이 문서에서는 데이터 중복 제거 의 작동 방식을 설명합니다.
데이터 중복 제거 작동 방식
Windows Server의 데이터 중복 제거는 다음 두 가지 원칙으로 만들어졌습니다.
최적화는 디스크에 쓰기를 방해해서는 안 됩니다 . 데이터 중복 제거는 사후 처리 모델을 사용하여 데이터를 최적화합니다. 모든 데이터는 최적화되지 않은 상태로 디스크에 기록된 후 나중에 데이터 중복 제거에 의해 최적화됩니다.
최적화는 액세스 의미 체계를 변경해서는 안 됩니다. 최적화된 볼륨의 데이터에 액세스하는 사용자 및 애플리케이션은 액세스하는 파일이 중복 제거되었음을 전혀 인식하지 못합니다.
볼륨에 대해 사용하도록 설정하면 데이터 중복 제거가 백그라운드에서 실행됩니다.
- 해당 볼륨의 전체 파일에 걸쳐 반복되는 패턴을 식별합니다.
- 해당 청크의 고유한 복사본을 가리키는 재분석 지점 이라는 특수 포인터를 사용하여 해당 부분 또는 청크를 원활하게 이동합니다.
이 과정은 다음 4단계로 실행됩니다.
- 최적화 정책을 충족하는 파일에 대해 파일 시스템을 검사합니다.

- 파일을 변수 크기 청크로 나눕니다.

- 고유한 청크를 식별합니다.
- 청크를 청크 저장소에 배치하고 필요에 따라 압축합니다.
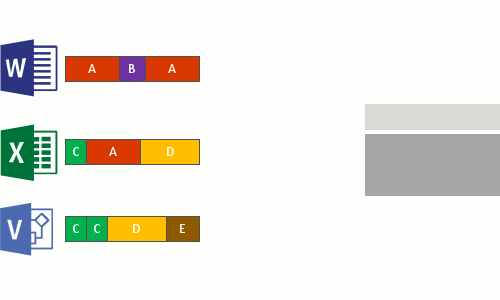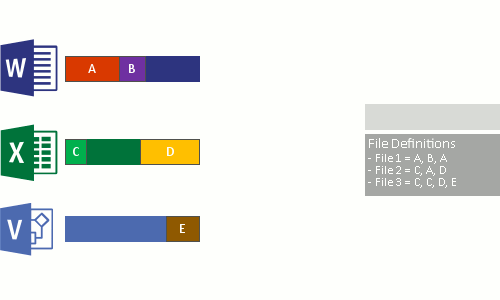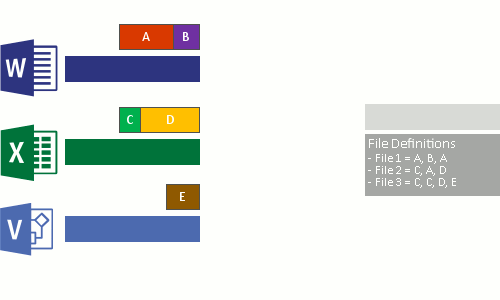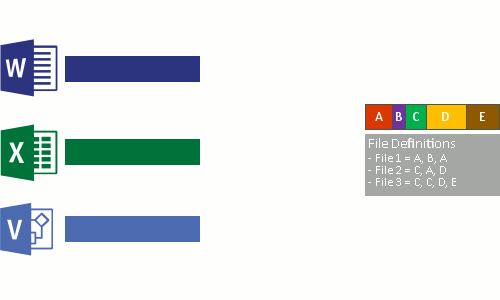
- 최적화된 파일의 원래 파일 스트림을 청크 저장소의 재분석 지점으로 바꿉니다.
최적화된 파일을 읽을 때 파일 시스템은 재분석 지점이 있는 파일을 데이터 중복 제거 파일 시스템 필터(Dedup.sys)로 보냅니다. 필터는 청크 저장소에서 해당 파일에 대한 스트림을 구성하는 적절한 청크로 읽기 작업을 리디렉션합니다. 중복 제거된 파일의 범위에 대한 수정 내용은 디스크에 최적화되지 않은 상태로 작성되며 다음에 실행될 때 최적화 작업에 의해 최적화됩니다.
사용 유형
다음 사용 유형은 일반 워크로드에 적합한 데이터 중복 제거 구성을 제공합니다.
| 사용 유형 | 이상적인 워크로드 | 무엇이 다른가 |
|---|---|---|
| 기본값 | 일반용 파일 서버:
|
|
| Hyper-V | VDI(가상 데스크톱 인프라) 서버 |
|
| 백업 | Microsoft DPM(Data Protection Manager)과 같은 가상화된 백업 애플리케이션 |
|
Jobs
데이터 중복 제거는 사후 처리 전략을 사용하여 볼륨의 공간 효율성을 최적화하고 유지 관리합니다.
| 작업 이름 | 작업 설명 | 기본 일정 |
|---|---|---|
| 최적화 | 최적화 작업은 볼륨 정책 설정당 볼륨의 데이터를 청크로 분할하고(선택적으로) 해당 청크를 압축하고 청크를 청크 저장소에 고유하게 저장하여 중복 제거합니다. 데이터 중복 제거에서 사용하는 최적화 프로세스는 데이터 중복 제거의 작동 방식에 대해 자세히 설명합니다. | 1시간마다 |
| 가비지 수집 | 가비지 수집 작업은 최근에 수정되거나 삭제된 파일에서 더 이상 참조되지 않는 불필요한 청크를 제거하여 디스크 공간을 회수합니다. | 매주 토요일 오전 2시35분 |
| 무결성 스크러빙 | 무결성 스크러빙 작업은 디스크 오류 또는 잘못된 섹터로 인한 청크 저장소의 손상을 식별합니다. 가능한 경우 데이터 중복 제거는 볼륨 기능(예: 스토리지 공간 볼륨의 미러 또는 패리티)을 사용하여 손상된 데이터를 자동으로 다시 구성할 수 있습니다. 또한 데이터 중복 제거는 핫스팟이라고 불리는 영역에서 100번 넘게 참조된, 자주 사용되는 청크의 백업 복사본을 보관합니다. | 매주 토요일 오전 3시35분 |
| 최적화 해제 | 수동으로만 실행해야 하는 특수 작업인 최적화 취소 작업은 중복 제거로 수행된 최적화를 실행 취소하고 해당 볼륨에 대한 데이터 중복 제거를 사용하지 않도록 설정합니다. | 주문형 전용 |
데이터 중복 제거 용어
| Term | Definition |
|---|---|
| 청크 | 청크는 다른 유사한 파일에서도 발견될 가능성이 있어 데이터 중복 제거 청크 알고리즘에 의해 선택된 파일의 섹션입니다. |
| 청크 저장소 | 청크 저장소는 데이터 중복 제거에서 청크를 고유하게 저장하는 데 사용하는 시스템 볼륨 정보 폴더에 구성된 일련의 컨테이너 파일입니다. |
| 중복 제거 | PowerShell, Windows Server API 및 구성 요소, Windows Server 커뮤니티에서 일반적으로 사용되는 데이터 중복 제거(Data Deduplication)의 약어입니다. |
| 파일 메타데이터 | 모든 파일에는 파일의 주요 내용에 상관없이 파일에 대한 흥미로운 속성을 설명하는 메타데이터가 포함되어 있습니다. 예를 들어 만든 날짜, 마지막으로 읽은 날짜, 만든 이 등이 여기에 해당합니다. |
| 파일 스트림 | 파일 스트림은 파일의 주요 내용입니다. 이는 데이터 중복 제거에서 최적화하는 부분입니다. |
| 파일 시스템 | 파일 시스템은 운영 체제가 스토리지 미디어에 파일을 저장하기 위해 사용하는 소프트웨어 및 디스크 상의 데이터 구조입니다. 데이터 중복 제거는 NTFS로 포맷된 볼륨에서 지원됩니다. |
| 파일 시스템 필터 | 파일 시스템 필터는 파일 시스템의 기본 동작을 수정하는 플러그 인입니다. 액세스 의미 체계를 유지하기 위해 데이터 중복 제거는 파일 시스템 필터(Dedup.sys)를 사용하여 최적화된 내용에 대한 읽기를 읽기 요청한 사용자 또는 애플리케이션으로 완전히 투명하게 리디렉션합니다. |
| 최적화 | 파일이 청크되고 고유한 청크가 청크 저장소에 저장된 경우 파일은 데이터 중복 제거에 의해 최적화(또는 중복 제거)된 것으로 간주됩니다. |
| 최적화 정책 | 최적화 정책은 데이터 중복 제거 대상 파일을 지정합니다. 예를 들어 파일은 새롭거나 볼륨의 특정 경로에서 열리거나 특정 파일 형식을 가진 경우 정책에서 벗어나는 것으로 간주될 수 있습니다. |
| 재분석 지점 | 재분석 지점은 지정된 파일 시스템 필터에 I/O를 전달하도록 파일 시스템에 알려주는 특수 태그입니다. 파일의 파일 스트림이 최적화된 경우 데이터 중복 제거는 해당 파일의 액세스 의미 체계를 유지할 수 있도록 파일 스트림을 재분석 지점으로 바꿉니다. |
| 음량 | 볼륨은 여러 실제 스토리지 디바이스를 하나 이상의 서버에 걸쳐 놓을 수 있는 논리적 스토리지 드라이브를 위한 Windows 구성체입니다. 중복 제거는 볼륨 단위로 설정됩니다. |
| 작업량 | 워크로드는 Windows Server에서 실행되는 애플리케이션입니다. 예를 들어 일반용 파일 서버, Hyper-V, SQL Server 등이 여기에 해당합니다. |
Warning
권한 있는 Microsoft 지원 담당자의 지시가 없는 한, 청크 저장소를 수동으로 수정하지 마세요. 수동으로 수정하면 데이터가 손상 또는 손실될 수 있습니다.
자주 묻는 질문
데이터 중복 제거는 다른 최적화 제품과 어떻게 다릅니까? 데이터 중복 제거와 다른 일반 스토리지 최적화 제품 간에는 몇 가지 중요한 차이점이 있습니다.
데이터 중복 제거는 단일 인스턴스 저장소와 어떻게 다릅니까? SIS(단일 인스턴스 저장소) 또는 SIS는 이전의 데이터 중복 제거 기술로 Windows Storage Server 2008 R2에 처음 도입되었습니다. 단일 인스턴스 저장소는 볼륨을 최적화하기 위해 완전히 동일한 파일을 식별하여 SIS 일반 저장소에 저장된 파일의 단일 복사본에 대한 논리적 링크로 대체했습니다. 단일 인스턴스 저장소와 달리, 데이터 중복 제거는 동일하지 않지만 많은 일반 패턴을 공유하는 파일 및 자체적으로 많은 반복 패턴을 포함하는 파일에서 공간을 확보할 수 있습니다. 단일 인스턴스 저장소는 Windows Server 2012 R2부터 사용 중단되었으며 Windows Server 2016에서 제거되고 데이터 중복 제거로 대체되었습니다.
데이터 중복 제거는 NTFS 압축과 어떻게 다릅니까? NTFS 압축은 볼륨 수준에서 선택적으로 사용할 수 있는 NTFS 기능입니다. NTFS 압축을 사용하면 각 파일이 쓰기 시 압축을 통해 개별적으로 최적화됩니다. NTFS 압축을 달리, 데이터 중복 제거는 볼륨의 모든 파일에서 공간을 확보할 수 있습니다. 파일은 내부 중복과 볼륨 내 다른 파일과의 유사성을 모두 가질 수 있으므로, 이는 NTFS 압축으로 내부 중복은 처리되지만 다른 파일과의 유사성은 처리되지 않기 때문에 NTFS 압축보다 낫습니다. 또한 데이터 중복 제거는 사후 처리 모델입니다. 즉, 새 파일 또는 수정된 파일이 최적화되지 않은 상태로 디스크에 기록되고 나중에 데이터 중복 제거에 의해 최적화됩니다.
데이터 중복 제거는 zip, rar, 7z, cab 등의 보관 파일 형식과 어떻게 다릅니까? zip, rar, 7z, cab 등의 보관 파일 형식은 지정된 파일 집합에 대해 압축을 수행합니다. 데이터 중복 제거와 마찬가지로, 파일 내 중복된 패턴 및 파일 간 중복된 패턴이 최적화됩니다. 그러나 보관 파일에 포함할 파일을 선택해야 합니다. 액세스 의미 체계 역시 다릅니다. 보관 파일 내 특정 파일에 액세스하려면 보관 파일을 열고, 특정 파일을 선택하고, 사용을 위해 해당 파일의 압축을 해제해야 합니다. 데이터 중복 제거는 사용자 및 관리자에게 투명하게 작동하므로 수동 작업이 필요 없습니다. 또한 데이터 중복 제거는 액세스 의미 체계를 유지합니다. 따라서 최적화된 파일이 최적화 후 변경되지 않은 상태로 표시됩니다.
선택한 사용 유형에 대해 데이터 중복 제거 설정을 변경할 수 있습니까? Yes. 데이터 중복 제거는 권장 워크로드에 대한 적절한 기본값을 제공하지만 데이터 중복 제거 설정을 조정하여 스토리지를 최대한 활용하려고 할 수 있습니다. 또한 다른 워크로드에서는 데이터 중복 제거가 워크로드를 방해하지 않도록 몇 가지 조정이 필요합니다.
데이터 중복 제거 작업을 수동으로 실행할 수 있습니까? 예, 모든 데이터 중복 제거 작업을 수동으로 실행할 수 있습니다. 이는 예약된 작업이 시스템 리소스 부족 또는 오류로 인해 실행되지 않은 경우에 바람직할 수 있습니다. 또한 최적화 해제 작업은 수동으로만 실행할 수 있습니다.
데이터 중복 제거 작업의 기록 결과를 모니터링할 수 있습니까? 예, 모든 데이터 중복 제거 작업은 Windows 이벤트 로그에 항목을 만듭니다.
시스템에서 데이터 중복 제거 작업에 대한 기본 일정을 변경할 수 있습니까? 예, 모든 일정을 구성할 수 있습니다. 기본 데이터 중복 제거 일정을 수정하는 것은 데이터 중복 제거 작업이 여유 있게 완료되고 워크로드와 리소스를 경합하지 않도록 하는 데 특히 바람직합니다.