Copy and transform data in Azure Database for PostgreSQL using Azure Data Factory or Synapse Analytics
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
This article outlines how to use Copy Activity in Azure Data Factory and Synapse Analytics pipelines to copy data from and to Azure Database for PostgreSQL, and use Data Flow to transform data in Azure Database for PostgreSQL. To learn more, read the introductory articles for Azure Data Factory and Synapse Analytics.
This connector is specialized for the Azure Database for PostgreSQL service. To copy data from a generic PostgreSQL database located on-premises or in the cloud, use the PostgreSQL connector.
Supported capabilities
This Azure Database for PostgreSQL connector is supported for the following capabilities:
| Supported capabilities | IR | Managed private endpoint |
|---|---|---|
| Copy activity (source/sink) | ① ② | ✓ |
| Mapping data flow (source/sink) | ① | ✓ |
| Lookup activity | ① ② | ✓ |
① Azure integration runtime ② Self-hosted integration runtime
The three activities work on all Azure Database for PostgreSQL deployment options:
Getting started
To perform the Copy activity with a pipeline, you can use one of the following tools or SDKs:
- The Copy Data tool
- The Azure portal
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- The Azure Resource Manager template
Create a linked service to Azure Database for PostgreSQL using UI
Use the following steps to create a linked service to Azure database for PostgreSQL in the Azure portal UI.
Browse to the Manage tab in your Azure Data Factory or Synapse workspace and select Linked Services, then click New:
Search for PostgreSQL and select the Azure database for PostgreSQL connector.
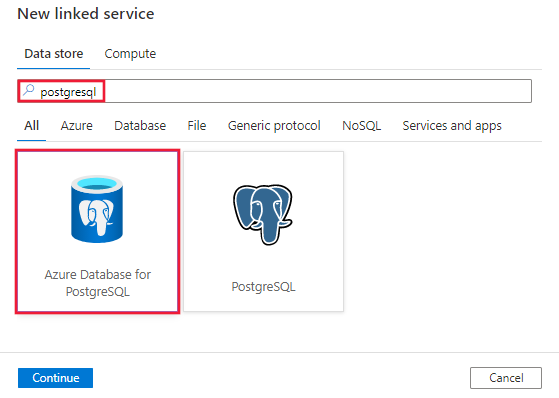
Configure the service details, test the connection, and create the new linked service.

Connector configuration details
The following sections offer details about properties that are used to define Data Factory entities specific to Azure Database for PostgreSQL connector.
Linked service properties
The following properties are supported for the Azure Database for PostgreSQL linked service:
| Property | Description | Required |
|---|---|---|
| type | The type property must be set to: AzurePostgreSql. | Yes |
| connectionString | An ODBC connection string to connect to Azure Database for PostgreSQL. You can also put a password in Azure Key Vault and pull the password configuration out of the connection string. See the following samples and Store credentials in Azure Key Vault for more details. |
Yes |
| connectVia | This property represents the integration runtime to be used to connect to the data store. You can use Azure Integration Runtime or Self-hosted Integration Runtime (if your data store is located in private network). If not specified, it uses the default Azure Integration Runtime. | No |
A typical connection string is Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>. Here are more properties you can set per your case:
| Property | Description | Options | Required |
|---|---|---|---|
| EncryptionMethod (EM) | The method the driver uses to encrypt data sent between the driver and the database server. For example, EncryptionMethod=<0/1/6>; |
0 (No Encryption) (Default) / 1 (SSL) / 6 (RequestSSL) | No |
| ValidateServerCertificate (VSC) | Determines whether the driver validates the certificate that's sent by the database server when SSL encryption is enabled (Encryption Method=1). For example, ValidateServerCertificate=<0/1>; |
0 (Disabled) (Default) / 1 (Enabled) | No |
Example:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>"
}
}
}
Example:
Store password in Azure Key Vault
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
Dataset properties
For a full list of sections and properties available for defining datasets, see Datasets. This section provides a list of properties that Azure Database for PostgreSQL supports in datasets.
To copy data from Azure Database for PostgreSQL, set the type property of the dataset to AzurePostgreSqlTable. The following properties are supported:
| Property | Description | Required |
|---|---|---|
| type | The type property of the dataset must be set to AzurePostgreSqlTable | Yes |
| tableName | Name of the table | No (if "query" in activity source is specified) |
Example:
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Copy activity properties
For a full list of sections and properties available for defining activities, see Pipelines and activities. This section provides a list of properties supported by an Azure Database for PostgreSQL source.
Azure Database for PostgreSql as source
To copy data from Azure Database for PostgreSQL, set the source type in the copy activity to AzurePostgreSqlSource. The following properties are supported in the copy activity source section:
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity source must be set to AzurePostgreSqlSource | Yes |
| query | Use the custom SQL query to read data. For example: SELECT * FROM mytable or SELECT * FROM "MyTable". Note in PostgreSQL, the entity name is treated as case-insensitive if not quoted. |
No (if the tableName property in the dataset is specified) |
| queryTimeout | The wait time before terminating the attempt to execute a command and generating an error, default is 120 minutes. If parameter is set for this property, allowed values are timespan, such as "02:00:00" (120 minutes). For more information, see CommandTimeout. | No |
| partitionOptions | Specifies the data partitioning options used to load data from Azure SQL Database. Allowed values are: None (default), PhysicalPartitionsOfTable, and DynamicRange. When a partition option is enabled (that is, not None), the degree of parallelism to concurrently load data from an Azure SQL Database is controlled by the parallelCopies setting on the copy activity. |
No |
| partitionSettings | Specify the group of the settings for data partitioning. Apply when the partition option isn't None. |
No |
Under partitionSettings: |
||
| partitionNames | The list of physical partitions that needs to be copied. Apply when the partition option is PhysicalPartitionsOfTable. If you use a query to retrieve the source data, hook ?AdfTabularPartitionName in the WHERE clause. For an example, see the Parallel copy from Azure Database for PostgreSQL section. |
No |
| partitionColumnName | Specify the name of the source column in integer or date/datetime type (int, smallint, bigint, date, timestamp without time zone, timestamp with time zone or time without time zone) that will be used by range partitioning for parallel copy. If not specified, the primary key of the table is auto-detected and used as the partition column.Apply when the partition option is DynamicRange. If you use a query to retrieve the source data, hook ?AdfRangePartitionColumnName in the WHERE clause. For an example, see the Parallel copy from Azure Database for PostgreSQL section. |
No |
| partitionUpperBound | The maximum value of the partition column to copy data out. Apply when the partition option is DynamicRange. If you use a query to retrieve the source data, hook ?AdfRangePartitionUpbound in the WHERE clause. For an example, see the Parallel copy from Azure Database for PostgreSQL section. |
No |
| partitionLowerBound | The minimum value of the partition column to copy data out. Apply when the partition option is DynamicRange. If you use a query to retrieve the source data, hook ?AdfRangePartitionLowbound in the WHERE clause. For an example, see the Parallel copy from Azure Database for PostgreSQL section. |
No |
Example:
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Database for PostgreSQL as sink
To copy data to Azure Database for PostgreSQL, the following properties are supported in the copy activity sink section:
| Property | Description | Required |
|---|---|---|
| type | The type property of the copy activity sink must be set to AzurePostgreSQLSink. | Yes |
| preCopyScript | Specify a SQL query for the copy activity to execute before you write data into Azure Database for PostgreSQL in each run. You can use this property to clean up the preloaded data. | No |
| writeMethod | The method used to write data into Azure Database for PostgreSQL. Allowed values are: CopyCommand (default, which is more performant), BulkInsert. |
No |
| writeBatchSize | The number of rows loaded into Azure Database for PostgreSQL per batch. Allowed value is an integer that represents the number of rows. |
No (default is 1,000,000) |
| writeBatchTimeout | Wait time for the batch insert operation to complete before it times out. Allowed values are Timespan strings. An example is 00:30:00 (30 minutes). |
No (default is 00:30:00) |
Example:
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSQLSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
Parallel copy from Azure Database for PostgreSQL
The Azure Database for PostgreSQL connector in copy activity provides built-in data partitioning to copy data in parallel. You can find data partitioning options on the Source tab of the copy activity.

When you enable partitioned copy, copy activity runs parallel queries against your Azure Database for PostgreSQL source to load data by partitions. The parallel degree is controlled by the parallelCopies setting on the copy activity. For example, if you set parallelCopies to four, the service concurrently generates and runs four queries based on your specified partition option and settings, and each query retrieves a portion of data from your Azure Database for PostgreSQL.
You are suggested to enable parallel copy with data partitioning especially when you load large amount of data from your Azure Database for PostgreSQL. The following are suggested configurations for different scenarios. When copying data into file-based data store, it's recommended to write to a folder as multiple files (only specify folder name), in which case the performance is better than writing to a single file.
| Scenario | Suggested settings |
|---|---|
| Full load from large table, with physical partitions. | Partition option: Physical partitions of table. During execution, the service automatically detects the physical partitions, and copies data by partitions. |
| Full load from large table, without physical partitions, while with an integer column for data partitioning. | Partition options: Dynamic range partition. Partition column: Specify the column used to partition data. If not specified, the primary key column is used. |
| Load a large amount of data by using a custom query, with physical partitions. | Partition option: Physical partitions of table. Query: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.Partition name: Specify the partition name(s) to copy data from. If not specified, the service automatically detects the physical partitions on the table you specified in the PostgreSQL dataset. During execution, the service replaces ?AdfTabularPartitionName with the actual partition name, and sends to Azure Database for PostgreSQL. |
| Load a large amount of data by using a custom query, without physical partitions, while with an integer column for data partitioning. | Partition options: Dynamic range partition. Query: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Partition column: Specify the column used to partition data. You can partition against the column with integer or date/datetime data type. Partition upper bound and partition lower bound: Specify if you want to filter against partition column to retrieve data only between the lower and upper range. During execution, the service replaces ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound, and ?AdfRangePartitionLowbound with the actual column name and value ranges for each partition, and sends to Azure Database for PostgreSQL. For example, if your partition column "ID" is set with the lower bound as 1 and the upper bound as 80, with parallel copy set as 4, the service retrieves data by 4 partitions. Their IDs are between [1,20], [21, 40], [41, 60], and [61, 80], respectively. |
Best practices to load data with partition option:
- Choose distinctive column as partition column (like primary key or unique key) to avoid data skew.
- If the table has built-in partition, use partition option "Physical partitions of table" to get better performance.
- If you use Azure Integration Runtime to copy data, you can set larger "Data Integration Units (DIU)" (>4) to utilize more computing resource. Check the applicable scenarios there.
- "Degree of copy parallelism" control the partition numbers, setting this number too large sometime hurts the performance, recommend setting this number as (DIU or number of Self-hosted IR nodes) * (2 to 4).
Example: full load from large table with physical partitions
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Example: query with dynamic range partition
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Mapping data flow properties
When transforming data in mapping data flow, you can read and write to tables from Azure Database for PostgreSQL. For more information, see the source transformation and sink transformation in mapping data flows. You can choose to use an Azure Database for PostgreSQL dataset or an inline dataset as source and sink type.
Source transformation
The below table lists the properties supported by Azure Database for PostgreSQL source. You can edit these properties in the Source options tab.
| Name | Description | Required | Allowed values | Data flow script property |
|---|---|---|---|---|
| Table | If you select Table as input, data flow fetches all the data from the table specified in the dataset. | No | - | (for inline dataset only) tableName |
| Query | If you select Query as input, specify a SQL query to fetch data from source, which overrides any table you specify in dataset. Using queries is a great way to reduce rows for testing or lookups. Order By clause is not supported, but you can set a full SELECT FROM statement. You can also use user-defined table functions. select * from udfGetData() is a UDF in SQL that returns a table that you can use in data flow. Query example: select * from mytable where customerId > 1000 and customerId < 2000 or select * from "MyTable". Note in PostgreSQL, the entity name is treated as case-insensitive if not quoted. |
No | String | query |
| Schema name | If you select Stored procedure as input, specify a schema name of the stored procedure, or select Refresh to ask the service to discover the schema names. | No | String | schemaName |
| Stored procedure | If you select Stored procedure as input, specify a name of the stored procedure to read data from the source table, or select Refresh to ask the service to discover the procedure names. | Yes (if you select Stored procedure as input) | String | procedureName |
| Procedure parameters | If you select Stored procedure as input, specify any input parameters for the stored procedure in the order set in the procedure, or select Import to import all procedure parameters using the form @paraName. |
No | Array | inputs |
| Batch size | Specify a batch size to chunk large data into batches. | No | Integer | batchSize |
| Isolation Level | Choose one of the following isolation levels: - Read Committed - Read Uncommitted (default) - Repeatable Read - Serializable - None (ignore isolation level) |
No | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE NONE |
isolationLevel |
Azure Database for PostgreSQL source script example
When you use Azure Database for PostgreSQL as source type, the associated data flow script is:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
Sink transformation
The below table lists the properties supported by Azure Database for PostgreSQL sink. You can edit these properties in the Sink options tab.
| Name | Description | Required | Allowed values | Data flow script property |
|---|---|---|---|---|
| Update method | Specify what operations are allowed on your database destination. The default is to only allow inserts. To update, upsert, or delete rows, an Alter row transformation is required to tag rows for those actions. |
Yes | true or false |
deletable insertable updateable upsertable |
| Key columns | For updates, upserts and deletes, key column(s) must be set to determine which row to alter. The column name that you pick as the key will be used as part of the subsequent update, upsert, delete. Therefore, you must pick a column that exists in the Sink mapping. |
No | Array | keys |
| Skip writing key columns | If you wish to not write the value to the key column, select "Skip writing key columns". | No | true or false |
skipKeyWrites |
| Table action | Determines whether to recreate or remove all rows from the destination table prior to writing. - None: No action will be done to the table. - Recreate: The table will get dropped and recreated. Required if creating a new table dynamically. - Truncate: All rows from the target table will get removed. |
No | true or false |
recreate truncate |
| Batch size | Specify how many rows are being written in each batch. Larger batch sizes improve compression and memory optimization, but risk out of memory exceptions when caching data. | No | Integer | batchSize |
| Select user DB schema | By default, a temporary table will be created under the sink schema as staging. You can alternatively uncheck the Use sink schema option and instead, specify a schema name under which Data Factory will create a staging table to load upstream data and automatically clean them up upon completion. Make sure you have create table permission in the database and alter permission on the schema. | No | String | stagingSchemaName |
| Pre and Post SQL scripts | Specify multi-line SQL scripts that will execute before (pre-processing) and after (post-processing) data is written to your Sink database. | No | String | preSQLs postSQLs |
Tip
- It's recommended to break single batch scripts with multiple commands into multiple batches.
- Only Data Definition Language (DDL) and Data Manipulation Language (DML) statements that return a simple update count can be run as part of a batch. Learn more from Performing batch operations
Enable incremental extract: Use this option to tell ADF to only process rows that have changed since the last time that the pipeline executed.
Incremental column: When using the incremental extract feature, you must choose the date/time or numeric column that you wish to use as the watermark in your source table.
Start reading from beginning: Setting this option with incremental extract will instruct ADF to read all rows on first execution of a pipeline with incremental extract turned on.
Azure Database for PostgreSQL sink script example
When you use Azure Database for PostgreSQL as sink type, the associated data flow script is:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSQLSink
Lookup activity properties
For more information about the properties, see Lookup activity.
Related content
For a list of data stores supported as sources and sinks by the copy activity, see Supported data stores.