적용 대상:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() Microsoft Fabric의 SQL 데이터베이스
Microsoft Fabric의 SQL 데이터베이스
Columnstore 인덱스는 대규모 데이터 웨어하우징 팩트 테이블을 저장하고 쿼리하는 표준입니다. 이 인덱스는 열 기반 데이터 스토리지 및 쿼리 처리를 사용하여 데이터 웨어하우스에서 기존 행 기반 스토리지보다 최대 10배 높은 쿼리 성능을 실현합니다. 또한 압축되지 않은 데이터 크기보다 최대 10배의 데이터 압축 향상을 얻을 수 있습니다. SQL Server 2016(13.x) SP1부터 columnstore 인덱스는 트랜잭션 워크로드에 고성능 실시간 분석을 실행하는 기능인 운영 분석을 지원합니다.
관련 시나리오에 대해 알아봅니다.
컬럼스토어 인덱스란 무엇입니까?
Columnstore 인덱스는 columnstore라는 칼럼 데이터 서식을 사용하여 데이터를 저장, 검색, 관리하는 기술입니다.
주요 용어 및 개념
다음은 columnstore 인덱스와 관련된 주요 용어와 개념입니다.
컬럼스토어
columnstore는 행과 열이 있는 테이블로 논리적으로 구성되고 열 데이터 형식으로 물리적으로 저장되는 데이터입니다.
행 저장
rowstore는 행과 열이 있는 테이블로 논리적으로 구성되고 행 데이터 형식으로 물리적으로 저장되는 데이터입니다. 이 형식은 관계형 테이블 데이터를 저장하는 전통적인 방법입니다. SQL Server에서 rowstore는 기본 데이터 스토리지 형식이 힙, 클러스터형 인덱스인 테이블 또는 메모리 최적화 테이블을 참조합니다.
참고
Columnstore 인덱스에 대한 설명에서는 데이터 스토리지에 대한 서식을 강조하기 위해 rowstore 및 columnstore라는 용어를 사용합니다.
로우그룹
행 그룹은 columnstore 서식으로 동시에 압축되는 행의 그룹입니다. 열 그룹에는 대개 1,048,576개(행 그룹당 최대 행 수)의 행이 포함됩니다.
Columnstore 인덱스는 성능과 압축률을 높이기 위해 테이블을 여러 행 그룹으로 조각화한 후에 각 행 그룹을 열 방식으로 압축합니다. 행 그룹의 행 수는 압축 속도를 향상시킬 만큼 충분히 크고 메모리 내 작업의 이점을 얻을 수 있을 만큼 작아야 합니다.
모든 데이터가 삭제된 행 그룹은 COMPRESSED에서 TOMBSTONE 상태로 전환되고 나중에 튜플 이동기라는 백그라운드 프로세스에 의해 제거됩니다. 행 그룹 상태에 대한 자세한 내용은 sys.dm_db_column_store_row_group_physical_stats(Transact-SQL)를 참조하세요.
팁
소규모의 행 그룹이 너무 많으면 columnstore 인덱스 품질이 저하됩니다. SQL Server 2017(14.x)까지는 삭제된 행을 제거하고 압축된 행 그룹을 결합하는 방법을 결정하는 내부 임계값 정책에 따라 더 작은 COMPRESSED 행 그룹을 병합하려면 재구성 작업이 필요합니다.
SQL Server 2019(15.x)부터 백그라운드 병합 작업은 많은 수의 행이 삭제된 COMPRESSED 행 그룹을 병합하는 작업도 수행합니다.
더 작은 행 그룹을 병합한 후에는 인덱스 품질이 향상되어야 합니다.
참고
SQL Server 2019(15.x), Azure SQL 데이터베이스, Azure SQL Managed Instance, Azure Synapse Analytics의 전용 SQL 풀부터는 내부 임계값에 따라 특정 시간 동안 존재하던 더 작은 열린 델타 행 그룹을 자동으로 압축하거나 다수의 행이 삭제된 곳에서 압축된 행 그룹을 병합하는 백그라운드 병합 작업이 튜플 이동기를 지원합니다. 그러면 시간이 지남에 따라 columnstore 인덱스 품질이 향상됩니다.
열 분할
열 세그먼트는 행 그룹 내의 데이터 열입니다.
- 각 행 그룹에는 테이블의 모든 열에 대해 하나의 열 세그먼트가 포함됩니다.
- 각 열 세그먼트는 함께 압축되며 실제 미디어에 저장됩니다.
- 세그먼트를 읽지 않고도 세그먼트를 빠르게 제거할 수 있도록 각 세그먼트에 메타데이터가 있습니다.
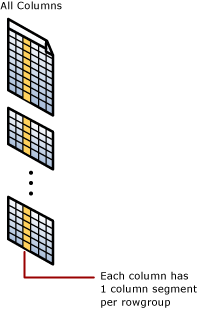
클러스터형 columnstore 인덱스
클러스터형 columnstore 인덱스는 전체 테이블에 대한 실제 스토리지입니다.
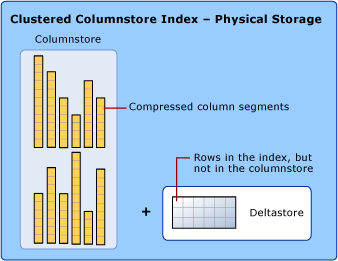
columnstore 인덱스는 열 세그먼트의 조각화를 줄이고 성능을 향상하기 위해 삭제된 행에 대한 ID의 B-트리 목록과 함께 deltastore라는 클러스터형 인덱스에 일부 데이터를 임시로 저장할 수 있습니다. deltastore 작업은 백그라운드에서 처리됩니다. 정확한 쿼리 결과를 반환하기 위해 클러스터형 columnstore 인덱스는 columnstore와 deltastore의 쿼리 결과를 모두 결합합니다.
참고
설명서는 인덱스를 지칭할 때 B-트리라는 용어를 사용합니다. rowstore 인덱스에서 데이터베이스 엔진은 B+ 트리를 구현합니다. 이는 columnstore 인덱스나 메모리 최적화 테이블 인덱스에는 적용되지 않습니다. 자세한 내용은 SQL Server 및 Azure SQL 인덱스 아키텍처 및 디자인 가이드를 참조하세요.
델타 행 그룹
델타 행 그룹은 columnstore 인덱스에만 사용되는 클러스터형 B-트리 인덱스입니다. 행을 저장하여 1,048,576개의 행이라는 임계값에 도달할 때까지 기다린 후, 이들 열을 columnstore로 이동시켜 columnstore의 압축 및 성능을 개선합니다.
델타 행 그룹이 최대 행 수에 도달하면 OPEN에서 CLOSED로 상태가 전환됩니다. 튜플 이동 장치라는 백그라운드 프로세스는 닫힌 행 그룹이 있는지 확인합니다. 닫힌 행 그룹이 있으면 델타 행 그룹을 압축하여 columnstore에 COMPRESSED 행 그룹으로 저장합니다.
델타 행 그룹이 압축된 경우 기존 델타 행 그룹은 TOMBSTONE 상태로 전환되어 나중에 이 그룹에 대한 참조가 없어지면 튜플 이동기에 의해 제거됩니다.
행 그룹 상태에 대한 자세한 내용은 sys.dm_db_column_store_row_group_physical_stats(Transact-SQL)를 참조하세요.
참고
SQL Server 2019(15.x)부터는 내부 임계값에 따라 특정 시간 동안 존재하던 더 작은 열린 델타 행 그룹을 자동으로 압축하거나 다수의 행이 삭제된 곳에서 압축된 행 그룹을 병합하는 백그라운드 병합 작업이 튜플 이동기를 지원합니다. 그러면 시간이 지남에 따라 columnstore 인덱스 품질이 향상됩니다.
Deltastore
columnstore 인덱스에는 둘 이상의 델타 행 그룹이 포함될 수 있습니다. 모든 델타 행 그룹을 통칭하여 deltastore라고 합니다.
대량 데이터 로드 시 대부분의 행은 "deltastore"를 통과하지 않고 "columnstore"로 직접 이동합니다. 대량 로드의 끝에 있는 일부 행은 행 그룹의 최소 크기(102,400개 행)를 충족하기에는 너무 적을 수 있습니다. 따라서 최종 행은 columnstore 대신 deltastore로 이동합니다. 행이 102,400개 미만인 소규모 대량 로드의 경우 모든 행이 deltastore로 직접 이동합니다.
비클러스터형 columnstore 인덱스
비클러스터형 columnstore 인덱스와 클러스터형 columnstore 인덱스는 동일하게 기능합니다. 차이는 비클러스터형 인덱스가 rowstore 테이블에 만들어지는 보조 인덱스이지만 클러스터형 columnstore 인덱스는 전체 테이블의 기본 스토리지라는 점입니다.
비클러스터형 인덱스에는 기본 테이블의 일부 또는 모든 행과 열의 복사본이 포함됩니다. 인덱스는 테이블의 하나 이상의 열로 정의되며 행을 필터링하는 선택적 조건이 있습니다.
비클러스터형 columnstore 인덱스를 사용하면 OLTP 워크로드가 기본 클러스터형 인덱스를 사용하는 동시에 columnstore 인덱스에서 분석이 동시에 실행되는 실시간 운영 분석을 사용할 수 있습니다. 자세한 내용은 실시간 운영 분석을 위한 칼럼스토어 시작하기를 참조하세요.
일괄 처리 모드 실행
일괄 처리 모드 실행은 여러 행을 함께 처리하는 쿼리 처리 방법입니다. 배치 모드 실행은 columnstore 스토리지 형식과 긴밀히 통합되고 그에 맞게 최적화되어 있습니다. 일괄 처리 모드 실행을 벡터 기반 또는 벡터화된 실행이라고도 합니다. Columnstore 인덱스에 대한 쿼리는 일반적으로 쿼리 성능을 2~4배 개선하는 일괄 처리 모드 실행을 사용합니다. 자세한 내용은 쿼리 처리 아키텍처 가이드를 참조하세요.
Columnstore 인덱스를 사용해야 하는 이유
Columnstore 인덱스는 매우 높은 수준의 데이터 압축(일반적으로 10배)을 제공하여 데이터 웨어하우스 스토리지 비용을 크게 줄일 수 있습니다. columnstore 인덱스는 B-트리 인덱스보다 뛰어난 분석 성능을 제공합니다. Columnstore 인덱스는 데이터 웨어하우징 및 분석 워크로드에 대한 기본 데이터 스토리지 형식입니다. SQL Server 2016(13.x)부터 운영 워크로드에 대한 실시간 분석에 columnstore 인덱스를 사용할 수 있습니다.
columnstore 인덱스가 매우 빠른 이유는 다음과 같습니다.
열은 동일한 도메인의 값을 저장하고 일반적으로 비슷한 값을 가지며, 이로 인해 압축 속도가 높습니다. 시스템의 I/O 병목 상태가 최소화되거나 제거되고 메모리 공간이 크게 줄어듭니다.
압축 비율이 높으면 메모리 내 사용 공간이 감소되어 쿼리 성능이 향상됩니다. SQL Server는 메모리에서 더 많은 쿼리 및 데이터 작업을 수행할 수 있어 쿼리 성능이 향상될 수 있습니다.
일괄 처리 실행은 여러 행을 함께 처리하여 쿼리 성능이 일반적으로 2~4배 향상됩니다.
쿼리는 종종 테이블에서 몇 개의 열만 선택하여 실제 미디어의 총 I/O를 줄입니다.
Columnstore 인덱스를 언제 사용해야 하나요?
권장 사용 사례는 다음과 같습니다.
데이터 웨어하우징 워크로드에서 팩트 테이블과 큰 차원 테이블을 저장하기 위해 클러스터형 columnstore 인덱스를 사용합니다. 이 메서드는 쿼리 성능 및 데이터 압축을 최대 10배 향상시킵니다. 자세한 내용은 데이터 웨어하우징용 columnstore 인덱스를 참조하세요.
비클러스터형 columnstore 인덱스를 사용하여 OLTP 워크로드에 대한 실시간 분석을 수행할 수 있습니다. 자세한 내용은 실시간 운영 분석을 위한 칼럼스토어 시작하기를 참조하세요.
columnstore 인덱스에 대한 더 많은 사용 시나리오는 요구 사항에 가장 적합한 columnstore 인덱스 선택을 참조하세요.
Rowstore 인덱스와 Columnstore 인덱스 간에 선택하려면 어떻게 해야 합니까?
Rowstore 인덱스는 데이터를 검색하는 쿼리, 특정 값을 검색할 때 또는 작은 범위의 값에 대한 쿼리에 가장 적합합니다. Rowstore 인덱스는 테이블 검색 대신 주로 테이블 찾기가 필요한 경향이 있으므로 트랜잭션 워크로드에서 사용됩니다.
Columnstore 인덱스는 특히 큰 테이블에서 많은 양의 데이터를 검색하는 분석 쿼리에 대해 높은 성능 향상 효과를 제공합니다. 데이터 웨어하우징 및 분석 워크로드, 특히 팩트 테이블에서는 보통 테이블 탐색보다 전체 테이블 검색이 필요하므로, columnstore 인덱스를 사용하는 것이 좋습니다.
순서가 지정된 클러스터형 columnstore 인덱스는 순서가 지정된 열 조건자를 기반으로 쿼리의 성능을 향상시킵니다. 순서가 지정된 columnstore 인덱스는 행 그룹 제거를 개선할 수 있으므로 행 그룹을 모두 건너뛰어 성능이 향상될 수 있습니다. 자세한 내용은 순서가 지정된 columnstore 인덱스 성능 튜닝을 참조하세요. 순서형 columnstore 인덱스 가용성에 대한 정보를 보려면 순서형 열 인덱스 가용성을 참조하세요.
같은 테이블에 rowstore와 columnstore를 결합할 수 있나요?
예. SQL Server 2016(13.x)부터 rowstore 테이블에서 업데이트 가능한 비클러스터형 columnstore 인덱스를 만들 수 있습니다. columnstore 인덱스는 선택한 열의 복사본을 저장하므로 이 데이터에 대한 추가 공간이 필요하지만 선택한 데이터는 평균 10회 압축됩니다. columnstore 인덱스에서 분석을 실행하고 이와 동시에 rowstore 인덱스에서 트랜잭션을 실행할 수 있습니다. rowstore 테이블의 데이터가 변경되면 columnstore가 업데이트되므로 두 인덱스 모두 동일한 데이터에 대해 작동합니다.
SQL Server 2016(13.x)부터 columnstore 인덱스에 하나 이상의 비클러스터형 rowstore 인덱스를 만들고 기본 columnstore에서 효율적인 테이블 검색을 수행할 수 있습니다. 다른 옵션도 사용할 수 있습니다. 예를 들어 rowstore 테이블에서 UNIQUE 제약 조건을 사용하여 기본 키 제약 조건을 적용할 수 있습니다. 고유하지 않은 값은 rowstore 테이블에 삽입하지 못하므로 SQL Server에서는 columnstore에 값을 삽입할 수 없습니다.
순서가 지정된 열 저장소 인덱스
효율적인 세그먼트 제거를 사용하도록 설정하면 정렬된 columnstore 인덱스는 쿼리 조건자와 일치하지 않는 대량의 정렬된 데이터를 건너뛰어 더 빠른 성능을 제공합니다. 정렬된 columnstore 인덱스에 데이터를 로드하는 작업은 데이터 정렬 작업으로 인해 정렬되지 않은 인덱스보다 오래 걸릴 수 있지만 순서가 지정된 columnstore 인덱스를 사용하면 나중에 쿼리가 더 빠르게 실행될 수 있습니다.
- 정렬된 columnstore 인덱스를 사용하여 SQL Database 엔진의 데이터 웨어하우징 워크로드 성능을 튜닝하는 방법에 대한 자세한 내용은 정렬된 columnstore 인덱스를 이용한 성능 튜닝을 참조하세요.
- columnstore 인덱스 유형을 사용하는 시기에 대한 자세한 내용은 요구 사항에 가장 적합한 columnstore 인덱스 선택을 참조 하세요.
순서가 지정된 columnstore 인덱스 가용성
정렬된 columnstore 인덱스는 다음 플랫폼에서 사용할 수 있습니다.
| 플랫폼 | 정렬된 클러스터형 columnstore 인덱스 | 정렬된 비클러스터형 columnstore 인덱스 |
|---|---|---|
| Azure SQL 데이터베이스 | 예 | 예 |
| Azure SQL Managed InstanceAUTD | 예 | 예 |
| Azure SQL Managed Instance2022 | 예 | 아니요 |
| Microsoft Fabric의 SQL 데이터베이스 | 예1 | 예 |
| SQL Server 2025(17.x) 미리 보기 | 예 | 예 |
| SQL Server 2022(16.x) | 예 | 아니요 |
| Azure Synapse Analytics의 전용 SQL 풀 | 예 | 아니요 |
AUTD Azure SQL Managed Instance는 Always-up-to-date 업데이트 정책로 구성되어 적용됩니다.
2022SQL Server 2022 업데이트 정책구성된 Azure SQL Managed Instance에 적용됩니다.
1Fabric SQL 데이터베이스에서는 클러스터형 columnstore 인덱스가 있는 테이블이 Fabric OneLake 에미러되지 않습니다.
메타데이터
columnstore 인덱스에 있는 모든 열이 메타데이터에 포괄 열로 저장됩니다. columnstore 인덱스에는 키 열이 없습니다.
관련 작업
| 작업 | 참조 문서 | 노트 |
|---|---|---|
| 컬럼스토어 형식으로 테이블을 만듭니다. | CREATE TABLE(Transact-SQL) | 기본적으로 테이블을 만들 때는 rowstore를 기본 데이터 형식으로 사용합니다. SQL Server 2016(13.x)부터 옵션을 지정하여 INDEX ... CLUSTERED COLUMNSTORE 클러스터형 columnstore 인덱스가 있는 테이블을 만들 수 있습니다. 먼저 rowstore 테이블을 만든 다음 columnstore로 변환할 필요가 없습니다. |
| rowstore 테이블을 columnstore로 변환합니다. | columnstore 인덱스 만들기(Transact-SQL) | 기존 힙 또는 B-트리를 컬럼스토어로 변환합니다. 이 변환을 수행할 때 기존 인덱스 및 인덱스의 이름을 처리하는 방법을 보여줍니다. |
| rowstore 테이블에 비클러스터형 columnstore 인덱스 만들기 | columnstore 인덱스 만들기(Transact-SQL) | Rowstore 테이블에는 비클러스터형 columnstore 인덱스 한 개가 있을 수 있습니다. SQL Server 2016(13.x)부터 비클러스터형 columnstore 인덱스가 필터링된 조건을 가질 수 있습니다. 예제에서는 기본 구문을 보여 줍니다. |
| columnstore 테이블을 rowstore로 변환합니다. | 클러스터형 인덱스 만들기(Transact-SQL) 또는 columnstore 테이블을 rowstore 힙으로 변환 | 일반적으로 이 변환은 필요하지 않지만 변환해야 하는 경우가 있을 수 있습니다. 예제에서는 columnstore를 힙 또는 클러스터형 인덱스로 변환하는 방법을 보여줍니다. |
| 데이터 웨어하우징을 위한 columnstore 인덱스를 만듭니다. | 데이터 웨어하우스를 위한 컬럼스토어 인덱스 | 빠른 데이터 웨어하우징 쿼리에 columnstore 인덱스를 사용하는 방법을 설명합니다. |
| 운영 분석을 위한 인덱스를 만듭니다. | 실시간 운영 분석을 위한 칼럼스토어 활용 시작하기 | OLTP 쿼리가 B-트리 인덱스를 사용하고 분석 쿼리가 columnstore 인덱스를 사용하도록 상호 보완적인 columnstore 및 B-트리 인덱스를 만드는 방법을 설명합니다. |
| B-트리 인덱스를 사용하여 columnstore 인덱스에 기본 키 제약 조건을 적용합니다. | 데이터 웨어하우스를 위한 컬럼스토어 인덱스 | B-트리와 columnstore 인덱스를 결합하여 columnstore 테이블에 기본 키 제약 조건을 적용하는 방법을 보여줍니다. |
| columnstore 인덱스가 포함된 메모리 최적화 테이블을 만듭니다. | CREATE TABLE(Transact-SQL) | SQL Server 2016(13.x)부터 columnstore 인덱스가 있는 메모리 최적화 테이블을 만들 수 있습니다.
ALTER TABLE ADD INDEX 구문을 사용하여 테이블을 만든 후 columnstore 인덱스를 추가할 수도 있습니다. |
| 데이터를 columnstore 인덱스로 로드합니다. | 컬럼스토어 인덱스 데이터 로드 | |
| Columnstore 인덱스를 삭제하십시오. | DROP INDEX(Transact-SQL) | columnstore 인덱스를 삭제할 때는 B-트리 인덱스에서 사용하는 표준 DROP INDEX 구문을 사용합니다. 클러스터형 columnstore 인덱스를 삭제하면 columnstore 테이블이 힙으로 변환됩니다. |
| Columnstore 인덱스에서 행을 삭제합니다. | DELETE (Transact-SQL) |
DELETE(Transact-SQL)를 사용하여 행을 삭제합니다. columnstore 행: SQL Server는 행을 논리적으로 삭제된 것으로 표시하지만, 인덱스가 다시 작성될 때까지는 행에 대한 실제 스토리지를 회수하지 않습니다. deltastore 행: SQL Server가 행을 논리적으로 그리고 물리적으로 삭제합니다. |
| columnstore 인덱스의 행을 갱신합니다. | UPDATE(Transact-SQL) |
UPDATE(Transact-SQL)를 사용하여 행을 업데이트합니다. columnstore 행: SQL Server는 행을 논리적으로 삭제된 것으로 표시한 다음 업데이트된 행을 deltastore에 삽입합니다. deltastore 행: SQL Server는 deltastore의 행을 업데이트합니다. |
| columnstore 인덱스 유지 관리 |
ALTER INDEX ... 재구성하다 columnstore 인덱스 다시 구성 인덱스 유지 관리 방법: 재구성 및 다시 작성 |
대부분의 경우 ALTER INDEX ... REORGANIZE 리소스 사용량이 적지만 유사하게 ALTER INDEX ... REBUILD 결과를 제공합니다.
ALTER INDEX ... REORGANIZE 항상 온라인으로 실행됩니다. 두 옵션 모두 컬럼스토어 인덱스를 조각 모음하고 델타스토어의 행이 컬럼스토어로 이동하도록 강제합니다.SQL Server 2019(15.x)부터 Azure SQL Database 및 Azure SQL Managed Instance에서 columnstore 인덱스 품질이 자동으로 유지되므로 대부분의 경우 주기적인 인덱스 유지 관리가 필요하지 않습니다. |