원래 제품 버전: SQL Server
원래 KB 번호: 243589
소개
이 문서에서는 SQL Server를 사용할 때 데이터베이스 애플리케이션에서 발생할 수 있는 성능 문제(특정 쿼리 또는 쿼리 그룹의 성능 저하)를 처리하는 방법에 대해 설명합니다. 다음 방법론을 사용하면 느린 쿼리 문제의 원인을 좁히고 해결 방법을 안내할 수 있습니다.
느린 쿼리 찾기
SQL Server 인스턴스에 쿼리 성능 문제가 있는지 확인하려면 먼저 실행 시간(경과 시간)을 기준으로 쿼리를 검사합니다. 설정된 성능 기준에 따라 설정한 임계값(밀리초)을 초과하는 시간을 확인합니다. 예를 들어 스트레스 테스트 환경에서 워크로드의 임계값을 300ms 이하로 설정했을 수 있으며 이 임계값을 사용할 수 있습니다. 그런 다음 해당 임계값을 초과하는 모든 쿼리를 식별하여 각 개별 쿼리 및 미리 설정된 성능 기준 기간에 초점을 맞출 수 있습니다. 궁극적으로 비즈니스 사용자는 데이터베이스 쿼리의 전체 기간에 신경을 써야 합니다. 따라서 주된 초점은 실행 기간에 있습니다. CPU 시간 및 논리적 읽기와 같은 다른 메트릭은 조사 범위를 좁히는 데 도움이 되도록 수집됩니다.
현재 실행 중인 문에 대해서는 sys.dm_exec_requests에서 total_elapsed_time 및 cpu_time 열을 확인하십시오. 다음 쿼리를 실행하여 데이터를 가져옵니다.
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;과거 쿼리 실행에 대해서는 sys.dm_exec_query_stats의 last_elapsed_time 및 last_worker_time 열을 확인합니다. 다음 쿼리를 실행하여 데이터를 가져옵니다.
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESC참고
avg_wait_time가 음수 값을 표시하면, 병렬 쿼리입니다.SSMS(SQL Server Management Studio), sqlcmd 또는 VISUAL Studio Code용 MSSQL 확장에서 요청 시 쿼리를 실행할 수 있는 경우 SET STATISTICS TIME
ON및 SET STATISTICS IOON를 사용하여 실행합니다.SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFF그런 다음 메시지에서 다음과 같은 CPU 시간, 경과된 시간 및 논리적 읽기가 표시됩니다.
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.쿼리 계획을 수집할 수 있는 경우 실행 계획 속성에서 데이터를 확인합니다.
실제 실행 계획 포함으로 쿼리를 실행합니다.
실행 계획에서 가장 왼쪽에 있는 연산자를 선택합니다.
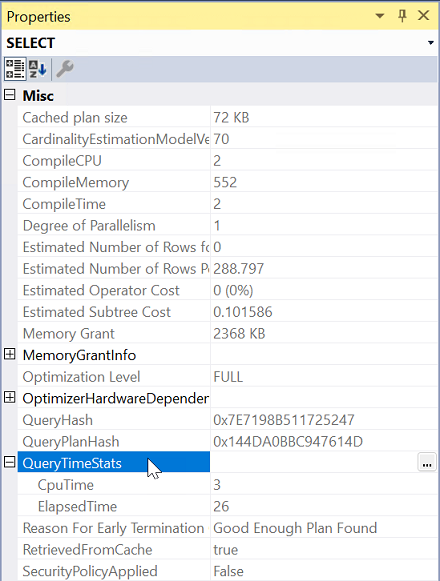
속성에서 QueryTimeStats 속성을 확장합니다.
ElapsedTime 및 CpuTime을 확인합니다.
실행 중과 대기 중: 쿼리 속도가 느린 이유는 무엇인가요?
미리 정의된 임계값을 초과하는 쿼리를 찾으면 왜 속도가 느려질 수 있는지 검사합니다. 성능 문제의 원인은 실행 중이거나 대기 중인 두 가지 범주로 그룹화할 수 있습니다.
대기 중: 쿼리는 오랜 시간 동안 병목 현상을 기다려야 하기 때문에 속도가 느려질 수 있습니다. 대기 유형에서 병목 현상의 자세한 목록을 참조하세요.
실행 중: 쿼리가 오랫동안 실행 중이므로 속도가 느려질 수 있습니다. 즉, 이러한 쿼리는 CPU 리소스를 적극적으로 사용합니다.
쿼리는 전체 수명(기간) 동안 일정 시간 실행되고 일정 시간 대기할 수 있습니다. 그러나 긴 경과 시간에 기여하는 주요 범주를 결정하는 데 초점을 맞춥니다. 따라서 첫 번째 작업은 쿼리가 속하는 범주를 설정하는 것입니다. 간단합니다. 쿼리가 실행되고 있지 않으면 대기 중입니다. 이상적으로 쿼리는 대부분의 경과된 시간을 실행 상태로 보내고 리소스를 기다리는 데 거의 시간을 소비하지 않습니다. 또한 최상의 시나리오에서는 쿼리가 미리 결정된 기준 내에서 또는 그 이하로 실행됩니다. 쿼리의 경과된 시간과 CPU 시간을 비교하여 문제 유형을 확인합니다.
유형 1: CPU 바운드(구동기)
CPU 시간이 경과된 시간과 같거나 더 높은 경우 CPU 바인딩된 쿼리로 처리할 수 있습니다. 예를 들어 경과된 시간이 3,000밀리초(밀리초)이고 CPU 시간이 2900ms이면 대부분의 경과된 시간이 CPU에 소요됩니다. 그런 다음 CPU 바인딩된 쿼리라고 말할 수 있습니다.
실행(CPU 바인딩된) 쿼리의 예:
| 경과된 시간(밀리초) | CPU 시간(밀리초) | 읽기(논리적) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1000 | 20 |
캐시에서 데이터/인덱스 페이지를 읽는 논리적 읽기는 SQL Server에서 CPU 사용률의 동인인 경우가 가장 많습니다. CPU 사용은 T-SQL, XProcs, SQL CRL 객체와 같은 코드의 while 루프와 같이 다른 출처로부터 발생할 수 있습니다. 표의 두 번째 예제에서는 대부분의 CPU가 읽기에서 사용되지 않는 이러한 시나리오를 보여 줍니다.
참고
CPU 시간이 기간보다 크면 병렬 쿼리가 실행됨을 나타냅니다. 여러 스레드가 동시에 CPU를 사용하고 있습니다. 자세한 내용은 병렬 쿼리 - 실행기 또는 웨이터를 참조하세요.
유형 2: 병목 상태 대기 중(웨이터)
경과된 시간이 CPU 시간보다 훨씬 큰 경우 쿼리가 병목 상태를 기다리고 있습니다. 경과된 시간에는 CPU에서 쿼리를 실행하는 시간(CPU 시간) 및 리소스가 해제될 때까지 기다리는 시간(대기 시간)이 포함됩니다. 예를 들어 경과된 시간이 2000ms이고 CPU 시간이 300ms인 경우 대기 시간은 1700ms(2000 - 300 = 1700)입니다. 자세한 내용은 대기 유형을 참조 하세요.
대기 중인 쿼리의 예:
| 경과된 시간(밀리초) | CPU 시간(밀리초) | 읽기(논리적) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10080 | 700 | 80000 |
병렬 쿼리 - 실행기 또는 웨이터
병렬 쿼리는 전체 기간보다 더 많은 CPU 시간을 사용할 수 있습니다. 병렬 처리의 목표는 여러 스레드가 쿼리의 일부를 동시에 실행할 수 있도록 하는 것입니다. 1초의 클록 시간에서 쿼리는 8개의 병렬 스레드를 실행하여 8초의 CPU 시간을 사용할 수 있습니다. 따라서 경과된 시간 및 CPU 시간 차이에 따라 CPU 바인딩 또는 대기 쿼리를 결정하는 것이 어려워집니다. 그러나 일반적으로 위의 두 섹션에 나열된 원칙을 따릅니다. 요약은 다음과 같습니다.
- 경과된 시간이 CPU 시간보다 훨씬 큰 경우 이를 웨이터로 간주합니다.
- CPU 시간이 경과된 시간보다 훨씬 큰 경우 실행 프로그램으로 간주하십시오.
병렬 쿼리의 예:
| 경과된 시간(밀리초) | CPU 시간(밀리초) | 읽기(논리적) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1500000 |
방법론의 개략적인 시각적 표현

대기 중인 쿼리 진단 및 해결
관심 있는 쿼리가 웨이터임을 확인한 경우 다음 단계는 병목 현상 문제를 해결하는 데 초점을 맞추는 것입니다. 그렇지 않으면 4단계: 실행 중인 쿼리 진단 및 해결로 이동합니다.
병목 상태를 기다리는 쿼리를 최적화하려면 대기 시간 및 병목 현상이 있는 위치(대기 유형)를 식별합니다. 대기 유형이 확인되면 대기 시간을 줄이거나 대기를 완전히 제거합니다.
대략적인 대기 시간을 계산하려면 쿼리의 경과된 시간에서 CPU 시간(작업자 시간)을 뺍니다. 일반적으로 CPU 시간은 실제 실행 시간이며 쿼리 수명 중 나머지 부분은 대기 중입니다.
대략적 대기 기간을 계산하는 방법의 예:
| 경과된 시간(밀리초) | CPU 시간(밀리초) | 대기 시간(밀리초) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
병목 상태 식별 또는 대기
기록된 장시간 대기 쿼리를 식별하려면(예, 전체 경과 시간의 20%가 대기 시간일 경우) 다음 쿼리를 실행합니다. 이 쿼리는 SQL Server가 시작된 이후 캐시된 쿼리 계획에 대한 성능 통계를 사용합니다.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESC대기 시간이 500ms보다 긴 현재 실행 중인 쿼리를 식별하려면 다음 쿼리를 실행합니다.
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1쿼리 계획을 수집할 수 있는 경우 SSMS의 실행 계획 속성에서 WaitStats를 확인합니다.
- "실제 실행 계획 포함 기능을 사용하여 쿼리를 실행합니다."
- 실행 계획 탭에서 가장 왼쪽에 있는 연산자를 마우스 오른쪽 단추로 클릭합니다.
- 속성을 선택한 다음 WaitStats 속성을 선택합니다.
- WaitTimeMs 및 WaitType을 확인합니다.
PSSDiag/SQLdiag 또는 SQL LogScout LightPerf/GeneralPerf 시나리오에 익숙한 경우 둘 중 하나를 사용하여 성능 통계를 수집하고 SQL Server 인스턴스에서 대기 중인 쿼리를 식별하는 것이 좋습니다. 수집된 데이터 파일을 가져오고 SQL Nexus를 사용하여 성능 데이터를 분석할 수 있습니다.
대기를 제거하거나 줄이는 데 도움이 되는 참조
각 대기 유형에 대한 원인과 해결 방법은 다양합니다. 모든 대기 유형을 확인하는 일반적인 방법은 없습니다. 일반적인 대기 유형 문제를 해결하고 해결하기 위한 문서는 다음과 같습니다.
- 차단 문제 이해 및 해결(LCK_M_*)
- Azure SQL 데이터베이스 차단 문제의 이해 및 해결
- I/O 문제로 인한 느린 SQL Server 성능 문제 해결(PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- SQL Server에서 마지막 페이지 삽입 시의 PAGELATCH_EX 경합 해결
- 메모리에서 설명 및 솔루션 부여(RESOURCE_SEMAPHORE)
- ASYNC_NETWORK_IO 대기 유형으로 인해 발생하는 느린 쿼리 문제 해결
- Always On 가용성 그룹을 사용하여 높은 HADR_SYNC_COMMIT 대기 유형 문제 해결
- 작동 방식: CMEMTHREAD 및 디버깅
- 병렬 처리 대기 시간 관리 가능하게 만들기 (CXPACKET 및 CXCONSUMER)
- THREADPOOL 대기
많은 대기 유형 및 해당 형식이 나타내는 내용에 대한 설명은 대기 유형에서 표를 참조하세요.
실행 중인 쿼리 진단 및 해결
CPU(작업자) 시간이 전체 경과 기간에 매우 가까운 경우 쿼리는 대부분의 수명을 실행합니다. 일반적으로 SQL Server 엔진이 높은 CPU 사용량을 구동하는 경우 높은 CPU 사용량은 많은 수의 논리적 읽기를 구동하는 쿼리에서 발생합니다(가장 일반적인 이유).
현재 높은 CPU 활동을 담당하는 쿼리를 식별하려면 다음 명령문을 실행합니다.
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
현재 쿼리가 CPU를 구동하지 않는 경우 다음 명령문을 실행하여 과거 CPU 바운드 쿼리를 찾을 수 있습니다.
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
장기 실행 CPU 바인딩 쿼리를 해결하는 일반적인 방법
- 쿼리 계획을 검사하다
- 통계 업데이트
- 누락된 인덱스를 식별하고 적용합니다. 누락된 인덱스를 식별하는 방법에 대한 자세한 단계는 누락된 인덱스 제안을 사용하여 비클러스터형 인덱스 조정을 참조 하세요.
- 쿼리 다시 디자인 또는 다시 쓰기
- 매개 변수가 중요한 계획 식별 및 해결
- SARG 기능 문제 식별 및 해결
- TOP, EXISTS, IN, FAST, SET ROWCOUNT, OPTION(FAST N)으로 인해 장기 실행 중첩 루프가 발생할 수 있는 행 목표 문제를 식별하고 해결합니다. 자세한 내용은 행 목표 문제 - 독립적인 행 목표 및 Showplan 향상 기능 - 행 목표를 제외한 추정 행 수를 참조하세요.
- 카디널리티 예측 문제를 평가하고 해결합니다. 자세한 내용은 SQL Server 2012 또는 이전 버전에서 2014 이상으로 업그레이드한 후의 쿼리 성능 저하를 참조 하세요.
- 완료되지 않은 것처럼 보이는 큐를 식별하고 해결합니다. SQL Server에서 종료되지 않는 것처럼 보이는 쿼리 문제 해결을 참조 하세요.
- 최적화 프로그램 시간 제한의 영향을 받는 느린 쿼리 식별 및 해결
- 높은 CPU 성능 문제를 식별합니다. 자세한 내용은 SQL Server에서 CPU 사용량이 많은 문제 해결을 참조 하세요.
- 두 서버 간에 현저한 성능 차이를 나타내는 쿼리 문제 해결
- 시스템의 컴퓨팅 리소스 증가(CPU)
- 좁고 넓은 계획을 사용하여 UPDATE 성능 문제 해결