Piezīme
Lai piekļūtu šai lapai, ir nepieciešama autorizācija. Varat mēģināt pierakstīties vai mainīt direktorijus.
Lai piekļūtu šai lapai, ir nepieciešama autorizācija. Varat mēģināt mainīt direktorijus.
[Šis raksts ir pirmsizlaides dokumentācija, kas var mainīties.]
Jaunais optimizētais DirectLake semantiskais modelis nodrošina ātrāku un efektīvāku procesu analīzi. Ietaupot atmiņu, varat analizēt lielākus procesus un ietaupīt izmaksas, analīzei izmantojot mazākas Fabric ietilpības. Turklāt tiek izmantota intuitīvāka Power BI semantiskā modeļa datu struktūra, kas ļauj iedziļināties ieskatos ar mazāku laiku un pūlēm.
Svarīgi
- Šis ir priekšskatījuma līdzeklis.
- Priekšskatījuma līdzekļi nav paredzēti komerciālai lietošanai, un to funkcionalitāte var būt ierobežota. Šie līdzekļi ir pieejami pirms oficiālā laidiena, lai klienti varētu priekšlaikus piekļūt līdzeklim un sniegt atsauksmes.
- Lai iegūtu papildinformāciju, dodieties uz mūsu priekšskatījuma noteikumiem.
Semantiskā modeļa apraksts
Kad process tiek publicēts Fabric darbvietā, tiek izveidots jauns semantiskais modelis un atbilstoša atskaite. Šis ekrānuzņēmums ir semantiskās modeļa struktūras piemērs, kas publicēts uzņēmumā Fabric.
Atlasiet palielināmo stiklu attēla apakšējā labajā stūrī, lai to palielinātu.

Attiecības
Relācijas, kas nepieciešamas vizuālo materiālu filtrēšanai un savstarpējai savienojamībai, ir iepriekš definētas publicētajā datu modelī. Nav nepieciešams manuāli izveidot vairāk relāciju, ja vien nav pievienoti citi datu avoti. Šim scenārijam izmantojiet saliktu semantisku modeli Power BI un veidojiet relācijas virs šī modeļa.
Datu modeļa kopsavilkums
No loģiskā viedokļa datu modelis sastāv no daudzām entītiju apakškopām, kā parādīts šīs sadaļas pirmajā rindkopā.
- Procesa dati: visi ar procesu saistītie dati bez filtrēšanas un aprēķinātajiem mērījumiem
- Vizuālie dati: entītijas, kas nodrošina iepriekš aprēķinātos datus, kas nepieciešami, lai parādītu pielāgotus vizuālos materiālus
- Palīdzības vienības: citas vienības, kas nepieciešamas Power BI
Tālāk ir sniegts īss apakškopu un iekļauto vienību apraksts.
Apstrādāt datus
Procesa datu entītiju saturs mainās noteiktos scenārijos.
- Kad procesa modeļa dati tiek atsvaidzināti
- Kad tiek izveidots jauns skats
- Kad tiek izveidota jauna pielāgota metrika
- Ja lietotājs maina filtrēšanas definīciju jebkurā procesa skatā
Darbs ar šīm entītijām ļauj:
- Piekļūstiet procesa neapstrādātajiem datiem
- Lietoto filtru ietekmētie procesa dati
- Piekļūstiet mērījumiem, kas aprēķināti, pamatojoties uz lietotajiem filtriem
| Tabula | Apraksts |
|---|---|
| Pieteikumi | Visu gadījumu un to atribūtu saraksts procesā. Katram pieteikumam ir unikāls pieteikuma ID displejs un katra pieteikuma atribūta vērtības, kā definēts kartēšanas iestatīšanas darbībā. Apvienojiet ar entītiju CaseMetrics, lai iegūtu pilnīgu informāciju par pieteikumu . |
| Notikumi | Visu procesa notikuma atribūtu saraksts. Katram notikumam ir unikāls notikuma identifikatora indekss un vērtības katram notikuma atribūtam, kā definēts kartēšanas iestatīšanas darbībā. Apvienojiet ar entītiju ProcessMapMetrics , kas filtrēta pēc Is_Node kolonnas, lai iegūtu pilnīgu notikuma informāciju. |
| Gadījumu metrika | Entītijai ir visi pieteikuma līmeņa rādītāji, kas saistīti ar noteiktu pieteikuma un skata kombināciju. Šai entītijai tiek pievienota pieteikuma līmeņa pielāgotā metrika, kas definēta datora programmā Power Automate Process Mining. |
| AtribūtiMetadati | Entītijai ir visu gadījuma/notikuma līmeņa atribūtu definīcija, kā definēts notikumu žurnāla datu importēšanā procesa modelī. Tas ietver tā datu tipu, atribūta veidu un atribūta līmeni, kas ir vai nu gadījums, vai notikums. |
| Kalnrūpniecības atribūti | Saglabā pieejamo ieguves atribūtu vērtības. Procesa skatu var iestatīt, lai aplūkotu procesu no dažādas perspektīvas, pamatojoties uz atlasīto ieguves atribūtu. Ja nav pieejams cits ieguves atribūts, entītijai ir atribūta Activity vērtības. |
| Skatījumi | Pieejamo (publicēto) skatu saraksts, kas izveidots datora programmā Power Automate Process Mining. Datu kopā tiek publicēti tikai publiskie procesa skati. Ierakstus var izmantot, lai filtrētu atskaiti, atskaites lapu un vizuālo materiālu, lai vizualizētu tikai datus no konkrētā procesa skata. |
| Varianti | Entītijai ir attiecības starp variantiem un procesa skatiem. Ieraksts tiek iekļauts, ja pēc filtrēšanas kritēriju ņemšanas vērā skatā tiek iekļauts konkrēts variants. |
Vizuālie dati
Vizuālo datu entītijas tiek pārrēķinātas tikai tad, ja procesa modelim tiek atsvaidzināti dati.
| Tabula | Apraksts |
|---|---|
| ProcessMapMetrics | Apkopoti mēri visiem procesa modeļa mezgliem un pārejām, kas nepieciešamas vizualizācijai procesa kartes pielāgotajā vizuālajā vi Šī entītija apvieno notikumu (mezgla) informāciju un malu (pārejas) informāciju — lai izmantotu notikumus vai malas citos vizuālajos materiālos, filtrējiet pēc kolonnas vērtības Is_Node .
Šai entītijai tiek pievienota notikuma līmeņa pielāgota metrika, kas definēta datora programmā Power Automate Process Mining. |
Citas vienības
| Tabula | Apraksts |
|---|---|
| Lokalizācijas tabula | Iekšējā tabula, ko izmanto lokalizācijas nolūkā. |
Power BI salikts modelis
Ieteicams izmantot saliktu modeli Power BI virs semantiskā modeļa, ko Power Automate publicējis Process Extract, un izveidot nepieciešamās izmaiņas šādiem scenārijiem:
- Jums ir jāizveido citi datu avoti
- Jums ir jāizveido citas entītijas
- Jums ir jāizveido vairāk attiecību
- Jums ir jāizveido vairāk pielāgotu DAX (datu analīzes izteiksmes) vaicājumu
Svarīgi
Semantiskais modelis tiek izveidots DirectLake piekļuves režīmā, bet tā opcija ir iestatīta uz Automātiski. Šis iestatījums nozīmē, ka, izmantojot neoptimālus DAX vaicājumus vai nepareizi iestatot saliktu modeli, var tikt atgriezties DirectQuery režīmā. Tas nozīmē, ka jūsu pārskats netiks bojāts, bet jums var būt zemāka veiktspēja.
Lai uzzinātu vairāk par saliktu datu modeļu izveidi Power BI , izmantojot DirectLake semantiskos modeļus, dodieties uz saliktu modeļu veidošana semantiskā modelī vai modelī.
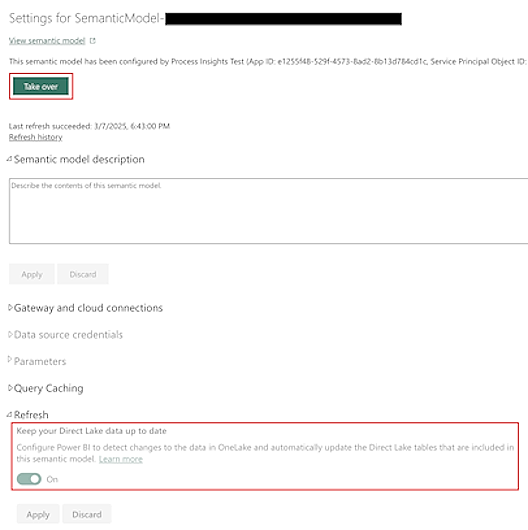
Semantiskā modeļa atsvaidzināšana
Pēc noklusējuma semantiskais modelis, ko Power Automate nodrošina Process Mining automātiski tiek atjaunināts.
Lielām datu kopām pamatā esošo tabulu datu atsvaidzināšana programmā OneLake var aizņemt ilgāku laiku. Tas var izraisīt iespējamas pārskata neatbilstības. Lai gan datu atsvaidzināšanas beigās ir iespējama konsekvence (semantiskais modelis ir skaidri atsvaidzināts), iespējams, vēlēsities noņemt iespējamās starpposma neatbilstības, semantiskā modeļa ekrānā Iestatījumi izslēdzot karodziņu Saglabāt Direct Lake datus .
Pirms šī ekrāna atjaunināšanas jums ir jāpārņem īpašumtiesības uz semantisku modeli, ekrāna Iestatījumi augšdaļā atlasot Pārņemt .