연습 - SELECT로 외부 테이블 만들기
이 연습에서는 CREATE EXTERNAL TABLE AS SELECT(CETAS)를 사용하여 다음을 수행합니다.
- 테이블을 Parquet 형식으로 내보냅니다.
- 데이터베이스의 콜드 데이터를 스토리지로 이동합니다.
- 내보낸 외부 데이터에 액세스할 외부 테이블을 만듭니다.
- 뷰 또는 와일드카드 검색을 쿼리 전략으로 사용합니다.
- 폴더 제거 및 메타데이터 정보를 사용하여 쿼리를 제한하여 성능을 향상시킵니다.
사전 요구 사항
- 인터넷 연결이 있는 SQL Server 2025 인스턴스와 이전 연습과 같이 외부 데이터용 PolyBase 쿼리 서비스가 설치되고 사용하도록 설정되었습니다.
- 샘플 데이터에 사용하기 위해 서버에 복원된 AdventureWorks2022 샘플 데이터베이스입니다.
- Azure Storage 계정이 있으며, 이 계정에는
data라는 Blob Storage 컨테이너가 생성되었습니다. 스토리지를 만들려면 빠른 시작: Azure Portal을 사용하여 Blob 업로드, 다운로드 및 나열을 참조하세요. - Azure에서 Azure 역할 기반 액세스 제어(RBAC) Storage Blob Data Contributor 역할이 할당되어 있습니다. 자세한 내용은 Blob 데이터에 액세스하기 위한 Azure 역할 할당을 참조하세요.
- CETAS에 사용할 READ, WRITE, LIST 및 CREATE 권한이 있는 Blob 컨테이너 SAS 토큰입니다. SAS 토큰을 만들려면 스토리지 컨테이너에 대한 SAS(공유 액세스 서명) 토큰 만들기를 참조하세요.
CETAS를 사용하여 테이블을 Parquet으로 내보내기
SQL Server 테이블에서 Azure Blob Storage 컨테이너로 2012년 이전 데이터를 내보내려는 비즈니스 분석 팀과 함께 일한다고 상상해 보십시오. SQL Server를 직접 쿼리하는 대신 내보낸 이 데이터에 대해 보고서 쿼리를 실행하려고 합니다.
SQL Server 인스턴스에서 CETAS를 사용하도록 설정합니다.
EXEC SP_CONFIGURE @CONFIGNAME = 'ALLOW POLYBASE EXPORT', @CONFIGVALUE = 1;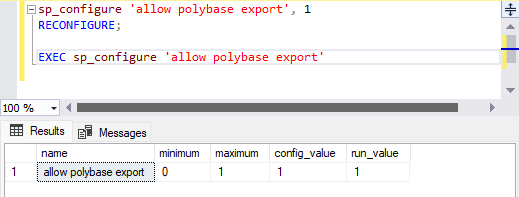
다음 데이터 탐색 쿼리를 실행하여 내보낼 데이터를 이해합니다. 이 경우 2012년 이전의 데이터를 찾고 있습니다. 2011 및 2012의 모든 데이터를 내보내려고 합니다.
-- RECORDS BY YEARS SELECT COUNT(*) AS QTY, DATEPART(YYYY, [DUEDATE]) AS [YEAR] FROM [PURCHASING].[PURCHASEORDERDETAIL] GROUP BY DATEPART(YYYY, [DUEDATE]) ORDER BY [YEAR]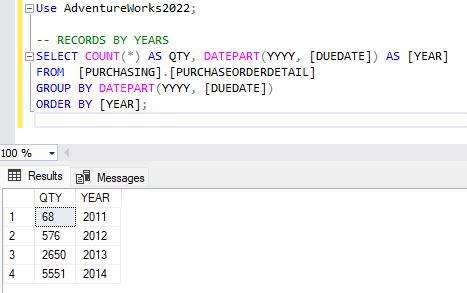
이전 연습과 같이 데이터베이스에 대한 데이터베이스 마스터 키를 만듭니다.
Use AdventureWorks2022 DECLARE @randomWord VARCHAR(64) = NEWID(); DECLARE @createMasterKey NVARCHAR(500) = N' IF NOT EXISTS (SELECT * FROM sys.symmetric_keys WHERE name = ''##MS_DatabaseMasterKey##'') CREATE MASTER KEY ENCRYPTION BY PASSWORD = ' + QUOTENAME(@randomWord, '''') EXEC sp_executesql @createMasterKey; SELECT * FROM sys.symmetric_keys;데이터베이스 범위 자격 증명 및 외부 데이터 원본을 만듭니다. Azure에서 만든 스토리지 계정 및 SAS 토큰으로
<sas_token>및<storageccount>자리 표시자를 바꿉니다.-- DATABASE SCOPED CREDENTIAL CREATE DATABASE SCOPED CREDENTIAL blob_storage WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<sas_token>'; -- AZURE BLOB STORAGE DATA SOURCE CREATE EXTERNAL DATA SOURCE ABS_Data WITH ( LOCATION = 'abs://<storageaccount>.blob.core.windows.net/data/chapter3' ,CREDENTIAL = blob_storage );Parquet에 대한 외부 파일 형식을 만듭니다.
-- PARQUET FILE FORMAT CREATE EXTERNAL FILE FORMAT ffParquet WITH (FORMAT_TYPE = PARQUET);CETAS를 사용하여 외부 테이블을 만듭니다. 다음 쿼리는 명명된
ext_data_2011_2012외부 테이블을 만들고 2011 및 2012의 모든 데이터를 데이터 원본ABS_Data에서 지정한 위치로 내보냅니다.CREATE EXTERNAL TABLE ex_data_2011_2012 WITH( LOCATION = 'data_2011_20122', DATA_SOURCE = ABS_Data, FILE_FORMAT = ffParquet )AS SELECT [PurchaseOrderID] ,[PurchaseOrderDetailID] ,[DueDate] ,[OrderQty] ,[ProductID] ,[UnitPrice] ,[LineTotal] ,[ReceivedQty] ,[RejectedQty] ,[StockedQty] ,[ModifiedDate] FROM [PURCHASING].[PURCHASEORDERDETAIL] WHERE YEAR([DUEDATE]) < 2013 GOAzure Portal에서 Azure Blob Storage를 확인합니다. 다음과 같은 구조가 생성됩니다. SQL Server 2025는 내보내는 데이터의 양과 파일 형식에 따라 파일 이름을 자동으로 만듭니다.
이제 일반 테이블처럼 외부 테이블에 액세스할 수 있습니다.
SELECT * FROM ex_data_2011_2012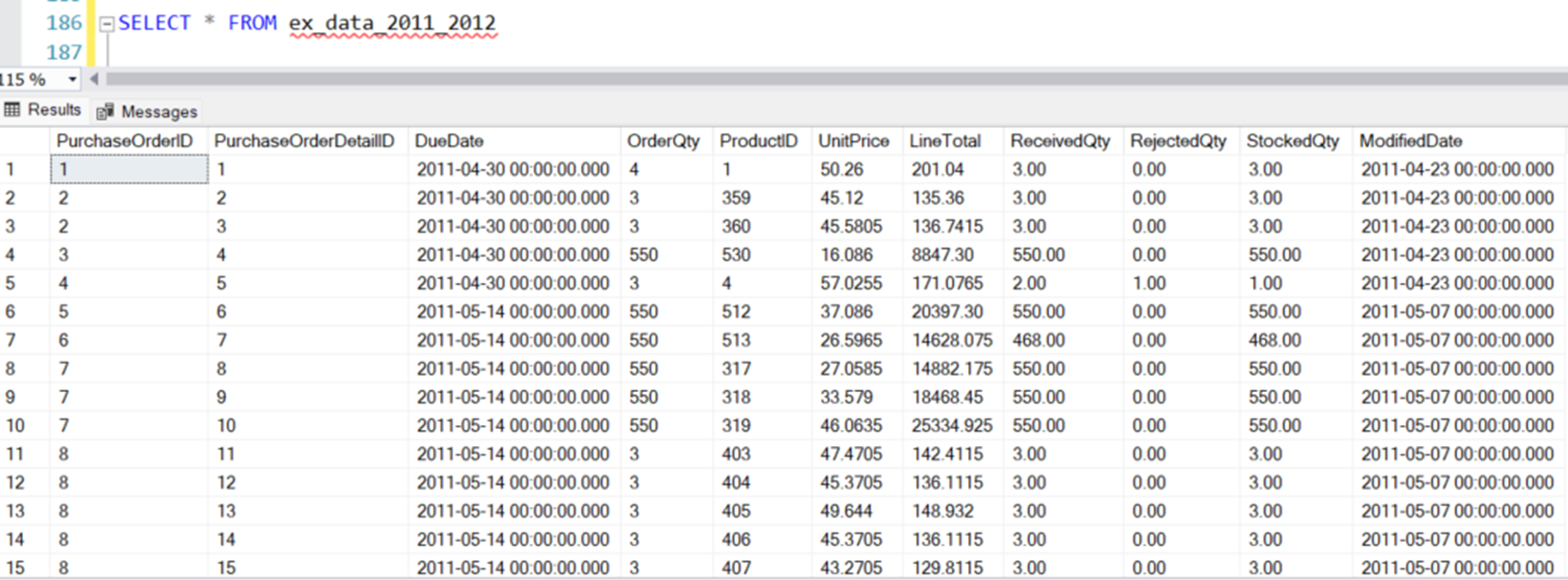
이제 데이터가 Parquet로 내보내지고 외부 테이블을 통해 쉽게 액세스할 수 있습니다. 비즈니스 분석 팀은 외부 테이블을 조회하거나, 보고 도구를 Parquet 파일에 직접 연결해 사용할 수 있습니다.
CETAS를 사용하여 데이터베이스에서 콜드 데이터 이동
데이터를 관리하기 위해 회사는 SQL Server 데이터베이스에서 2014년보다 오래된 데이터를 이동하기로 결정합니다. 그러나 모든 데이터에 계속 액세스할 수 있어야 합니다.
이 예제에서는 CETAS를 통해 데이터를 내보내고 나중에 쿼리할 수 있는 여러 외부 테이블을 생성합니다. UNION 문이 있는 뷰를 사용하여 데이터를 쿼리하거나 단일 외부 테이블을 만들고 와일드카드를 사용하여 내보낸 데이터의 하위 폴더를 검색할 수 있습니다.
먼저 데이터 내보내기 및 제거를 시뮬레이션하려고 하지만 현재 데이터 원본을 반드시 삭제하지는 않으려 하므로 원래 테이블을 복제합니다. 다음 문을 실행합니다.
-- CLONE TABLE
SELECT * INTO [PURCHASING].[PURCHASEORDERDETAIL_2] FROM [PURCHASING].[PURCHASEORDERDETAIL]
첫 번째 데이터 탐색 쿼리에서 2014년부터 5551개의 레코드가 있다는 것을 알 수 있습니다. 2014년 이전의 모든 항목을 연도별로 식별된 폴더로 내보내야 합니다. 2011년 데이터는 라는 2011폴더로 이동합니다.
외부 테이블을 만들려면 다음 명령을 실행합니다.
CREATE EXTERNAL TABLE ex_2011 WITH( LOCATION = '2011', DATA_SOURCE = ABS_Data, FILE_FORMAT = ffParquet )AS SELECT [PurchaseOrderID] ,[PurchaseOrderDetailID] ,[DueDate] ,[OrderQty] ,[ProductID] ,[UnitPrice] ,[LineTotal] ,[ReceivedQty] ,[RejectedQty] ,[StockedQty] ,[ModifiedDate] FROM [PURCHASING].[PURCHASEORDERDETAIL_2] WHERE YEAR([DUEDATE]) = 2011;CREATE EXTERNAL TABLE ex_2012 WITH( LOCATION = '2012', DATA_SOURCE = ABS_Data, FILE_FORMAT = ffParquet )AS SELECT [PurchaseOrderID] ,[PurchaseOrderDetailID] ,[DueDate] ,[OrderQty] ,[ProductID] ,[UnitPrice] ,[LineTotal] ,[ReceivedQty] ,[RejectedQty] ,[StockedQty] ,[ModifiedDate] FROM [PURCHASING].[PURCHASEORDERDETAIL_2] WHERE YEAR([DUEDATE]) = 2012;CREATE EXTERNAL TABLE ex_2013 WITH( LOCATION = '2013', DATA_SOURCE = ABS_Data, FILE_FORMAT = ffParquet )AS SELECT [PurchaseOrderID] ,[PurchaseOrderDetailID] ,[DueDate] ,[OrderQty] ,[ProductID] ,[UnitPrice] ,[LineTotal] ,[ReceivedQty] ,[RejectedQty] ,[StockedQty] ,[ModifiedDate] FROM [PURCHASING].[PURCHASEORDERDETAIL_2] WHERE YEAR([DUEDATE]) = 2013;이러한 명령을 실행한 후 SSMS 개체 탐색기를 새로 고칩니다. 그런 다음 Databases>AdventureWorks2022>테이블>외부 테이블을 열어 외부 테이블을 확인합니다.
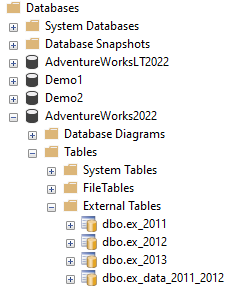
Azure Storage 컨테이너에 다음 폴더가 표시되는지 확인합니다.
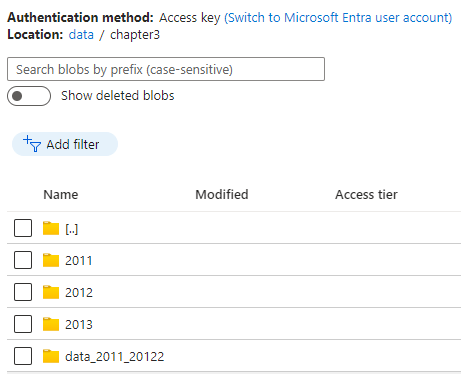
콜드 데이터를 내보낸 후 원래 테이블 위치에서 삭제할 수 있습니다.
DELETE FROM [PURCHASING].[PURCHASEORDERDETAIL_2] WHERE YEAR([DUEDATE]) < 2014
외부 테이블을 포함하는 쿼리 데이터
뷰 또는 와일드카드 검색을 사용하여 내보낸 외부 데이터를 쿼리할 수 있습니다. 각 메서드에는 장점과 단점이 있습니다. 뷰 메서드는 일반적으로 더 잘 수행되며 실제 테이블과 결합될 수도 있으므로 반복 요청에 권장됩니다. 와일드카드 검색 방법은 탐색 목적으로 더 유연하고 사용하기 쉽습니다.
뷰를 사용하여 데이터 쿼리
이제 데이터베이스에서 이전 데이터를 내보내고 삭제했으므로 T-SQL을 사용하여 데이터베이스의 모든 외부 테이블과 현재 데이터를 쿼리하는 뷰를 만들 수 있습니다.
CREATE VIEW vw_purchaseorderdetail
AS
SELECT * FROM ex_2011
UNION ALL
SELECT * FROM ex_2012
UNION ALL
SELECT * FROM ex_2013
UNION ALL
SELECT * FROM [PURCHASING].[PURCHASEORDERDETAIL_2]
이번에는 새로 만든 보기를 사용하여 원래 데이터 탐색 쿼리를 실행하여 동일한 결과를 볼 수 있습니다.
SELECT COUNT(*) AS QTY, DATEPART(YYYY, [DUEDATE]) AS [YEAR]
FROM vw_purchaseorderdetail
GROUP BY DATEPART(YYYY, [DUEDATE])
ORDER BY [YEAR]
와일드카드 검색을 사용하여 데이터 쿼리
앞의 예제에서는 UNION 문을 포함한 뷰를 활용하여 세 개의 외부 테이블을 결합했습니다. 원하는 결과를 얻을 수 있는 또 다른 방법은 와일드카드 검색을 사용하여 하위 폴더를 비롯한 폴더 구조에서 특정 형식의 데이터를 검색하는 것입니다.
다음 T-SQL 예제에서는 OPENROWSET을 사용하여 하위 폴더를 포함한 데이터 원본에서 ABS_Data Parquet 파일을 검색합니다.
SELECT COUNT(*) AS QTY, DATEPART(YYYY, [DUEDATE]) AS [YEAR]
FROM OPENROWSET
(BULK '**'
, FORMAT = 'PARQUET'
, DATA_SOURCE = 'ABS_Data')
AS [cc]
GROUP BY DATEPART(YYYY, [DUEDATE])
ORDER BY [YEAR]
폴더 제거 및 메타데이터 정보
외부 테이블과 OPENROWSET 모두 이 함수를 filepath 사용하여 파일 메타데이터를 기반으로 정보를 수집하고 필터링할 수 있습니다. 함수는 filepath 전체 경로, 폴더 이름 및 파일 이름을 반환합니다. 이 정보를 사용하여 외부 테이블과 OPENROWSET 명령 모두의 검색 기능을 향상시킬 수 있습니다.
SELECT
r.filepath(1) 'folder_name'
,r.filepath() 'full_path'
,r.filepath(2) 'file_name'
FROM OPENROWSET(
BULK '*/*.parquet',
DATA_SOURCE = 'ABS_Data',
FORMAT = 'parquet'
) as [r]
GROUP BY
r.filepath(2),r.filepath(1), r.filepath()
ORDER BY
r.filepath(2)
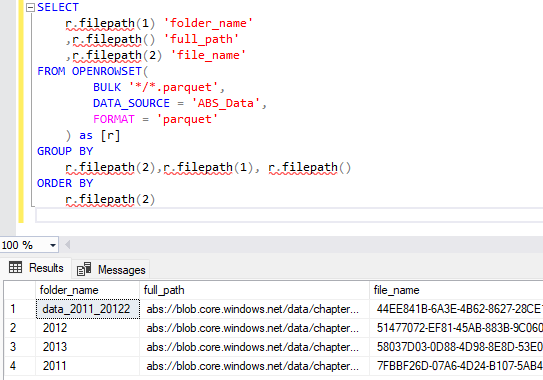
특정 폴더에서 데이터를 검색하고 와일드카드 검색 방법의 기능을 계속 사용하려는 경우 다음 쿼리를 사용할 수 있습니다.
SELECT *
FROM OPENROWSET(
BULK '*/*.parquet',
DATA_SOURCE = 'ABS_Data',
FORMAT = 'parquet'
) AS r
WHERE
r.filepath(1) IN ('2011')
최종 결과는 동일하지만 폴더 제거 메타데이터를 사용하여 쿼리는 전체 데이터 원본을 검색하는 대신 필요한 폴더에만 액세스하여 더 나은 쿼리 성능을 생성합니다. PolyBase 기능을 더 잘 사용하도록 스토리지 아키텍처를 디자인할 때 이 정보를 염두에 두어야 합니다.
예를 들어 다음과 같은 폴더 아키텍처가 제공됩니다.
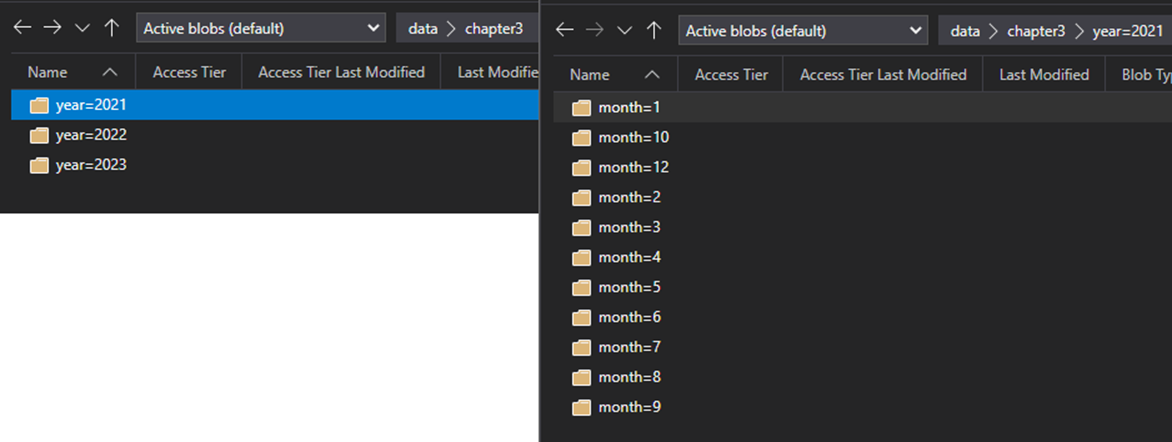
다음 쿼리를 사용할 수 있습니다.
SELECT *
FROM OPENROWSET(
BULK 'year=*/month=*/*.parquet',
DATA_SOURCE = 'ABS_Data',
FORMAT = 'parquet'
) AS r
WHERE
r.filepath(1) IN ('<year>')
r.filepath(2) IN ('<month>')
이 쿼리는 데이터 원본의 크기가 얼마나 커지는지는 중요하지 않습니다. SQL Server는 선택한 폴더의 데이터만 로드, 읽기 및 쿼리하여 다른 모든 폴더를 건너뜁니다.
데이터베이스에 데이터가 저장되지 않으므로 데이터베이스 관리자는 이 데이터를 관리하기 위한 특정 전략을 설계할 필요가 없습니다. 회사는 백업, 가용성 및 사용 권한을 포함하지만 제한되지 않는 데이터를 안전하게 유지하기 위해 필요한 모든 예방 조치를 취해야 합니다.
요약
이 연습에서는 CETAS를 사용하여 데이터베이스에서 Azure Storage로 콜드 데이터를 이동하고 테이블을 Parquet 파일 형식으로 내보냅니다. 외부 데이터를 쿼리하여 탐색하고 성능을 최적화하는 방법을 배웠습니다.
CETAS를 사용하여 OPENROWSET, 외부 테이블, 뷰, 와일드카드 검색 및 파일 경로 함수를 결합할 수 있습니다. SQL Server, Oracle, Teradata 및 MongoDB와 같은 다른 데이터베이스 또는 Azure Blob Storage, Azure Data Lake Storage 또는 S3 호환 개체 스토리지에서 데이터에 액세스하고 내보낼 수 있습니다. CETAS는 지원되는 모든 PolyBase 데이터 원본에서 성능, 내구성 및 확장성 있는 솔루션을 설계하는 데 도움이 될 수 있습니다.