What is custom neural voice?
Custom neural voice (CNV) is a text to speech feature that lets you create a one-of-a-kind, customized, synthetic voice for your applications. With custom neural voice, you can build a highly natural-sounding voice for your brand or characters by providing human speech samples as training data.
Important
Custom neural voice access is limited based on eligibility and usage criteria. Request access on the intake form.
Access to Custom neural voice (CNV) Lite is available for anyone to demo and evaluate CNV before investing in professional recordings to create a higher-quality voice.
Out of the box, text to speech can be used with prebuilt neural voices for each supported language. The prebuilt neural voices work well in most text to speech scenarios if a unique voice isn't required.
Custom neural voice is based on the neural text to speech technology and the multilingual, multi-speaker, universal model. You can create synthetic voices that are rich in speaking styles, or adaptable cross languages. The realistic and natural sounding voice of custom neural voice can represent brands, personify machines, and allow users to interact with applications conversationally. See the supported languages for custom neural voice.
How does it work?
To create a custom neural voice, use Speech Studio to upload the recorded audio and corresponding scripts, train the model, and deploy the voice to a custom endpoint.
Tip
Try Custom neural voice (CNV) Lite to demo and evaluate CNV before investing in professional recordings to create a higher-quality voice.
Creating a great custom neural voice requires careful quality control in each step, from voice design and data preparation, to the deployment of the voice model to your system.
Before you get started in Speech Studio, here are some considerations:
- Design a persona of the voice that represents your brand by using a persona brief document. This document defines elements such as the features of the voice, and the character behind the voice. This helps to guide the process of creating a custom neural voice model, including defining the scripts, selecting your voice talent, training, and voice tuning.
- Select the recording script to represent the user scenarios for your voice. For example, you can use the phrases from bot conversations as your recording script if you're creating a customer service bot. Include different sentence types in your scripts, including statements, questions, and exclamations.
Here's an overview of the steps to create a custom neural voice in Speech Studio:
- Create a project to contain your data, voice models, tests, and endpoints. Each project is specific to a country/region and language. If you're going to create multiple voices, it's recommended that you create a project for each voice.
- Set up voice talent. Before you can train a neural voice, you must submit a recording of the voice talent's consent statement. The voice talent statement is a recording of the voice talent reading a statement that they consent to the usage of their speech data to train a custom voice model.
- Prepare training data in the right format. It's a good idea to capture the audio recordings in a professional quality recording studio to achieve a high signal-to-noise ratio. The quality of the voice model depends heavily on your training data. Consistent volume, speaking rate, pitch, and consistency in expressive mannerisms of speech are required.
- Train your voice model. Select at least 300 utterances to create a custom neural voice. A series of data quality checks are automatically performed when you upload them. To build high-quality voice models, you should fix any errors and submit again.
- Test your voice. Prepare test scripts for your voice model that cover the different use cases for your apps. It’s a good idea to use scripts within and outside the training dataset, so you can test the quality more broadly for different content.
- Deploy and use your voice model in your apps.
You can tune, adjust, and use your custom voice, similarly as you would use a prebuilt neural voice. Convert text into speech in real-time, or generate audio content offline with text input. You use the REST API, the Speech SDK, or the Speech Studio.
Tip
Check out the code samples in the Speech SDK repository on GitHub to see how to use custom neural voice in your application.
The style and the characteristics of the trained voice model depend on the style and the quality of the recordings from the voice talent used for training. However, you can make several adjustments by using SSML (Speech Synthesis Markup Language) when you make the API calls to your voice model to generate synthetic speech. SSML is the markup language used to communicate with the text to speech service to convert text into audio. The adjustments you can make include change of pitch, rate, intonation, and pronunciation correction. If the voice model is built with multiple styles, you can also use SSML to switch the styles.
Components sequence
Custom neural voice consists of three major components: the text analyzer, the neural acoustic model, and the neural vocoder. To generate natural synthetic speech from text, text is first input into the text analyzer, which provides output in the form of phoneme sequence. A phoneme is a basic unit of sound that distinguishes one word from another in a particular language. A sequence of phonemes defines the pronunciations of the words provided in the text.
Next, the phoneme sequence goes into the neural acoustic model to predict acoustic features that define speech signals. Acoustic features include the timbre, the speaking style, speed, intonations, and stress patterns. Finally, the neural vocoder converts the acoustic features into audible waves, so that synthetic speech is generated.
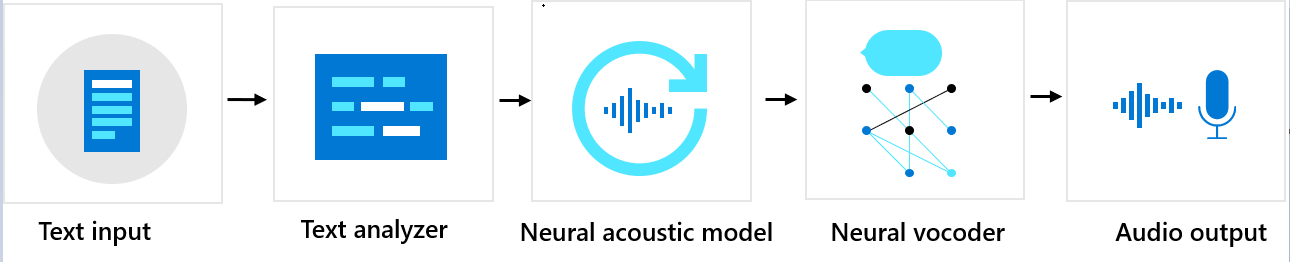
Neural text to speech voice models are trained by using deep neural networks based on the recording samples of human voices. For more information, see this Microsoft blog post. To learn more about how a neural vocoder is trained, see this Microsoft blog post.
Responsible AI
An AI system includes not only the technology, but also the people who use it, the people who are affected by it, and the environment in which it's deployed. Read the transparency notes to learn about responsible AI use and deployment in your systems.
- Transparency note and use cases for custom neural voice
- Characteristics and limitations for using custom neural voice
- Limited access to custom neural voice
- Guidelines for responsible deployment of synthetic voice technology
- Disclosure for voice talent
- Disclosure design guidelines
- Disclosure design patterns
- Code of Conduct for Text to speech integrations
- Data, privacy, and security for custom neural voice