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
--or type = 144 --SOS_CACHESTORE
--or type = 8 --MUTEX
--or type = 53 --LOGCACHE_ACCESS
--or type = 41 --LOGFLUSHQ
--or type = 25 --SQL_MGR
--or type = 39 --XDESMGR
) ADD target package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
)
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = START;
DECLARE @instance_name NVARCHAR(MAX) = @@SERVICENAME;
DECLARE @loop_count INT = 1;
DECLARE @xml_result XML;
DECLARE @slot_count BIGINT;
DECLARE @xp_cmdshell NVARCHAR(MAX) = NULL;
--start polling for the backoffs
PRINT 'Polling for: ' + convert(VARCHAR(32), @total_delay_time_seconds) + ' seconds';
WHILE (@loop_count < CAST(@total_delay_time_seconds / 1 AS INT))
BEGIN
WAITFOR DELAY '00:00:01'
--get the xml from the bucketizer for the session
SELECT @xml_result = CAST(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
--get the highest slot count from the bucketizer
SELECT @slot_count = @xml_result.value(N'(//Slot/@count)[1]', 'int');
--if the slot count is higher than the threshold in the one minute period
--dump the process and clean up session
IF (@slot_count > @dump_threshold)
BEGIN
PRINT 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 c:\ '''
SELECT @xp_cmdshell = 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 ' + @output_path + ' '''
EXEC sp_executesql @xp_cmdshell
PRINT 'loop count: ' + convert(VARCHAR(128), @loop_count)
PRINT 'slot count: ' + convert(VARCHAR(128), @slot_count)
SET @dump_captured_flag = 1
BREAK
END
--otherwise loop
SET @loop_count = @loop_count + 1
END;
--see what was collected then clean up
DBCC TRACEON (3656, -1);
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = STOP;
DROP EVENT SESSION spinlock_backoff_with_dump ON SERVER;
GO
/* CAPTURE THE DUMPS
******************************************************************/
--Example: This will run continuously until a dump is created.
DECLARE @sqldumper_path NVARCHAR(MAX) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"';
DECLARE @dump_threshold INT = 300; --capture mini dump when the slot count for the top bucket exceeds this
DECLARE @total_delay_time_seconds INT = 60; --poll for 60 seconds
DECLARE @PID INT = 0;
DECLARE @flag TINYINT = 0;
DECLARE @dump_count TINYINT = 0;
DECLARE @max_dumps TINYINT = 3; --stop after collecting this many dumps
DECLARE @output_path NVARCHAR(max) = 'c:\'; --no spaces in the path please :)
--Get the process id for sql server
DECLARE @error_log TABLE (
LogDate DATETIME,
ProcessInfo VARCHAR(255),
TEXT VARCHAR(max)
);
INSERT INTO @error_log
EXEC ('xp_readerrorlog 0, 1, ''Server Process ID''');
SELECT @PID = convert(INT, (REPLACE(REPLACE(TEXT, 'Server Process ID is ', ''), '.', '')))
FROM @error_log
WHERE TEXT LIKE ('Server Process ID is%');
PRINT 'SQL Server PID: ' + convert(VARCHAR(6), @PID);
--Loop to monitor the spinlocks and capture dumps. while (@dump_count < @max_dumps)
BEGIN
EXEC sp_xevent_dump_on_backoffs @sqldumper_path = @sqldumper_path,
@dump_threshold = @dump_threshold,
@total_delay_time_seconds = @total_delay_time_seconds,
@PID = @PID,
@output_path = @output_path,
@dump_captured_flag = @flag OUTPUT
IF (@flag > 0)
SET @dump_count = @dump_count + 1
PRINT 'Dump Count: ' + convert(VARCHAR(2), @dump_count)
WAITFOR DELAY '00:00:02'
END;
부록: 시간에 따른 스핀 잠금 통계 캡처
다음 스크립트를 사용하여 특정 기간 동안의 스핀 잠금 통계를 확인할 수 있습니다. 실행할 때마다 현재 값과 수집된 이전 값 사이의 델타를 반환합니다.
/* Snapshot the current spinlock stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
USE tempdb;
GO
DECLARE @current_snap_time DATETIME;
DECLARE @previous_snap_time DATETIME;
SET @current_snap_time = GETDATE();
IF NOT EXISTS (
SELECT name
FROM tempdb.sys.sysobjects
WHERE name LIKE '#_spin_waits%'
)
CREATE TABLE #_spin_waits (
lock_name VARCHAR(128),
collisions BIGINT,
spins BIGINT,
sleep_time BIGINT,
backoffs BIGINT,
snap_time DATETIME
);
--capture the current stats
INSERT INTO #_spin_waits (
lock_name,
collisions,
spins,
sleep_time,
backoffs,
snap_time
)
SELECT name,
collisions,
spins,
sleep_time,
backoffs,
@current_snap_time
FROM sys.dm_os_spinlock_stats;
SELECT TOP 1 @previous_snap_time = snap_time
FROM #_spin_waits
WHERE snap_time < (
SELECT max(snap_time)
FROM #_spin_waits
)
ORDER BY snap_time DESC;
--get delta in the spin locks stats
SELECT TOP 10 spins_current.lock_name,
(spins_current.collisions - spins_previous.collisions) AS collisions,
(spins_current.spins - spins_previous.spins) AS spins,
(spins_current.sleep_time - spins_previous.sleep_time) AS sleep_time,
(spins_current.backoffs - spins_previous.backoffs) AS backoffs,
spins_previous.snap_time AS [start_time],
spins_current.snap_time AS [end_time],
DATEDIFF(ss, @previous_snap_time, @current_snap_time) AS [seconds_in_sample]
FROM #_spin_waits spins_current
INNER JOIN (
SELECT *
FROM #_spin_waits
WHERE snap_time = @previous_snap_time
) spins_previous
ON (spins_previous.lock_name = spins_current.lock_name)
WHERE spins_current.snap_time = @current_snap_time
AND spins_previous.snap_time = @previous_snap_time
AND spins_current.spins > 0
ORDER BY (spins_current.spins - spins_previous.spins) DESC;
--clean up table
DELETE
FROM #_spin_waits
WHERE snap_time = @previous_snap_time;
다음 단계
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기