Spark compute configuration settings in Fabric environments
Microsoft Fabric Data Engineering and Data Science experiences operate on a fully managed Spark compute platform. This platform is designed to deliver unparalleled speed and efficiency. It includes starter pools and custom pools.
A Fabric environment contains a collection of configurations, including Spark compute properties that allow users to configure the Spark session after they're attached to notebooks and Spark jobs. With an environment, you have a flexible way to customize compute configurations for running your Spark jobs. In an environment, the compute section allows you to configure the Spark session level properties to customize the memory and cores of executors based on workload requirements.
Workspace admins can enable or disable compute customizations with the Customize compute configurations for items switch in the Pool tab of the Data Engineering/Science section in the Workspace settings screen.
Workspace admins can delegate the members and contributors to change the default session level compute configurations in s Fabric environment by enabling this setting.
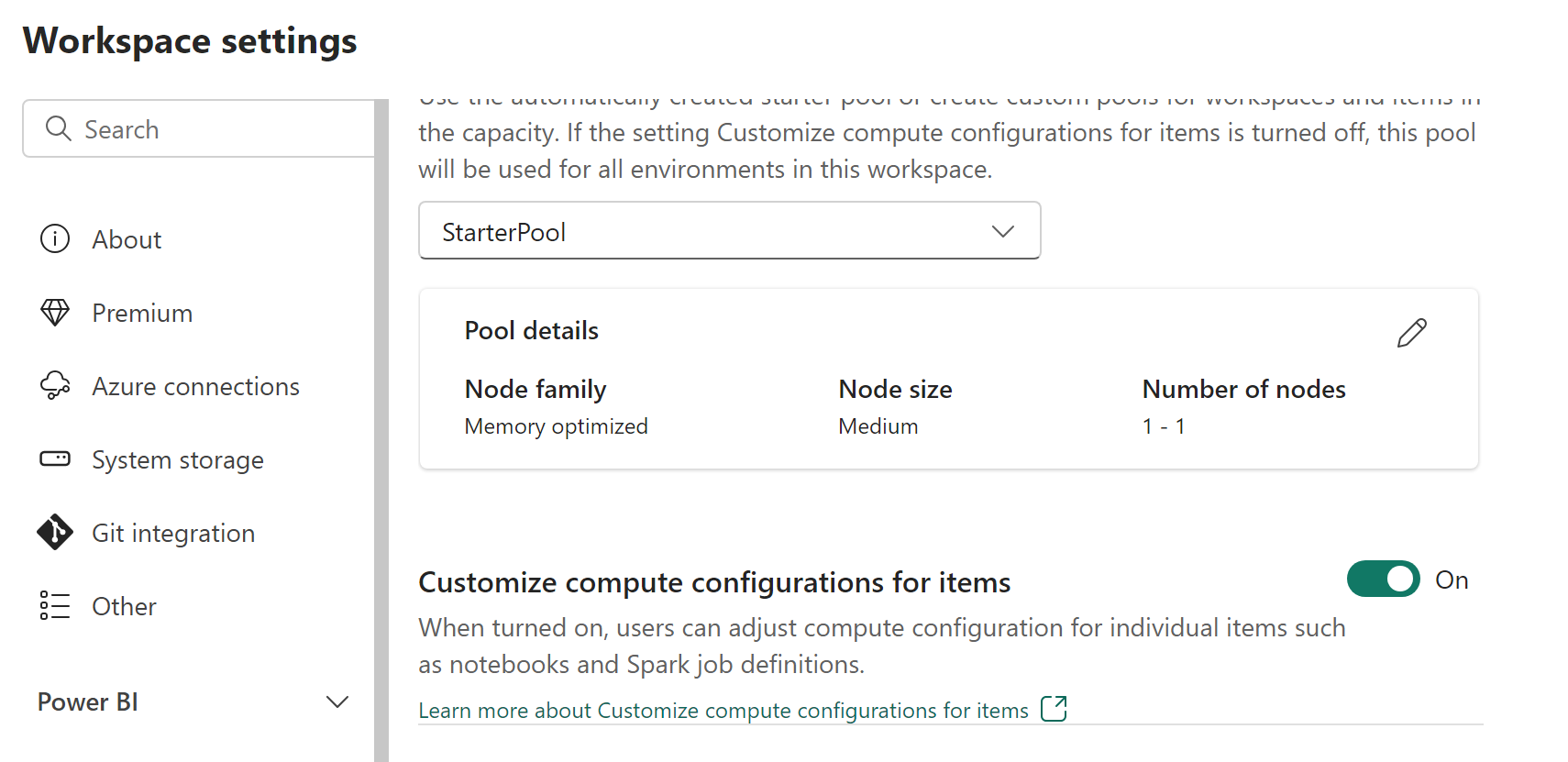
If the workspace admin disables this option in the workspace settings, the compute section of the environment is disabled and the default pool compute configurations for the workspace are used for running Spark jobs.
Customizing session level compute properties in an environment
As a user, you can select a pool for the environment from the list of pools available in the Fabric workspace. The Fabric workspace admin creates the default starter pool and custom pools.
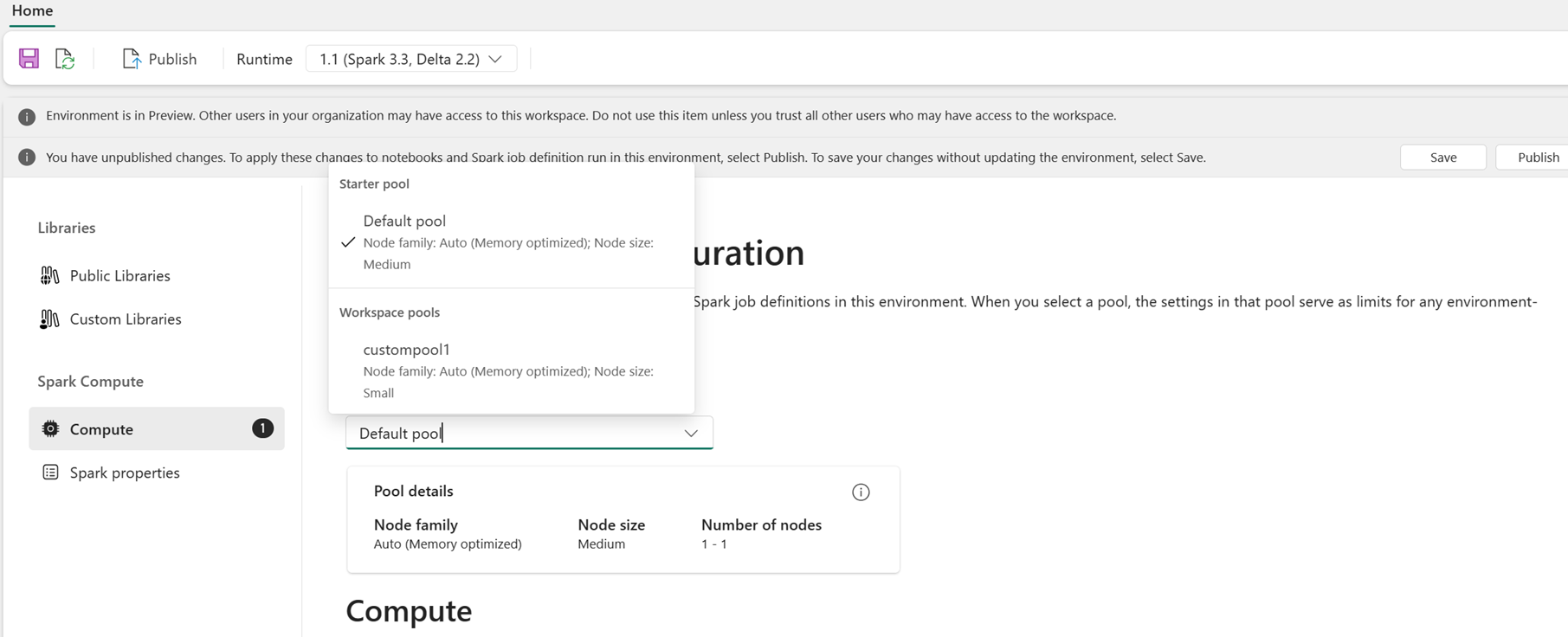
After you select a pool in the Compute section, you can tune the cores and memory for the executors within the bounds of the node sizes and limits of the selected pool.
For example: You select a custom pool with node size of large, which is 16 Spark vCores, as the environment pool. You can then choose the driver/executor core to be either 4, 8 or 16, based on your job level requirement. For the memory allocated to driver and executors, you can choose 28 g, 56 g, or 112 g, which are all within the bounds of a large node memory limit.
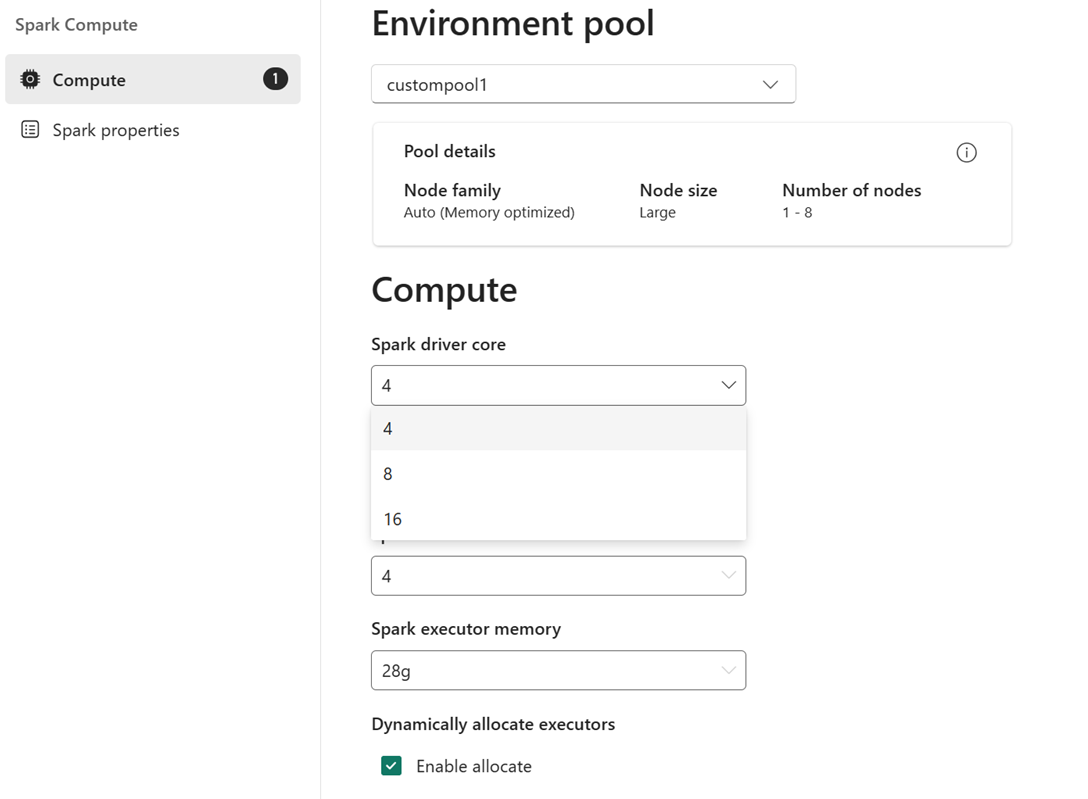
For more information about Spark compute sizes and their cores or memory options, see What is Spark compute in Microsoft Fabric?.