Debug an Azure AI Search skillset in Azure portal
Start a portal-based debug session to identify and resolve errors, validate changes, and push changes to an existing skillset in your Azure AI Search service.
A debug session is a cached indexer and skillset execution, scoped to a single document, that you can use to edit and test skillset changes interactively. When you're finished debugging, you can save your changes to the skillset.
For background on how a debug session works, see Debug sessions in Azure AI Search. To practice a debug workflow with a sample document, see Tutorial: Debug sessions.
Prerequisites
An Azure AI Search service, any region or tier.
An Azure Storage account, used to save session state.
An existing enrichment pipeline, including a data source, a skillset, an indexer, and an index.
Security and permissions
To save a debug session to Azure storage, the search service identity must have Storage Blob Data Contributor permissions on Azure Storage. Otherwise, plan on choosing a full access connection string for the debug session connection to Azure Storage.
If the Azure Storage account is behind a firewall, configure it to allow search service access.
Limitations
Debug sessions work with all generally available indexer data sources and most preview data sources, with the following exceptions:
SharePoint Online indexer.
Azure Cosmos DB for MongoDB indexer.
For the Azure Cosmos DB for NoSQL, if a row fails during index and there's no corresponding metadata, the debug session might not pick the correct row.
For the SQL API of Azure Cosmos DB, if a partitioned collection was previously non-partitioned, the debug session won't find the document.
For custom skills, a user-assigned managed identity isn't supported for a debug session connection to Azure Storage. As stated in the prerequisites, you can use a system managed identity, or specify a full access connection string that includes a key. For more information, see Connect a search service to other Azure resources using a managed identity.
Create a debug session
Sign in to the Azure portal and find your search service.
On the left menu, select Search management > Debug sessions.
On the action bar at the top, select Add debug session.

In Debug session name, provide a name that will help you remember which skillset, indexer, and data source the debug session is about.
In Indexer template, select the indexer that drives the skillset you want to debug. Copies of both the indexer and skillset are used to initialize the session.
In Document to debug, choose the first document in the index or select a specific document. If you select a specific document, depending on the data source, you're asked for a URI or a row ID.
If your specific document is a blob, provide the blob URI. You can find the URI in the blob property page in the Azure portal.

In Storage account, choose a general-purpose storage account for caching the debug session.
Select Authenticate using managed identity if you previously assigned Storage Blob Data Contributor permissions to the search service system-managed identity. If you don't check this box, the search service connects using a full access connection string.
Select Save.
- Azure AI Search creates a blob container on Azure Storage named ms-az-cognitive-search-debugsession.
- Within that container, it creates a folder using the name you provided for the session name.
- It starts your debug session.


The debug session begins by executing the indexer and skillset on the selected document. The document's content and metadata are visible and available in the session.
A debug session can be canceled while it's executing. If you hit the Cancel button you should be able to analyze partial results.
It's expected for a debug session to take longer to execute than the indexer since it goes through extra processing.
Start with errors and warnings
Indexer execution history in the Azure portal gives you the full error and warning list for all documents. In a debug session, the errors and warnings are limited to one document. You can work through this list, make your changes, and then return to the list to verify whether issues are resolved.
Remember that a debug session is based on one document from the entire index. If an input or output looks wrong, the problem could be specific to that document. You can choose a different document to confirm whether errors and warnings are pervasive or specific to a single document.
Select Errors or Warnings for a list of issues.

As a best practice, resolve problems with inputs before moving on to outputs.
To prove whether a modification resolves an error, follow these steps:
Select Save in the skill details pane to preserve your changes.
Select Run in the session window to invoke skillset execution using the modified definition.
Return to Errors or Warningsto see if the count is reduced.
View enriched or generated content
AI enrichment pipelines extract or infer information and structure from source documents, creating an enriched document in the process. An enriched document is first created during document cracking and populated with a root node (/document), plus nodes for any content that is lifted directly from the data source, such as metadata and the document key. More nodes are created by skills during skill execution, where each skill output adds a new node to the enrichment tree.
All content created or used by a skillset appears in the Expression Evaluator. You can hover over the links to view each input or output value in the enriched document tree. To view the input or output of each skill, follow these steps:
In a debug session, expand the blue arrow to view context-sensitive details. By default, the detail is the enriched document data structure. However, if you select a skill or a mapping, the detail is about that object.

Select a skill.
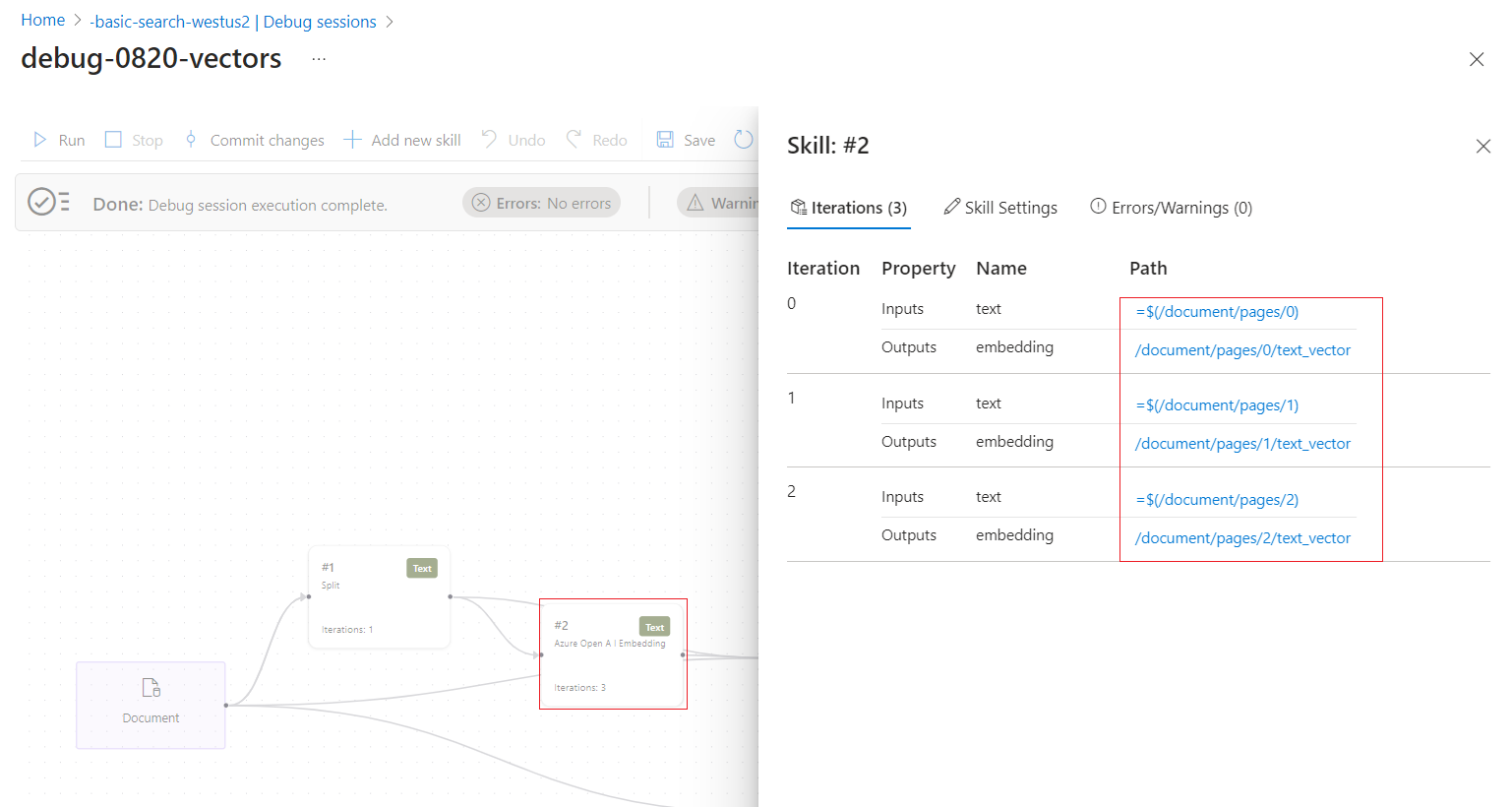
Follow the links to drill further into skills processing. For example, the following screenshot shows the output of the first iteration of the Text Split skill.




Check index mappings
If skills produce output but the search index is empty, check the field mappings. Field mappings specify how content moves out of the pipeline and into a search index.

Select one of the mapping options and expand the details view to review source and target definitions.
Projection Mappings are found in skillsets that provide integrated vectorization, such as the skills created by the Import and vectorize data wizard. These mappings determine parent-child (chunk) field mappings and whether a secondary index is created for just the chunked content
Output Field Mappings are found in indexers and are used when skillsets invoke built-in or custom skills. These mappings are used to set the data path from a node in the enrichment tree to a field in the search index. For more information about paths, see enrichment node path syntax.
Field Mappings are found in indexer definitions and they establish the data path from raw content in the data source and a field in the index. You can use field mappings to add encoding and decoding steps as well.
This example shows the details for a projection mapping. You can edit the JSON to fix any mapping issues.

Edit skill definitions
If the field mappings are correct, check individual skills for configuration and content. If a skill fails to produce output, it might be missing a property or parameter, which can be determined through error and validation messages.
Other issues, such as an invalid context or input expression, can be harder to resolve because the error will tell you what is wrong, but not how to fix it. For help with context and input syntax, see Reference enrichments in an Azure AI Search skillset. For help with individual messages, see Troubleshooting common indexer errors and warnings.
The following steps show you how to get information about a skill.
Select a skill on the work surface. The Skill details pane opens to the right.
Edit a skill definition using Skill Settings. You can edit the JSON directly.
Check the path syntax for referencing nodes in an enrichment tree. Following are some of the most common input paths:
/document/contentfor chunks of text. This node is populated from the blob's content property./document/merged_contentfor chunks of text in skillets that include Text Merge skill./document/normalized_images/*for text that is recognized or inferred from images.
Debug a custom skill locally
Custom skills can be more challenging to debug because the code runs externally, so the debug session can't be used to debug them. This section describes how to locally debug your Custom Web API skill, debug session, Visual Studio Code and ngrok or Tunnelmole. This technique works with custom skills that execute in Azure Functions or any other Web Framework that runs locally (for example, FastAPI).
Get a public URL
This section describes two approaches for getting a public URL to a custom skill.
Use Tunnelmole
Tunnelmole is an open source tunneling tool that can create a public URL that forwards requests to your local machine through a tunnel.
Install Tunnelmole:
- npm:
npm install -g tunnelmole - Linux:
curl -s https://tunnelmole.com/sh/install-linux.sh | sudo bash - Mac:
curl -s https://tunnelmole.com/sh/install-mac.sh --output install-mac.sh && sudo bash install-mac.sh - Windows: Install by using npm. Or if you don't have NodeJS installed, download the precompiled .exe file for Windows and put it somewhere in your PATH.
- npm:
Run this command to create a new tunnel:
tmole 7071You should see a response that looks like this:
http://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071 https://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071In the preceding example,
https://m5hdpb-ip-49-183-170-144.tunnelmole.netforwards to port7071on your local machine, which is the default port where Azure functions are exposed.
Use ngrok
ngrok is a popular, closed source, cross-platform application that can create a tunneling or forwarding URL, so that internet requests reach your local machine. Use ngrok to forward requests from an enrichment pipeline in your search service to your machine to allow local debugging.
Install ngrok.
Open a terminal and go to the folder with the ngrok executable.
Run ngrok with the following command to create a new tunnel:
ngrok http 7071Note
By default, Azure functions are exposed on 7071. Other tools and configurations might require that you provide a different port.
When ngrok starts, copy and save the public forwarding URL for the next step. The forwarding URL is randomly generated.

Configure in Azure portal
Once you have a public URL for your custom skill, modify your Custom Web API Skill URI within a debug session to call the Tunnelmole or ngrok forwarding URL. Be sure to append "/api/FunctionName" when using Azure Function for executing the skillset code.
You can edit the skill definition in the Skill settings section of the Skill details pane.
Test your code
At this point, new requests from your debug session should now be sent to your local Azure Function. You can use breakpoints in your Visual Studio Code to debug your code or run step by step.
Next steps
Now that you understand the layout and capabilities of the Debug Sessions visual editor, try the tutorial for a hands-on experience.