How to copy data using copy activity
In Data Pipeline, you can use the Copy activity to copy data among data stores located in the cloud.
After you copy the data, you can use other activities to further transform and analyze it. You can also use the Copy activity to publish transformation and analysis results for business intelligence (BI) and application consumption.
To copy data from a source to a destination, the service that runs the Copy activity performs these steps:
- Reads data from a source data store.
- Performs serialization/deserialization, compression/decompression, column mapping, and so on. It performs these operations based on the configuration.
- Writes data to the destination data store.
Prerequisites
To get started, you must complete the following prerequisites:
A Microsoft Fabric tenant account with an active subscription. Create an account for free.
Make sure you have a Microsoft Fabric enabled Workspace.
Add a copy activity using copy assistant
Follow these steps to set up your copy activity using copy assistant.
Start with copy assistant
Open an existing data pipeline or create a new data pipeline.
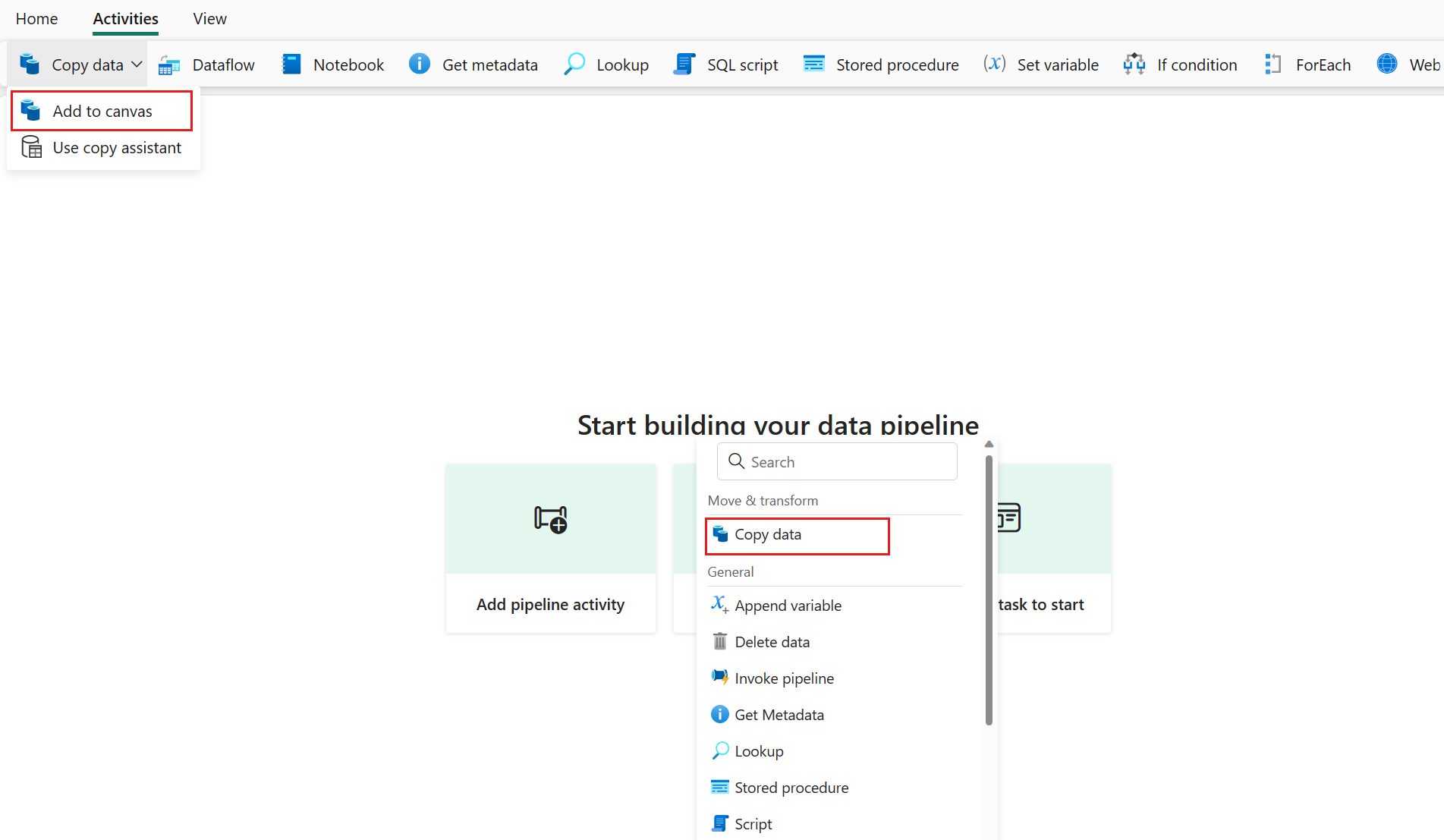
Select Copy data on the canvas to open the Copy Assistant tool to get started. Or select Use copy assistant from the Copy data drop down list under the Activities tab on the ribbon.


Configure your source
Select a data source type from the category. You'll use Azure Blob Storage as an example. Select Azure Blob Storage and then select Next.

Create a connection to your data source by selecting Create new connection.

After you select Create new connection, fill in the required connection information and then select Next. For the details of connection creation for each type of data source, you can refer to each connector article.
If you have existing connections, you can select Existing connection and select your connection from the drop-down list.

Choose the file or folder to be copied in this source configuration step, and then select Next.





Configure your destination
Select a data source type from the category. You'll use Azure Blob Storage as an example. You can either create a new connection that links to a new Azure Blob Storage account by following the steps in the previous section or use an existing connection from the connection drop-down list. The capabilities of Test connection and Edit are available to each selected connection.

Configure and map your source data to your destination. Then select Next to finish your destination configurations.


Note
You can only use a single on-premises data gateway within the same Copy activity. If both source and sink are on-premises data sources, they must use the same gateway. To move data between on-premises data sources with different gateways, you must copy using the first gateway to an intermediate cloud source in one Copy activity. Then you can use another Copy activity to copy it from the intermediate cloud source using the second gateway.



Review and create your copy activity
Review your copy activity settings in the previous steps and select OK to finish. Or you can go back to the previous steps to edit your settings if needed in the tool.


Once finished, the copy activity will then be added to your data pipeline canvas. All settings, including advanced settings to this copy activity, are available under the tabs when it’s selected.

Now you can either save your data pipeline with this single copy activity or continue to design your data pipeline.
Add a copy activity directly
Follow these steps to add a copy activity directly.
Add a copy activity
Open an existing data pipeline or create a new data pipeline.
Add a copy activity either by selecting Add pipeline activity > Copy activity or by selecting Copy data > Add to canvas under the Activities tab.

Configure your general settings under general tab
To learn how to configure your general settings, see General.
Configure your source under the source tab
Select + New beside the Connection to create a connection to your data source.

Choose the data source type from the pop-up window. You'll use Azure SQL Database as an example. Select Azure SQL Database, and then select Continue.

It navigates to the connection creation page. Fill in the required connection information on the panel, and then select Create. For the details of connection creation for each type of data source, you can refer to each connector article.

Once your connection is created successfully, it takes you back to the data pipeline page. Then select Refresh to fetch the connection that you created from the drop-down list. You could also choose an existing Azure SQL Database connection from the drop-down directly if you already created it before. The capabilities of Test connection and Edit are available to each selected connection. Then select Azure SQL Database in Connection type.

Specify a table to be copied. Select Preview data to preview your source table. You can also use Query and Stored procedure to read data from your source.

Expand Advanced for more advanced settings.







Configure your destination under the destination tab
Choose your destination type. It could be either your internal first class data store from your workspace, such as Lakehouse, or your external data stores. You'll use Lakehouse as an example.

Choose to use Lakehouse in Workspace data store type. Select + New, and it navigates you to the Lakehouse creation page. Specify your Lakehouse name and then select Create.

Once your connection is created successfully, it takes you back to the data pipeline page. Then select Refresh to fetch the connection that you created from the drop-down list. You could also choose an existing Lakehouse connection from the drop-down directly if you already created it before.
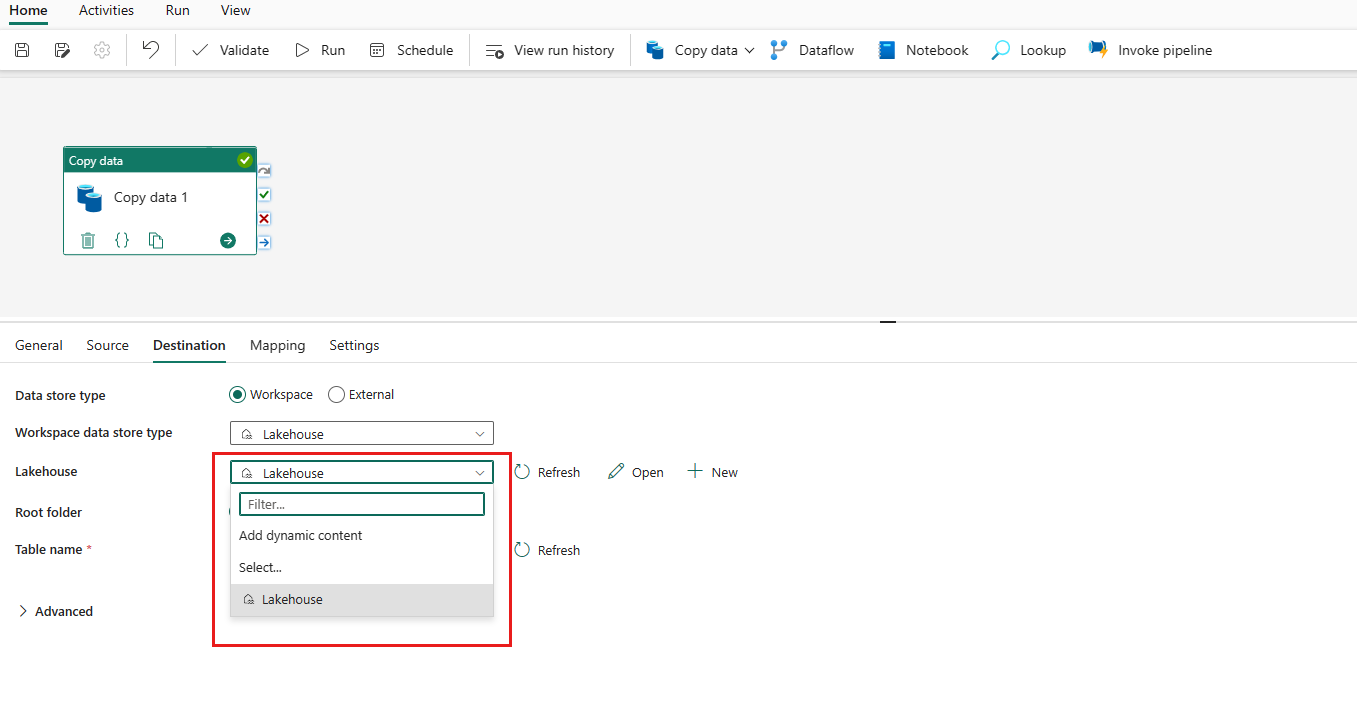
Specify a table or set up the file path to define the file or folder as the destination. Here select Tables and specify a table to write data.

Expand Advanced for more advanced settings.






Now you can either save your data pipeline with this single copy activity or continue to design your data pipeline.
Configure your mappings under mapping tab
If the connector that you apply supports mapping, you can go to Mapping tab to configure your mapping.
Select Import schemas to import your data schema.

You can see the auto mapping is shown up. Specify your Source column and Destination column. If you create a new table in the destination, you can customize your Destination column name here. If you want to write data into the existing destination table, you can't modify the existing Destination column name. You can also view the Type of source and destination columns.



Besides, you can select + New mapping to add new mapping, select Clear to clear all mapping settings, and select Reset to reset all mapping Source column.
Configure your other settings under settings tab
The Settings tab contains the settings of performance, staging, and so on.

See the following table for the description of each setting.
| Setting | Description | JSON script property |
|---|---|---|
| Intelligent throughput optimization | Specify to optimize the throughput. You can choose from: • Auto • Standard • Balanced • Maximum When you choose Auto, the optimal setting is dynamically applied based on your source-destination pair and data pattern. You can also customize your throughput, and custom value can be 2-256 while higher value implies more gains. |
dataIntegrationUnits |
| Degree of copy parallelism | Specify the degree of parallelism that data loading would use. | parallelCopies |
| Fault tolerance | When selecting this option, you can ignore some errors occurred in the middle of copy process. For example, incompatible rows between source and destination store, file being deleted during data movement, etc. | • enableSkipIncompatibleRow • skipErrorFile: fileMissing fileForbidden invalidFileName |
| Enable logging | When selecting this option, you can log copied files, skipped files and rows. | / |
| Enable staging | Specify whether to copy data via an interim staging store. Enable staging only for the beneficial scenarios. | enableStaging |
| Data store type | When enable staging, you can choose Workspace and External as your data store type. | / |
| For Workspace | ||
| Workspace | Specify to use built-in staging storage. | / |
| For External | ||
| Staging account connection | Specify the connection of an Azure Blob Storage or Azure Data Lake Storage Gen2, which refers to the instance of Storage that you use as an interim staging store. Create a staging connection if you don't have it. | connection (under externalReferences) |
| Storage path | Specify the path that you want to contain the staged data. If you do not provide a path, the service creates a container to store temporary data. Specify a path only if you use Storage with a shared access signature, or you require temporary data to be in a specific location. | path |
| Enable compression | Specifies whether data should be compressed before it's copied to the destination. This setting reduces the volume of data being transferred. | enableCompression |
| Preserve | Specify whether to preserve metadata/ACLs during data copy. | preserve |
Note
If you use staged copy with compression enabled, the service principal authentication for staging blob connection isn't supported.
Configure parameters in a copy activity
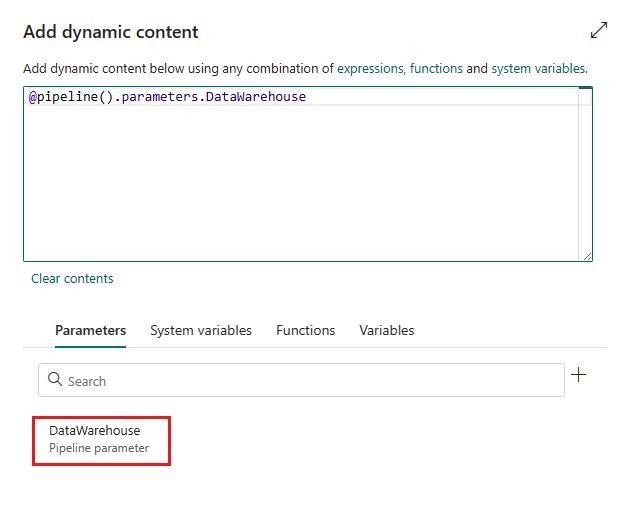
Parameters can be used to control the behavior of a pipeline and its activities. You can use Add dynamic content to specify parameters for your copy activity properties. Let's take specifying Lakehouse/Data Warehouse/KQL Database as an example to see how to use it.
In your source or destination, after selecting Workspace as data store type and specifying Lakehouse/Data Warehouse/KQL Database as workspace data store type, select Add dynamic content in the drop-down list of Lakehouse or Data Warehouse or KQL Database.
In the pop-up Add dynamic content pane, under Parameters tab, select +.
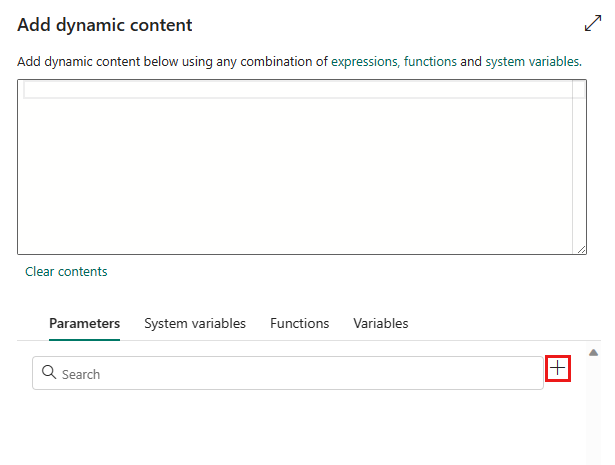
Specify the name for your parameter and give it a default value if you want, or you can specify the value for the parameter after selecting Run in the pipeline.

Note that the parameter value should be Lakehouse/Data Warehouse/KQL Database object ID. To get your Lakehouse/Data Warehouse/KQL Database object ID, open your Lakehouse/Data Warehouse/KQL Database in your workspace, and the ID is after
/lakehouses/or/datawarehouses/or/databases/in your URL.Lakehouse object ID:

Data Warehouse object ID:

KQL Database object ID:

Select Save to go back to the Add dynamic content pane. Then select your parameter so it appears in the expression box. Then select OK. You'll go back to the pipeline page and can see the parameter expression is specified after Lakehouse object ID/Data Warehouse object ID/KQL Database object ID.