누락된 인덱스 제안으로 비클러스터형 인덱스 조정
적용 대상: ![]() SQL Server
SQL Server ![]() Azure SQL 데이터베이스
Azure SQL 데이터베이스 ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
누락된 인덱스 기능은 쿼리 성능을 크게 향상시킬 수 있는 누락된 인덱스를 찾아 주는 간단한 도구입니다. 이 문서에서는 누락된 인덱스 제안을 사용하여 인덱스를 효과적으로 조정하고 쿼리 성능을 개선하는 방법을 설명합니다.
누락된 인덱스 기능의 제한 사항
쿼리 최적화 프로그램은 쿼리 계획을 생성할 때 어떤 인덱스가 특정 필터 조건에 가장 적합한지 분석합니다. 최상의 인덱스가 없을 경우 쿼리 최적화 프로그램에서 사용 가능한 가장 비용이 적게 드는 액세스 방법을 사용하여 쿼리 계획을 생성하지만 이러한 인덱스에 대한 정보도 저장합니다. 누락된 인덱스 기능을 통해 가능한 최상의 인덱스 정보에 액세스하고 구현 여부를 결정할 수 있습니다.
쿼리 최적화는 시간이 중요한 프로세스이므로 누락된 인덱스 기능에는 제한 사항이 있습니다. 제한에는 다음 내용이 포함됩니다.
- 누락된 인덱스 제안은 쿼리를 실행하기 전에 단일 쿼리를 최적화하는 동안 수행된 예상을 기반으로 합니다. 누락된 인덱스 제안은 쿼리 실행 후에 테스트되거나 업데이트되지 않습니다.
- 누락된 인덱스 기능은 비클러스터형 디스크 기반 rowstore 인덱스만 제안합니다. 고유 및 필터링된 인덱스는 제안되지 않습니다.
- 키 열은 제안되지만, 제안에서는 해당 열에 대한 순서를 지정하지 않습니다. 열 정렬에 대한 자세한 내용은 이 문서의 누락된 인덱스 제안 적용 섹션을 참조하세요.
- 포괄 열이 제안되지만 SQL Server에서 제안된 포괄 열이 많은 경우 결과 인덱스의 크기에 대한 비용 이점 분석을 수행하지 않습니다.
- 누락된 인덱스 요청은 쿼리 전체의 동일한 테이블 및 열에 대해 유사한 인덱스 변형을 제공할 수 있습니다. 인덱스 제안을 검토하고 가능한 경우 결합하는 것이 중요합니다.
- 간단한 쿼리 계획에 대한 제안은 제공되지 않습니다.
- 같지 않음 조건자만 포함하는 쿼리의 경우 비용 정보의 정확도가 낮습니다.
- 최대 600개까지 누락된 인덱스 그룹에 대한 제안이 수집됩니다. 이 임계값에 도달하면 누락된 인덱스 그룹 데이터가 더 이상 수집되지 않습니다.
이러한 제한 사항으로 인해 누락된 인덱스 제안은 인덱스 분석, 디자인, 튜닝 및 테스트를 수행할 때 여러 정보 원본 중 하나로 가장 잘 처리됩니다. 누락된 인덱스 제안은 제안된 그대로 인덱스를 만드는 처방전이 아닙니다.
참고 항목
Azure SQL Database는 자동 인덱스 튜닝을 제공합니다. 자동 인덱스 튜닝은 기계 학습을 사용하여 AI를 통해 Azure SQL Database의 모든 데이터베이스를 수평으로 학습하고 튜닝 작업을 동적으로 개선합니다. 자동 인덱스 튜닝에는 만들어진 인덱스의 워크로드 성능이 긍정적으로 향상되도록 하는 확인 프로세스가 포함되어 있습니다.
누락된 인덱스 권장 사항 보기
누락된 인덱스 기능은 다음 구성 요소로 구성됩니다.
- 실행 계획의 XML에 있는
MissingIndexes요소 이렇게 하면 쿼리 최적화 프로그램에서 누락된 것으로 간주하는 인덱스와 누락된 쿼리의 상관관계를 지정할 수 있습니다. - 누락된 인덱스에 대한 정보를 반환하기 위해 쿼리할 수 있는 DMV(동적 관리 뷰) 세트 이렇게 하면 데이터베이스의 누락된 인덱스 권장 사항을 모두 볼 수 있습니다.
실행 계획에서 누락된 인덱스 제안 보기
쿼리 실행 계획은 여러 가지 방법으로 만들거나 가져올 수 있습니다.
- 쿼리를 작성하거나 튜닝할 때 SSMS(SQL Server Management Studio)를 사용하여 쿼리를 실행하지 않고 예상 실행 계획을 표시하거나 쿼리를 실행하고 실제 실행 계획을 표시할 수 있습니다.
- 쿼리 저장소를 사용하도록 설정하면 실행 계획을 수집합니다.
- sys.dm_exec_text_query_plan과 같은 DMV를 쿼리하여 캐시된 실행 계획을 식별할 수 있습니다.
예를 들어 다음 쿼리를 사용하여 AdventureWorks 샘플 데이터베이스에 누락된 인덱스 요청을 생성할 수 있습니다.
SELECT City, StateProvinceID, PostalCode
FROM Person.Address as a
JOIN Person.BusinessEntityAddress as ba on
a.AddressID = ba.AddressID
JOIN Person.Person as p on
ba.BusinessEntityID = p.BusinessEntityID
WHERE p.FirstName like 'K%' and
StateProvinceID = 9;
GO
누락된 인덱스 요청을 생성하고 보려면 다음을 수행합니다.
SSMS를 열고 AdventureWorks 샘플 데이터베이스의 복사본에 세션을 연결합니다.
SSMS에서 쿼리를 세션에 붙여넣고 예상 실행 계획 표시 도구 모음 단추를 선택하여 해당 쿼리에 대한 예상 실행 계획을 생성합니다. 실행 계획은 현재 세션의 창에 표시됩니다. 그래픽 계획의 맨 위에 녹색 누락 인덱스 문이 나타납니다.
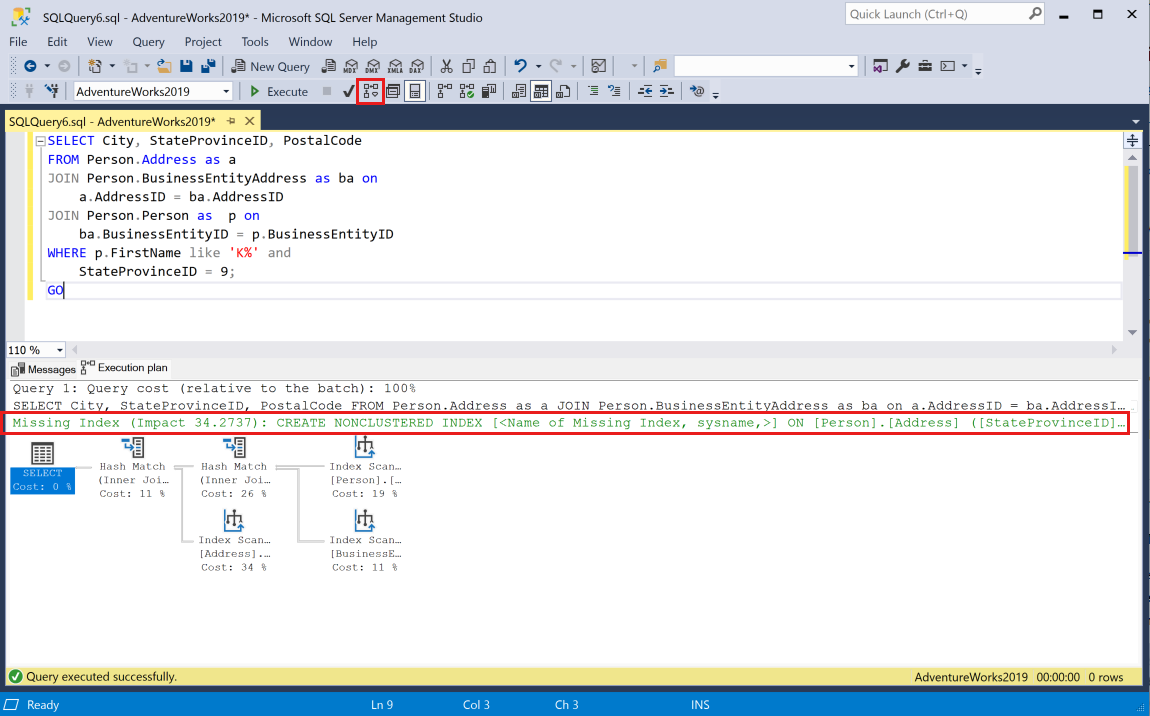
단일 실행 계획에는 누락된 인덱스 요청이 여러 개 포함될 수 있지만, 그래픽 실행 계획에는 누락된 인덱스 요청을 하나만 표시할 수 있습니다. 실행 계획에 누락된 인덱스 전체 목록을 보는 한 가지 옵션은 실행 계획 XML을 보는 것입니다.
실행 계획을 마우스 오른쪽 단추로 클릭하고 메뉴에서 실행 계획 XML 표시...를 선택합니다.
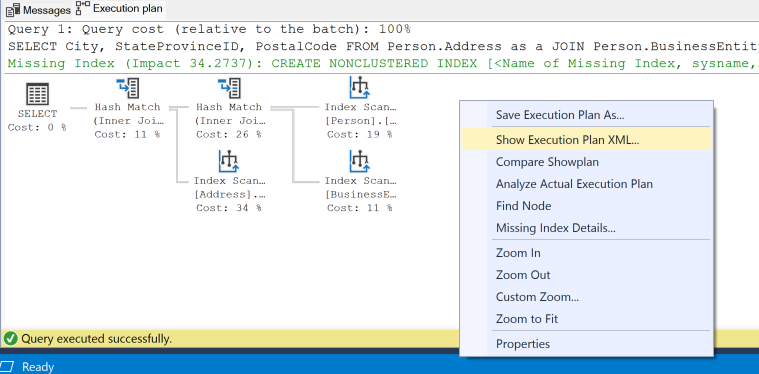
실행 계획 XML은 SSMS 내에서 새 탭으로 열립니다.
참고 항목
실행 계획 XML에 여러 제안이 있는 경우에도 하나의 누락된 인덱스 제안만 누락된 인덱스 세부 정보... 메뉴 옵션에 표시됩니다. 표시되는 누락된 인덱스 제안은 쿼리의 예상 개선 사항이 가장 높은 인덱스 제안이 아닐 수 있습니다.
CTRL+f 바로 가기를 사용하여 찾기 대화 상자를 표시합니다.
MissingIndex를 검색합니다.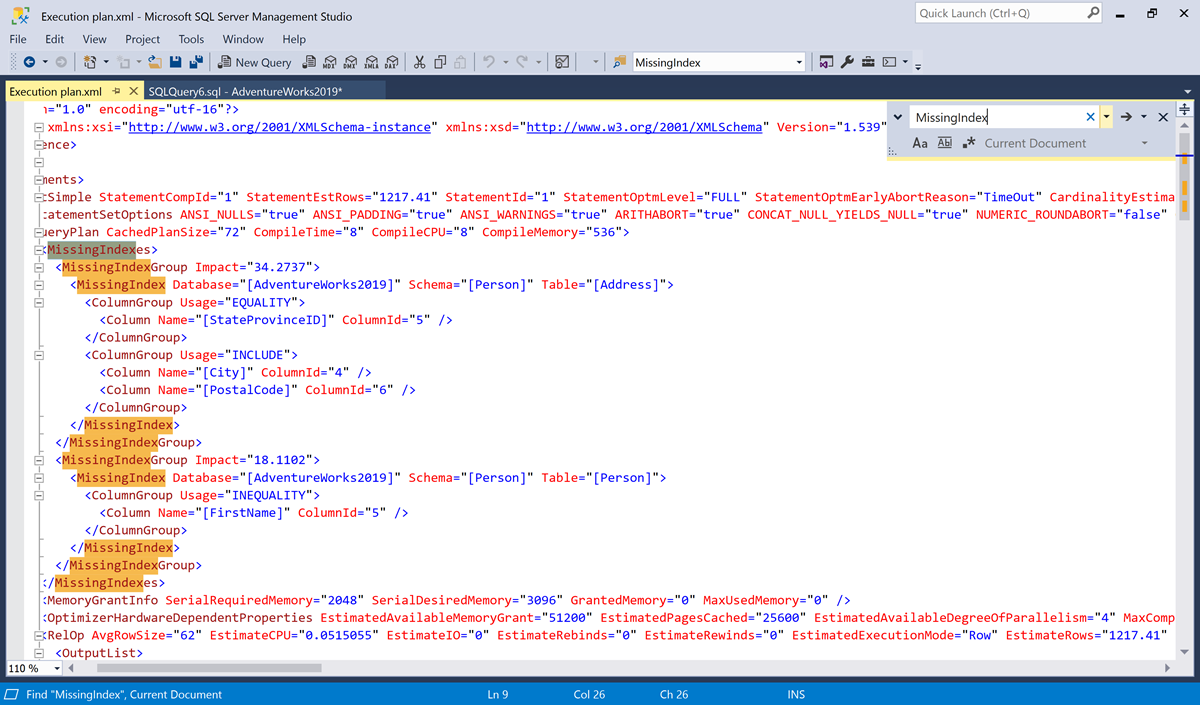
이 예제에는 두
MissingIndex요소가 있습니다.- 첫 번째 누락된 인덱스 제안에서는 쿼리가
City및PostalCode열을 더 포함하는StateProvinceID열에서 같음 검색을 지원하는Person.Address테이블의 인덱스를 사용할 수 있습니다. 최적화 시 쿼리 최적화 프로그램은 이 인덱스가 쿼리의 예상 비용을 34.2737% 줄일 수 있다고 판단했습니다. - 두 번째 누락된 인덱스 제안에서는 쿼리가 FirstName 열에서 같지 않음 검색을 지원하는
Person.Person테이블의 인덱스를 사용할 수 있습니다. 최적화 시 쿼리 최적화 프로그램은 이 인덱스가 쿼리의 예상 비용을 18.1102% 줄일 수 있다고 판단했습니다.
- 첫 번째 누락된 인덱스 제안에서는 쿼리가


데이터베이스의 각 디스크 기반 비클러스터형 인덱스는 공간을 차지하고 삽입, 업데이트 및 삭제에 대한 오버헤드를 추가하며 유지 관리가 필요할 수 있습니다. 이러한 이유로 쿼리 실행 계획에 따라 인덱스를 추가하기 전에 테이블 및 테이블의 기존 인덱스에서 누락된 인덱스 요청을 모두 검토하는 것이 좋습니다.
DMV에서 누락된 인덱스 제안 보기
다음 표에 나와 있는 동적 관리 개체를 쿼리하여 누락된 인덱스에 대한 정보를 검색할 수 있습니다.
| 동적 관리 뷰(Dynamic management view) | 반환된 정보 |
|---|---|
| sys.dm_db_missing_index_group_stats (Transact-SQL) | 누락된 인덱스 그룹의 특정 그룹을 구현하여 얻을 수 있는 성능 향상과 같은 누락된 인덱스 그룹에 대한 요약 정보를 반환합니다. |
| sys.dm_db_missing_index_groups(Transact-SQL) | 그룹 식별자 및 해당 그룹에 포함된 모든 누락된 인덱스의 식별자와 같은 누락된 인덱스의 특정 그룹에 대한 정보를 반환합니다. |
| sys.dm_db_missing_index_details(Transact-SQL) | 누락된 인덱스에 대한 자세한 정보를 반환합니다. 예를 들어 인덱스가 누락된 테이블의 이름과 식별자와 누락된 인덱스를 구성해야 하는 열 및 열 형식을 반환합니다. |
| sys.dm_db_missing_index_columns(Transact-SQL) | 인덱스가 누락된 데이터베이스 테이블 열에 대한 정보를 반환합니다. |
다음 쿼리는 누락된 인덱스 DMV를 사용하여 CREATE INDEX 문을 생성합니다. 여기에 있는 인덱스 생성 문은 테이블의 기존 인덱스와 함께 테이블에 대한 모든 요청을 검사한 후 고유한 DDL을 만드는 데 도움이 됩니다.
SELECT TOP 20
CONVERT (varchar(30), getdate(), 126) AS runtime,
CONVERT (decimal (28, 1),
migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)
) AS estimated_improvement,
'CREATE INDEX missing_index_' +
CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' +
mid.statement + ' (' + ISNULL (mid.equality_columns, '') +
CASE
WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL THEN ','
ELSE ''
END + ISNULL (mid.inequality_columns, '') + ')' +
ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
FROM sys.dm_db_missing_index_groups mig
JOIN sys.dm_db_missing_index_group_stats migs ON
migs.group_handle = mig.index_group_handle
JOIN sys.dm_db_missing_index_details mid ON
mig.index_handle = mid.index_handle
ORDER BY estimated_improvement DESC;
GO
이 쿼리는 이름이 estimated_improvement인 열로 제안을 정렬합니다. 예상 개선 사항은 다음의 조합을 기반으로 합니다.
- 누락된 인덱스 요청과 관련된 쿼리의 예상 쿼리 비용입니다.
- 인덱스 추가로 인해 예상되는 영향입니다. 이는 비클러스터형 인덱스가 쿼리 비용을 얼마나 줄일 수 있는지에 대한 추정치입니다.
- 누락된 인덱스 요청 관련 쿼리에 대해 실행된 쿼리 연산자(검색 및 검사) 실행 합계입니다. 쿼리 저장소를 사용하여 누락된 인덱스 유지에서 설명하는 것처럼 이 정보는 주기적으로 지워집니다.
참고 항목
Microsoft Tiger 도구 상자의 인덱스 생성 스크립트는 누락된 인덱스 DMV를 검사하여 중복으로 제안된 인덱스를 자동으로 제거하고, 영향이 적은 인덱스를 구문 분석하고, 검토를 위해 인덱스 생성 스크립트를 생성합니다. 위의 쿼리에서와 같이 인덱스 생성 명령을 실행하지 않습니다. 인덱스 생성 스크립트는 SQL Server 및 Azure SQL Managed Instance에 적합합니다. Azure SQL Database의 경우 자동 인덱스 튜닝을 구현하는 것이 좋습니다.
누락된 인덱스 기능의 제한 사항과 인덱스를 만들기 전에 누락된 인덱스 제안을 적용하는 방법을 검토하고 데이터베이스의 명명 규칙과 일치하도록 인덱스 이름을 수정합니다.
쿼리 저장소를 사용하여 누락된 인덱스 유지
DMV에서 누락된 인덱스 제안은 인스턴스 다시 시작, 장애 조치(failover) 및 데이터베이스 오프라인 설정과 같은 이벤트에 의해 지워집니다. 또한, 테이블의 메타데이터가 변경되면 해당 테이블에 대한 모든 누락된 인덱스 정보가 이러한 동적 관리 개체에서 삭제됩니다. 테이블 메타데이터 변경은 예를 들어 테이블에서 열을 추가하거나 삭제하거나 테이블 열에 인덱스를 만들 때 발생할 수 있습니다. 테이블 인덱스에 대해 ALTER INDEX REBUILD 작업을 수행하여 해당 테이블의 누락된 인덱스 요청도 지웁니다.
마찬가지로, 계획 캐시에 저장된 실행 계획도 인스턴스 다시 시작, 장애 조치(failover) 및 데이터베이스 오프라인 설정과 같은 이벤트에 의해 지워집니다. 메모리 압력 및 다시 컴파일로 인해 실행 계획이 캐시에서 제거될 수 있습니다.
쿼리 저장소를 사용하도록 설정하여 이러한 이벤트에서 실행 계획에서 누락된 인덱스 제안을 유지할 수 있습니다.
다음 쿼리는 쿼리에 대한 총 논리적 읽기 수의 대략적인 추정치를 기반으로 쿼리 저장소에서 누락된 인덱스 요청이 포함된 상위 20개의 쿼리 계획을 검색합니다. 데이터는 지난 48시간 이내에 쿼리 실행으로 제한됩니다.
SELECT TOP 20
qsq.query_id,
SUM(qrs.count_executions) * AVG(qrs.avg_logical_io_reads) as est_logical_reads,
SUM(qrs.count_executions) AS sum_executions,
AVG(qrs.avg_logical_io_reads) AS avg_avg_logical_io_reads,
SUM(qsq.count_compiles) AS sum_compiles,
(SELECT TOP 1 qsqt.query_sql_text FROM sys.query_store_query_text qsqt
WHERE qsqt.query_text_id = MAX(qsq.query_text_id)) AS query_text,
TRY_CONVERT(XML, (SELECT TOP 1 qsp2.query_plan from sys.query_store_plan qsp2
WHERE qsp2.query_id=qsq.query_id
ORDER BY qsp2.plan_id DESC)) AS query_plan
FROM sys.query_store_query qsq
JOIN sys.query_store_plan qsp on qsq.query_id=qsp.query_id
CROSS APPLY (SELECT TRY_CONVERT(XML, qsp.query_plan) AS query_plan_xml) AS qpx
JOIN sys.query_store_runtime_stats qrs on
qsp.plan_id = qrs.plan_id
JOIN sys.query_store_runtime_stats_interval qsrsi on
qrs.runtime_stats_interval_id=qsrsi.runtime_stats_interval_id
WHERE
qsp.query_plan like N'%<MissingIndexes>%'
and qsrsi.start_time >= DATEADD(HH, -48, SYSDATETIME())
GROUP BY qsq.query_id, qsq.query_hash
ORDER BY est_logical_reads DESC;
GO
누락된 인덱스 제안 적용
누락된 인덱스 제안을 효과적으로 사용하려면 비클러스터형 인덱스 디자인 지침을 따릅니다. 누락된 인덱스 제안으로 비클러스터형 인덱스를 조정하는 경우 기본 테이블 구조를 검토하고, 인덱스를 신중하게 결합하고, 키 열 순서를 고려하고, 포괄 열 제안을 검토합니다.
기본 테이블 구조 검토
누락된 인덱스 제안을 기반으로 테이블에 비클러스터형 인덱스를 만들기 전에 테이블의 클러스터형 인덱스를 검토합니다.
클러스터형 인덱스 확인 방법 중 하나는 sp_helpindex 시스템 저장 프로시저를 사용하는 것입니다. 예를 들어 다음 문을 실행하여 Person.Address테이블의 인덱스 요약을 볼 수 있습니다.
exec sp_helpindex 'Person.Address';
GO
index_description 열을 검토합니다. 각 테이블마다 클러스터형 인덱스를 하나만 포함할 수 있습니다. 테이블에 클러스터형 인덱스가 구현된 경우 index_description에는 'clustered'라는 단어가 포함됩니다.

클러스터형 인덱스가 없으면 테이블은 힙입니다. 이 경우 특정 성능 문제를 해결하기 위해 테이블이 의도적으로 힙으로 만들어졌는지 검토합니다. 대부분의 테이블은 클러스터형 인덱스의 이점을 활용하며 실수로 테이블이 힙으로 구현되기도 합니다. 클러스터형 인덱스 디자인 지침에 따라 클러스터형 인덱스 구현을 고려합니다.
누락된 인덱스 및 기존 인덱스에서 중복 여부 검토
누락된 인덱스는 쿼리 전체의 동일한 테이블 및 열에 대해 유사한 비클러스터형 인덱스 변형을 제공할 수 있습니다. 누락된 인덱스는 테이블의 기존 인덱스와 유사할 수도 있습니다. 최적의 성능을 위해 누락된 인덱스와 기존 인덱스를 검사하여 중복 인덱스를 만들지 않는 것이 가장 좋습니다.
테이블의 기존 인덱스 스크립팅
테이블의 기존 인덱스 정의를 검사하는 한 가지 방법은 개체 탐색기 세부 정보를 사용하여 인덱스를 스크립팅하는 것입니다.
- 개체 탐색기를 인스턴스 또는 데이터베이스에 연결합니다.
- 개체 탐색기에서 해당 데이터베이스의 노드를 확장합니다.
- 테이블 폴더를 확장합니다.
- 인덱스를 스크립아웃 하려는 테이블을 확장합니다.
- 인덱스 폴더를 선택합니다.
- 개체 탐색기 세부 정보 창이 아직 열려 있지 않으면 보기 메뉴에서 개체 탐색기 세부 정보를 선택하거나 F7 키를 누릅니다.
- Ctrl+a 바로 가기를 사용하여 개체 탐색기 세부 정보 창에 나와 있는 모든 인덱스를 선택합니다.
- 선택한 영역의 아무 곳이나 마우스 오른쪽 단추로 클릭하고 메뉴 옵션인 스크립트 인덱스, CREATE 및 새 쿼리 편집기 창을 차례로 선택합니다.

인덱스를 검토하고 가능한 경우 결합
테이블의 누락된 인덱스 권장 사항과 테이블의 기존 인덱스 정의를 함께 검토합니다. 인덱스를 정의할 때는 일반적으로 같음 열이 같지 않음 열 앞에 배치되어야 하며 함께 인덱스의 키를 형성해야 합니다. 같음 열에 대한 유효 순서를 확인하려면 선택성에 따라 순서를 지정합니다. 가장 선택적인 열을 먼저 나열합니다(열 목록에서 맨 왼쪽). 고유 열은 가장 선택적이지만 반복 값이 많은 열은 덜 선택적입니다.
또한 INCLUDE 절을 사용하여 CREATE INDEX 문에 포괄 열을 추가해야 합니다. 포괄 열의 순서는 쿼리 성능에 영향을 주지 않습니다. 따라서 인덱스를 결합할 때 포괄 열은 순서에 대한 걱정 없이 결합할 수 있습니다. 포괄 열 지침에 대해 자세히 알아보세요.
예를 들어 Person.Address 키 열에 기존 인덱스가 있는 StateProvinceID 테이블이 있을 수도 있습니다. 다음 열에서 Person.Address 테이블의 누락된 인덱스 권장 사항이 보일 수도 있습니다.
StateProvinceID및City에 대한 같음 필터StateProvinceID및City에 대한 같음 필터(PostalCode포함)
두 번째 권장 사항과 일치하도록 기존 인덱스를 수정하면 StateProvinceID 및 City(PostalCode 포함)에 대한 키가 포함된 인덱스가 두 인덱스 제안을 모두 생성한 쿼리를 충족할 수 있습니다.
절충은 인덱스 튜닝에서 일반적입니다. 많은 데이터 세트의 경우 City 열이 StateProvinceID 열보다 더 선택적일 수 있습니다. 그러나 StateProvinceID에서 기존 인덱스가 많이 사용되고 다른 요청이 StateProvinceID 및 City 모두에서 주로 검색되는 경우 일반적으로 데이터베이스가 키에 두 열을 모두 포함하는 단일 인덱스를 갖는 것이 오버헤드가 낮으며, 가장 선택적인 열은 아니지만 StateProvinceID보다는 선택적인 열입니다.
인덱스는 다음과 같은 여러 가지 방법으로 수정할 수 있습니다.
- CREATE INDEX 문은 DROP_EXISTING 절과 함께 사용할 수 있습니다. 명명 규칙에 따라 이름이 인덱스 정의를 정확하게 설명하도록 수정한 후 인덱스의 이름을 바꿀 수 있습니다.
- DROP INDEX(Transact-SQL) 문 뒤에 CREATE INDEX 문을 사용할 수 있습니다.
인덱스 키의 순서는 인덱스 제안을 결합할 때 중요합니다. City 선행 열은 StateProvinceID 선행 열과 다릅니다. 비클러스터형 인덱스 디자인 지침에 대해 자세히 알아보세요.
인덱스를 만들 때 온라인 인덱스 작업을 사용할 수 있는 경우 사용하는 것이 좋습니다.
인덱스는 경우에 따라 쿼리 성능을 크게 향상할 수 있지만 인덱스에는 오버헤드 및 관리 비용도 있습니다. 일반 인덱스 디자인 지침을 검토하여 인덱스를 만들기 전에 인덱스의 이점을 평가할 수 있습니다.
인덱스 변경이 성공했는지 확인
인덱스 변경이 성공했는지 확인하는 것이 중요합니다. 쿼리 최적화 프로그램이 인덱스를 사용하고 있나요?
인덱스 변경 내용의 유효성을 검사하는 한 가지 방법은 쿼리 저장소를 사용하여 누락된 인덱스 요청이 있는 쿼리를 식별하는 것입니다. 쿼리의 query_id를 확인합니다. 쿼리 저장소의 추적된 쿼리 보기를 사용하여 쿼리 실행 계획이 변경되었는지, 최적화 프로그램에서 새 인덱스 또는 수정된 인덱스를 사용하고 있는지 확인합니다. 쿼리 성능 문제 해결을 시작으로 추적된 쿼리에 대해 자세히 알아보세요.
관련 콘텐츠
다음 문서에서 인덱스 및 성능 튜닝에 대해 자세히 알아보세요.
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기