Code First Migrations in Team Environments
Note
This article assumes you know how to use Code First Migrations in basic scenarios. If you don’t, then you’ll need to read Code First Migrations before continuing.
Grab a coffee, you need to read this whole article
The issues in team environments are mostly around merging migrations when two developers have generated migrations in their local code base. While the steps to solve these are pretty simple, they require you to have a solid understanding of how migrations works. Please don’t just skip ahead to the end – take the time to read the whole article to ensure you are successful.
Some general guidelines
Before we dig into how to manage merging migrations generated by multiple developers, here are some general guidelines to set you up for success.
Each team member should have a local development database
Migrations uses the __MigrationsHistory table to store what migrations have been applied to the database. If you have multiple developers generating different migrations while trying to target the same database (and thus share a __MigrationsHistory table) migrations is going to get very confused.
Of course, if you have team members that aren’t generating migrations, there is no problem having them share a central development database.
Avoid automatic migrations
The bottom line is that automatic migrations initially look good in team environments, but in reality they just don’t work. If you want to know why, keep reading – if not, then you can skip to the next section.
Automatic migrations allows you to have your database schema updated to match the current model without the need to generate code files (code-based migrations). Automatic migrations would work very well in a team environment if you only ever used them and never generated any code-based migrations. The problem is that automatic migrations are limited and don’t handle a number of operations – property/column renames, moving data to another table, etc. To handle these scenarios you end up generating code-based migrations (and editing the scaffolded code) that are mixed in between changes that are handled by automatic migrations. This makes it near on impossible to merge changes when two developers check in migrations.
Understanding how migrations works
The key to successfully using migrations in a team environment is a basic understanding how migrations tracks and uses information about the model to detect model changes.
The first migration
When you add the first migration to your project, you run something like Add-Migration First in Package Manager Console. The high level steps that this command performs are pictured below.
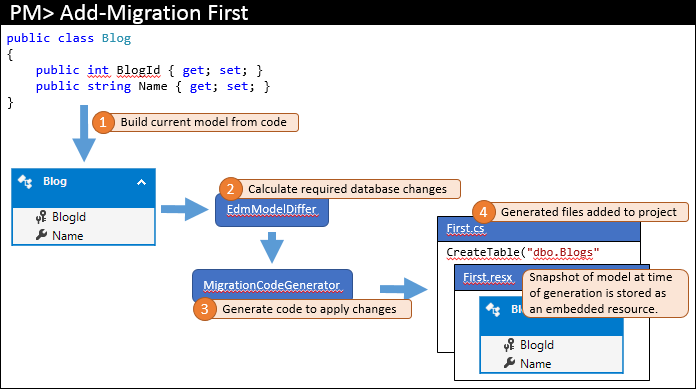
The current model is calculated from your code (1). The required database objects are then calculated by the model differ (2) – since this is the first migration the model differ just uses an empty model for the comparison. The required changes are passed to the code generator to build the required migration code (3) which is then added to your Visual Studio solution (4).
In addition to the actual migration code that is stored in the main code file, migrations also generates some additional code-behind files. These files are metadata that is used by migrations and are not something you should edit. One of these files is a resource file (.resx) that contains a snapshot of the model at the time the migration was generated. You’ll see how this is used in the next step.
At this point you would probably run Update-Database to apply your changes to the database, and then go about implementing other areas of your application.
Subsequent migrations
Later you come back and make some changes to your model – in our example we’ll add a Url property to Blog. You would then issue a command such as Add-Migration AddUrl to scaffold a migration to apply the corresponding database changes. The high level steps that this command performs are pictured below.
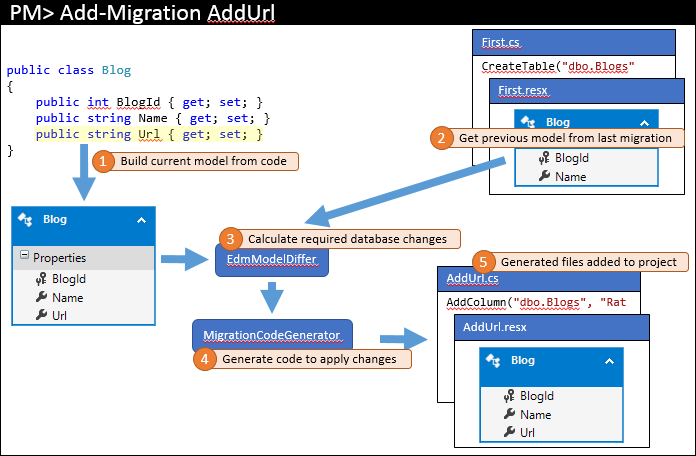
Just like last time, the current model is calculated from code (1). However, this time there are existing migrations so the previous model is retrieved from the latest migration (2). These two models are diffed to find the required database changes (3) and then the process completes as before.
This same process is used for any further migrations that you add to the project.
Why bother with the model snapshot?
You may be wondering why EF bothers with the model snapshot – why not just look at the database. If so, read on. If you’re not interested then you can skip this section.
There are a number of reasons EF keeps the model snapshot around:
- It allows your database to drift from the EF model. These changes can be made directly in the database, or you can change the scaffolded code in your migrations to make the changes. Here are a couple of examples of this in practice:
- You want to add an Inserted and Updated to column to one or more of your tables but you don’t want to include these columns in the EF model. If migrations looked at the database it would continually try to drop these columns every time you scaffolded a migration. Using the model snapshot, EF will only ever detect legitimate changes to the model.
- You want to change the body of a stored procedure used for updates to include some logging. If migrations looked at this stored procedure from the database it would continually try and reset it back to the definition that EF expects. By using the model snapshot, EF will only ever scaffold code to alter the stored procedure when you change the shape of the procedure in the EF model.
- These same principles apply to adding extra indexes, including extra tables in your database, mapping EF to a database view that sits over a table, etc.
- The EF model contains more than just the shape of the database. Having the entire model allows migrations to look at information about the properties and classes in your model and how they map to the columns and tables. This information allows migrations to be more intelligent in the code that it scaffolds. For example, if you change the name of the column that a property maps to migrations can detect the rename by seeing that it’s the same property – something that can’t be done if you only have the database schema.
What causes issues in team environments
The workflow covered in the previous section works great when you are a single developer working on an application. It also works well in a team environment if you are the only person making changes to the model. In this scenario you can make model changes, generate migrations and submit them to your source control. Other developers can sync your changes and run Update-Database to have the schema changes applied.
Issues start to arise when you have multiple developers making changes to the EF model and submitting to source control at the same time. What EF lacks is a first class way to merge your local migrations with migrations that another developer has submitted to source control since you last synced.
An example of a merge conflict
First let’s look at a concrete example of such a merge conflict. We’ll continue on with the example we looked at earlier. As a starting point let’s assume the changes from the previous section were checked in by the original developer. We’ll track two developers as they make changes to code base.
We’ll track the EF model and the migrations through a number of changes. For a starting point, both developers have synced to the source control repository, as depicted in the following graphic.
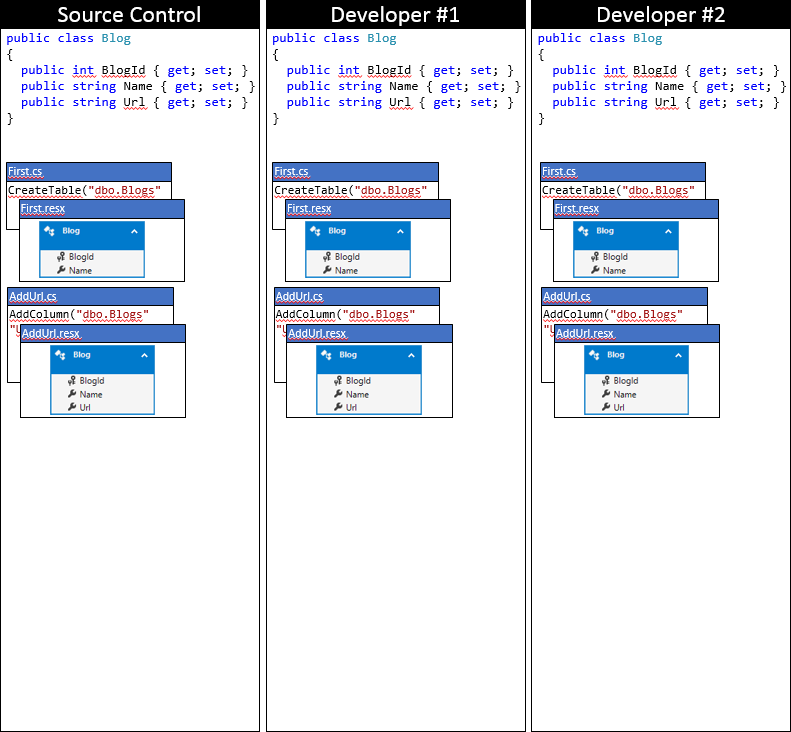
Developer #1 and developer #2 now makes some changes to the EF model in their local code base. Developer #1 adds a Rating property to Blog – and generates an AddRating migration to apply the changes to the database. Developer #2 adds a Readers property to Blog – and generates the corresponding AddReaders migration. Both developers run Update-Database, to apply the changes to their local databases, and then continue developing the application.
Note
Migrations are prefixed with a timestamp, so our graphic represents that the AddReaders migration from Developer #2 comes after the AddRating migration from Developer #1. Whether developer #1 or #2 generated the migration first makes no difference to the issues of working in a team, or the process for merging them that we’ll look at in the next section.
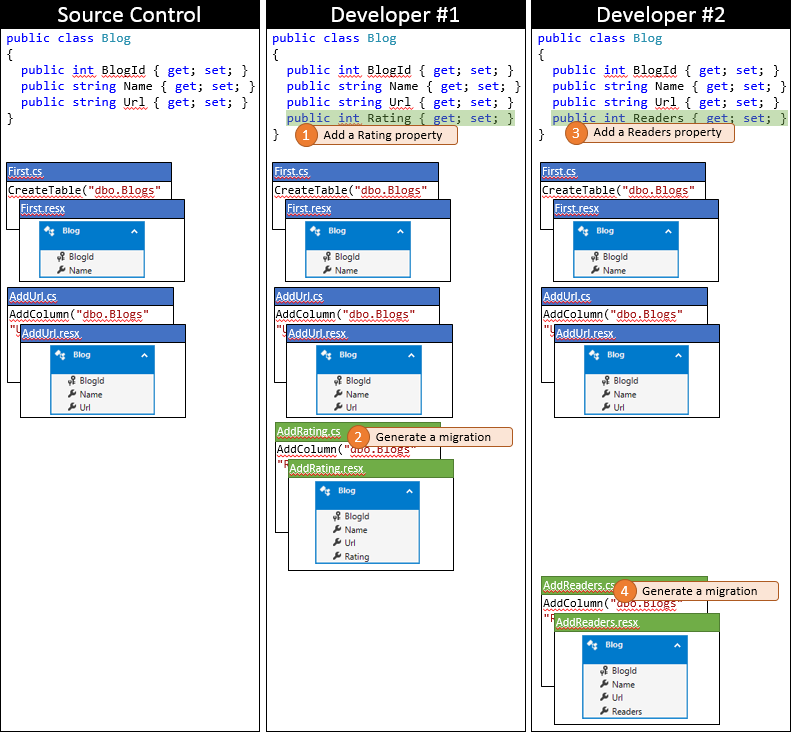
It’s a lucky day for Developer #1 as they happen to submit their changes first. Because no one else has checked in since they synced their repository, they can just submit their changes without performing any merging.
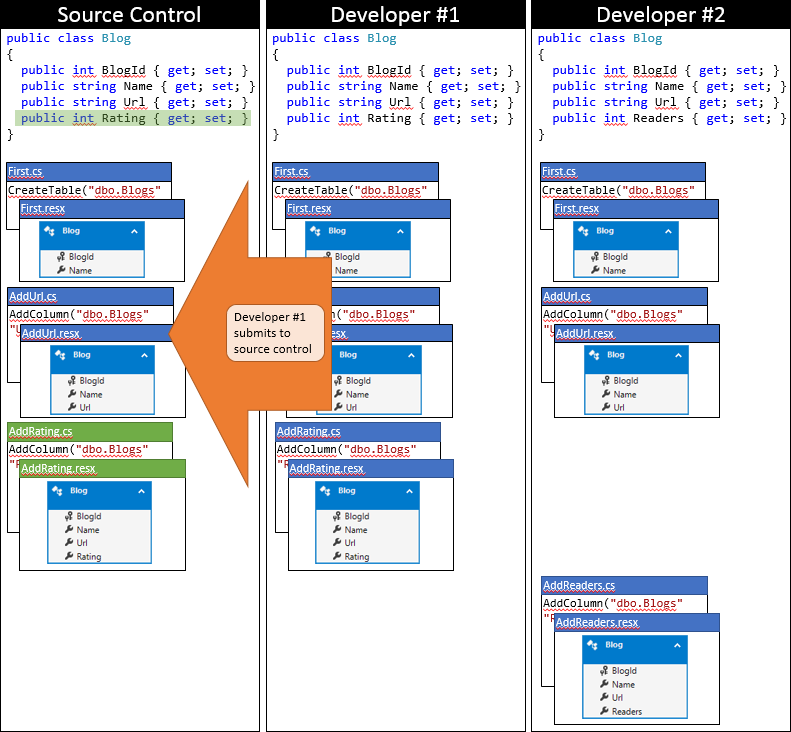
Now it’s time for Developer #2 to submit. They aren’t so lucky. Because someone else has submitted changes since they synced, they will need to pull down the changes and merge. The source control system will likely be able to automatically merge the changes at the code level since they are very simple. The state of Developer #2’s local repository after syncing is depicted in the following graphic.
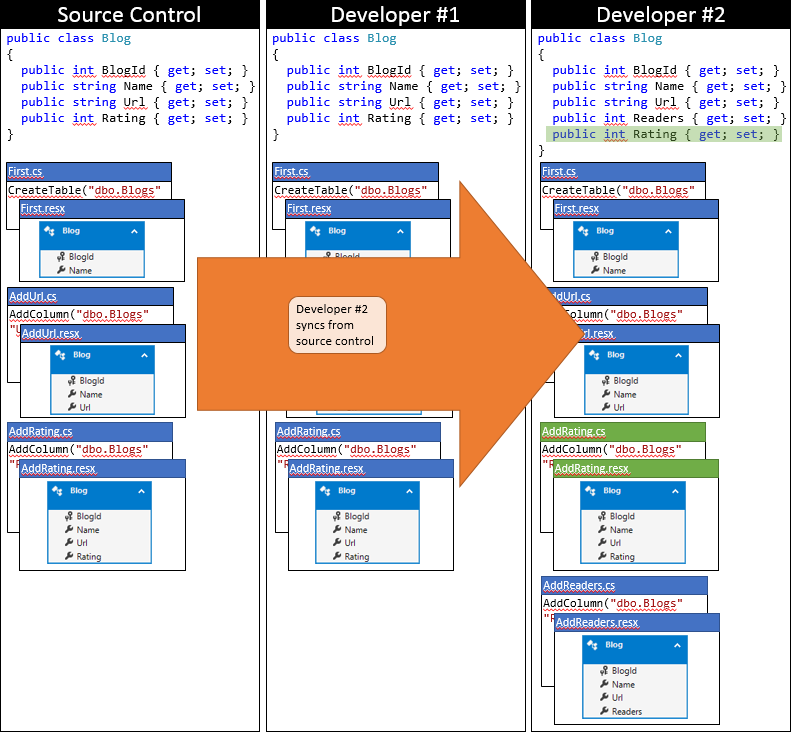
At this stage Developer #2 can run Update-Database which will detect the new AddRating migration (which hasn’t been applied to Developer #2’s database) and apply it. Now the Rating column is added to the Blogs table and the database is in sync with the model.
There are a couple of problems though:
- Although Update-Database will apply the AddRating migration it will also raise a warning: Unable to update database to match the current model because there are pending changes and automatic migration is disabled… The problem is that the model snapshot stored in the last migration (AddReader) is missing the Rating property on Blog (since it wasn’t part of the model when the migration was generated). Code First detects that the model in the last migration doesn’t match the current model and raises the warning.
- Running the application would result in an InvalidOperationException stating that “The model backing the 'BloggingContext' context has changed since the database was created. Consider using Code First Migrations to update the database…” Again, the problem is the model snapshot stored in the last migration doesn’t match the current model.
- Finally, we would expect running Add-Migration now would generate an empty migration (since there are no changes to apply to the database). But because migrations compares the current model to the one from the last migration (which is missing the Rating property) it will actually scaffold another AddColumn call to add in the Rating column. Of course, this migration would fail during Update-Database because the Rating column already exists.
Resolving the merge conflict
The good news is that it’s not too hard to deal with the merge manually – provided you have an understanding of how migrations works. So if you’ve skipped ahead to this section… sorry, you need to go back and read the rest of the article first!
There are two options, the easiest is to generate a blank migration that has the correct current model as a snapshot. The second option is to update the snapshot in the last migration to have the correct model snapshot. The second option is a little harder and can’t be used in every scenario, but it’s also cleaner because it doesn’t involve adding an extra migration.
Option 1: Add a blank ‘merge’ migration
In this option we generate a blank migration solely for the purpose of making sure the latest migration has the correct model snapshot stored in it.
This option can be used regardless of who generated the last migration. In the example we’ve been following Developer #2 is taking care of the merge and they happened to generate the last migration. But these same steps can be used if Developer #1 generated the last migration. The steps also apply if there are multiple migrations involved – we’ve just been looking at two in order to keep it simple.
The following process can be used for this approach, starting from the time you realize you have changes that need to be synced from source control.
- Ensure any pending model changes in your local code base have been written to a migration. This step ensures you don’t miss any legitimate changes when it comes time to generate the blank migration.
- Sync with source control.
- Run Update-Database to apply any new migrations that other developers have checked in. Note: if you don’t get any warnings from the Update-Database command then there were no new migrations from other developers and there is no need to perform any further merging.
- Run Add-Migration <pick_a_name> –IgnoreChanges (for example, Add-Migration Merge –IgnoreChanges). This generates a migration with all the metadata (including a snapshot of the current model) but will ignore any changes it detects when comparing the current model to the snapshot in the last migrations (meaning you get a blank Up and Down method).
- Run Update-Database to re-apply the latest migration with the updated metadata.
- Continue developing, or submit to source control (after running your unit tests of course).
Here is the state of Developer #2’s local code base after using this approach.
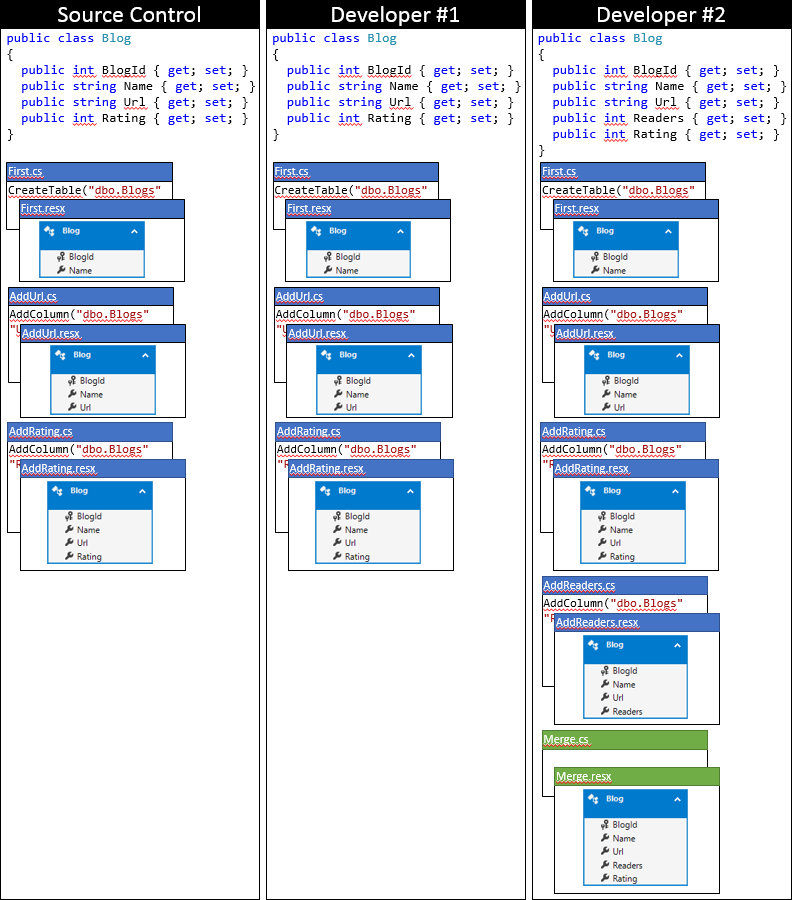
Option 2: Update the model snapshot in the last migration
This option is very similar to option 1 but removes the extra blank migration – because let’s face it, who wants extra code files in their solution.
This approach is only feasible if the latest migration exists only in your local code base and has not yet been submitted to source control (for example, if the last migration was generated by the user doing the merge). Editing the metadata of migrations that other developers may have already applied to their development database – or even worse applied to a production database – can result in unexpected side effects. During the process we’re going to roll back the last migration in our local database and re-apply it with updated metadata.
While the last migration needs to just be in the local code base there are no restrictions to the number or order of migrations that proceed it. There can be multiple migrations from multiple different developers and the same steps apply– we’ve just been looking at two in order to keep it simple.
The following process can be used for this approach, starting from the time you realize you have changes that need to be synced from source control.
- Ensure any pending model changes in your local code base have been written to a migration. This step ensures you don’t miss any legitimate changes when it comes time to generate the blank migration.
- Sync with the source control.
- Run Update-Database to apply any new migrations that other developers have checked in. Note: if you don’t get any warnings from the Update-Database command then there were no new migrations from other developers and there is no need to perform any further merging.
- Run Update-Database –TargetMigration <second_last_migration> (in the example we’ve been following this would be Update-Database –TargetMigration AddRating). This rolls the database back to the state of the second last migration – effectively ‘un-applying’ the last migration from the database. Note: This step is required to make it safe to edit the metadata of the migration since the metadata is also stored in the __MigrationsHistoryTable of the database. This is why you should only use this option if the last migration is only in your local code base. If other databases had the last migration applied you would also have to roll them back and re-apply the last migration to update the metadata.
- Run Add-Migration <full_name_including_timestamp_of_last_migration> (in the example we’ve been following this would be something like Add-Migration 201311062215252_AddReaders). Note: You need to include the timestamp so that migrations knows you want to edit the existing migration rather than scaffolding a new one. This will update the metadata for the last migration to match the current model. You’ll get the following warning when the command completes, but that’s exactly what you want. “Only the Designer Code for migration '201311062215252_AddReaders' was re-scaffolded. To re-scaffold the entire migration, use the -Force parameter.”
- Run Update-Database to re-apply the latest migration with the updated metadata.
- Continue developing, or submit to source control (after running your unit tests of course).
Here is the state of Developer #2’s local code base after using this approach.
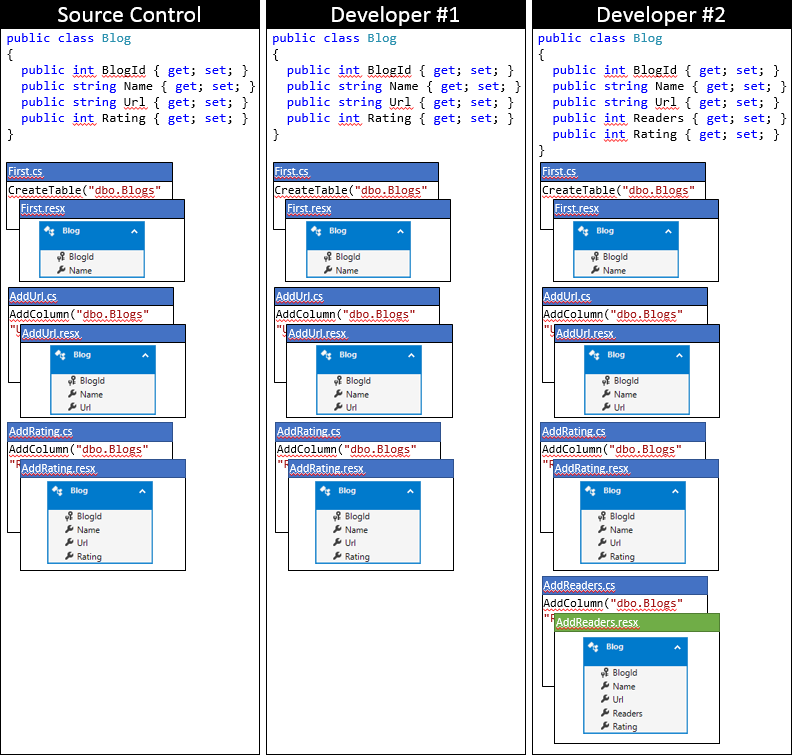
Summary
There are some challenges when using Code First Migrations in a team environment. However, a basic understanding of how migrations works and some simple approaches for resolving merge conflicts make it easy to overcome these challenges.
The fundamental issue is incorrect metadata stored in the latest migration. This causes Code First to incorrectly detect that the current model and database schema don’t match and to scaffold incorrect code in the next migration. This situation can be overcome by generating a blank migration with the correct model, or updating the metadata in the latest migration.