Nata
Norint pasiekti šį puslapį, reikalingas leidimas. Galite pabandyti prisijungti arba pakeisti katalogus.
Norint pasiekti šį puslapį, reikalingas leidimas. Galite pabandyti pakeisti katalogus.
Note
The Retail Interest Group by Dynamics 365 Commerce has moved from Yammer to Viva Engage. If you don't have access to the new Viva Engage community, fill out this form (https://aka.ms/JoinD365commerceVivaEngageCommunity) to be added and stay engaged in the latest discussions.
This article is intended for people who implement functionality that is related to data synchronization (Commerce Data Exchange, [CDX]) in a Microsoft Dynamics 365 Commerce environment. It gives an overview, implementation tips, and overall guidance that you should consider as you plan your implementation, in regard to pages, setup, configuration, best practices, and more.
Proper configuration and synchronization of data is crucial to a correct implementation. Regardless of business requirements, IT infrastructure, and overall preparedness, if data isn't correctly synchronized, the whole environment is effectively useless. Therefore, a top priority is to understand what is required to configure, generate, synchronize, and verify data across the full implementation. This goes from Commerce headquarters through the Commerce Scale Unit to the brick-and-mortar stores that use the Store Commerce app (with or without an offline database) and other in-store components. CDX is the Commerce functionality that replicates and synchronizes data across databases. However, CDX differs from typical data replication functionality because it also allows for filtering. Therefore, CDX helps minimize data sets by generating only data that is specific to the channels that were specified for selection, filtering specific tables from offline databases, and filtering expired records for data that is no longer used, such as expired discounts.
Before you go through this article, it's important that you understand the concepts of a channel (store), registers and devices, and the Store Commerce app offline database. Therefore, we recommend that you review some of the resources at the end of this article, such as the Device management implementation guide and the overview of the Commerce architecture.
Important Commerce headquarters pages
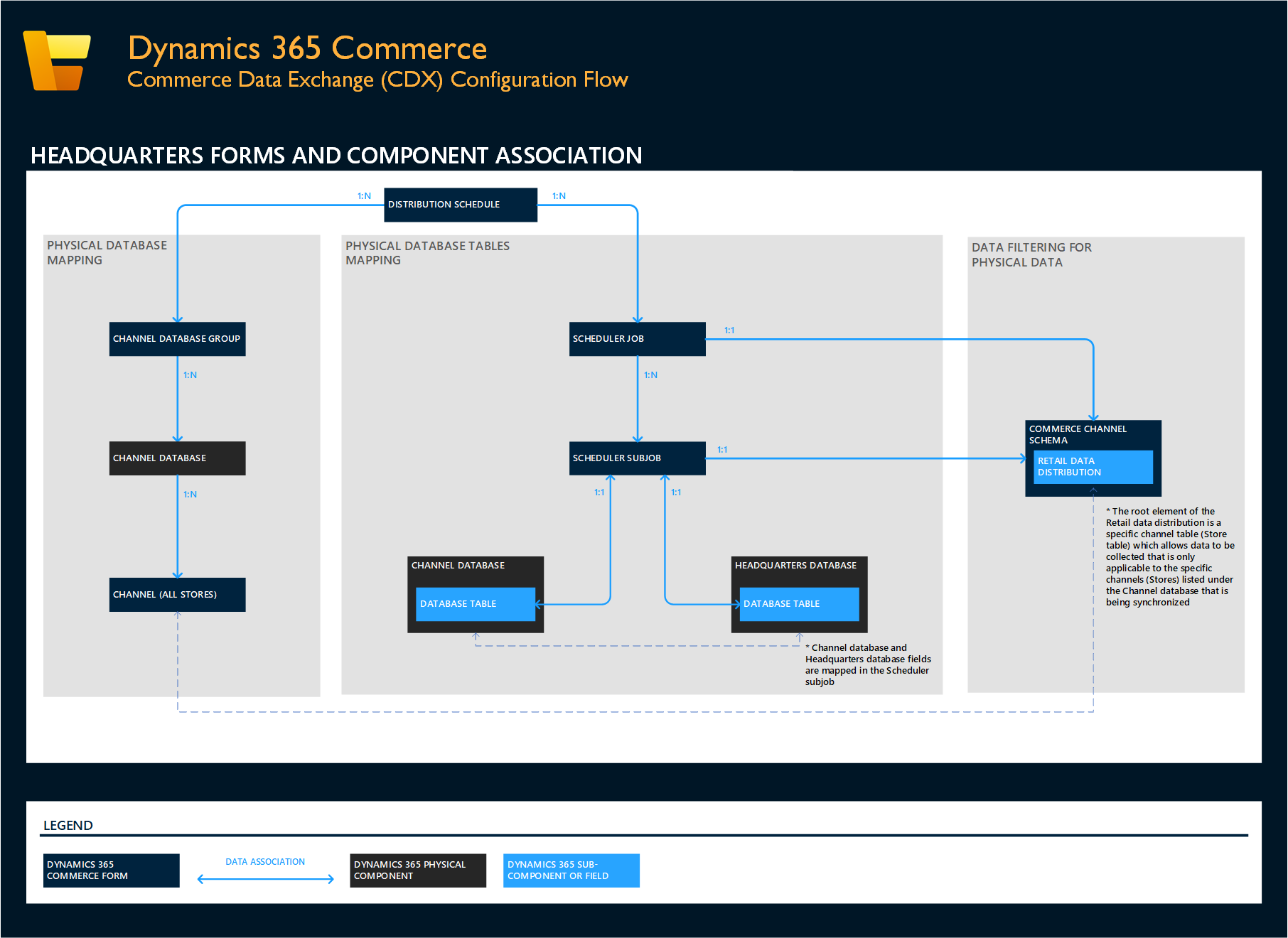
- Channel database – Use this page to create, review, and edit the channel databases that are used in Commerce Scale Units (both Cloud and Self-hosted) and the offline databases that are used with the Store Commerce app. Each database that you create here refers to a single, physical database (in other words, there is a one-to-one [1:1] mapping). A channel database or offline database must be associated with a channel database group. From this page, you can also create full synchronizations of a scheduler job for a selected channel database or offline database.
- Channel database group – Use this page to create, review, and edit channel database groups. Each group is associated with one or more channel or offline databases. The database group is responsible for gathering all the relevant data that is required by all the associated channel and offline databases, and that must be generated as part of CDX data synchronization.
- Channel profile – Use this page to create, review, and edit channel profiles. Each channel profile stores the URLs that are relevant to the network-based communication that is required within a channel. A channel profile typically has a Retail Server URL and a Cloud POS URL. Often, there is also a Media Server Base URL. This URL is the internet addressable location of images that are used by the POS, E-Commerce, and other Commerce channels. Although a channel profile is automatically generated for a Commerce Scale Unit (Cloud), it must be manually generated as part of the configuration and installation steps for a Commerce Scale Unit (Self-hosted).
- Offline profile – Use this page to create, review, and edit offline profiles. Each offline profile lets a user configure settings that are related to offline mode. For example, you can configure settings that let users manually switch to offline mode before they sign in, enable advanced offline switching, and pause offline synchronization. These settings are discussed later in this article and also in the related articles that are listed at the end of this article.
- Commerce channel schema – Use this page to create, review, and edit channel schemas. By default, one schema that is named AX7 is already created and available. The channel schema is required to define how the Commerce headquarters database should be read for Commerce data. It also includes a setting that lets you exclude customer-related data from data synchronization to offline databases. This setting is discussed later in this article and also in the related articles that are listed at the end of this article.
- Distribution schedule – Use this page create, review, and edit distribution schedule jobs. These schedule jobs determine which channel database groups run the associated scheduler job (see the next item in this list). A schedule job can be marked as active, and a single direction of data is associated with it. Typically, the direction is Download, so that data is sent down to the channels. By default, all Commerce-related jobs already exist and are ready to be used with any generated Commerce Scale unit (Cloud). From this page, you can also create delta synchronizations for a selected schedule job.
- Scheduler job – Use this page to create, review, and edit a selected job from the schedule job. This job has a series of associated subjobs. It's also associated with a channel schema (typically, the default AX7 schema). A job can be excluded from synchronization to offline databases.
- Scheduler subjob – Use this page to create, review, and edit a subjob. A subjob is associated with one or more jobs, as shown on the Scheduler job page. A subjob is associated with a single table in the Commerce headquarters database. It shows the channel field mapping, which lists all the related fields that are used in the database table.
- Download sessions and Upload sessions – Use these pages to review and edit download or upload sessions that were created through the data packages that were generated via the previously described pages. These pages show how many rows of data must be synced, when the data was made available, and when it was synced. They also show the overall size of the data package. These pages let you manage and troubleshoot data packages to some extent. For example, you can view any errors that have occurred, and cancel or delete any jobs that are causing an issue. For more information, see Commerce Data Exchange best practices.
Data synchronization overview
When a scheduler job is run, the channel database group selects, from the fields that are listed in the accumulated subjobs, the relevant data for all channel or offline databases that are associated with itself. The result of this data selection is a data package. A data package is a file or multiple files that are zipped together, and contains data that must be applied to one or more destination databases. This data is either all previously selected data or, typically, a selected delta of data. The destination databases can be either channel databases or offline databases.
Data is generated and flows in a specific direction (either download or upload). To understand how best to configure the timing and select data for synchronization, it's important that you understand how the various pages in Commerce headquarters are used and how data generation occurs. When data generation is done correctly, it helps increase performance and reduce Commerce headquarters utilization.
The following illustration shows the various pages in Commerce headquarters and how they are related to each other. (For descriptions of these pages, see the previous section.) CDX data generation can occur only if it's fully configured across all these pages. Data can be downloaded or uploaded. The data synchronization status is viewable on two different pages in headquarters: Download sessions and Upload sessions. CDX data generation occurs through headquarters and is synchronized down (download). Modern Point of Sale (POS) transactional data generated while offline requires the data to be synchronized up (upload).
The following illustration shows the data flows for download and upload. Data packages that are generated through CDX flow downward. A generated data package can apply to the Commerce Scale Unit and to the Store Commerce app offline databases, based on the channel database groups that are configured. Transactional data flows upward from the Store Commerce app offline databases to the Commerce Scale Unit channel database. All transactional data stores in the channel database is then uploaded to the headquarters database.
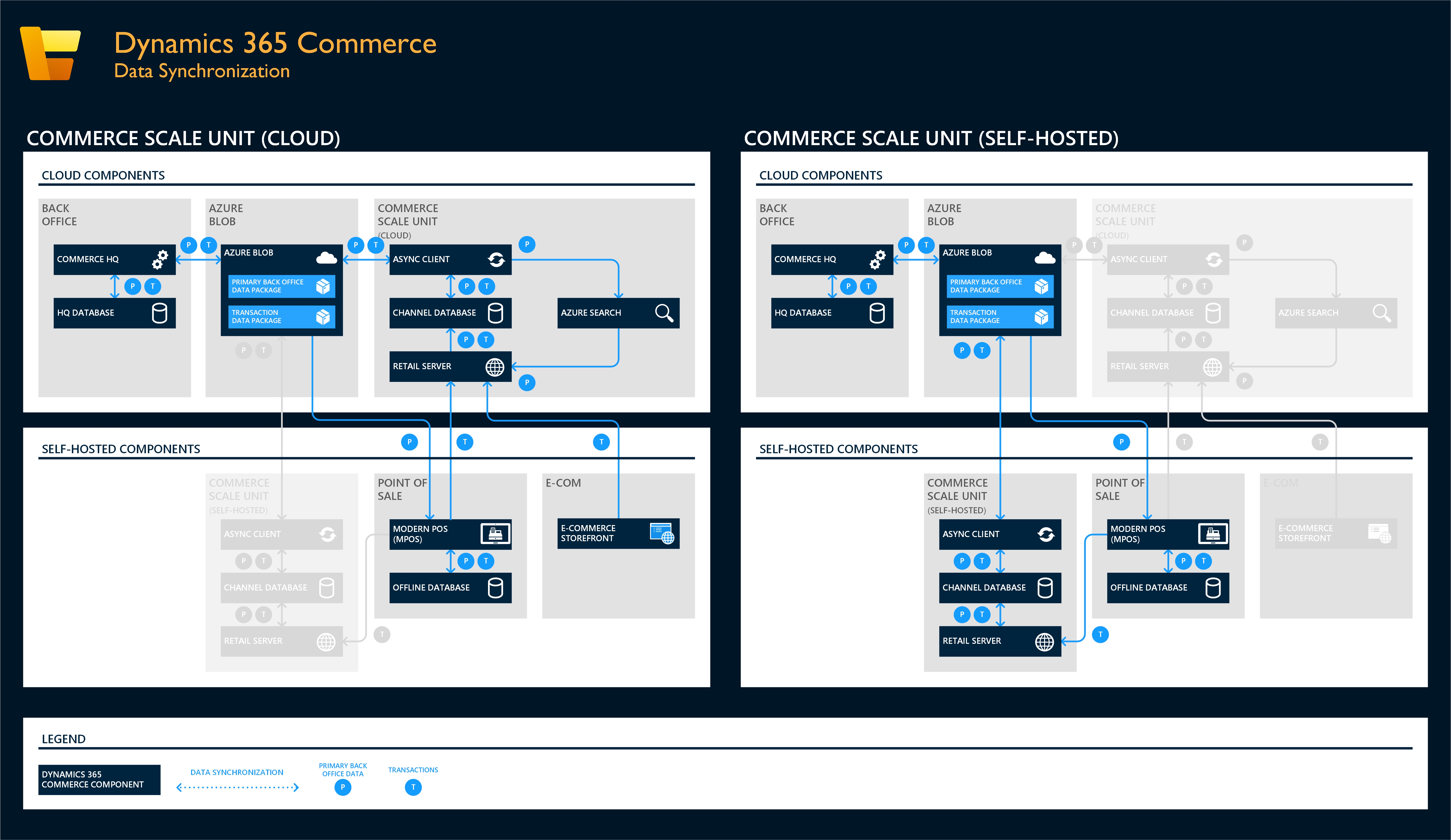
Overview of package management
As packages are created, they are processed and sent to Azure storage, where they are ready for download to a channel or offline database. During all stages from creation through full application, these packages can be viewed as a detailed list on the Download sessions page. In a similar way, as transactions are uploaded, there is an Upload sessions page. On these pages, you can manage the packages to some extent during the various stages.
In general, packages automatically retry and take care of themselves. However, various scenarios can cause a package to become stuck in some way, so that it endlessly retries itself, but without success or outright failure. When you troubleshoot the package application process in these scenarios, the ability to delete or manually retry jobs can be valuable.
Important CDX-related features
All these features are available in version 10.0.12 and later.
| Feature name | Description |
|---|---|
| Advanced offline | This feature consists of a series of settings in the offline profile. These settings make additional offline switching scenarios available, give users the ability to switch to offline mode before they sign in to the POS, and allow for enhanced Commerce headquarters availability testing, so that you can switch to offline mode more often and more easily return to online status. |
| Offline data exclusion | This feature is also known as Data sizing improvements. It provides the ability to flag specific data that must be excluded from offline databases, and that must not be synced in the future. It's also used to fully remove all customer-related data from offline databases. |
| Forced Batch processing and inability to use recurrence with a Full sync | In version 10.0.11 and later, you can't perform the Run now command from the Distribution schedule page unless batch processing is used. This change was made because of performance issues that occurred if jobs were run during times when environments were most heavily used. In another change that was made as a part of this feature enhancement, recurrence can't be used when the Full data sync command (full job synchronization) is run from the Channel database page in Commerce headquarters. Only a single occurrence can be run. |
Advanced offline
This feature can be configured in the offline profile. Three settings are related to it:
- Allow manual switch to offline before sign in – This setting lets Store Commerce app users switch to offline mode before they sign in to the POS. It's helpful in scenarios where time-outs might occur before sign-in is completed, or where atypical response codes from the Commerce Scale Unit (Cloud or Self-hosted) are occurring. When this setting is turned on, a Store Commerce app user who is using an offline database can access the Settings menu from the POS sign-in page. This menu includes a new option for switching to offline mode. By selecting this option, the user can sign in directly against the offline database instead of first having to sign in via a call to the Commerce Scale Unit.
- Enable advanced offline switching – This setting enables the Store Commerce app to switch to offline mode more easily and more often. Typically, the Store Commerce app tries to maintain its online status and switches to offline mode only when such a switch is required to continue functionality. When this setting is turned on, the Store Commerce app can switch more often, especially in scenarios that involve sign-in and additional Commerce Scale Unit responses that might be considered a delay to POS operation. This setting is most valuable in scenarios where speed is a higher priority than maintaining availability of online-only features (for example, paying with a gift card, which requires connection to headquarters).
- System health check interval (mins) – This setting works as a subfeature of the Enable advanced offline switching setting that was just described. Usually, when that setting is turned off and the Store Commerce app is in offline mode, the POS waits a specific amount of time, based on configuration in the Offline profile, and then tries to reconnect to the Commerce Scale Unit during the next operation call that occurs. This advanced offline health check provides a more frequent, operation-independent method of checking online availability and switching more quickly as soon as online functionality is available again.
Offline data exclusion
This feature began to be released in version 10.0.11, and the full feature set was completed in version 10.0.12. This feature is intended to help reduce that amount of data that is synced to offline databases. On the Scheduler job and Scheduler subjob pages in Commerce headquarters, an option that is named Exclude from offline databases lets you exclude data (tables) when you sync data to the offline database.
- On the Scheduler job page, set the option to Yes to stop all generated data packages for the job from being synced to offline databases. If the Full data sync command is run for the excluded job from the Channel database page, the relevant tables in offline databases will be emptied (that is, all data that previously existed will be cleared).
- On the Scheduler subjob, set the option to Yes to stop the associated table for any job that contains the subjob from being synchronized to offline databases. For example, the channel database SQL table DIRPARTYTABLE is synchronized by three different scheduler jobs. Therefore, if you exclude the DIRPARTYTABLE table, you stop its data from being synced to offline databases by all three jobs. (We don't recommend that you exclude this example table (DIRPARTYTABLE) as it is critical for the staff-related data it stores in the offline database).
This feature also represents the first step in row-level filtering. In Commerce headquarters, the Commerce channel schema page includes a new option that is named Filter shared customer data tables. (To open the Commerce channel schema page, go to Retail and Commerce > Headquarters setup > Commerce scheduler > Channel database group, and then, in the Commerce channel schema field, select a value. The default value is AX7.) By setting the option to Yes, you flag all customer data in shared tables. This setting works only for standard Microsoft-created tables (that is, tables that aren't custom-created tables). When you set this option to Yes, you receive a message that states, "This will remove customer data from the records in the channel data distribution only. All schedule jobs that contain customer data also need to be marked to skip offline synchronization." You can then select either Yes or No. This message is intended as a reminder that the Exclude from offline databases option must also be set to Yes for all customer data jobs. (By default, the only customer data job is the 1010 job.)
Here is an example of this filtering. The DIRPARTYTABLE table is used for both customers and employees. If you set the Filter shared customer data tables to Yes, all customer records at the row level are flagged to indicate that they should not be synced to offline databases. When the Exclude from offline databases option is also set to Yes, all customer data will be excluded from synchronization to offline databases.
Implementation considerations
This section describes configurations that you should consider when you begin to plan your implementation. The features that are described here are related to data management and data configuration. Before you read the guidance that is provided here, we highly recommend that you read Commerce Data Exchange best practices.
Create a Scheduler job calendar – How often will each job occur? How many times per day will each job occur? Will large, non-critical jobs occur only during off-hours, when the overall environment isn't heavily used? By creating a calendar (either physical or virtual, as you prefer), you can learn the details about how jobs will intersect with other workloads that affect performance (for example, statement posting), hours of operation, batch processing for external data, and any customizations that push or pull data at specified times (or frequently throughout the day, just like a CDX job).
Pause offline synchronization – As a retail organization expands, it should take advantage of this offline profile feature as fully as possible. Growth is good, but data generation should be managed to help minimize the performance impact on the currently operating business. This feature enables the creation of channels, registers, and databases, but without requiring a massive, performance-affecting amount of data generation long before the registers are ever used.
Advanced offline – The previously described advanced offline features can be helpful, but they should be used only if they suit the priorities and values of the retail organization. Although the advanced offline health check interval can help maximize online time, it will also be more forceful about pushing a register to offline mode if Commerce headquarters or the Commerce Scale Unit becomes unresponsive or unavailable for any reason. It can be valuable to maximize the performance of registers by quickly switching to offline mode instead of waiting for time-outs or repeated retry responses. However, this approach must be understood and managed against the standard seamless offline model that tries to stay online as long as possible, to allow for operations such as loyalty operations, additional payment methods, and customer orders.
Offline data exclusion – In general, a small data set is typically faster than a large data set. It can be valuable to exclude data that isn't relevant to the functionality of the offline database when you want to reduce the overall database size (for example, SQL Express allows for databases of only 10 gigabytes [GB]), and also when you want to minimize the amount of data that the POS terminal queries as part of general operations while it's in offline mode.
This feature varies widely, depending on the business requirements of the retail organization. Therefore, it's crucial that you know what data is required for customizations to work, or even what data is required for standard day-to-day operations. For example, if a customer doesn't have to be attached to a transaction, customers can be excluded from the offline databases.
Channel database groups – At a minimum, two channel database groups should exist: one for the initial Commerce Scale Unit (Cloud) that is used, and one for any or all offline databases that are used. Large retail enterprises might have multiple offline-focused channel database groups that are separated based on similarity of data in their associated channels (stores).
Additionally, it's helpful to have a "dummy" channel database group that can be used to configure new channel databases, registers that have offline support (in this case, offline databases will be created), and maybe even new but unused Commerce Scale Units (either Cloud or Self-hosted). Because this "dummy" group won't be associated with any distribution schedule jobs, no data generation will ever occur for anything that is associated with it. As time and the implementation progress, the associated entities (for example, channels [stores] and register offline databases) will be re-associated with the correct database group. A great alternative to this approach, and perhaps even an improvement, is to use the Pause offline synchronization feature that was described earlier.
SQL Server versions and licenses
To learn more about the versions of SQL Server and how to use them, see Commerce offline implementation and troubleshooting.
Additional resources
Commerce Data Exchange troubleshooting
Commerce Data Exchange best practices
Commerce offline implementation and troubleshooting
Dynamics 365 Commerce architecture overview