Įvykiai
03-31 23 - 04-02 23
Didžiausias "Fabric", Power BI ir SQL mokymosi įvykis. Kovo 31 d. – balandžio 2 d. Naudokite kodą FABINSIDER, kad įrašytumėte $400.
Registruokitės šiandienŠi naršyklė nebepalaikoma.
Atnaujinkite į „Microsoft Edge“, kad pasinaudotumėte naujausiomis funkcijomis, saugos naujinimais ir techniniu palaikymu.
In this article, you learn how to get data from OneLake into either a new or existing table.
From your workspace select the Lakehouse environment containing the data source you want to use.
Place your cursor over the desired file and select the More (...) menu, then select Properties.
Svarbu

Under URL, select the Copy to clipboard icon and save it somewhere to retrieve in a later step.

Return to your workspace and select a KQL database.
On the lower ribbon of your KQL database, select Get Data.
In the Get data window, the Source tab is selected.
Select the data source from the available list. In this example, you're ingesting data from OneLake.

Select a target table. If you want to ingest data into a new table, select +New table and enter a table name.
Pastaba
Table names can be up to 1024 characters including spaces, alphanumeric, hyphens, and underscores. Special characters aren't supported.
In OneLake file, paste the file path of the Lakehouse you copied in Copy file path from Lakehouse.
Pastaba
You can add up to 10 items of up to 1-GB uncompressed size each.

Select Next.
The Inspect tab opens with a preview of the data.
To complete the ingestion process, select Finish.

Optionally:
Pastaba
The changes you can make in a table depend on the following parameters:
| Table type | Mapping type | Available adjustments |
|---|---|---|
| New table | New mapping | Rename column, change data type, change data source, mapping transformation, add column, delete column |
| Existing table | New mapping | Add column (on which you can then change data type, rename, and update) |
| Existing table | Existing mapping | none |

Some data format mappings (Parquet, JSON, and Avro) support simple ingest-time transformations. To apply mapping transformations, create or update a column in the Edit columns window.
Mapping transformations can be performed on a column of type string or datetime, with the source having data type int or long. Supported mapping transformations are:
Tabular (CSV, TSV, PSV):
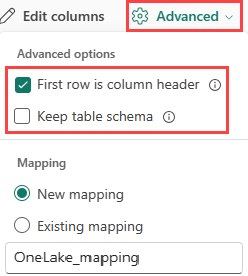
If you're ingesting tabular formats in an existing table, you can select Advanced > Keep table schema. Tabular data doesn't necessarily include the column names that are used to map source data to the existing columns. When this option is checked, mapping is done by-order, and the table schema remains the same. If this option is unchecked, new columns are created for incoming data, regardless of data structure.
To use the first row as column names, select Advanced > First row is column header.
JSON:
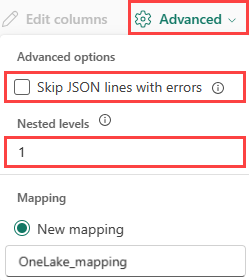
To determine column division of JSON data, select Advanced > Nested levels, from 1 to 100.
If you select Advanced > Skip JSON lines with errors, the data is ingested in JSON format. If you leave this check box unselected, the data is ingested in multijson format.
In the Data preparation window, all three steps are marked with green check marks when data ingestion finishes successfully. You can select a card to query, drop the ingested data, or see a dashboard of your ingestion summary.

Įvykiai
03-31 23 - 04-02 23
Didžiausias "Fabric", Power BI ir SQL mokymosi įvykis. Kovo 31 d. – balandžio 2 d. Naudokite kodą FABINSIDER, kad įrašytumėte $400.
Registruokitės šiandienMokymas
Mokymosi kelias
Ingest data with Microsoft Fabric - Training
Explore how Microsoft Fabric enables you to ingest and orchestrate data from various sources (such as files, databases, or web services) through dataflows, notebooks, and pipelines.
Sertifikatas
Microsoft Certified: Fabric Data Engineer Associate - Certifications
As a Fabric Data Engineer, you should have subject matter expertise with data loading patterns, data architectures, and orchestration processes.
Dokumentacija
Get data from file - Microsoft Fabric
Learn how to get data from a local file in a KQL database in Real-Time Intelligence.
Options to get data into the Lakehouse - Microsoft Fabric
Learn how to load data into a lakehouse via a file upload, Apache Spark libraries in notebook code, and the copy tool in pipelines.
Load data into your lakehouse with a notebook - Microsoft Fabric
Learn how to use a notebook to load data into your lakehouse with either an existing notebook or a new one.