Reporting across scaled-out cloud databases (preview)
Applies to: ![]() Azure SQL Database
Azure SQL Database
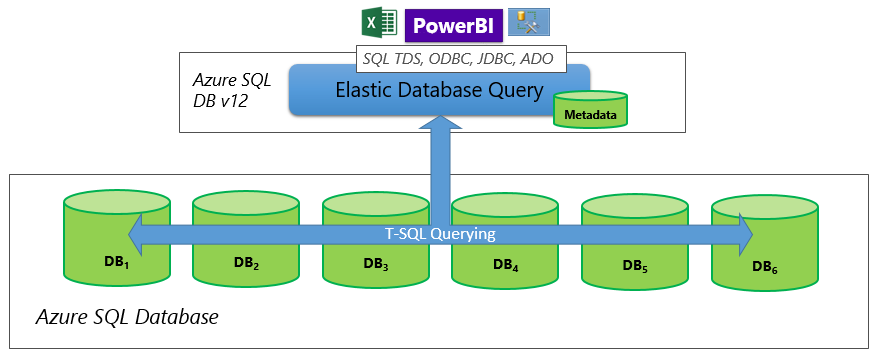
Sharded databases distribute rows across a scaled out data tier. The schema is identical on all participating databases, also known as horizontal partitioning. Using an elastic query, you can create reports that span all databases in a sharded database.
For a quickstart, see Reporting across scaled-out cloud databases.
For non-sharded databases, see Query across cloud databases with different schemas.
Prerequisites
- Create a shard map using the elastic database client library. see Shard map management. Or use the sample app in Get started with elastic database tools.
- Alternatively, see Migrate existing databases to scaled-out databases.
- The user must possess ALTER ANY EXTERNAL DATA SOURCE permission. This permission is included with the ALTER DATABASE permission.
- ALTER ANY EXTERNAL DATA SOURCE permissions are needed to refer to the underlying data source.
Overview
These statements create the metadata representation of your sharded data tier in the elastic query database.
- CREATE MASTER KEY
- CREATE DATABASE SCOPED CREDENTIAL
- CREATE EXTERNAL DATA SOURCE
- CREATE EXTERNAL TABLE
1.1 Create database scoped master key and credentials
The credential is used by the elastic query to connect to your remote databases.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
CREATE DATABASE SCOPED CREDENTIAL [<credential_name>] WITH IDENTITY = '<username>',
SECRET = '<password>';
Note
Make sure that the "<username>" does not include any "@servername" suffix.
1.2 Create external data sources
Syntax:
<External_Data_Source> ::=
CREATE EXTERNAL DATA SOURCE <data_source_name> WITH
(TYPE = SHARD_MAP_MANAGER,
LOCATION = '<fully_qualified_server_name>',
DATABASE_NAME = '<shardmap_database_name>',
CREDENTIAL = <credential_name>,
SHARD_MAP_NAME = '<shardmapname>'
) [;]
Example
CREATE EXTERNAL DATA SOURCE MyExtSrc
WITH
(
TYPE=SHARD_MAP_MANAGER,
LOCATION='myserver.database.windows.net',
DATABASE_NAME='ShardMapDatabase',
CREDENTIAL= SMMUser,
SHARD_MAP_NAME='ShardMap'
);
Retrieve the list of current external data sources:
select * from sys.external_data_sources;
The external data source references your shard map. An elastic query then uses the external data source and the underlying shard map to enumerate the databases that participate in the data tier. The same credentials are used to read the shard map and to access the data on the shards during the processing of an elastic query.
1.3 Create external tables
Syntax:
CREATE EXTERNAL TABLE [ database_name . [ schema_name ] . | schema_name. ] table_name
( { <column_definition> } [ ,...n ])
{ WITH ( <sharded_external_table_options> ) }
) [;]
<sharded_external_table_options> ::=
DATA_SOURCE = <External_Data_Source>,
[ SCHEMA_NAME = N'nonescaped_schema_name',]
[ OBJECT_NAME = N'nonescaped_object_name',]
DISTRIBUTION = SHARDED(<sharding_column_name>) | REPLICATED |ROUND_ROBIN
Example
CREATE EXTERNAL TABLE [dbo].[order_line](
[ol_o_id] int NOT NULL,
[ol_d_id] tinyint NOT NULL,
[ol_w_id] int NOT NULL,
[ol_number] tinyint NOT NULL,
[ol_i_id] int NOT NULL,
[ol_delivery_d] datetime NOT NULL,
[ol_amount] smallmoney NOT NULL,
[ol_supply_w_id] int NOT NULL,
[ol_quantity] smallint NOT NULL,
[ol_dist_info] char(24) NOT NULL
)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'orders',
OBJECT_NAME = 'order_details',
DISTRIBUTION=SHARDED(ol_w_id)
);
Retrieve the list of external tables from the current database:
SELECT * from sys.external_tables;
To drop external tables:
DROP EXTERNAL TABLE [ database_name . [ schema_name ] . | schema_name. ] table_name[;]
Remarks
The DATA_SOURCE clause defines the external data source (a shard map) that is used for the external table.
The SCHEMA_NAME and OBJECT_NAME clauses map the external table definition to a table in a different schema. If omitted, the schema of the remote object is assumed to be dbo and its name is assumed to be identical to the external table name being defined. This is useful if the name of your remote table is already taken in the database where you want to create the external table. For example, you want to define an external table to get an aggregate view of catalog views or DMVs on your scaled out data tier. Since catalog views and DMVs already exist locally, you cannot use their names for the external table definition. Instead, use a different name and use the catalog view's or the DMV's name in the SCHEMA_NAME and/or OBJECT_NAME clauses. (See the example below.)
The DISTRIBUTION clause specifies the data distribution used for this table. The query processor utilizes the information provided in the DISTRIBUTION clause to build the most efficient query plans.
- SHARDED means data is horizontally partitioned across the databases. The partitioning key for the data distribution is the <sharding_column_name> parameter.
- REPLICATED means that identical copies of the table are present on each database. It is your responsibility to ensure that the replicas are identical across the databases.
- ROUND_ROBIN means that the table is horizontally partitioned using an application-dependent distribution method.
Data tier reference: The external table DDL refers to an external data source. The external data source specifies a shard map that provides the external table with the information necessary to locate all the databases in your data tier.
Security considerations
Users with access to the external table automatically gain access to the underlying remote tables under the credential given in the external data source definition. Avoid undesired elevation of privileges through the credential of the external data source. Use GRANT or REVOKE for an external table as though it were a regular table.
Once you have defined your external data source and your external tables, you can now use full T-SQL over your external tables.
Example: querying horizontal partitioned databases
The following query performs a three-way join between warehouses, orders, and order lines and uses several aggregates and a selective filter. It assumes (1) horizontal partitioning (sharding) and (2) that warehouses, orders, and order lines are sharded by the warehouse ID column, and that the elastic query can co-locate the joins on the shards and process the expensive part of the query on the shards in parallel.
select
w_id as warehouse,
o_c_id as customer,
count(*) as cnt_orderline,
max(ol_quantity) as max_quantity,
avg(ol_amount) as avg_amount,
min(ol_delivery_d) as min_deliv_date
from warehouse
join orders
on w_id = o_w_id
join order_line
on o_id = ol_o_id and o_w_id = ol_w_id
where w_id > 100 and w_id < 200
group by w_id, o_c_id
Stored procedure for remote T-SQL execution: sp_execute_remote
Elastic query also introduces a stored procedure that provides direct access to the shards. The stored procedure is called sp_execute _remote and can be used to execute remote stored procedures or T-SQL code on the remote databases. It takes the following parameters:
- Data source name (nvarchar): The name of the external data source of type RDBMS.
- Query (nvarchar): The T-SQL query to be executed on each shard.
- Parameter declaration (nvarchar) - optional: String with data type definitions for the parameters used in the Query parameter (like sp_executesql).
- Parameter value list - optional: Comma-separated list of parameter values (like sp_executesql).
The sp_execute_remote uses the external data source provided in the invocation parameters to execute the given T-SQL statement on the remote databases. It uses the credential of the external data source to connect to the shardmap manager database and the remote databases.
Example:
EXEC sp_execute_remote
N'MyExtSrc',
N'select count(w_id) as foo from warehouse'
Connectivity for tools
Use regular SQL Server connection strings to connect your application, your BI, and data integration tools to the database with your external table definitions. Make sure that SQL Server is supported as a data source for your tool. Then reference the elastic query database like any other SQL Server database connected to the tool, and use external tables from your tool or application as if they were local tables.
Best practices
- Ensure that the elastic query endpoint database has been given access to the shardmap database and all shards through the SQL Database firewalls.
- Validate or enforce the data distribution defined by the external table. If your actual data distribution is different from the distribution specified in your table definition, your queries may yield unexpected results.
- Elastic query currently does not perform shard elimination when predicates over the sharding key would allow it to safely exclude certain shards from processing.
- Elastic query works best for queries where most of the computation can be done on the shards. You typically get the best query performance with selective filter predicates that can be evaluated on the shards or joins over the partitioning keys that can be performed in a partition-aligned way on all shards. Other query patterns may need to load large amounts of data from the shards to the head node and may perform poorly
Next steps
- For an overview of elastic query, see Elastic query overview.
- For a vertical partitioning tutorial, see Getting started with cross-database query (vertical partitioning).
- For syntax and sample queries for vertically partitioned data, see Querying vertically partitioned data)
- For a horizontal partitioning (sharding) tutorial, see Getting started with elastic query for horizontal partitioning (sharding).
- See sp_execute _remote for a stored procedure that executes a Transact-SQL statement on a single remote Azure SQL Database or set of databases serving as shards in a horizontal partitioning scheme.